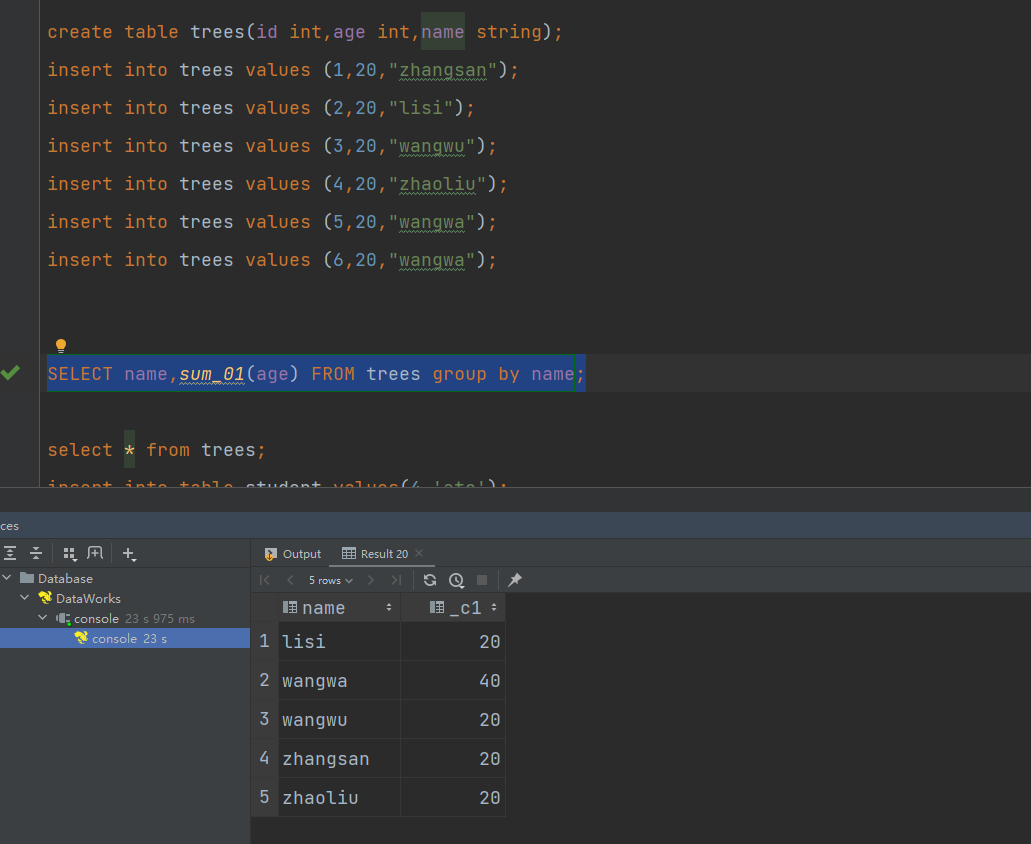
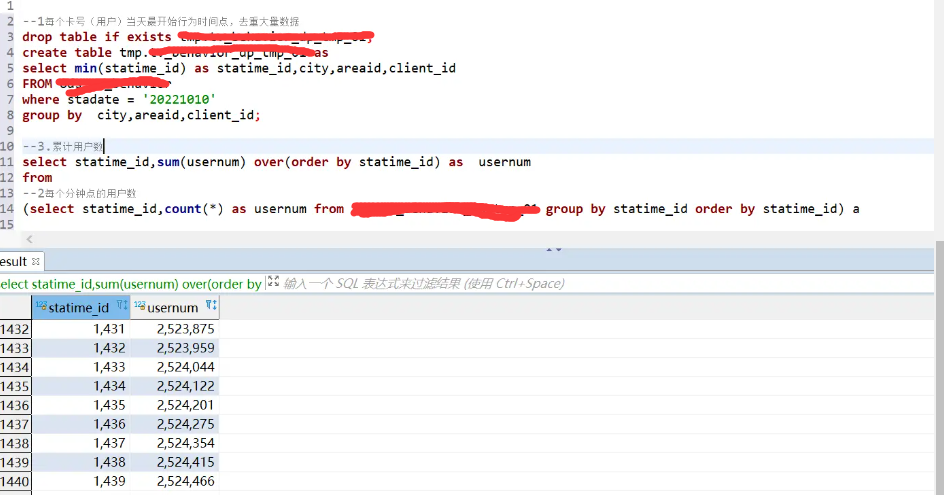
servlet
开发板评测
堆
vsprintf
架构
emmc
cloud alibaba
uni-app
CubeMX
AOE网
gee
python学习资料
aws
mutex
定时同步
策略模式
GDAL
Lambda表达式
族谱
线性分类器
hive
2024/4/11 14:31:04
Hive学习 第四课 创建表并load 数据到表
本章将介绍如何创建一个表以及如何将数据插入。创造表的约定在Hive中非常类似于使用SQL创建表。
CREATE TABLE语句
Create Table是用于在Hive中创建表的语句。语法和示例如下:
语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name…
大数据--hive--经典SQL题目(百度面试SQL题目)
目录 一:题目一:第n多和连续三天思维
1.1 统计近10天每日行为数量
1.1.1 答案:
1.1.2 注意事项:
1.2 行为第三多的用户及其数量
1.2.1 答案
1.2.2 注意事项
1.3 连续3天有行为的用户
1.3.1 思路
1.3.2 答案
1.3.3 注意…
拉链表和快照表的选择
考虑以下因素 数据类型:拉链表适用于存储变化频繁且数量较少的数据,例如日志记录。而快照表适用于存储大量数据。 数据访问需求:如果需要频繁进行查询和更新操作,则拉链表可能更合适。如果只需要读取数据的历史版本,则…

中科网联CCData借助亚马逊云科技实现高效融媒体测量
近年来,随着媒体与广告传媒行业数字化转型向纵深发展,如何利用数据洞察用户生态、实现精准触达以及业务持续创新已成为媒体产业深入发展的“必答题”。与此同时,随着数据应用的不断深入,借助人工智能和机器学习技术,找…
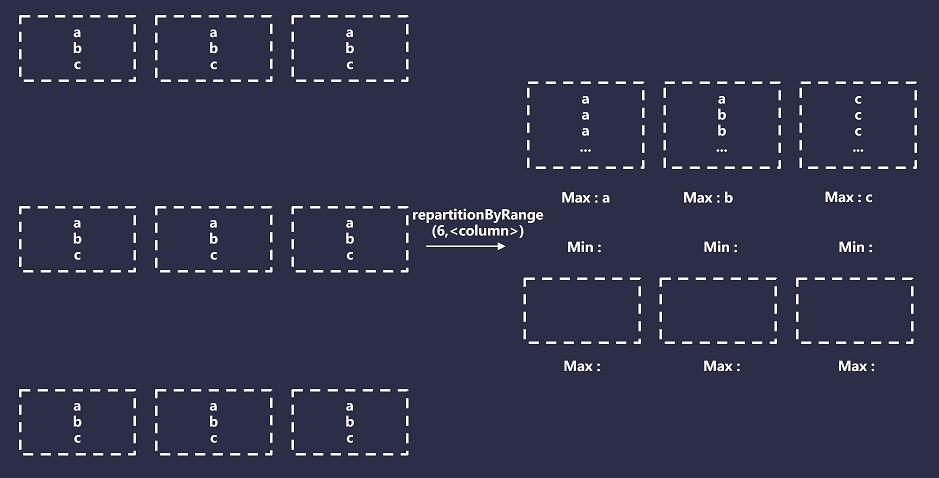
Hive 和 Spark 分区策略剖析
作者:vivo 互联网搜索团队- Deng Jie 随着技术的不断的发展,大数据领域对于海量数据的存储和处理的技术框架越来越多。在离线数据处理生态系统最具代表性的分布式处理引擎当属Hive和Spark,它们在分区策略方面有着一些相似之处,但也…
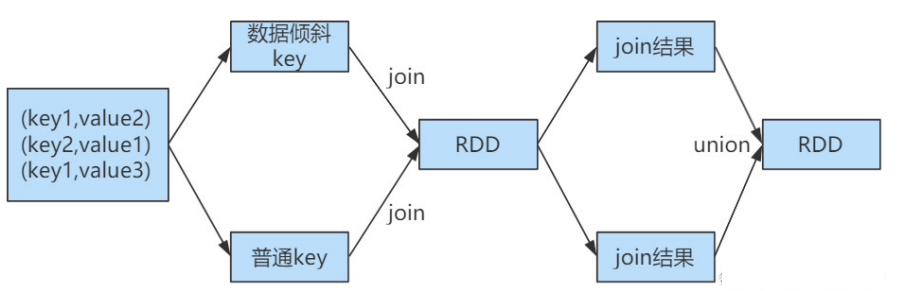
hive/spark数据倾斜解决方案
Hive数据倾斜以及解决方案
1、什么是数据倾斜
数据倾斜主要表现在,mapreduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他…
Hive集成Tez让大象飞起来
[img]http://dl2.iteye.com/upload/attachment/0114/5700/de4b9062-7d61-3ea5-995d-5ae35deb61c0.jpg[/img][sizemedium]
基础环境Apache Hadoop2.7.1
Centos6.5
Apache Hadoop2.7.1
Apache Hbase0.98.12
Apache Hive1.2.1
Apache Tez0.7.0
Apache Pig0.15.0
Apache oozie…
电影票房之数据分析(Hive)--第5关
电影票房之数据分析(Hive)
第5关:统计2020年元旦节与国庆节放假后7天的观影人数
本关任务
基于EduCoder平台提供的初始数据集,统计 2020 年元旦节与国庆节放假后 7 天的观影人数。
编程要求
本实验环境已开启Hadoop服务
在 …
【踩坑】hive脚本笛卡尔积严重降低查询效率问题
前一阵子查看我们公司的大数据平台的离线脚本运行情况, 结果发现有一个任务居然跑了一天多, 要知道这还只是几千万量级的表, 且这个任务是每天需要执行的
于是我把hive脚本捞出来看了下, 发现无非多join了几个复杂的子查询, 应该不至于这么久, 包括我又检查了是不是没有加上每…
7. Hive解析JSON字符串、JSON数组
文章目录 Hive解析JSON字符串1. get_json_object局限性 2. json_tuple Hive解析JSON数组前置知识explode函数regexp_replace函数 1. 嵌套子查询解析JSON数组(使用exploderegexp_replace)2. 使用 lateral view 解析JSON数组 学习链接 Hive解析JSON字符串 …
因mapjoin加载内存溢出而导致return code 3
因mapjoin加载内存溢出而导致return code 3 问题描述:日志定位: 问题描述:
例行Hive作业报错
日志定位:
Starting to launch local task to process map join; maximum memory 5172101120
[2023-10-16 07:56:51,530] - INFO:…
基于Linux安装Hive
Hive安装包下载地址
Index of /dist/hive
上传解压
[rootmaster opt]# cd /usr/local/
[rootmaster local]# tar -zxvf /opt/apache-hive-3.1.2-bin.tar.gz重命名及更改权限
mv apache-hive-3.1.2-bin hivechown -R hadoop:hadoop hive配置环境变量
#编辑配置
vi /etc/pro…
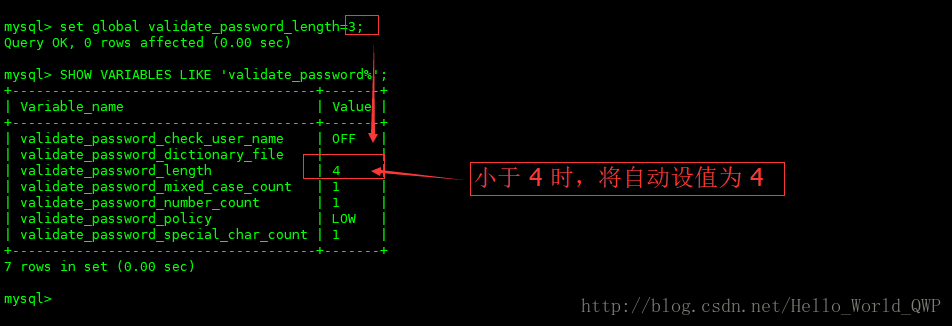
mysql更改密码策略强制更改简单密码
关于这个问题是在 《 基于MySQL Yum存储库在Linux-7.2上安装MySQL-5.7.21数据库服务(实战篇) 》 时遇到的问题,这是 mysql 初始化时,使用临时密码,修改自定义密码时,由于自定义密码比较简单,就…

启动hive遇到Exception in thread main java. lang. Lega LArgumentException:java . net . UnknownHost Excep
Exception in thread main java. lang. Lega LArgumentException:java . net . UnknownHost Exception: master 克隆原集群中的master 作为高性能的单点机器,配置好hdfs ,yarn ,hive文件后 单点集群正常启动,但是hive报错, 解决: 在隐射后面 192.168.226.104 standalone 后面再…
hql创建指定日期表
SELECT DATE_ADD(start_date, pos) dd FROM (SELECT ‘2022-03-01’ AS start_date, ‘2022-03-30’ AS end_date) temp LATERAL VIEW POSEXPLODE(SPLIT(SPACE(DATEDIFF(end_date, start_date)), ‘’)) t AS pos, val

大数据毕业设计选题推荐-热门旅游景点数据分析-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…
Hive建表语法和参数记录
Hive是一个基于Hadoop的数据仓库工具,可以将结构化数据映射到HDFS存储(建表对应在HDFS建了一个文件夹),并提供类SQL查询语言-HiveQL,Hive可以将HQL语句转换为MR任务执行。 本文记录Hive建表的常用语法和参数。
建表语…
![[sqoop]hive导入mysql,其中mysql的列存在默认值列](https://img-blog.csdnimg.cn/7b88c454df43430999a49c43984ea63e.png)
[sqoop]hive导入mysql,其中mysql的列存在默认值列
一、思路
直接在hive表中去掉有默认值的了列,在sqoop导入时,指定非默认值列即可,
二、具体
mysql的表 hive的表
create table dwd.dwd_hk_rcp_literature(id string,literature_no string,authors string,article_title string,source_title string…
springboot hive mysql 多数据源切换
springboot hive mysql 多数据源切换 本次实验重在多数据源切换 性能不在考虑其中 开发环境: hive 3.1.3 mysql 8.0.33 jdk 1.8 maven 3.9.1 idea 2023.1 springboot 2.7.11 HikariCP 连接池 实验效果:从 hive 中迁移数据到 MySQL
pom.xml
<?xml v…
Hive学习---4、函数
1、函数
1.1 函数简介
Hive会将常用的逻辑封装成函数给用户进行使用,类似java中的函数。 好处:避免用户反复写逻辑,可以直接拿来使用 重点:用户需要知道函数叫什么,能做什么
Hive提供了大量的内置函数,按…
python大数据开发学习路线
5个月,精通大数据的必备干货【技术点标记重点】,下方含全套自学 视频源码资料,如果零基础入门数据开发行业的小伙伴从Python语言入手。Python语言简单易懂,适合零基础入门,在编程语言排名上升最快,能完成数…
hive sql,年月日 时分秒格式的数据,以15分钟为时间段,找出每一条数据所在时间段的上下界限时间值(15分钟分区)
获取当前的年月日 时分秒
select date_format(current_timestamp(), yyyy-MM-dd HH:mm:ss)date_format(时间字段, ‘yyyy-MM-dd HH:mm:ss’) 将时间字段转为 2023-10-18 18:14:16 这种格式 在指定时间上增加15分钟
select from_unixtime(unix_timestamp(current_timestamp(…
Hive 作业产生的map数越多越好还是越少越好?
前言
通常情况下,作业会通过input目录产生一个或多个任务。 主要决定因素: input的文件总个数input的文件大小集群设置的文件块大小1. 是不是越多越好呢?
答案:不是! 原因:假如一个任务有很多小文件,并且文件大小远远小于块大小128M(默认值),则每个小文件也会被当作…
19. 统计每日商品1和商品2销量的差值
文章目录 题目需求实现一题目来源 题目需求
从订单明细表(order_detail)中统计每天商品1和商品2销量(件数)的差值(商品1销量-商品2销量)。
期望结果如下:
create_date diff 2020-10-08-24202…
2023.11.16 hivesql之条件函数,case when then
目录 一.Conditional Functions条件函数
二.空值相关函数
三:使用注意事项
3.1 then后面不能接子查询
3.2 then后面只能是结果值
3.3 then后面能不能接两列
四.用于建表新增字段使用场景 一.Conditional Functions条件函数 -- 演示条件函数
-- if(条件判断,t…
Hive中常见的join方式
Hive中除了支持和传统数据库中一样的内关联、左关联、右关联、全关联,还支持LEFT SEMI JOIN和CROSS JOIN,但这两种JOIN类型也可以用前面的代替。
如何实现join?
1)内关联(JOIN) 只返回能关联上的结果。
SELECT a.i…

Hive的安装和配置
文章目录Hive的安装和配置安装HIVE配置先创建用户(备用)修改环境变量配置hive-site.xml文件配置hive-env.sh文件添加MySQL的jar包启动hive总结Hive的安装和配置
安装HIVE
提前准备好安装包上传到linux系统内 输入解压命令:
tar -zxvf hive-1.1.0-cdh5.14.2.tar.…


Zepplin安装使用
文章目录Zepplin安装使用一 下载安装包二 上传并解压三 修改 配置文件四 启动zeppelin五 配置hive解释器5.1 环境和变量配置5.2 在web界面配置集成hive六 使用Zepplin的hive解释器Zepplin安装使用
一 下载安装包
http://zeppelin.apache.org/download.html 选择zeppelin-0.8.…
hadoop测试环境sqoop使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Sqoop看这篇文章就够了_must contain $conditions in where clause._SoWhat1412的博客-CSDN博客 大数据环境 C:\Windows\System32\drivers\etc 修改ip和hostname的对应关系 1…
Conda 安装Jupyter:使用Pyhive(Kerberos)
安装基本环境
conda create -n bigdata python3.10
conda activate bigdata
conda install -y pandas numpy pyhive
yum install gcc-c python-devel.x86_64 cyrus-sasl-devel.x86_64
pip install sasl
Jupyter Notebook
安装jupyter notebook配置自动提示
conda insta…


Spark连接mysql、hive
文章目录Spark连接mysql利用idea工具连接Spark连接hive配置文件启动hive服务通过idea工具连接利用spark-shell连接Spark连接mysql
将mysql-connector包 导入spark/jars/ 路径内
利用idea工具连接
代码如下:
package nj.zb.kb11import org.apache.spark.{SparkC…
Hbase数据映射到Hive
Hbase数据映射到Hive
//新建库 并使用库create database events;use events;//设置变量名为db 指向库名 eventsset hivevar:dbevents;//设置允许所有的分区列都是动态分区列00000000000000000000set hive.exec.dynamic.partition.modenonstrict;//设置允许动态分区功能SET h…
udaf中加载外部文件
加载外部文件:
1.在shell中 要将文件加载进去 使用add file
例如:
hive -e " add file ./pro_data/testfile.txt; add jars $CLASSIFIER_JAR; ...
说明:文件位置在./pro_data目录下 2.java调用时, 文件路径需要改变
例…

利用MapReduce的思想用Hive做词频统计
利用MapReduce的思想用Hive做词频统计
关于mapreduce hive 等的关系大家可以参考这位博主的文章:
1.打开hadoop与hive
start-dfs.sh 或者 start-all.sh
qive或者进到hive安装目录的bin下再输入hive
2.在hive shell下面先建立数据库WordCount ,然后…
☀️☀️基于 Hive 的 SparkSQL 启动流程—Hadoop、MySQL、Hive、Spark
本文目录如下:第1章 基于 Hive 的 SparkSQL 启动流程1.1 启动 Hadoop 集群 (HDFS)1.2 启动 MySQL 服务1.3 启动 Hive 服务1.4 启动 Zookeeper 服务, 配置高可用 (伪分布式模式时启动)1.5 启动 Spark 集群1.6 Hive On Spark 项目实战第1章 基于 Hive 的 SparkSQL 启动…

hivesql 执行顺序与常用函数、表连接、coalesce函数
hivesql 执行顺序与常用函数:
xmind获取链接:https://pan.baidu.com/s/1IppOx-eu17i3mIvYaqZnsA 提取码:iasu 表连接相关笔记: coalesce函数:
coalesce是一个函数,(expression_1,expression_2,…,express…
分布式搭建(hadoop+hive+spark)
地址规划
hadoop-master 192.168.43.141 hadoop-slave1 192.168.43.142 hadoop-slave2 192.168.43.143
核心软件包下载链接
链接:https://pan.baidu.com/s/1OwKLvZAaw8AtVaO_c6mvtw?pwd1234 提取码:1234 MYSQL5.6:wget http://repo.mysql…
实验六:熟悉Hive的基本操作
由于CSDN上传md文件总是会使图片失效 完整的实验文档地址如下: https://download.csdn.net/download/qq_36428822/85709631?spm1001.2014.3001.5501 “大数据技术原理与应用”课程实验报告
题目:实验六:熟悉Hive的基本操作 姓名:…
HIVE 第二章 目录和表
1.目录篇 创建表目录 create database companys create database companys location table create database companys location table with dbproperties(namekedde,data2012-01-02) 查看database信息,无法查看当前表目录 describe database companys describe dat…
HIVE 第三章 表分区
3.表篇分区 不用于关系数据库partition中的字段可以不再table中,但是partition中的字段可以如同table中column一样使用这样可以加快查询速度,因为只用查找一个目下文件就可以了这里分区分为单分区partition一个column,多分区partition多个col…
Hive的full join
sql里面把某段获取到的最大时间当变量,可 full join where 11 把那段时间数据(select max(dt))放入表中使用再处理
Hive - distinct group by 求 UV,PV 实战
一.引言 给定数据表中包含用户 uid 和用户是否点击广告的标签 label,经常有需求统计用户的下发,打开 UV,PV,下面通过 Hive 实现统计并分析 distinct 与 group by 的性能与使用场景。 一.Distinct & 未分组
使用 distinct 计算用户打开的…
Hive 任务调优实践总结
一、背景:
最近由于要回刷数据
调优前: map数:30000 单个map 运行7-8分钟
reduce数:50 单个reduce 运行了20h 还没完成,还经常失败
整体耗时20多个小时还没有完成并且失败了,明显数据倾斜reduce 某个节点跑很久出…

用户画像系列——数据中台之OneID (ID-Mapping)核心架构设计
一.引言
大家在上网的过程中是不是经常有这样的体验,我在百度(或者京东、淘宝)上搜索一件商品(比如说:我搜索了一台iphone 手机看了看,但是没买),奇怪的是过两天,我竟然在某视频平台或者某网页上又看到了它࿱…
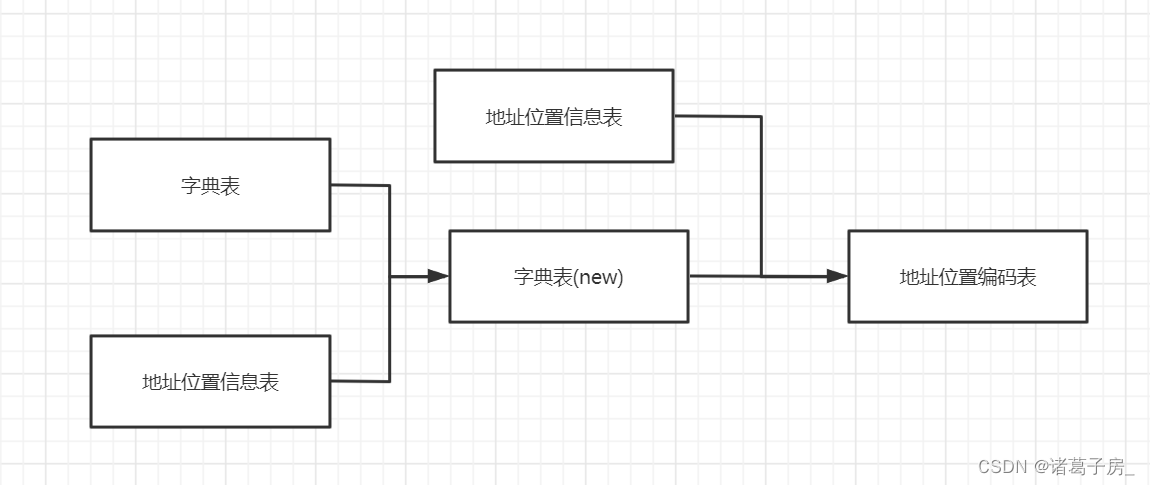
离线表数据敏感字段自动id化处理
一、背景
对于一些表数据包含的铭感字段需要id 化处理,比如说:用户搜索了某个关键词,或者用户的购物地址是某个城市,这种都需要进行模糊化处理,但是直接模糊化处理不利于使用,比如说:在三四线城…

Hive学习 第一课
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 Hive 不是
一个关系数据库一个设计用于联机事务处…
同事写了一个update,误用一个双引号,生产数据全变0了!
来源:fordba.com/mysql-double-quotation-marks-accident.html一、前言最近经常碰到开发误删除误更新数据,这不,他们又给我找了个麻烦,我们来看下整个过程。二、过程由于开发需要在生产环节中修复数据,需要执行120条SQ…

Hive - 增删改 Hive 表字段
一.引言
使用 Hive 表时由于数据的变换经常需要调整 Hive 表字段结构,这里记录一下常用方法。先创建一个测试表 tmp_change_column,包含两个字段 a,b 和分区标识 dt :
function createTable() {
hive -e "
create table if not exists…
使用元数据服务的方式访问Hive报Exception in thread “main“ org.apache.thrift.transport.TTransportException: Could n
目录参考链接参考链接
org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9083.
Hive面试题系列第一题-连续登录问题
视频讲解地址:https://www.bilibili.com/video/BV1iV4y1x7yo?spm_id_from333.999.0.0&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第一题-连续登录问题 题目:求连续7天登录的用户 表结构:
CREATE TABLE logtable( uid int, dt s…
Hive面试题系列第三题-用户留存问题
视频讲解地址:https://www.bilibili.com/video/BV1Rd4y1T7iU/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第三题-用户留存问题
题目:求用户1日、3日、7日留存率 概念问题: 第N日活跃用户留存率&am…
Hive面试题系列第七题-同时在线问题
视频讲解地址: https://www.bilibili.com/video/BV1Tg411r7Jz/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第七题-同时在线问题 题目:计算主播最高同时在线人数(pcu) 表结构:
create t…
maven 3.8.1 引用hive-service报错Could not find artifact org.pentaho:pentaho-aggdesigner问题
环境
: maven 版本:3.8.1 java 版本:1.8 pom 引入:
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-service</artifactId><version>2.3.3</version>
</dependency> 有其他人报这个错误:Could not find ar…


HIVE中UDF的使用
1)创建Maven工程 2)项目pom.xml文件中添加hive的依赖。 <dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>2.3.8</version></dependency>
3) 创建类BaseFi…

大数据项目实战---电商埋点日志分析(第四部分,DWD层深度解析)
1)创建加载表dwd_display_log 2)创建加载表dwd_newsdetail_log 3)创建加载表dwd_loading_log 4)创建加载表dwd_ad_log 5)创建加载表dwd_notification_log 6)创建加载表dwd_for_activity_log 7)创…

【DBeaver】驱动添加-Hive和星环
驱动
Hive驱动
hive驱动可以直接去官网下载官网地址,填一下个人信息。
如果想直接下载可以去我上次的资源下地址,需要用zip解压。
星环驱动
星环驱动是我第一次接触,是国产的基于开源Hive驱动自研的产品,我看到官网上有很多类…
hive on spark 测试
[sizemedium]
基础环境:Apache Hadoop2.7.1
Centos6.5
Apache Hadoop2.7.1
Apache Hbase0.98.12
Apache Hive1.2.1
Apache Tez0.7.0
Apache Pig0.15.0
Apache oozie4.2.0
Apache Spark1.6.0
Cloudrea Hue3.8.1 经测试,spark1.6.0和spark1.5.x集成…
hive建分区表,分桶表,内部表,外部表
hive建分区表,分桶表,内部表,外部表
一、概念介绍
Hive是基于Hadoop的一个工具,用来帮助不熟悉 MapReduce的人使用SQL对存储在Hadoop中的大规模数据进行数据提取、转化、加载。Hive数据仓库工具能将结构化的数据文件映射为一张数…

Spark SQL+Hive历险记
基础依赖环境 Apache Hadoop2.7.1 Apache Spark1.6.0 Apache Hive1.2.1 Apache Hbase0.98.12 (1)提前安装好scala的版本,我这里是2.11.7 (2)下载spark-1.6.0源码,解压进入根目录编译 (…
[Hive] 查询结果保存
文章目录 1.插入新表追加 2.插入hdfs文件系统 1.插入新表
使用INSERT OVERWRITE语句的情况:
整个表:可以使用INSERT OVERWRITE TABLE table_name语句将查询结果直接覆盖整个表中的数据。
INSERT OVERWRITE TABLE table_name
SELECT * FROM ...特定分区…
GZ033 大数据应用开发赛题第08套
2023年全国职业院校技能大赛 赛题第08套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …
开源大数据索引项目hive-solr
github地址:https://github.com/qindongliang/hive-solr 欢迎大家fork和使用 关于这个项目的介绍,请参考散仙前面的文章: http://qindongliang.iteye.com/blog/2283862 最新更新: (1)添加了对solrcl…
Apache Tez0.7编译笔记
[img]http://dl2.iteye.com/upload/attachment/0114/5711/86f2acad-6ad7-3822-b59f-8c24335265f7.png[/img]
[sizemedium]
目前最新的Tez版本是0.8,但还不是稳定版,所以大家还是先下载0.7用吧
下载地址: wget http://archive.apache.org/dist…
c# string填充空格_C#| 使用String.Format()方法在浮点数(左对齐)的左侧填充空格
c# string填充空格To align a float number with spaces, we can use String.Format() in C#, here is the example. 为了使浮点数与空格对齐,我们可以在C#中使用String.Format(),这是示例。 using System;namespace ConsoleApplication1{cl…
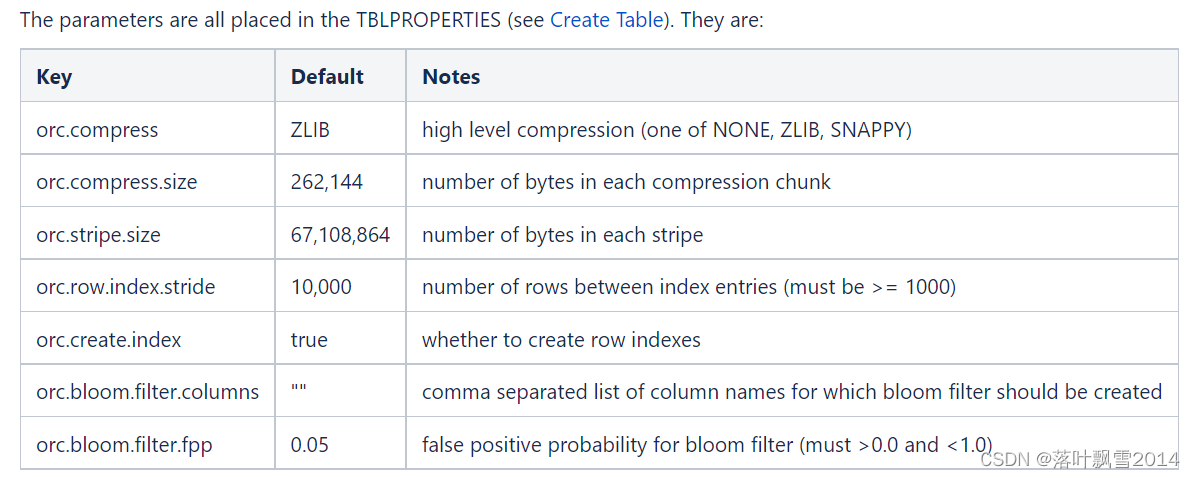
Hive之存储和压缩
Hive系列 第十章 存储和压缩
10.1 首先看一下Hadoop中的压缩
10.1.1 基本概念
1、概念
压缩是一种通过特定的算法来减小计算机文件大小的机制。这种机制是一种很方便的发明,尤其是对网络用户,因为它可以减小文件的字节总数,使文件能够通过…

Hive安装配置 - 内嵌模式
文章目录 一、Hive运行模式二、安装配置内嵌模式Hive(一)下载hive安装包(二)上传hive安装包(三)解压缩hive安装包(四)配置hive环境变量(五)关联Hadoop&#x…
educoder中Hive综合应用案例 — 学生成绩查询
第1关:计算每个班的语文总成绩和数学总成绩
---------- 禁止修改 ----------drop database if exists mydb cascade;set hive.auto.convert.join = false;
set hive.ignore.mapjoin.hint=false;
---------- 禁止修改 ----------
---------- begin ----------
---创建mydb数据…
干翻Hadoop系列之:Hadoop、Hive、Spark的区别和联系
第一章:Hadoop和Hive以及Spark的关系是什么?
Hadoop和Hive、Spark都是大数据领域的技术栈。
一:大数据领域当中以后两个最为核心的问题
1:数据怎么存储 2:海量数据怎么计算
单机系统时代。 所有数据都在一个计算机…
Trino 与Hive 有差异的函数
日常使用中发现trino和hive中的有一些函数存在差异,所以开此帖记录一下 这里只是记录trino和hive有差异的函数,遇到了就会记录一下,不定期更新
1. 查看集合中元素个数
hive:size() trino:cardinality()
2. map取值 …
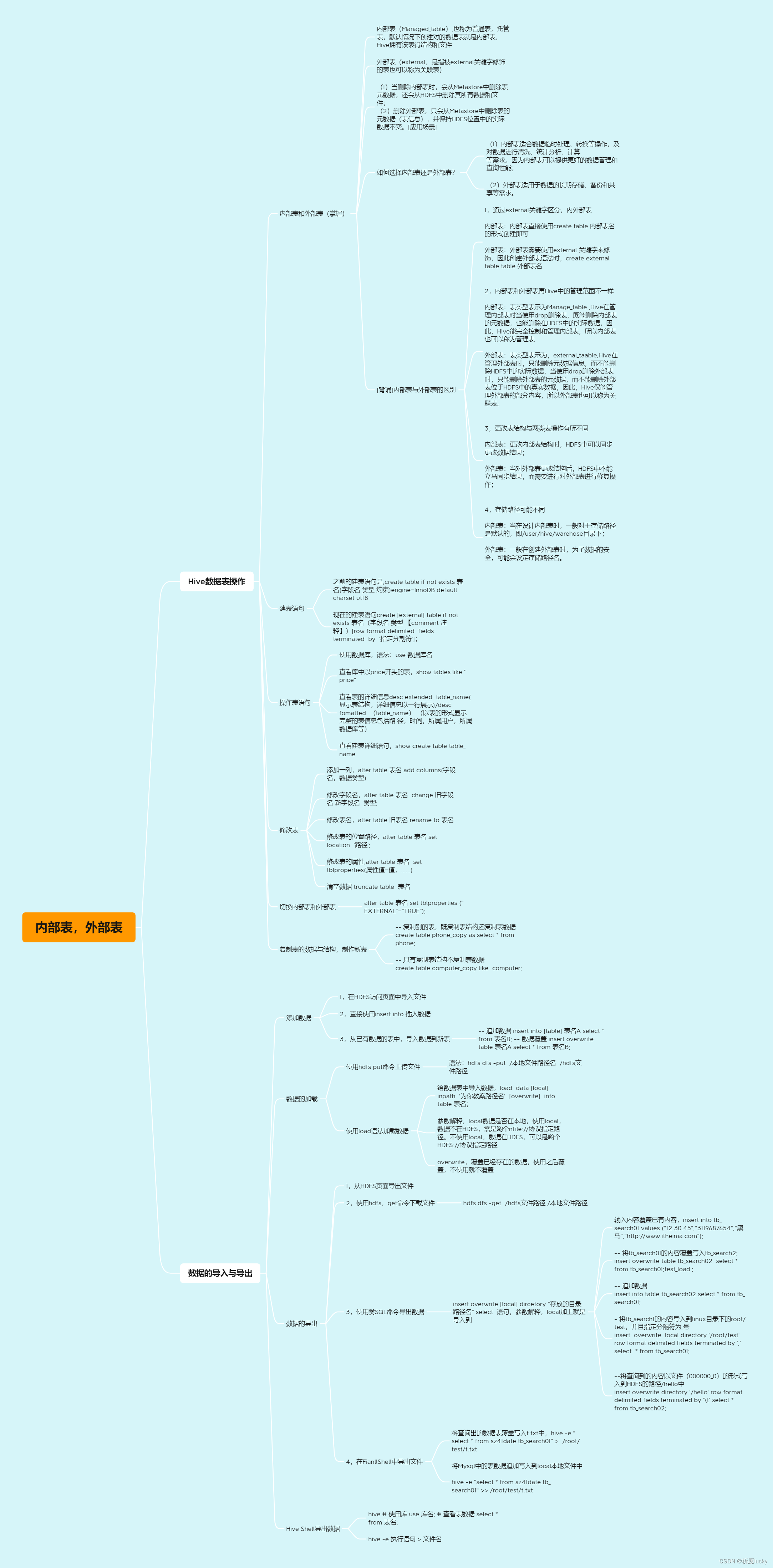
Hive数据表操作--学习笔记
1,Hive数据表操作
1,建表语句和内外部表 ①创建内部表
create [external] table [if not exists] 表名(
字段名 字段类型 [comment 注释],
字段名 字段类型 [comment 注释],
...
)
[row format delimited
fields terminated by 指定分隔符];࿰…
【Python 千题 —— 基础篇】减法计算
题目描述
题目描述
编写一个程序,接受用户输入的两个数字,然后计算这两个数字的差,并输出结果。
输入描述
输入两个数字,用回车隔开两个数字。
输出描述
程序将计算这两个数字的差,并输出结果。
示例
示例 ① …
[Hive] CTE 通用表达式 WITH关键字
在Hive中,CTE代表的是Common Table Expression(通用表达式),这是一种SQL语句结构,使用WITH关键字定义的子句。
CTE
CTE提供了一种在查询中定义临时结果集的方式,以便后续查询可以引用这些临时结果集&…
win10用jdbc连接hive遇到的问题
目录
背景
error starting hiveServer2
java.lang.NoSuchMethodError: org.eclipse.jetty.server.Server.setThreadPool(Lorg/eclipse/jetty/util/thread/ThreadPool;)V
ConnectionException:Call from ... to localhost:10000 failed on connection exception:Connection …

分布式数据恢复-hbase+hive分布式存储误删除如何恢复数据?
hbasehive分布式存储数据恢复环境: 16台某品牌R730XD服务器节点,每台物理服务器节点上有数台虚拟机,虚拟机上配置的分布式,上层部署hbase数据库hive数据仓库。
hbasehive分布式存储故障&初检: 数据库文件被误删除…
【Hive 基础】-- 数据倾斜
1.什么是数据倾斜?由于数据分布不均匀,导致大量数据集中到一点,造成数据热点。常见现象:一个 hive sql 有100个 map/reducer task, 有一个运行了 20分钟,其他99个 task 只运行了 1分钟。2.产生数据倾斜的原…
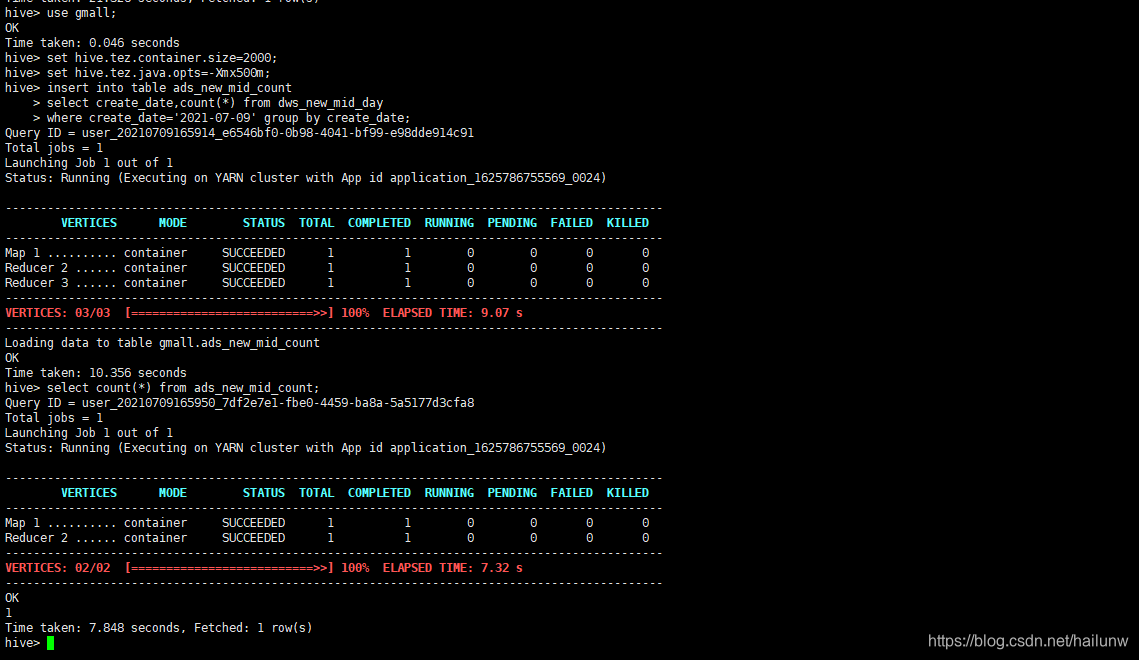
大数据项目实战---电商埋点日志分析(第七部分,每日新增设备主题(DWS层+ADS层)
1)创建设备按天明细表,dws_new_mid_day并加载数据。 2)创建每日新增设备表,ads_new_mid_count并加载数据。 下一章 https://blog.csdn.net/hailunw/article/details/118611510
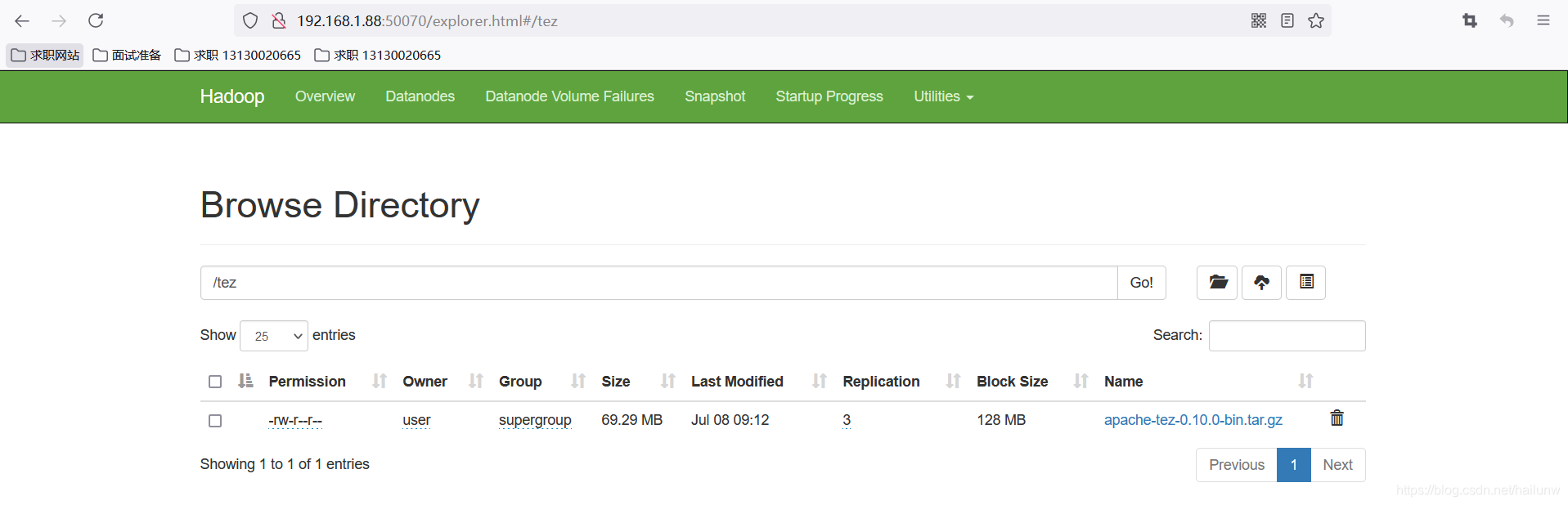
Tez的简介以及安装配置
Tez简介
Tez是一个Hive的运行引擎,由于没有中间存盘的过程,性能优于MR。Tez可以将多个依赖作业转换成一个作业,这样只需要写一次HDFS,中间节点少,提高作业的计算性能。 Tez的安装步骤
1)下载安装包到hive所在的66服务…

Hive 中数据仓库默认位置配置及库表关系
1、原始位置的默认配置
hive中的Default(默认)数据仓库的最原始位置是在hdfs上的 /user/hive/warehouse(以下默认Hive的HDFS根目录为/user/hive)路径下,这个原始位置是本地的/usr/local/hive/conf/hive-default.xml.t…
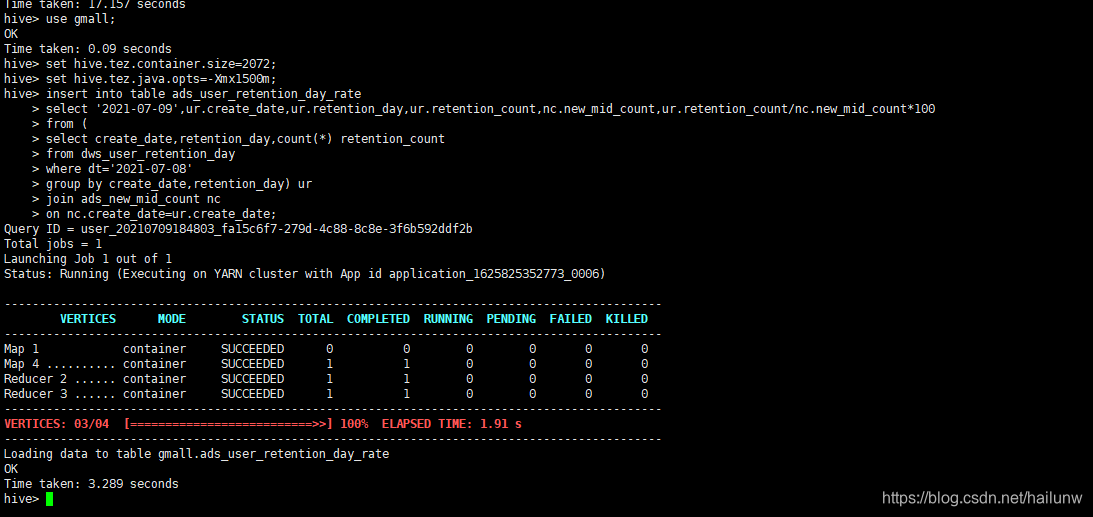
大数据项目实战---电商埋点日志分析(第八部分,用户留存主题(DWS层+ADS层)
1)创建每日留存用户明细表dws_user_retention_day并加载数据。 2)创建每日留存用户数表ads_user_retention_day_count并加载数据。 3)创建每日留存用户比例表ads_user_retention_day_rate并加载数据 为了能够尽快地找到新工作,这个项目先到这…

大数据项目实战---电商埋点日志分析(第六部分,ADS层之用户活跃主题)
大数据项目实战---电商埋点日志分析(第六部分,ADS层之用户活跃主题)
创建用户活跃汇总表ads_uv_account并加载数据。 下一章 https://blog.csdn.net/hailunw/article/details/118609254
Hive中常出现的错误(不定时更新)
1.加载数据失败 hive> load data local inpath /home/user/hive.txt into table studentl> ;
FAILED: SemanticException [Error 10001]: Line 1:56 Table not found studentl
hive> load data local inpath /home/user/hive.txt into table student;
Loading data to…


hive查询语句中的常见错误
1、case when --else end 语句中忘记写end,或者忘记把整个字句用as起别名,因为一个字段如果用case when条件语句计算后就是已经生成新的字段了,不能再用以前的字段名称。例如:
原来的字段是age,他的值是连续的int&…
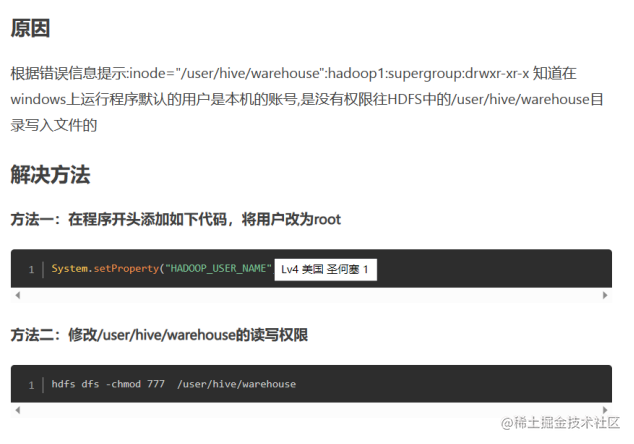
解决spark程序 Permission denied: user=<username>, access=WRITE...等常见hive权限报错
Permission Denied
Permission Denied: 这是最常见的错误消息之一,表示当前用户没有足够的权限执行写入操作。报错信息可能类似于: org.apache.hadoop.security.AccessControlException: Permission denied: user<username>, accessWRITE, inode&…
大数据数仓建模基础理论【维度表、事实表、数仓分层及示例】
文章目录 什么是数仓仓库建模?ER 模型三范式 维度建模事实表事实表类型 维度表维度表类型 数仓分层ODS 源数据层ODS 层表示例 DWD 明细数据层DWD 层表示例 DIM 公共维度层DIM 层表示例 DWS 数据汇总层DWS 层表数据 ADS 数据应用层ADS 层接口示例 数仓分层的优势 什么…
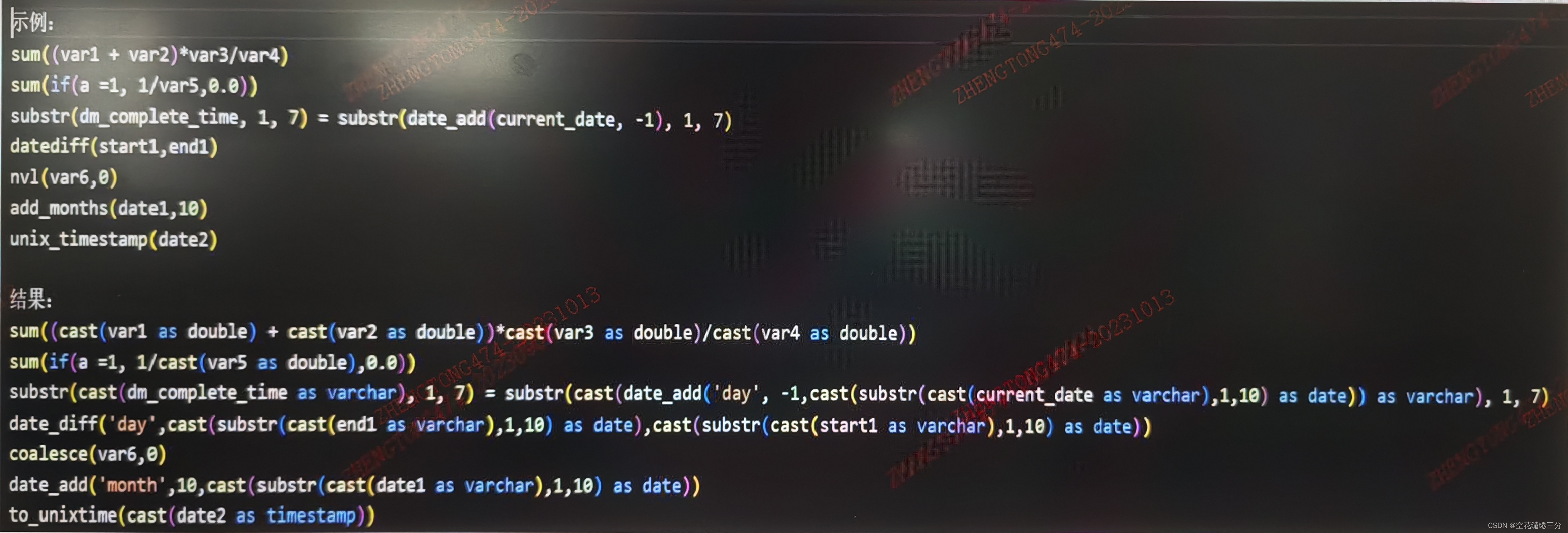
数据库:Hive转Presto(五)
此篇将所有代码都补充完了,之前发现有的代码写错了,以这篇为准,以下为完整代码,如果发现我有什么考虑不周的地方,可以评论提建议,感谢。代码是想哪写哪,可能比较繁琐,还需要优化。
…
2023.11.12 hive中分区表,分桶表与区别
1.分区表 分区表的本质就是在分目录
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。…

Hive数据库动态分区和静态分区插入区别
Hive数据库的动态分区插入和静态分区插入区别用法如下: 动态分区:不需要人为使用alter table命令执行添加分区,分区不固定,关键在于“动态”,根据数据集的字段给动态的生成分区。它是在SQL执行的时候确定的。分区前需打…

Apache Hive3.1.3 遇到DATE_FORMAT转换2021年12月格式的问题
比如:需要将时间2021-12-28 00:00:00转换成2021-12的格式,用date_format会将2021-12转换成2022-12的问题。
解决方法:
方式一:大写的‘Y’换成‘y’ 方式二:字符串截取,substr
本博主推荐方式一…
Hive(17):Hive Show显示语法
Show相关的语句提供了一种查询Hive metastore的方法。可以帮助用户查询相关信息。
1 显示所有数据库 SCHEMAS和DATABASES的用法 功能一样
show databases;
show schemas; 2 显示当前数据库所有表/视图/物化视图/分区/索引
show tables;
SHOW TABLES [IN database_name]; --指…
hive metastore元数据同步无效分区清理
通过获取hive元数据,查询数据表,批量[MSCK] REPAIR TABLE table_identifier [{ADD|DROP|SYNC} PARTITIONS] #!/usr/bin/env bash
dir_path"/tmp/hive_meta_clean"
mkdir -p ${dir_path}
database_list_file"${dir_path}/database_list.cs…
Hive on Zeppelin
**
Hive on Zeppelin
**
官网:zeppelin.apache.org
做大数据的人应该对Hive不陌生,Hive应该是大数据SQL引擎的鼻祖。历经多个版本的改进,现在的Hive3已经具备比较完善的ACID功能,能够同时满足交互式查询和ETL 两种场景。 那怎…
java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are un
创建于:2022.06.13 修改于:2022.06.13
尝试用本地pySpark读取远程的hive数据时候出现的问题。
本地需要安装配置hadoop的环境变量,把hadoop.dll放到system32中。 关于IDEA出现报错: java.io.FileNotFoundException: HADOOP_HOME…


CDH-Flume从Kafka同步数据到hive
启动Flume命令
flume-ng agent -n a -c /opt/cloudera/parcels/CDH-6.3.0-1.cdh6.3.0.p0.1279813/lib/flume-ng/conf/ -f ./kafka2hiveTest.conf -Dflume.root.loggerINFO,console hive建表 语句
#分桶开启事务并分区
create table log_test(ip string,username string,reque…
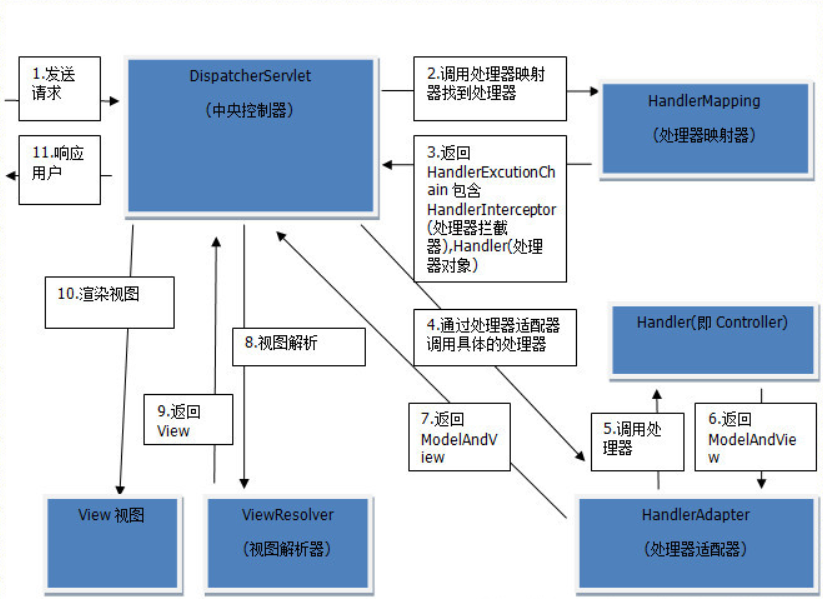
二、编写第一个 Spring MVC 程序(总结项目报 404 问题以及 Spring MVC 的执行流程)
文章目录 一、编写第一个 Spring MVC 程序二、项目运行时报 404错误原因总结三、Spring MVC 的执行流程 一、编写第一个 Spring MVC 程序 创建 maven 项目,以此项目为父项目,在父项目的 pom.xml 中导入相关依赖 <dependencies><dependency…
hive中的group by分组查询注意和其他其他传统关系数据库sql的区别
顾名思义就是按照指定的一个或者多个字段就行分组查询,返回每个组的相关值,group by时常与聚合函数结合使用,
这里需要注意的是,
1、在hive中, 一旦有group by子句,那么,在select子句中只能有…

大数据毕业设计选题推荐-消防监控平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
Hive - Count Sum 使用与性能对比
一.引言
使用 hive 计数时常使用 Count 和 Sum 两个函数进行统计,下面看看二者的使用方法。 二.Count
count 方法可以统计有效行数
1.统计所有行数
select count(*) from table
2.统计不为null的行数
select count(col) from table
3.配合 case distinct 使用…
pg库的with recursive递归,oracle的connect by,Hive递归思路
开发有需求,说需要对一张地区表进行递归查询,Postgres中有个 with recursive的查询方式,可以满足递归查询(一般>=2层)。 测试如下:
create table tb(id varchar(3) , pid varchar(3) , name varchar(10)); insert into tb values(002 , 0 , 浙江省);
insert into tb v…

E044-服务漏洞利用及加固-利用redis未授权访问漏洞进行提权
任务实施:
E044-服务漏洞利用及加固-利用redis未授权访问漏洞进行提权
任务环境说明:
服务器场景:p9_kali-6(用户名:root;密码:toor)
服务器场景操作系统:Kali Linux 192.168.3…
hive substr用法
hive substr用法
substr(string A, int start, int len) 其中start大於0,表示從前往后取數據,start小於0,表示從後往前取數據 if(matnr like 0000000000%, substring(matnr, -8), matnr) matnr,取倒數8個數 if(matnr like 0000000000%, subs…
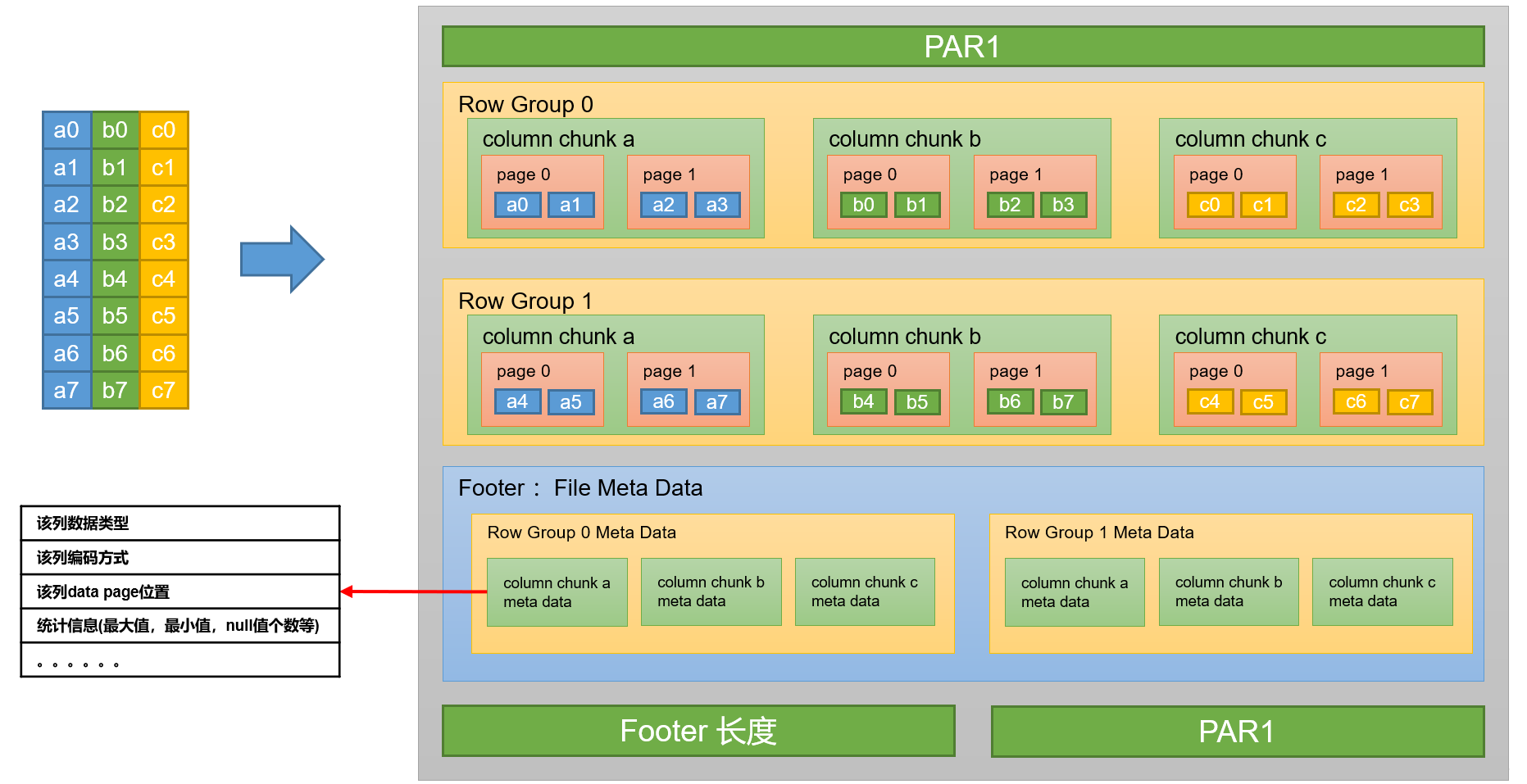
简单理解parquet文件格式——按列存储和元数据存储
简介
Apache Parquet是一种常见的列式存储文件格式,常用于Pig, Spark, Hive等大数据组件中,其后缀是.parquet。
核心特点有:
跨平台可被各种文件系统识别的格式按列存储数据存储元数据
下面详细介绍第3、4个特点。
列式存储
假设有以下…
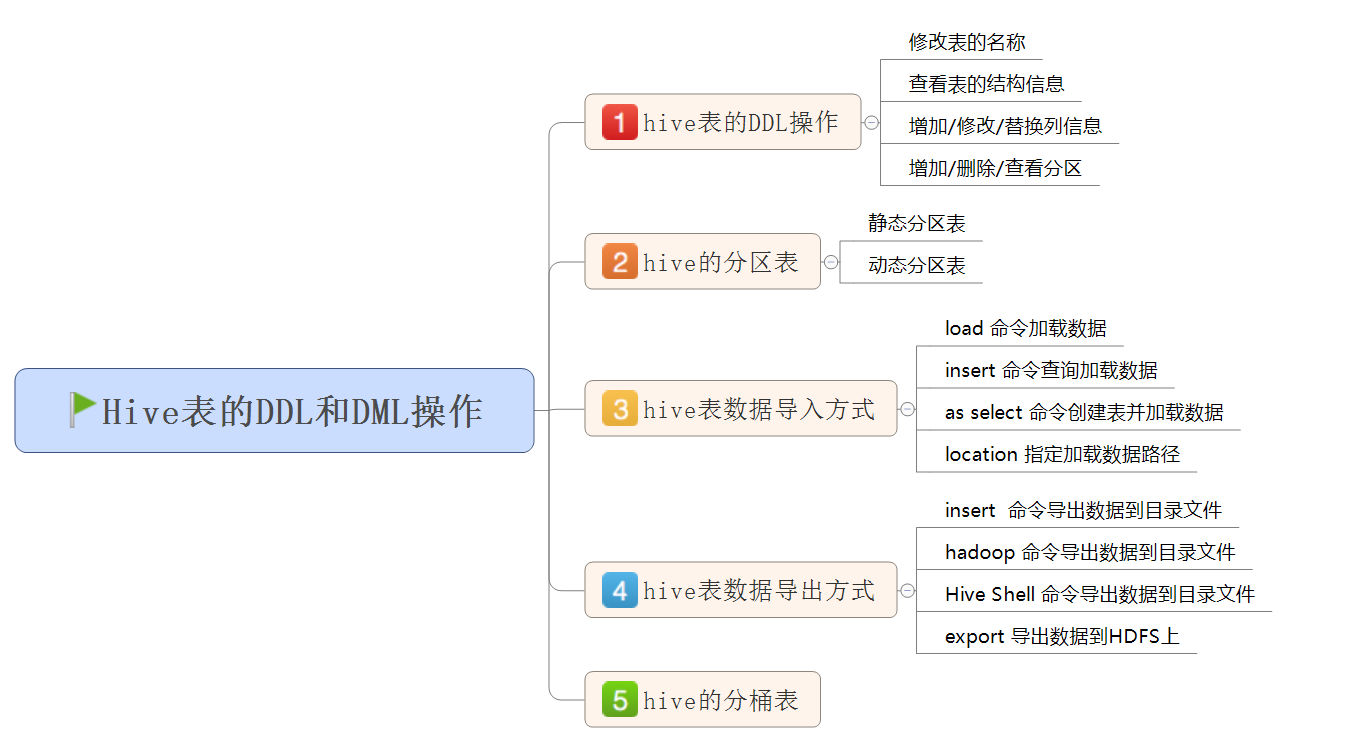
大数据学习:hive的DQL和DML操作
hive的DQL和DML操作
1. Hive的分桶表 1.1 分桶表原理 分桶是相对分区进行更细粒度的划分 Hive表或分区表可进一步的分桶 分桶将整个数据内容按照某列取hash值,对桶的个数取模的方式决定该条记录存放在哪个桶当中;具有相同hash值的数据进入到同一个文件…
Hive 窗口函数超详细教程
Hive 窗口函数 前言1. 窗口函数1.1 聚合窗口函数1.2 分析窗口函数1.3 取值窗口函数2. 综合案例分析2.1 案例1:连续出现的数字2.2 案例2:连续3天交易的用户总结前言
在SQL开发中,有时我们可以使用聚合函数将多行数据按照规则聚集在一行,但是我们又想同时得到聚合前的数据,…
hive修改inputformat
ALTER TABLE table_name [PARTITION partitionSpec] SET FILEFORMAT file_format 分区和表都会存储了文件格式,都要改过来才正确。。 例子: ALTER TABLE foo SET FILEFORMATINPUTFORMAT “com.hadoop.mapred.DeprecatedLzoTextInputFormat”OUTPUTFORMAT…

Hive 的函数介绍
目录
编辑
一、内置运算符
1.1 关系运算符
1.2算术运算符
1.3逻辑运算符
1.4复杂类型函数
1.5对复杂类型函数操作
二、内置函数
2.1数学函数
2.2收集函数
2.3类型转换函数
2.4日期函数
2.5条件函数
2.6字符函数
三、内置的聚合函数
四、内置表生成函数
五、…
Hive学习第三课 创建数据库和删除数据库
Hive是一种数据库技术,可以定义数据库和表来分析结构化数据。主题结构化数据分析是以表方式存储数据,并通过查询来分析。本章介绍如何创建Hive 数据库。配置单元包含一个名为 default 默认的数据库。
CREATE DATABASE语句
创建数据库是用来创建数据库在…
您应该知道的101个大数据术语
由于每天都会产生大量的数据,因此了解大数据的复杂性变得至关重要。如果您打算进入大数据星球,则应该熟悉大数据术语。这些术语将帮助您深入了解大数据世界。因此,让我们从术语大数据本身开始-
由于业务专业人员,项目,…

sublime+python+hive
安装Python、安装pip
安装sublime、配置sublime
Package Control
SublimeREPL(使可以进行交互,例如input)
tools–>build system–>new build system–>修改为如下代码–>保存(例如命名为python3.8)
…

大数据之hive实践一(基础)
预知识
数据仓库
数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成 的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant &#…

大数据之hive实践二(DDL+DML+查询+函数)
第 4 章 DDL 数据定义
4.1 创建数据库
1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db。 hive (default)> create datbase db_hive; 2)避免要创建的数据库已经存在错误,增加 if not exist 判断…
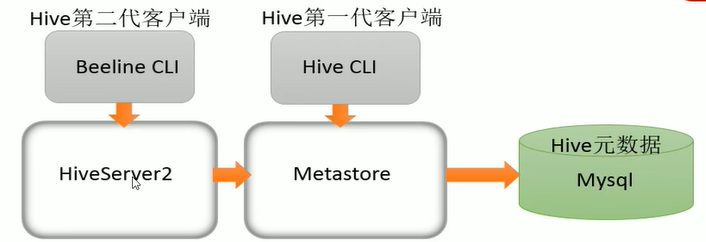
2.Apache Hive
Apache Hive概述 Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hivev查询语言(HQL)…

Hive是如何让MapReduce实现SQL操作的
之前我们说过了MapReduce的运算流程,整体架构方法,JobTracker与TaskTracker之间的通信协调关系等等,但是虽然我们知道了,自己只需要完成Map和Reduce 就可以完成整个MapReduce运算了,但是很多人还是习惯用sql进行数据分…
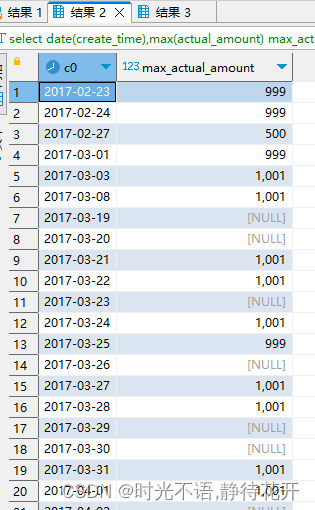
explain 实战-----查看hive sql执行计划
目录 1.join/left join/full join 语句会过滤关联字段 null 的值吗?
(1)join
(2) left join /full join
2.group by 分组语句会进行排序吗? 1.join/left join/full join 语句会过滤关联字段 null 的值吗…

SQL方式对hudi表进行操作
插入数据
查询数据
更新数据
删除数据
覆盖数据
修改表结构
修改分区 插入数据 默认情况下,如果提供了preCombineKey,则insert into的写操作类型为upsert,否则使用insert。
向非分区表插入数据
insert into hudi_cow_nonpcf_tbl sel…
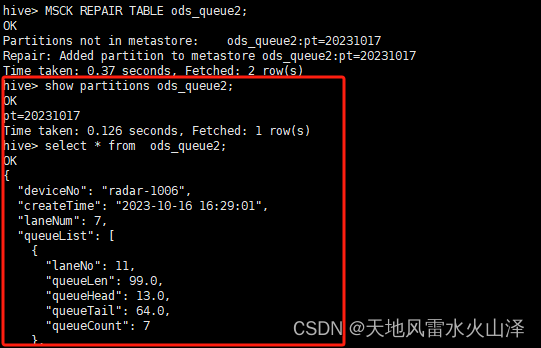
一百九十、Hive——Hive刷新分区MSCK REPAIR TABLE
一、目的
在用Flume采集Kafka中的数据直接写入Hive的ODS层静态分区表后,需要刷新表,才能导入分区和数据。原因很简单,就是Hive表缺乏分区的元数据
二、实施步骤
(一)问题——在Flume采集Kafka中的数据写入HDFS后&am…
hive表小文件合并
1. 背景
公司的 hive 表中的数据是通过 flink sql 程序,从 kafka 读取,然后写入 hive 的,为了数据能够被及时可读,我设置了 flink sql 程序的 checkpoint 时间为 1 分钟,因此,在 hive 表对应的 hdfs 上&am…
使用Core ORC API的VectorizedRowBatch 读取ORC文件详解
本文针对使用Core ORC API的VectorizedRowBatch 读取ORC文件详解,并给出详细的示例源代码
Vectorized Row Batch
数据作为包含1024行数据的VectorizedRowBatch实例传递给ORC。重点在于速度和直接访问数据字段。cols是ColumnVector的数组,size是行数。
抽象类 ColumnVector…
Hive 分区表和分桶表
前言
在《Hive 建表语句解析》文章中,建表的时候我们可以使用 PARTITIONED BY 子句和 CLUSTERED BY 子句来创建分区表和分桶表,为什么要创建分区表和分桶表呢?分区表和分桶表有什么区别呢?
分区表
1. 为什么分区
在Hive 查询中一般会扫描整个表内容,会消耗很多时间做没…
hive sql优化
一、 Hive join优化1. 尽量将小表放在join的左边,我们这边使用的hive-0.12.0,所以是自动转化的,既把小表自动装入内存,执行map side join(性能好), 这是由参数hive.auto.convert.jointrue 和hive.smalltable.filesize25000000L&#…

Hive自定义函数理论知识总结
文章目录Hive自定义函数理论知识总结1、普通UDF2、复制类型的UDF:3、聚合函数:GenericUDAF4、表生成函数:GenericUDTFHive自定义函数理论知识总结
1、普通UDF
单行输入(基本类型) --> 输出一个结果 继承UDF,提供evaluate()
…

Hive学习 第二课 hive安装
第1步:验证JAVA安装
在Hive安装之前,Java必须在系统上已经安装。使用下面的命令来验证是否已经安装Java:
$ java –version
如果Java已经安装在系统上,就可以看到如下回应:
java version "1.7.0_71"
Ja…
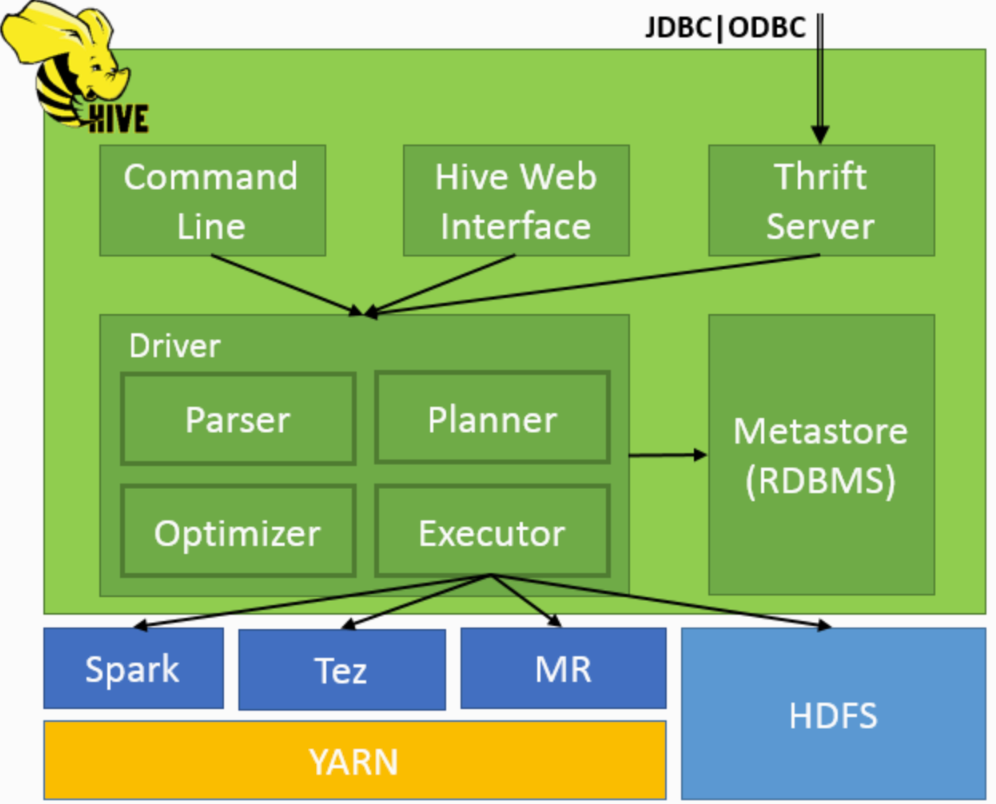
001 hive简介
一. hive概述
1. hive的产生背景
mapreduce程序大部分解决的问题是结构化数据,而解决结构化数据最佳方案是一条sql语句
hive出现的主要原因是解决mapreduce开发成本高的问题。但hive不能完全替代mr,只能处理mr中的结构化数据。 2. hive是什么
hive提…
Hive自定义函数 - Java的一个例子
基础信息参照:Hive 自定义函数 - Java和Python的详细实现
一 需求 对手机号进行脱敏处理,将中间4位数字替换成**** 对数据格式进行判断:11位数字对于格式正确的数据,将中间4位数字替换成****对于格式不正确的数据,将原…

每天一道大厂SQL题【Day20】华泰证券真题实战(二)表转置
每天一道大厂SQL题【Day20】华泰证券真题实战(二)
大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题&…

大数据毕业设计选题推荐-设备环境监测平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…

SparkSQL-liunx系统Spark连接Hive
目录
先来到spark312的jar包存放目录中:
复制jar包到该目录:
来到conf目录: 把hive312/conf中的hive-site.xml复制到spark312/conf目录下: 修改hive-site.xml文件:下面是里面的所有配置
配置完成,开始测试…
详细解释HiveSQL执行计划
一、前言
Hive SQL的执行计划描述SQL实际执行的整体轮廓,通过执行计划能了解SQL程序在转换成相应计算引擎的执行逻辑,掌握了执行逻辑也就能更好地把握程序出现的瓶颈点,从而能够实现更有针对性的优化。此外还能帮助开发者识别看似等价的SQL其…

hiveq sql语句的三种执行方式
hive脚本的三种执行方式
1. hive控制台交互式执行;2. hive -e "SQL"执行;或者 hive -S -e " sql" ,加了-S表示静音模式,即不会显示mapreduce的操作过程。 这种方式直接在bash shell终端里边输入 hive -e "SQL&q…
hive自定义函数及案例
一.自定义函数
1.Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2.当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。
3.根据用户自定义…

hive分桶抽样查询
分桶抽样查询 对于非常大的数据集,需要使用的是具有代表性的查询结果而不是全部。Hive可以通过对表进行分桶抽样来满足这个需求。
查询表stu_buck中的数据
hive (stu)> select * from stu_buck tablesample(bucket 1 out of 4 on id);tablesample
tablesample…
Hive VS Spark
spark是一个计算引擎,hive是一个存储框架。他们之间的关系就像发动机组与加油站之间的关系。
类似于spark的计算引擎还有很多,像mapreduce,flink等等。
类似于hive的存储框架也是数不胜数,比如pig。
最底层的存储往往都是使用h…
GZ033 大数据应用开发赛题第03套
2023年全国职业院校技能大赛
赛题第03套 赛项名称: 大数据应用开发
英文名称: Big Data Application Development
赛项组别: 高等职业教育组
赛项编号: GZ033 …
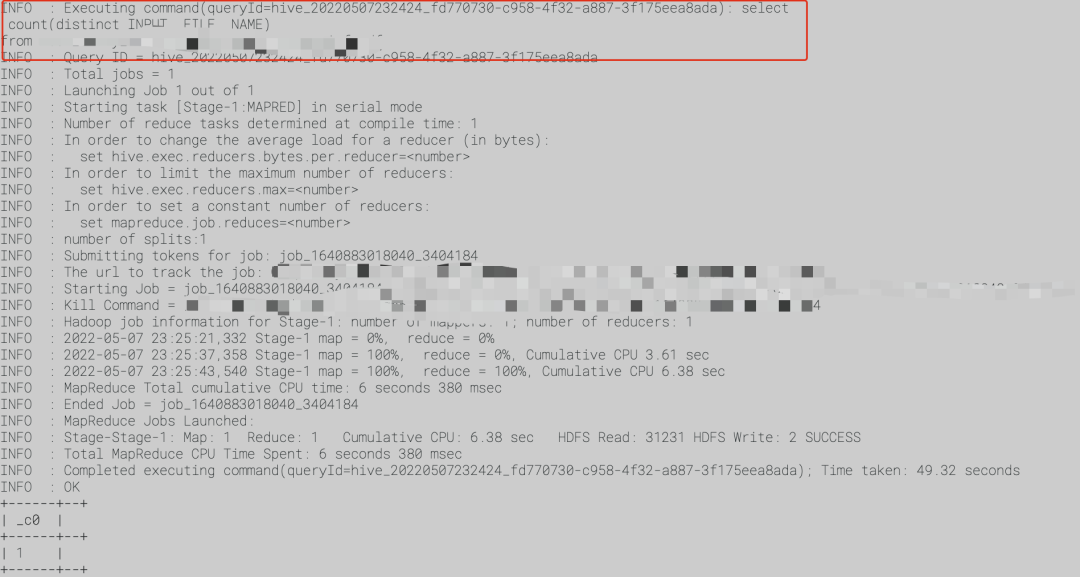
大数据开发之Hive案例篇5- count(distinct) 优化一例
文章目录 一. 问题描述二. 解决方案2.1 调整reduce个数2.2 SQL改写 一. 问题描述
需求:
卡在了reduce,只有一个reduce MR job卡在了最后一个reduce,任务迟迟未运行成功
二. 解决方案
2.1 调整reduce个数
一般一个reduce处理的数据是1G,…
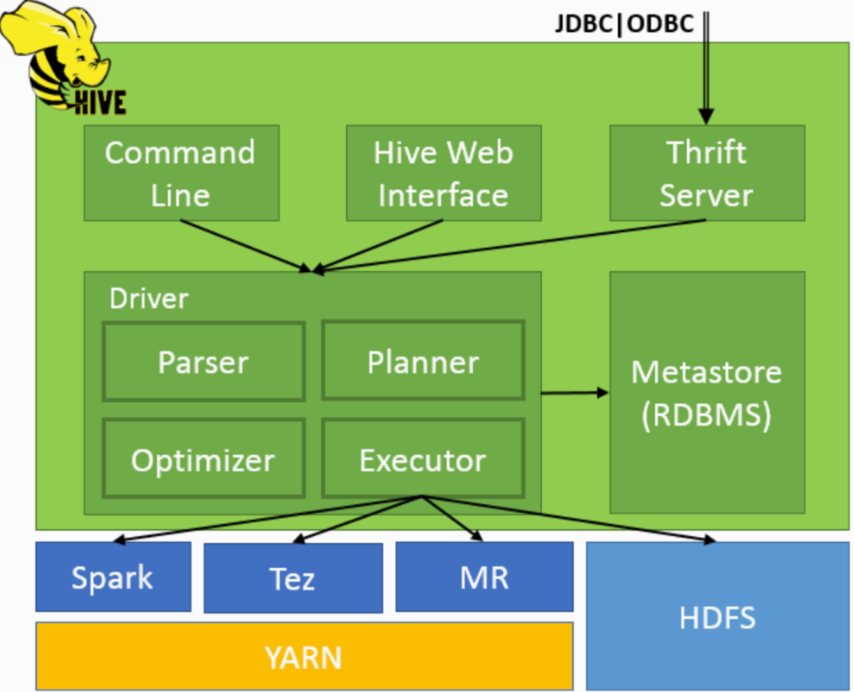
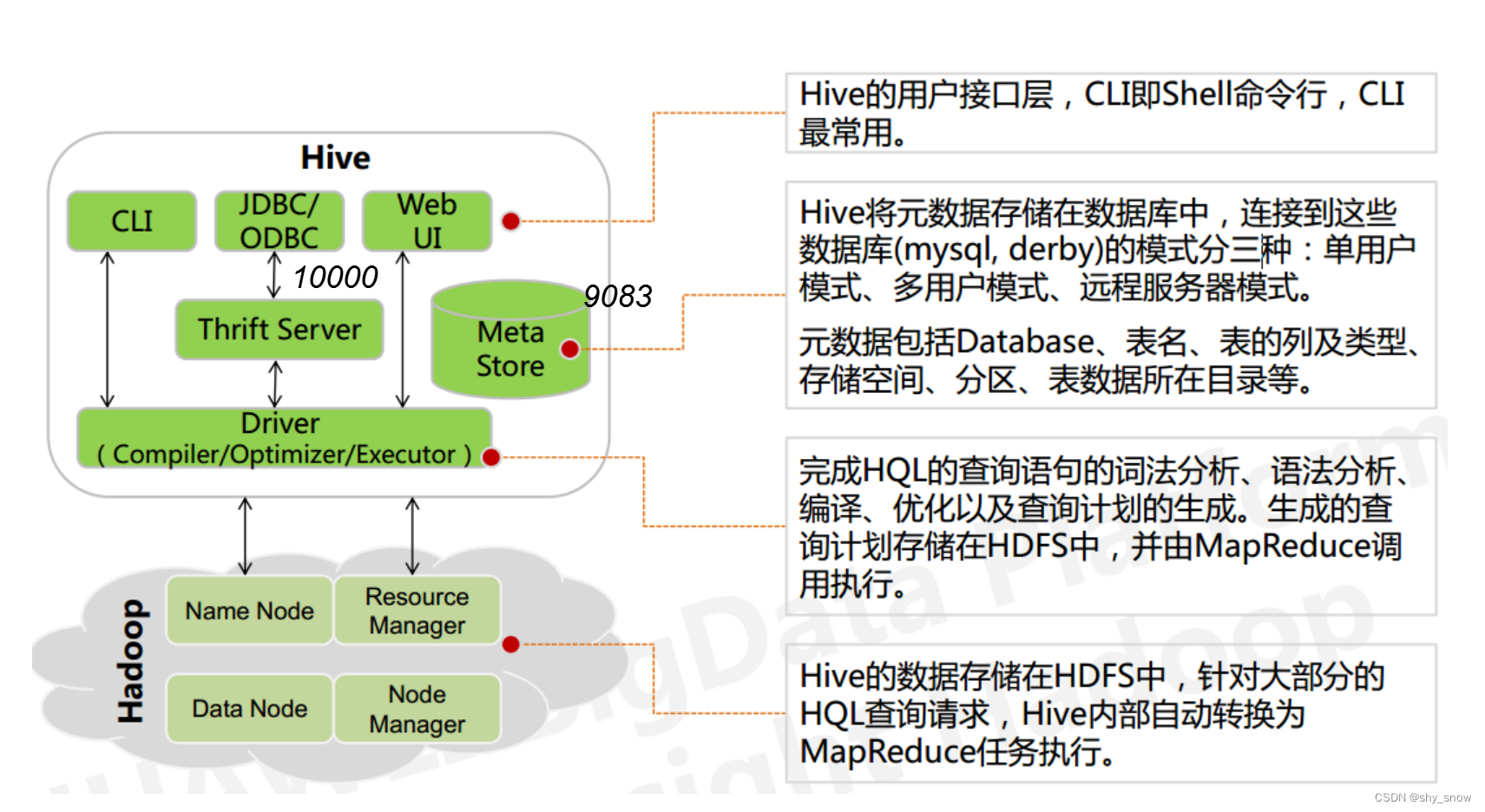
【hive-design】hive架构详解:描述了hive架构,hive主要组件的作用、hsql在hive执行过程中的底层细节、hive各组件作用
文章目录 一. Hive Architecture二. Metastore1. Metastore Architecture2. Metastore Interface 三. Compiler四. hive架构小结 本文主要讨论了 描述了hive架构,hive主要组件的作用详细描述了hsql在hive执行过程中的底层细节描述了hive各组件作用 一. Hive Archite…
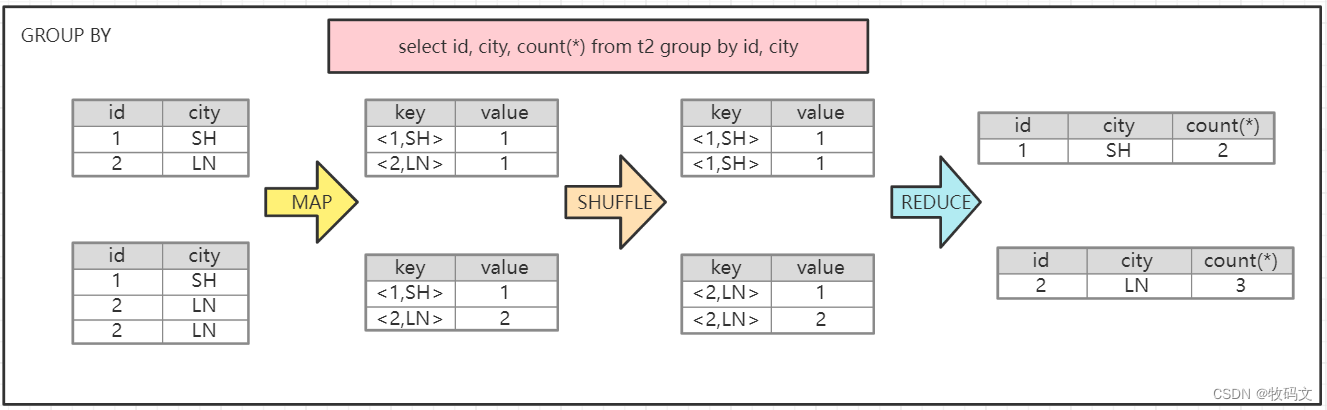
HIVE SQL 进行 Join 和 group by的具体原理及分区方式
HIVE SQL 实现Join和group by 具体原理
1、JOIN
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源。MapReduce的过程如下: 2、 GROUP BY HIVE SQL 实现Join和group by 的分区原理
1、JOIN
在join操作中,两个…
21. 查询每个用户登录日期的最大空档期
文章目录 题目需求实现一题目来源 题目需求
从登录明细表(user_login_detail)中查询每个用户两个登录日期(以login_ts为准)之间的最大的空档期。统计最大空档期时,用户最后一次登录至今的空档也要考虑在内,…
9. 统计每个商品的销量最高的日期
文章目录 题目需求实现一题目来源 题目需求
从订单明细表(order_detail)中统计出每种商品销售件数最多的日期及当日销量,如果有同一商品多日销量并列的情况,取其中的最小日期。
期望结果如下:
sku_id (商…

大数据 Hive 数据仓库介绍
目录
一、数据仓库概念
二、场景案例:数据仓库为何而来?
2.1 操作型记录的保存
2.2 分析型决策的制定
2.3 OLTP 环境开展分析可行吗?
2.4 数据仓库的构建
三、数据仓库主要特征
3.1 面向主题性(Subject-Orient…
Hive中表分类概念介绍
表分类
– 由Hive全权管理的表 所谓的管理表指的是hive是否具备数据的管理权限,如果该表是管理表,当用户删除表的同时hive也会将表内对应的数据删除,因此在生产环境下,为了防止误操作,带来数据损失,一般考…

kettle数据库链接共享(或本地配置文件)
在一个文件里,新建所有需要共享的数据库链接。 然后右键数据库链接,点共享。
之后重启Kettle可以完成共享,或者重复共享,取消共享操作。
共享操作主要是修改了,kettle本地的配置文件shared.xml 有需要的小伙伴&…
Centos7安装MySQL遇到libaio问题1
一、问题
[rootlocalhost upload]# rpm -ivh MySQL-server-5.6.24a-1.rhel5.x86_64.rpm error: Failed dependencies: libaio.so.1()(64bit) is needed by MySQL-server-5.6.24a-1.rhel5.x86_64 libaio.so.1(LIBAIO_0.1)(64bit) is needed by MySQL-server-5.6.24a-1.rhel5.x8…
hive查询中的排序总结
四个排序总结
order by全局排序reduce启动个数为一个sort by区内排序和distrbute by 结合使用reduce个数为多个distribute by同上reduce个数为多个cluster by当distribute by 和 sort by相同时 使用。reduce个数为多个
全局排序(Order By)
Order By&am…
【hive】报错累积
6.1 创建新表 错误1:FAILED: SemanticException [Error 10006]: Line 1:63 Partition not found "20210919" 场景:在创建例行表时,报错。这种情况是先创建了多级分区表(date,product),…
Leetcode 数据库刷题记录
https://leetcode-cn.com/problemset/database/ 题目都是leetcode 上的可以点击题目会有相应的链接 每道题后面都应相应的难度等级,如果没时间做的话 可以在leetcode 按出题频率刷题,答案仅供参考 175. 组合两个表
难度简单
SQL架构
表1: Person
---…
hive- 18~18区间找最晚批次
开始时间:14:20 15:20 16:20 17:20 19:20 计算【18,18)内的最晚时间 开始时间大于等于18点,开始时间减去18小时; 开始时间小于18点,开始时间加上(24-18)小时 select
from_unixtime(if(unix_timestamp(t0.start_…
Eclipse+JDBC远程操作Hive0.13
[b][colorolive][sizelarge]在前几篇的博客里,散仙已经写了如何在Liunx上安装Hive以及如何与Hadoop集成和将Hive的元数据存储到MySQL里,今天散仙就来看下,如何在Eclipse里通过JDBC的方式操作Hive.我们都知道Hive是一个类SQL的框架,…
Hive的分区与分桶
文章目录Hive的分区与分桶Hive的分区分区的作用静态分区动态分区Hive的分桶分桶的作用分桶的定义分桶的抽样总结分区分桶抽样语句 tablesample(bucket x out of y)Hive的分区与分桶
Hive的分区
分区的代码标准格式: 通过建表时就定义分区(用…
什么是hive?什么是hbase?它们有什么区别与联系。
Hive和HBase是两个在大数据领域中常用的开源项目,它们有不同的功能和用途: Hive(Apache Hive): Hive是一个基于Hadoop的数据仓库基础架构,它提供了一种类似于SQL的查询语言(HiveQL)来…
启动hive报错:ls: 无法访问/opt/module/spark-yarn/lib/spark-assembly-*.jar: 没有那个文件或目录
spark-2.1.1-bin-hadoop2.7.tgz和apache-hive-1.2.1-bin.tar.gz 环境中spark-yarn下每次进行hive --service metastore启动的时候,总是会报一个小BUG。
无法访问/home/ndscbigdata/soft/spark-2.0.0/lib/spark-assembly-*.jar: 没有那个文件或目录。
而这一行究竟…

基于Seatunnel2.1.0连通Hive数仓和ClickHouse的实战
背景 目前公司的分析数据基本存储在 Hive 数仓中,使用 Presto 完成 OLAP 分析,但是随着业务实时性增强,对查询性能的要求不断升高,同时许多数据应用产生,比如对接 BI 进行分析等,Presto不能满足需求&#x…

spark下启动hive常遇到的3个坑
第一个错误,终端输入hive报以下错误解决方法:将/usr/local/hive/conf/hive-site.xml配置文件第一行<?xml version"1.0" encoding"UTF-8 " standalone"no"?>中的encoding"UTF-8 " standalone"no&qu…

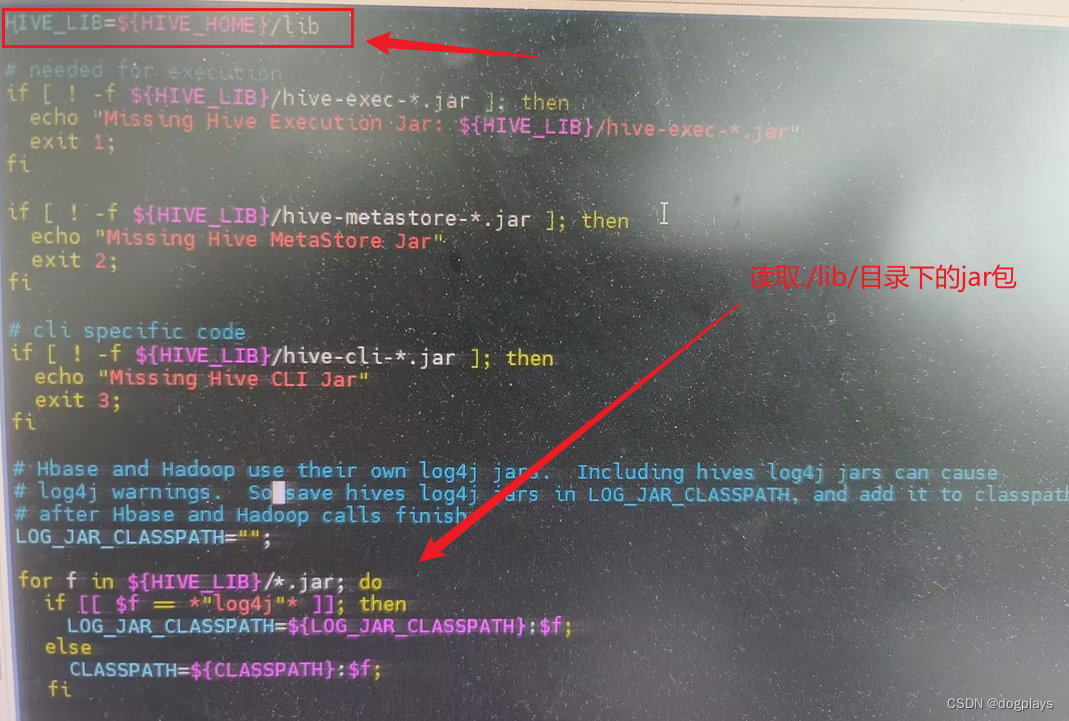
hive命令启动出现classnotfound
环境:ambari集群三个节点node104、node105和node106,其中node105上有hiveserver2,并且三个节点均有HIVE CLIENT
注意:“./”指hive安装目录 其中装有hiveserver2的node105节点,由于某种需要向lib目录下上传了某些jar包…

Hive精选10道面试题
1.Hive内部表和外部表的区别?
内部表的数据由Hive管理,外部表的数据不由Hive管理。 在Hive中删除内部表后,不仅会删除元数据还会删除存储数据, 在Hive中删除外部表后,只会删除元数据但不会删除存储数据。
内部表一旦…
大数据组件之Hive(Hive学习一篇就够了)
文章目录一、Hive安装1、解压环境2、环境变量配置3、配置文件信息1.打开编辑文件2.输入以下内容4、拷贝mysql驱动5、更新guava包和hadoop一致6、mysql授权7、初始化8、hive启动模式9、Hadoop的core-site.xml配置二、Hive1、Hive的文件结构2、MySQL上Hive的元数据3、hadoop文件授…
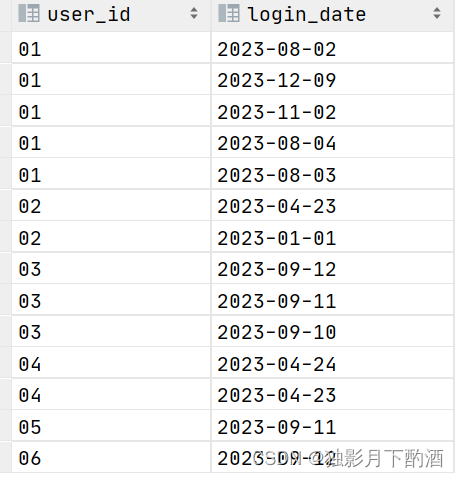
HQL解决连续三天登陆问题
1.背景
统计连续登录天数超过3天的用户,输出信息包括:用户id,登录天数,起始时间,结束时间;
2.准备数据
-- 建表
create table if not exists user_login_3days(user_id STRING,login_date date
);--插入…
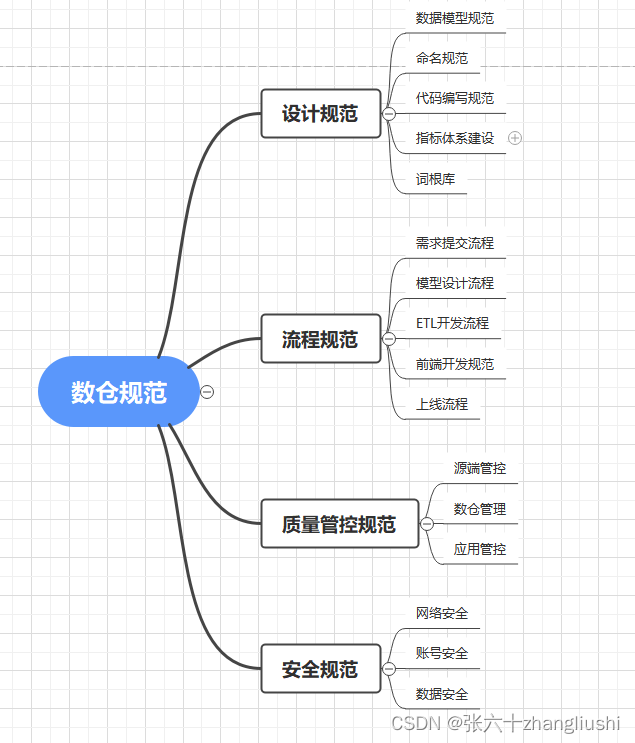

Hive集群高可用配置与impala集群高可用配置
Hive 高可用配置与impala高可用
1. HiveServer2高可用及Metastore高可用
使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和p…
5. Hive的三种去重方法
文章目录 Hive的三种去重方法1. distinct2. group by3. row_number()4. 三者的效率对比参考链接 Hive的三种去重方法
1. distinct
-- 语法SELECT DISTINCT column1, column2, ...
FROM table_name;注意事项: distinct 不能单独用于指定某一列,必须放在…
Hive知识梳理(好文)
Hive是建立在 Hadoop 上的数据仓库基础构架。可以将SQL查询转换为MapReduce的job在Hadoop集群上执行。 元数据
Hive元数据信息存储在Hive MetaStore中,或者mysql中。 分隔符
Hive默认的分格符有三种,分别是(Ctrl/A)、࿰…
Hive操作命令上手手册
内容来自于《大数据Hive离线计算开发实战》 Hive原理
Hive是一个基于Hadoop的数据仓库和分析系统,用于管理和查询大型数据集。以下是Hive的原理:
数据仓库:Hive将结构化的数据文件映射成一张表,并提供类SQL查询功能。用户可以使…
pyspark.sql.utils.IllegalArgumentException: ‘java.net.UnknownHostException: cdhmaster‘
创建于:2022.06.16 修改于:2022.06.16
1 问题描述
基于本地pc机器安装的Spark2.4.2,采用本地模式,读取远程服务器的hive数据。
报出如下错误: pyspark.sql.utils.IllegalArgumentException: ‘java.net.UnknownHost…
【大数据之Hive】十、Hive之DML(Data Manipulation Language)数据操作语言
1 Load
将文件导入Hive表中。 语法:
hive>load data [local] inpath filepath [overwrite] into table tablename [partition (partcol1val1, ...)];关键字说明: (1)local:表示从本地加载数据到Hive表;…
Spark整合hive的时候出错
Spark整合hive的时候 连接Hdfs不从我hive所在的机器上找,而是去连接我的集群里的另外两台机器 但是我的集群没有开 所以下面就一直在retry
猜测:
出现这个错误的原因可能与core-site.xml和hdfs-site.xml有关,因为这里面配置了集群的nameno…
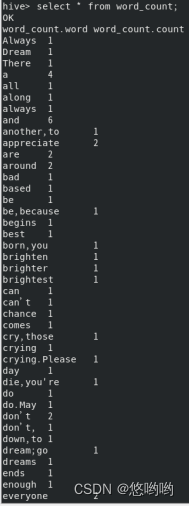
【大数据技术】实验3:熟悉常用的Hive操作
文章目录一、实验环境二、实验内容安装Hive环境HiveQL练习词频统计出现的问题一、实验环境
操作系统:Linux(与实验1保持一致);Hadoop版本:3.3.1;JDK版本:1.8;Hive版本:3…
21. 常用shell之 chmod - 更改文件权限 的用法和衍生用法
chmod 是一个在 Unix 和类 Unix 系统(如 Linux 和 macOS)中用于更改文件或目录权限的命令。理解 chmod 的基本用法和衍生用法对于管理系统文件和保护数据安全非常重要。
基本用法
在 Unix 和类 Unix 系统中,文件和目录的访问权限被分为三类…
hive 清空分区表 多姿势对比
目的
测试 清空hive分区表(分区>1000) 最优方案
测试背景
表: 分区表 二级分区分区个数: 5400数据量: 8000 万HDFS占用: 214.9 GB复制 测试的分区表 每张表耗时: 18min,其中扫描5400个路径下的文件耗时26s set spark.executor.memory3g;set spark.executor.cores15;set s…
Hive字符串数组json类型取某字段再列转行
一、原始数据
acctcontent1232313[{"name":"张三","code":"上海浦东新区89492jfkdaj\r\n福建的卡"...},{"name":"狂徒","code":"select * from table where aa1\r\n and a12"...},{...}]...…

【Python大数据笔记_day09_hive函数和调优】
hive函数
函数分类标准[重点] 原生分类标准: 内置函数 和 用户定义函数(UDF,UDAF,UDTF)
分类标准扩大化: 本来,UDF 、UDAF、UDTF这3个标准是针对用户自定义函数分类的; 但是,现在可以将这个分类标准扩大到hive中所有的函数,…
Hive数据倾斜的原因以及常用解决方案
在Hadoop平台的hive数据库进行开发的时候,数据倾斜也是比较容易遇到的问题,这边文章对数据倾斜的定义以及产生的原因、对应的解决方案进行学习。
一、数据倾斜的定义
数据倾斜:数据分布不均匀,造成数据大量的集中到一点…
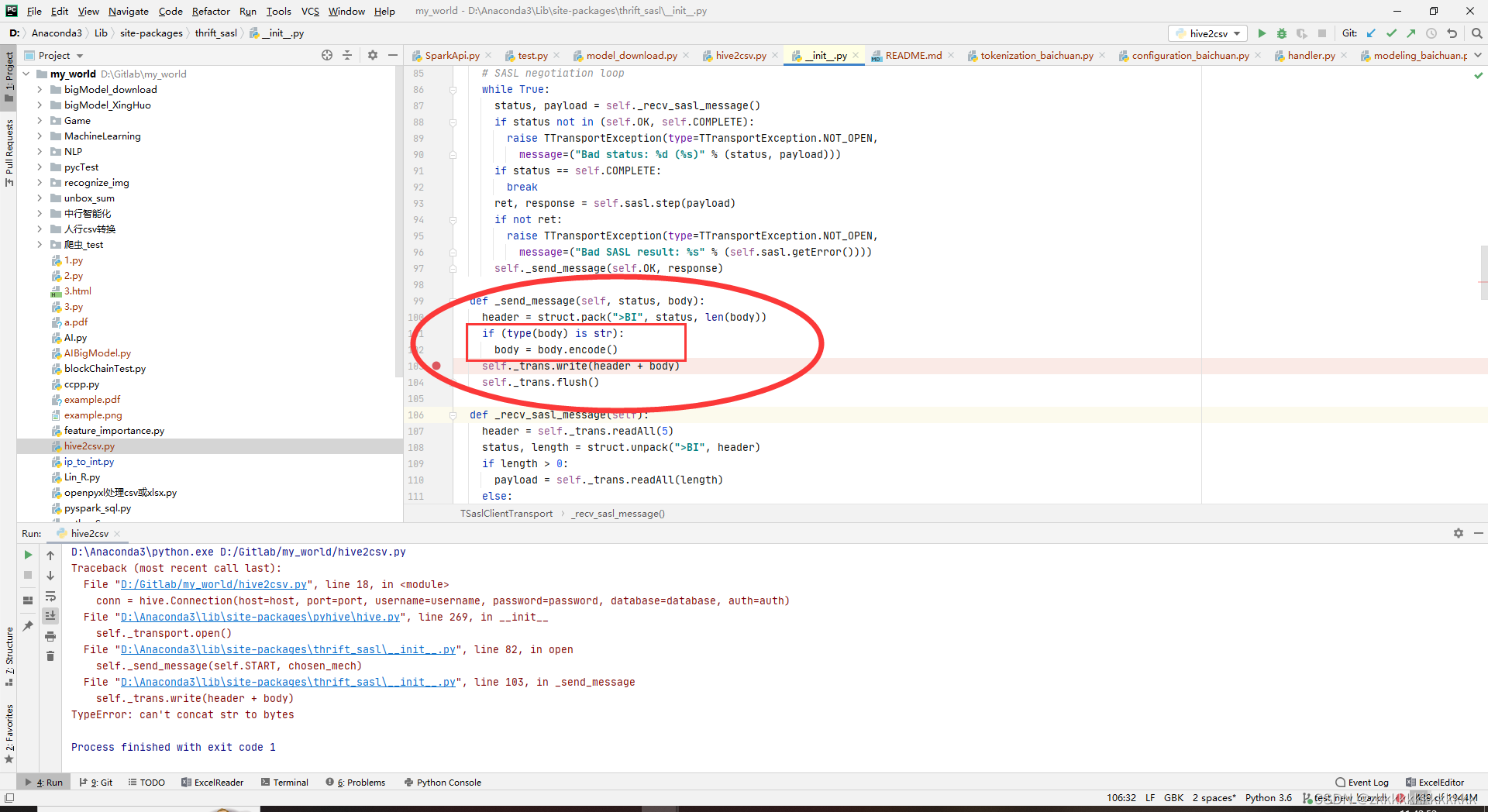
python连接hive报错:TypeError: can‘t concat str to bytes
目录
一、完整报错
二、解决
三、 其他报错 一、完整报错 Traceback (most recent call last): File "D:/Gitlab/my_world/hive2csv.py", line 18, in <module> conn hive.Connection(hosthost, portport, usernameusername, passwordpassword, data…

Hive 之 函数 03-系统内置函数 及 自定义函数
欢迎大家扫码关注我的微信公众号: Hive 之 函数 03-系统内置函数 及 自定义函数一、 系统内置函数1.1 查看系统自带的函数1.2 显示自带的函数的用法1.3 详细显示自带的函数的用法二、 自定义函数2.1 概述2.2 自定义 UDF 函数2.2.1 创建一个Maven 工程;2…
Hive——简单操作
进入控制台 hive 控制台显示当前使用的数据库 set hive.cli.print.current.dbtrue; 创建数据库 CREATE DATABASE [IF NOT EXISTS] test; 显示所有数据库 show databases; 切换数据库 use test; 显示所有的表 show tables; 显示表字段 desc 表名; Hive映射Hbase表,用…

一百零六、Hive312的计算引擎由MapReduce(默认)改为Spark(亲测有效)
一、Hive引擎包括:默认MR、tez、spark 在低版本的hive中,只有两种计算引擎mr, tez 在高版本的hive中,有三种计算引擎mr, spark, tez
二、Hive on Spark和Spark on Hive的区别 Hive on Spark:Hive既存储元数据又负责SQL的解析&…
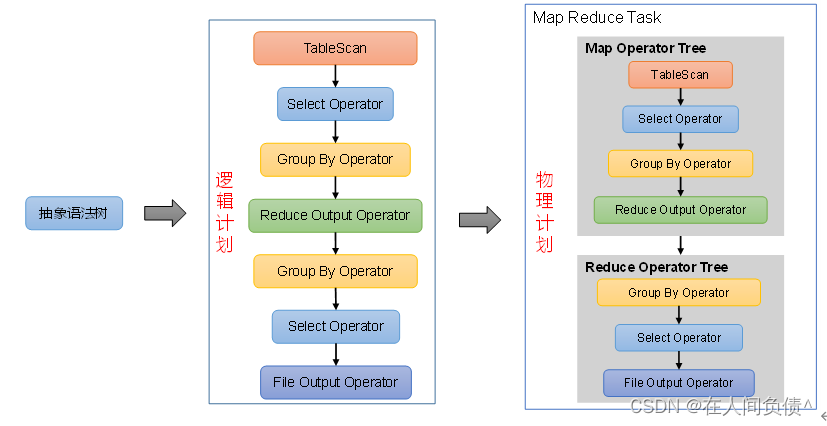
Hive ---- Hive入门
Hive ---- Hive入门 1. 什么是Hive1. Hive简介2. Hive本质 2. Hive架构原理1. 用户接口:Client2. 元数据:Metastore3. 驱动器:Driver4. Hadoop 1. 什么是Hive
1. Hive简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具&a…
2024.1.10 SparkSQL ,函数分类, Spark on HIVE,底层执行流程
目录
一 . 开窗函数
二 . SparkSQL函数定义 1. HIVE_SQL用户自定义函数 2.Spark原生UDF 3. pandasUDF 4. pandasUDAF
三. Spark on HIVE
四.SparkSQL的执行流程 一 . 开窗函数 分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx]) 分析函…
自定义UDF函数进行敏感字段加密解密
需求 一些用户数据中包含诸如用户手机号等信息,直接暴露出来的话,是违法的。。。需要对数据进行脱敏,如果单纯的将手机号替换为***号,那么就意味着丢失用户的手机号数据了,因为无法再将***变回手机号。所以需要自定义UDF函数,实现敏感数据的加密解密。 这里实现了…

一百八十五、大数据离线数仓完整流程——步骤四、在Hive的DWD层建动态分区表并动态加载数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(四)步骤四、在Hive的…
ClickHouse与Presto及Hive性能对比(7亿数据)
数据量
总量7.6亿,机台数据
Hive中数据 DROP TABLE IF EXISTS dwd_ipqc_online;
CREATE EXTERNAL TABLE dwd_ipqc_online
(MACH_ID string COMMENT 機台ID,MACH_IP string COMMENT 機台IP,CREATE_TIME string COMMENT 創建時間,IPQC_ONLINEID strin…

Shlle脚本传参调用seatunnel(原waterdrop)将hive中数据导入ClickHouse
前言
公司分析数据已经存入hive,但需要输入参数计算得到很长一段时间的趋势变化数据(不固定查询),经调研ClickHouse时序优化后比较满足需求,并且ClickHouse在数据量大时最好采用DNS轮询本地表写,分布式表读…
Hive动态分区导入ClickHouse时出现错误
项目场景:
最近在将hive导入clickhouse,全量导入没有问题,增量导入时出现问题,这里记录下来 hive源表:
DROP TABLE IF EXISTS dwd_test;
CREATE EXTERNAL TABLE dwd_test
(id string COMMENT ID,name stri…

hive亿级数据导入ClickHouse并增量更新
项目场景:
hive亿级数据导入ClickHouse,并每日导入 (技术工具看上文)
hive中表结构: 数据量7.6亿
DROP TABLE IF EXISTS dwd_ipqc_online;
CREATE EXTERNAL TABLE dwd_ipqc_online
(MACH_ID string COMMENT 機…

hive导入ClickHouse时Spark读取Hive分区错误解决
项目场景:
错误由来
问题描述: java.lang.RuntimeException: Caught Hive MetaException attempting to get partition metadata by filter from Hive. You can set the Spark configuration setting spark.sql.hive.manageFilesourcePartitions to fa…

基于Seatunnel连通Hive数仓和ClickHouse的实战
背景 目前公司的分析数据基本存储在 Hive 数仓中,使用 Presto 完成 OLAP 分析,但是随着业务实时性增强,对查询性能的要求不断升高,同时许多数据应用产生,比如对接 BI 进行分析等,Presto不能满足需求&#x…
springboot连接hive数据库
springboot后台开发连接hive数据库
确保集群上hivesever2的服务已启动
hive数据库一般在10000端口
springboot开发
pox.xml 文件
<?xml version"1.0" encoding"UTF-8"?>
<project xmlns"http://maven.apache.org/POM/4.0.0" xml…
【Hive实战】Hive的逻辑视图
Hive视图使用 Hive的逻辑视图使用视图的目的视图规则视图的问题Hive中的视图使用定义视图查询视图详细查询引用视图修改视图查询删除视图 Hive的逻辑视图
视图是在SQL标准协议中是一种信息模式,是根据定义模式的基础表定义的视图表。 The views of the Information…
Hive SQL题库(初级)
第一章 环境准备
1.1 建表语句
hive>
-- 创建学生表
DROP TABLE IF EXISTS student;
create table if not exists student_info(stu_id string COMMENT 学生id,stu_name string COMMENT 学生姓名,birthday string COMMENT 出生日期,sex string COMMENT 性别
)
row format…

数据仓库Hive——DDL详细数据操作
文章目录一、Hive基本概念1.什么是Hive2.Hive的优缺点3.Hive的架构原理4.Hive和数据库的比较二、Hive DDL的基本操作指令1.展示数据库2.使用数据库3.展示表4.导入数据5.用Hive查看HDFS目录文件6.用Hive查看本地目录7.查看hive历史操作命令8.查看表的详细信息9.创建表9.1 这是创…

数据仓库 Apache Hive
一、数据分析
1、数据仓库 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(…
使用Python创建faker实例生成csv大数据测试文件并导入Hive数仓
文章目录 一、Python生成数据1.1 代码说明1.2 代码参考 二、数据迁移2.1 从本机上传至服务器2.2 检查源数据格式2.3 检查大小并上传至HDFS 三、beeline建表3.1 创建测试表并导入测试数据3.2 建表显示内容 四、csv文件首行列名的处理4.1 创建新的表4.2 将旧表过滤首行插入新表 一…

锁屏面试题百日百刷-Hive篇(十一)
锁屏面试题百日百刷,每个工作日坚持更新面试题。锁屏面试题app、小程序现已上线,官网地址:https://www.demosoftware.cn。已收录了每日更新的面试题的所有内容,还包含特色的解锁屏幕复习面试题、每日编程题目邮件推送等功能。让你…
Sqoop ---- Sqoop的简单使用案例
Sqoop ---- Sqoop的简单使用案例 1. 导入数据1. RDBMS到HDFS2. RDBMS到Hive3. RDBMS到Hbase 2. 导出数据1. HIVE/HDFS到RDBMS 3. 脚本打包 1. 导入数据
在Sqoop中,“导入”概念指:从非大数据集群(RDBMS)向大数据集群(…
hive sql 和 spark sql的区别
Hive SQL 和 Spark SQL 都是用于在大数据环境中处理结构化数据的工具,但它们有一些关键的区别: 底层计算引擎: Hive SQL:Hive 是建立在 Hadoop 生态系统之上的,使用 MapReduce 作为底层计算引擎。因此,它的…
hive中如何求取中位数?
目录 中位数的概念代码实现准备数据实现 中位数的概念
中位数(Median)又称中值,统计学中的专有名词,是按顺序排列的一组数据中居于中间位置的数,代表一个样本、种群或概率分布中的一个数值,其可将数值集合…
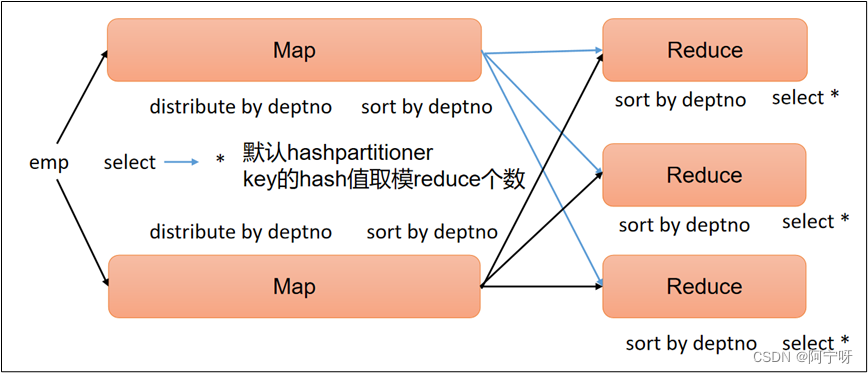
【大数据之Hive】十二、Hive-HQL查询之分组、join、排序
一、分组
1 group by 语句 group by 通常和聚合函数一起使用,按照一个或多个列的结果进行分组,任何对每个租执行聚合操作。 用group by时,select中只能用在group by中的字段和聚合函数。
--计算emp每个部门中每个岗位的最高薪水&#x…
Hive 库表相关操作
1、Hive内部表和外部表
1.内部表:未被external修饰;外部表:被external修饰。
区别:
(1)内部表数据由Hive自身管理,外部表数据由HDFS管理;
(2)内部表数据存…

Hive与JDBC示例
在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口。使用下面命令进行开启: hive -service hiveserver & 1). 测试数据 userinfo.txt文件内容(每行数据之间用tab键隔开): 1 xiapi
2 xiaoxue
3 qingqing 2). 程序代码 package com.ljq.hive;import…
Hive基础知识(十):Hive导入数据的五种方式
1. 向表中装载数据(Load) 1)语法 hive> load data [local] inpath 数据的 path[overwrite] into table student [partition (partcol1val1,…)];
(1)load data:表示加载数据
(2)local:表示…
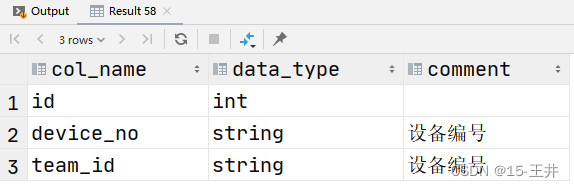
Hive设置元数据支持中文显示
在hive中建外部表时遇见到这样一个问题,就是表字段的中文注释在desc 表结构时看不了,发现原来是Hive的元数据库没有设置支持中文显示
第一步,在元数据库metastore完成初始化后,再次登录MySQL
[roothurys24 hurys_table_data]# m…
from_unixtime和unix_timestamp用法
from_unixtime和unix_timestamp是SQL中用来转换时间戳的两个函数。
1、from_unixtime函数:
from_unixtime函数将Unix时间戳转换为MySQL或者Hive中的日期时间格式。其语法如下: from_unixtime(unix_timestamp, [format]) 参数说明: unix_tim…
Hive支持Json格式
1、下载hive-json-serde相关包
下载json-serde-1.3.8-jar-with-dependencies.jar、json-udf-1.3.8-jar-with-dependencies.jar,将其放到mapreduce、spark对应的lib目录下,如下:
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/lib/下载地…
大数据:hive数据库的操作语法,数据表,内部表,external外部表,数据导入导出load,insert
大数据:
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql要学&#x…
Hive cube / rollup / grouping sets/GROUPING__ID用法详解
Hive CUBE / ROLLUP / GROUPING SETS / GROUPING__ID用法详解GROUPING SETSGROUPING__ID(注意这里是两个下划线)CUBEROLLUPcube / rollup / grouping sets/GROUPING__ID,经常会被问到这几个函数的区别,今天就好好整理一下。GROUPI…
NIFI大数据进阶_实时同步MySql的数据到Hive中去_可增量同步_实时监控MySql数据库变化_操作方法说明_02---大数据之Nifi工作笔记0034
然后我们继续来看,如果需要同步,当然需要先开启mysqlbin log日志了 可以看到开启操作 在windows和linux上开启binlog日志 然后看一下 在windows上开启mysql的binlog的方法

彷徨 | Hive---需求:求出连续三天有销售记录的店铺
原始数据 :
A,2017-10-11,300
A,2017-10-12,200
A,2017-10-13,100
A,2017-10-15,100
A,2017-10-16,300
A,2017-10-17,150
A,2017-10-18,340
A,2017-10-19,360
B,2017-10-11,400
B,2017-10-12,200
B,2017-10-15,600
C,2017-10-11,350
C,2017-10-13,250
C,2017-10-14,300
C,2017…
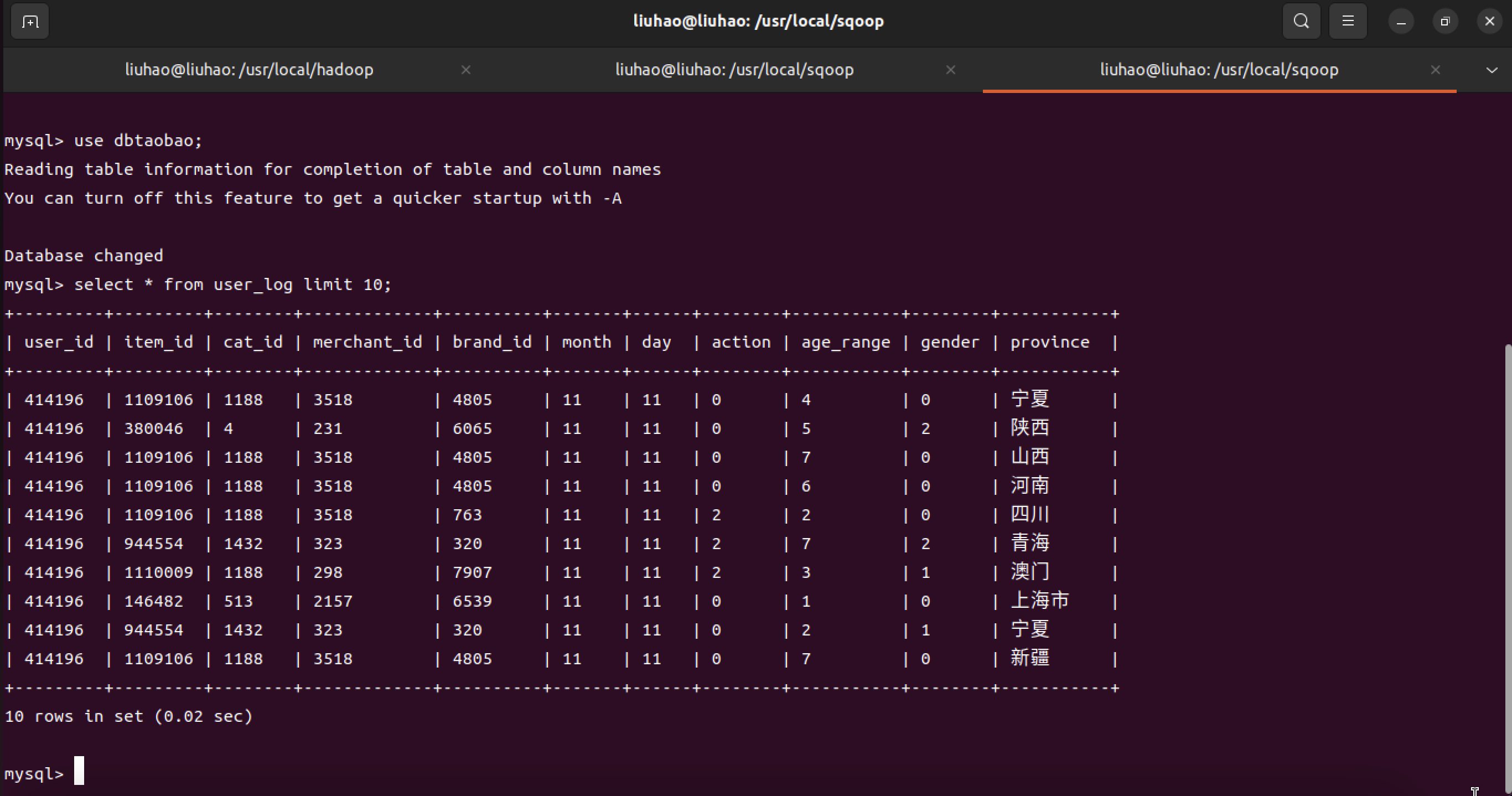
【大数据存储技术】「#3」将数据从Hive导入到MySQL
文章目录准备工作安装Hive、MySQL和SqoopHive预操作启动MySQL、hadoop、hive创建临时表inner_user_log和inner_user_info使用Sqoop将数据从Hive导入MySQL启动hadoop集群、MySQL服务将前面生成的临时表数据从Hive导入到 MySQL 中查看MySQL中user_log或user_info表中的数据准备工…

解决: Caused by: com.alibaba.druid.sql.parser.ParserException: syntax error, error in :'like %?%...
精选30云产品,助力企业轻松上云!>>> 问题: Caused by: com.alibaba.druid.sql.parser.ParserException: syntax error, error in :like "%"?"%"解决 1.使用 (CONCAT(%,#{字段}), %) name like CONCAT(%,#{na…
Hive常见的面试题(十二道)
Hive
1. Hive SQL 的执行流程
⾸先客户端通过shell或者Beeline等⽅式向Hive提交SQL语句,之后sql在driver中经过 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 ANTLR&…

Hive - 警惕默认分割符号:^A
一.引言
hive 执行如下 insert 插入语句后将数据从 RCFile 格式转换为 Text 并导入 Hdfs:
function insertData() {
hive -e "
insert overwrite directory $output
select col_1,\t,col_2 from $table where dt$day and num > 10000
"
}
但是解析忽略了 ^A 默…
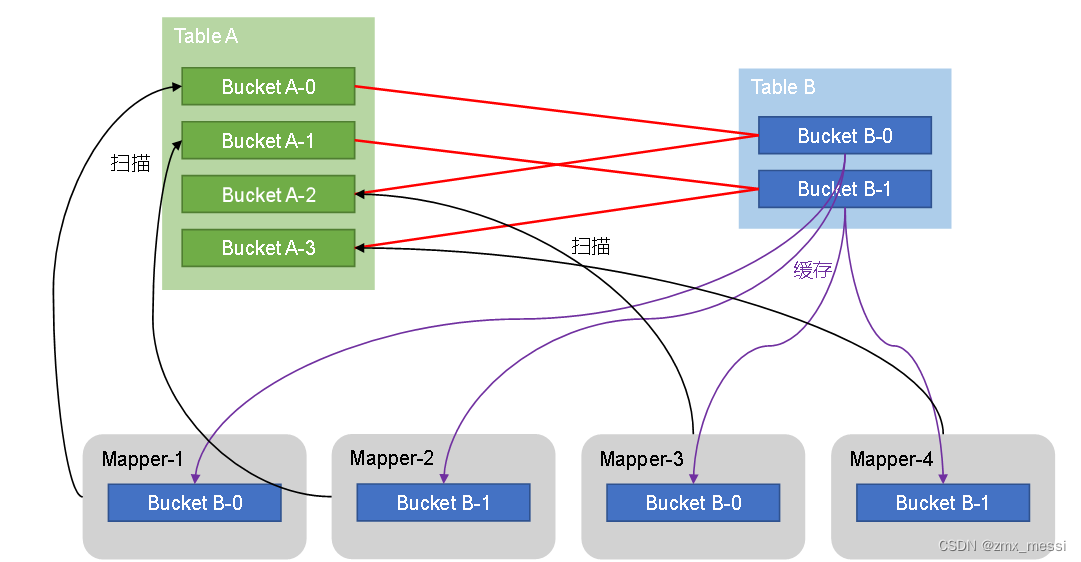
HiveSql语法优化二 :join算法
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等,下面对每种join算法做简要说明: Common Join Common Join是Hive中最稳定的join算法,其通过一个M…
“一键导出,高效整理:将之前的部分记录导出!“
亲爱的朋友们,你们是否曾经为了导出之前的记录而感到烦恼?冗长的过程,无法精确控制的选项,实在让人感到心力交瘁。但现在,我们为你带来一种全新的解决方案,让你的工作更轻松,更高效!…

Hive - grouping sets 示例与详解
一.引言
现有超市用户购物数据表一张,其字段与数据如下: 用户 id 为连续数字编号,性别分别用 0、1表示,年龄使用 xxs 表示,cost 代表用户在超市的消费总额:
1 0 00s 100 20220505
2 1 90s 200 20220505
3…
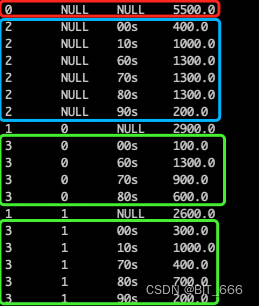
Hive - Cube, Rollup, GroupingId 示例与详解
一.引言
上篇文章讲到了 Grouping Sets 的使用方法,Grouping Sets 可以看做是将 group by 的内容进行 union 整合,这篇文章将基于同一思想进行扩展介绍两个方法 Cube 以及 Rollup,同时给出辅助函数 GroupingId 的生成方法与使用方法。 1 0 0…
配置Hive使用Spark执行引擎
配置Hive使用Spark执行引擎 Hive引擎概述兼容问题安装SparkSpark配置Hive配置HDFS上传Spark的jar包执行测试速度对比 Hive引擎
概述 在Hive中,可以通过配置来指定使用不同的执行引擎。Hive执行引擎包括:默认MR、tez、spark MapReduce引擎: 早…

Hive SQL间隔连续问题
问题引入
下面是某游戏公司记录的用户每日登录数据, 计算每个用户最大的连续登录天数,定义连续登录时可以间隔一天。举例:如果一个用户在 1,3,5,6,9 登录了游戏,则视为连续 6 天登录。
id dt1001 2021-12-121002 2021-12-121001 2021-12-131001 2021…

Hive与HBase的区别及应用场景
当数据量达到一定量级的时候,存储和统计计算查询都会遇到问题,今天了解一下Hive和Hbase的区别和应用场景。 一、定义
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能&am…
从零开始学Shell - Hive示例
更多请参考:https://blog.csdn.net/zhsworld/article/details/119964283
# 通过安全认证
kinit -kt /home/demo/xxx.keytab xxxxxx# 按照时间顺序,从距离今天的第30天开始,一直循环查询到距离今天的第10天
for((i30;i>10;i--))
do# 获取日…
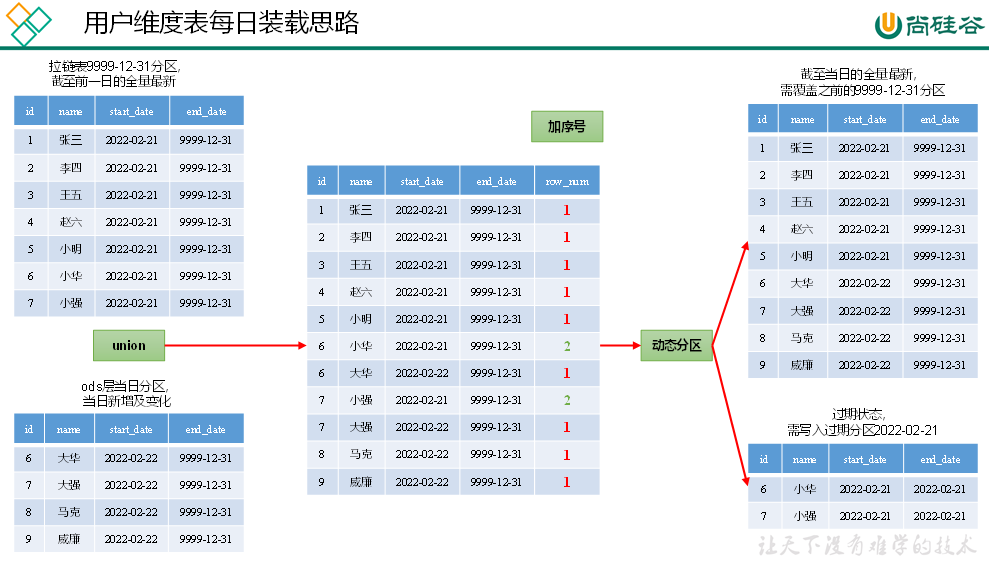
尚硅谷大数据项目《在线教育之离线数仓》笔记003
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili 目录
第8章 数仓开发之DIM层
P039
P040
P041
P042
P043
P044
P045
P046
P047
P048 第8章 数仓开发之DIM层
P039 第8章 数仓开发之DIM层 DIM层设计要点: (1&a…
Hive、MySQL、Oracle内建函数对照表
Hive、MySQL、Oracle内建函数对照表 1、背景2、Hive、MySQL、Oracle内建函数对照表 1、背景 Hive自身预置了许多函数,可以满足大部分业务场景的数据处理需求。例如,日期与时间函数、数学函数、窗口函数、聚合函数、字符串函数、复杂类型函数、加密函数等…
Hive - ROW_NUMBER() OVER 排序去重
一.引言
需求:
每日更新的全量数据表,根据用户去重获取7日内的最新的用户行为 二.ROW_NUMBER() OVER 实现
全量数据表 user_action ,根据 dt 分区,共包含三列
(user STRING,
action STRING,
dt STRING)
假设有过去一年共 3…
助力工业物联网,工业大数据之ODS层构建:需求分析【八】
文章目录01:ODS层构建:需求分析02:ODS层构建:创建项目环境03:ODS层构建:代码导入01:ODS层构建:需求分析 目标:掌握ODS层构建的实现需求 路径 step1:目标step…
【Hive实战】 Hive的权限模型
Hive的权限模型 文章目录 Hive的权限模型总览什么是Hive授权Hive的授权场景Hive的授权模式使用建议 基于元数据存储的授权元存储服务器安全的必要性元存储安全的配置参数配置举例 基于sql标准的授权配置举例对Hive命令和语句的限制权限对象对象所有者用户与角色角色管理命令Gra…
2023.12.14 hive sql的聚合增强函数 grouping set
目录 1.建库建表 2.需求 3.使用union all来完成需求 4.聚合函数增强 grouping set 5.聚合增强函数cube ,rollup 6.rollup翻滚
7.聚合函数增强 -- grouping判断 1.建库建表
-- 建库
create database if not exists test;
use test;
-- 建表
create table test.t_cookie(month …
大数据学习(14)-Map Join和Common Join
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
【Spring教程23】Spring框架实战:从零开始学习SpringMVC 之 SpringMVC简介与SpringMVC概述
目录 1,SpringMVC简介2、SpringMVC概述 欢迎大家回到《Java教程之Spring30天快速入门》,本教程所有示例均基于Maven实现,如果您对Maven还很陌生,请移步本人的博文《如何在windows11下安装Maven并配置以及 IDEA配置Maven环境》&…

大数据毕业设计选题推荐-营业厅营业效能监控平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
Hive 内部表和外部表对比
前言
在创建表的过程中,会有内部表和外部表之分,那么它们有哪些差别呢,分别的使用场景是什么呢?
内部表
内部表一般存储在 hive.metastore.warehouse.dir 配置项指定的目录下,默认情况下存储在类似于/user/hhive/wa…
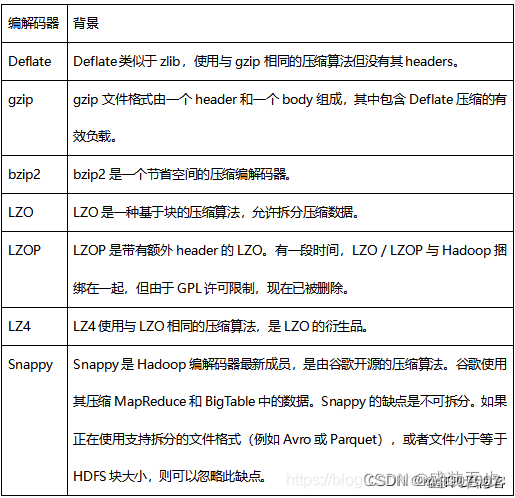
大数据系列——Hive理论
概述
Hive是一个数据仓库管理工具,将结构化的数据文件映射为一张数据库表,并提供类SQL(HQL)查询功能。由Facebook实现并开源,最后捐赠给Apache发展为顶级项目。
以RDBMS数据库为元数据存储服务,
以Hadoop HDFS来存储…

初学Hadoop——Hive命令行客户端使用
一、Hive简介
Hive是一个基于HDFS和MapReduce的分布式数据仓库系统,以表的形式管理用户数据,用户只需要编写HQL语句就能够利用MR对存放在HDFS上的数据进行计算(Hive会将HQL语句自动转换为MR作业,提交给MR执行)&#x…
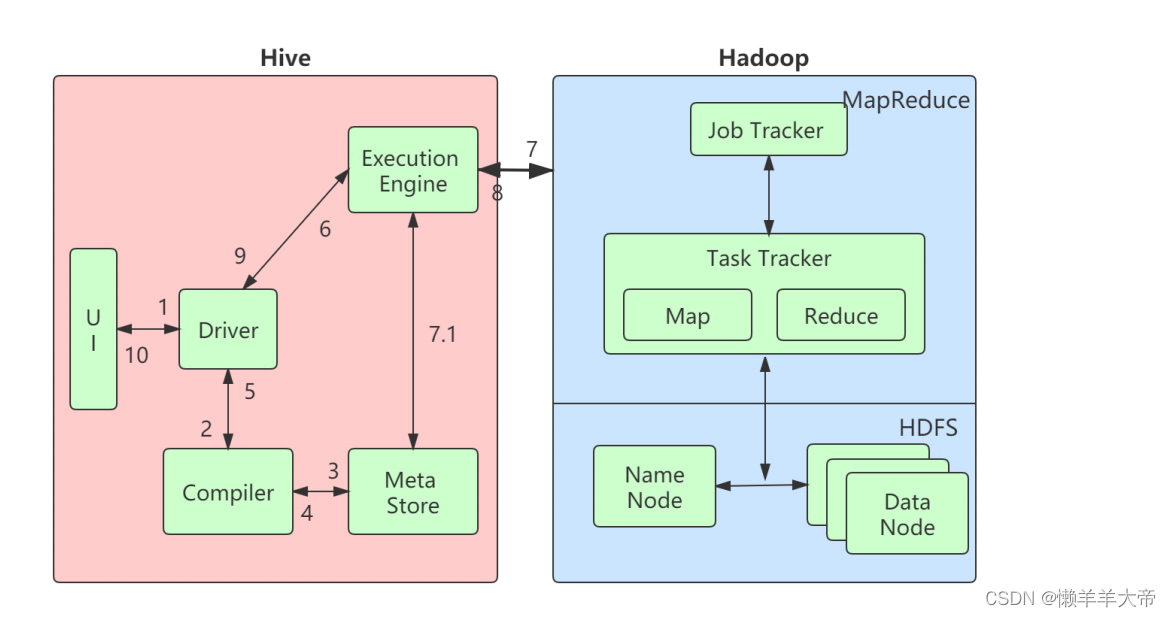
hive数据仓库--Hive介绍
1 什么是HiveHive是基于Hadoop的⼀个数据仓库⼯具,⽤来进⾏数据提取、转化、加载,这是⼀种可以存储、查询和分析存储在Hadoop中的⼤规模数据的机制。Hive数据仓库⼯具能将结构化的数据⽂件映射为⼀张数据库表,并提供类SQL的查询功能ÿ…

【Java 进阶篇】Java Listener 使用详解
在 Java Web 应用程序中,监听器(Listener)是一种强大的机制,用于在 Web 容器中监听和响应各种事件。通过监听器,我们可以在应用程序生命周期中执行特定的任务,如在应用启动时初始化资源,在会话创…

Hbase 映射到Hive
目录
一、环境配置修改
关闭掉hbase,zookeeper和hive服务
进入hive312/conf
修改hive-site.xml配置, 在代码最后添加配置 将hbase235的jar包全部拷贝到hive312的lib目录,并且所有的是否覆盖信息全部输入n,不覆盖 查看hive312下…
hive java 的demo
首先假定你的Hive已经部署完毕。 导入hive 下所有包 linux 下启动您的Hive: [rootxxx bin]# hive --service hiveserver 50031 Starting Hive Thrift Server Hive 连接 1 package hadoop.demo.hive;2 3 import java.sql.Connection;4 import java.sql.DriverManager;5 import j…
Hive的几种常见的数据导入方式
Hive的几种常见的数据导入方式这里介绍四种:(1)、从本地文件系统中导入数据到Hive表;(2)、从HDFS上导入数据到Hive表;(3)、从别的表中查询出相应的数据并导入到Hive表中&…
用户行为分析-小数据集
林子雨——用户行为分析 本篇文章主要分享一下自己跟着这个教程做的时候踩的坑,这个版本我用的是ubantu22, 之后会更新一篇ubantu16踩的坑 原网址:
用户行为分析
我的ubantu映像文件和jar包: ubantu映像
jar包
我用的是22,16,18也用过&am…
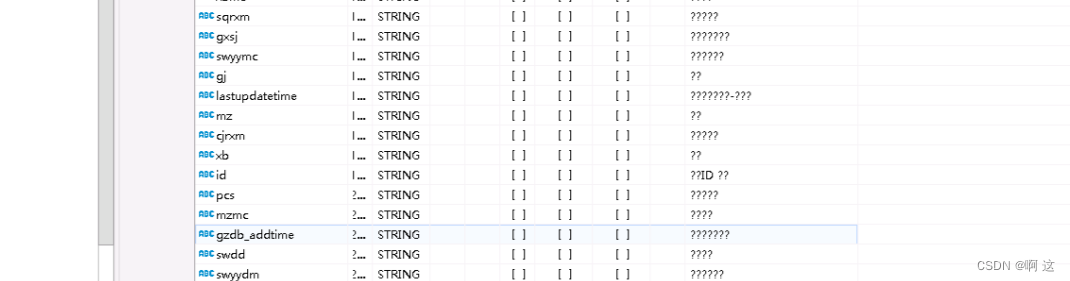
CDH 之 Hive 中文乱码平定通用法则
一、乱象
1.1 中文注释乱码 hive> DESCRIBE test;
OK
# col_name data_type comment
id string ??ID ??
pcs string ????? …
Hive用户中文使用手册系列(四)
Python Client
在github 上上可以使用 Python client 驱动程序。有关安装说明,请参阅设置 HiveServer2:Python Client 驱动程序。
Ruby Client
一个 Ruby client 驱动程序在https://github.com/forward3d/rbhive的 github 上可用。
与 SQuirrel SQL …

Hive 之 查询 03-排序
欢迎大家扫码关注我的微信公众号: Hive 之 查询 03-排序一、 全局排序(order by)二、 按照别名排序三、 多个列排序四、 每个 MapReduce 内部排序(sort by)五、 分区排序(distribute by)六、 c…
【大数据工具】Hive 安装
Hive 环境搭建与基本使用
Hive 安装包下载地址:https://dlcdn.apache.org/hive/
注:安装 Hive 前要先安装好 MySQL
1. MySQL 安装
MySQL 安装包下载地址:https://dev.mysql.com/downloads/mysql/archives/community/MySQL%20::%20Downloa…
Hive -- 基本概念
1、什么是Hive:
Hive是数据仓库建模的工具之一,通过向hive中写一个交互式的sql,在海量数据中查询分析得到结果的平台。
2、Hive的优缺点: 1、优点:
1、操作接口采用类sql语法,提供快速开发的能力&#x…

Hive 未关闭表的事务功能(ACID)的问题
Hive 未关闭表的事务功能(ACID)的问题
一、Hive 未关闭表的事务功能(ACID)的所引发的问题
记录一次HDP3.0 的hive 3.1.2由于未关闭ACID功能,导致使用到用户画像的Spark计算引擎报错,无法处理数据,impala无法查询的问题。由于hive 3.0之后默…
10分钟数仓实战之kettle整合Hadoop
1.写在前面
很多朋友在做数仓的ETL的动作的时候,还是喜欢比较易上手的kettle
前面章节有介绍过安装kettle,可以参考
ETL工具--安装kettle_老码试途的博客-CSDN博客_spoon.bat 安装
kettle在Windows系统中对数据的转换、表和文件的转换等,…
Hive表优化、表设计优化、Hive表数据优化(ORC)、数据压缩、存储优化
文章目录Hive表优化Hive表设计优化分区表结构 - 分区设计思想分桶表结构 - Join问题Hive中的索引Hive表数据优化常见文件格式TextFileSequenceFileParquetORC数据压缩存储优化 - 避免小文件生成存储优化 - 合并输入的小文件存储优化 - ORC文件索引Row Group IndexBloom Filter …
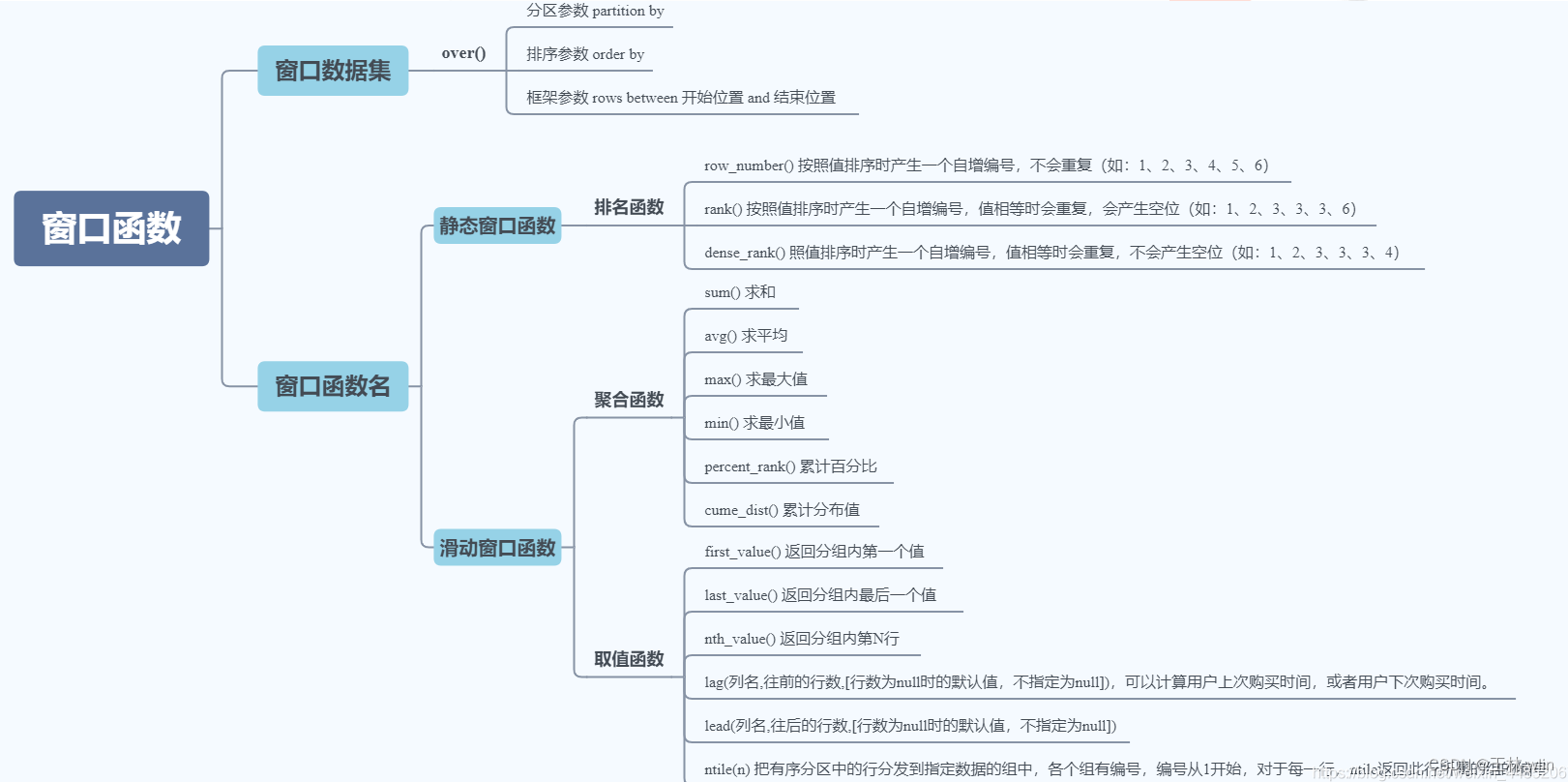
SQL 窗口函数详解
SQL窗口函数详解 窗口函数的主要作用是对数据进行分组排序、求和、求平均值、计数等。 一、窗口函数的基本语法
<分析函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单> [ROWS BETWEEN 开始位置 AND 结束位置])理解窗口函数的基本语法ÿ…
HBase---idea操作Hbase数据库并且映射到Hive
idea操作Hbase数据库并且映射到Hive 文章目录idea操作Hbase数据库并且映射到Hiveidea操作Hbase数据库环境准备启动服务创建Maven工程在测试类中编写初始化方法在测试类中编写关闭方法在测试类中编写创建命名空间方法在测试类中编写创建表方法在测试类中编写查看表结构方法在测试…

Hive 之 查询 04-分桶及抽样查询
欢迎大家扫码关注我的微信公众号: Hive 之 查询 04-分桶及抽样查询一、 分桶表数据存储二、 分桶抽样查询一、 分桶表数据存储
分区针对的是数据的存储路径, 分桶针对的是数据文件;
分区提供一个隔离数据和优化查询的便利方式。 不过&…

Hive 之 查询 02-join 语句
欢迎大家扫码关注我的微信公众号: Hive 之 查询 02-join 语句一、 只支持等值 join二、 表的别名三、 内连接四、 左外连接五、 右外连接六、 满外连接八、 笛卡尔积九、 连接谓词中不支持 or一、 只支持等值 join
Hive 支持通常的 SQL JOIN 语句, 但是…
Hive窗口函数详细介绍
文章目录 Hive窗口函数概述样本数据表结构表数据 窗口函数窗口聚合函数count()SQL演示 sum()SQL演示 avg()SQL演示 min()SQL演示 max()SQL演示 窗口分析函数first_value() 取开窗第一个值应用场景SQL演示 last_value()取开窗最后一个值应用场景SQL演示 lag(col, n, default_val…
【大数据】Hive系列之- Hive-DML 数据操作
Hive系列-DML 数据操作数据导入向表中装载数据(Load)语法操作用例通过查询语句向表中插入数据(Insert)创建一张表插入数据基本模式插入(根据单张表查询结果)查询语句中创建表并加载数据(As Sele…

彷徨 | Hive---报表统计
联级累计报表查询
有如下数据: A,2015-01-08,5 A,2015-01-11,15 B,2015-01-12,5 A,2015-01-12,8 B,2015-01-13,25 A,2015-01-13,5 C,2015-01-09,10 C,2015-01-11,20 A,2015-02-10,4 A,2015-02-11,6 C,2015-01-12,30 C,2015-02-13,10 B,2015-02-10,10 B,2015-02-11,…

利用Yarn多队列实现Hadoop资源隔离
大数据处理离不开hadoop集群的部署和管理,对于本来硬件资源就不多的创业团队来说,做好资源的共享和隔离是很有必要的,毕竟不像BAT那么豪,那么怎么样能把有限的节点同时分享给多组用户使用而且互不影响呢,我们来研究一下…

理解数据仓库中星型模型和雪花模型
在数据仓库的建设中,一般都会围绕着星型模型和雪花模型来设计表关系或者结构。下面我们先来理解这两种模型的概念。 (一)星型模型图示如下: 星型模是一种多维的数据关系,它由一个事实表和一组维表组成。每个维表都有一…
Bug死磕之hue集成的oozie+pig出现资源任务死锁问题
[sizemedium]
这两天,打算给现有的Apache Hadoop2.7.1的集群装个hue,方便业务人员使用hue的可视化界面,来做一些数据分析任务,这过程遇到不少问题,不过大部分最终都一一击破,收获经验若干,折腾的…
Hadoop2.2.0+Hive0.13+Hbase0.96.2集成
[b][colorgreen][sizelarge]本篇,散仙主要讲的是使用Hive如何和Hbase集成,Hbase和Hive的底层存储都在HDFS上,都是hadoop生态系统中的重要一员,所以他们之间有着很亲密的联系,可以相互转换与操作。hadoop,hb…
hive任务reduce步骤卡在99%原因及解决
我们在写sql的时候经常发现读取数据不多,但是代码运行时间异常长的情况,这通常是发生了数据倾斜现象。数据倾斜现象本质上是因为数据中的key分布不均匀,大量的数据集中到了一台或者几台机器上计算,这些数据的计算速度远远低于平均…
Hive中order by,sort by,distribute by和cluster by详解
前言
作为数据开发工程师,在平时工作中,肯定接到过产品小姐姐提的排序需求,例如在mysql数据库中,就是使用order by函数。在hive中也是有order by函数的,那么除了order by之外是否还有其他排序函数呢?今天就跟小伙伴们聊聊hive中有哪些排序函数以及使用场景!
1. order …
HIVE的DDL DML随笔
DDL数据库的增删改查注释显示数据库show databases;*:占位符,占多位,%:占位符,占一位show databases like big*;显示数据库信息desc database database_name;desc:describedesc database extended database_name;创建数据库create database database_name;数据库在 …

Hadoop之Hive基本操作
Hadoop之Hive基本操作Hive数据库操作创建数据库查看数据库查看数据库详细信息切换数据库删除数据库修改数据库属性Hive数据类型基础数据类型复制数据类型Hive数据表操作数据库编码问题语法格式创建数据表查看数据表查询表类型查询表结构插入数据查询数据修改数据表删除数据表内…

大数据项目实战---电商埋点日志分析(第五部分,DWS层之用户活跃主题)
1)创建用户按天明细表,dws_uv_detail_day并加载数据。 2)创建用户按周明细表,dws_uv_detail_wk并加载数据。 3)创建用户按月明细表,dws_uv_detail_mn并加载数据。 下一章 https://blog.csdn.net/hailunw/ar…
Hive UDF自定义函数上线速记
0. 编写hive udf函数jar包
略
1. 永久函数上线
1.1 提交jar包至hdfs
使用命令or浏览器上传jar到hdfs,命令的话格式如下 hdfs dfs -put [Linux目录] [hdfs目录] 示例:
hdfs dfs -put /home/mo/abc.jar /tmp1.2 将 JAR 文件添加到 Hive 中
注意hdfs路径前面要加上hdfs://na…
hive:创建自定义函数 UDF
编写Apache Hive用户自定义函数(UDF)有两个不同的接口,一个非常简单,另一个相对复杂点: 简单API: org.apache.hadoop.hive.ql.exec.UDF 复杂API: org.apache.hadoop.hive.ql.udf.generic.GenericUDF 如果你的函数读和返回都是基础数据类型(Hadoop&Hive 基本writab…
Hive 用户访问路径明细表计算
用户访问路径分析: 用户访问路径明细记录表 源表:DWD_APP_TFC_DTL_DEMO 目标表:DWD_APL_RUT_DTL
源表DWD_APP_TFC_DTL_DEMO表结构:
hive>create table DWD_APP_TFC_DTL_DEMO(
guid bigint,
eventid String,
event Map<String…
hive或者impala如何根据字段找到表
hive或者impala如何根据字段找到表
举个例子,我想在知道有一个字段叫做user_ip,但是我不知道这个字段存放在哪个表里面,怎么办呢? 我希望有一种可以通过字段名称,反向查找表名的功能。 这个功能在mysql中已经有了。 但…
快速入门数据仓库(Data WareHouse)
在很久很久之前,异世界里生活着许许多多的种族,有人类、有精灵、有兽人,还有哥布林、魔王… 这个异世界的神想要统一的管理这些种族,于是神打造了多个象征权力的戒指,分发给每个种族的首领——这个戒指可以帮助他们更…

【Impala】基于Hive的快速大数据查询引擎——Impala知识点总结
content Impala简介Impala系统架构Impala核心组件Impala查询执行过程Impala的优缺点Impala与Hive的比较 Impala简介
Impala是由Cloudera公司开发的新型查询系统Imapla提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据Impala基于MPP (Massive…
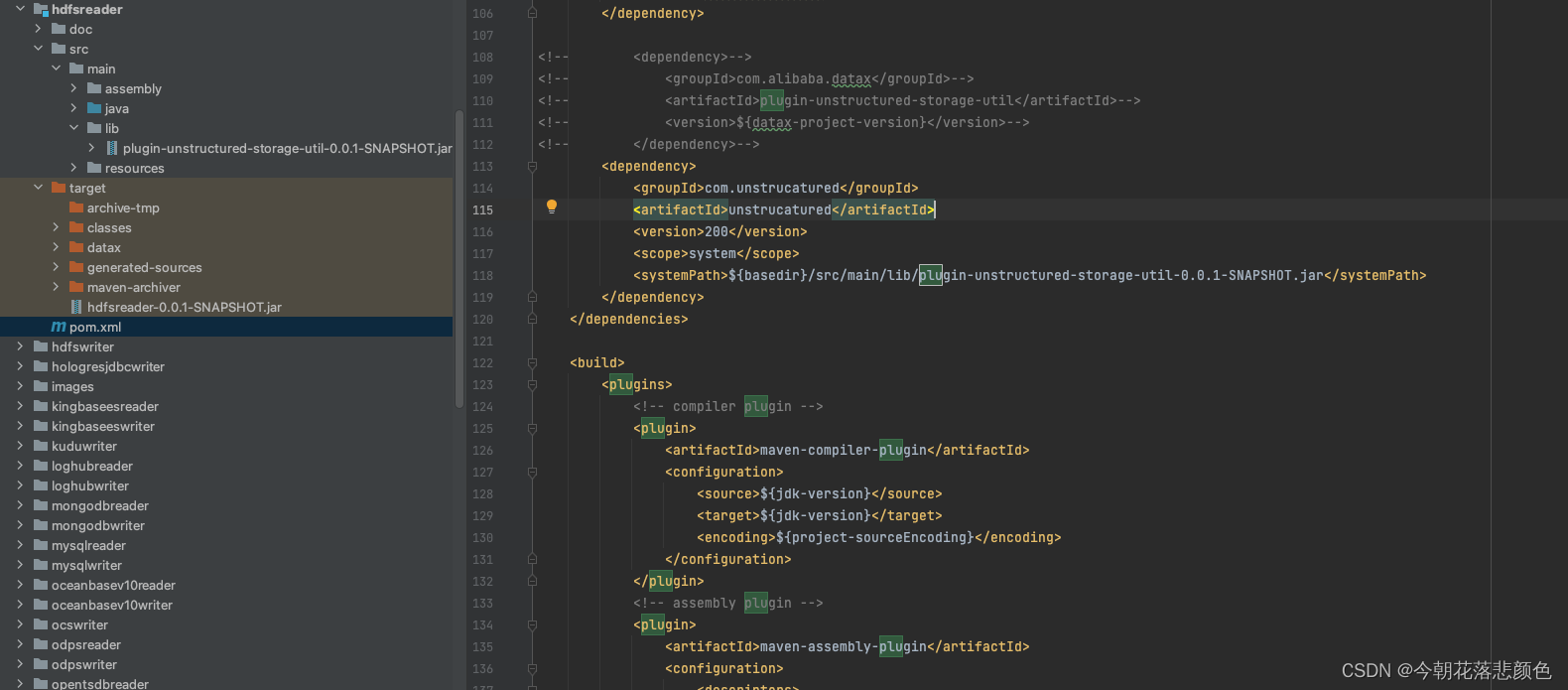
DATAX hdfsreader orc格式读取数据丢失问题
最近做一个数据同步任务,从hive仓库同步数据到pg,Hive有4000w多条数据,但datax只同步了280w就结束了,也没有任何报错。
看了下datax源码,找到HdfsReader模块DFSUtil核心实现源码读取orc格式的文件方法: pu…
清空hive表 姿势大全
-- 清空分区表 清空hive表 hive分区表清空 清空hive分区表
为什么着重强调分区表,因为分区表清空可能会因为分区过多导致清理速度特别慢. 方式1 truncate table tb1(分区表注意)
注意事项:
truncate table不会删除hdfs 分区文件夹,只会删除parquet文件,所以结果就是一堆分区…

hive数据库hql基础操作02
1.内部表和外部表
默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。换句话说,Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。当你删除内部表时,它会删除数据以及表的元数据。可以使…

最详细的HiveHBase
Hive
一 Hive基本概念
1 Hive简介 1.1 什么是 Hive
Hive 由 Facebook 实现并开源,是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据映射为一张数据库表,并提供 HQL(Hive SQL)查询功能,底层数据是存储在 HDFS 上。Hive 本质…
1.数据仓库基本理论
1.数据仓库
概念: 数据仓库是一个用于存储、分析、报告的数据系统 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策
特点: 数据仓库本身并不“生产”任何数据,其数据来源与不同外部系统 同时数据仓库自身…
【学习记录】大数据课程-学习十五周总结
4.2.数据库表操作
4.2.1.创建数据库表语法 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], …)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], …)] [CLUSTERED BY (col_name, co…
大数据开发之 Impala介绍
Impala 介绍 Impala 主要特点Impala与 Hive的异同之处 Impala 是 Cloudera 开源的一个高性能、分布式、SQL 查询引擎,用于Apache Hadoop 上进行交互式数据分析。Impala 可以实现实时的 SQL 查询操作,最初是为了解决 Hive-MapReduce 处理速度慢的问题&…
3.Hive SQL数据定义语言(DDL)
1. 数据定义语言概述
1.1 常见的开发方式
(1) Hive CLI、Beeline CLI Hive自带的命令行客户端 优点:不需要额外安装 缺点:编写SQL环境恶劣,无有效提示,无语法高亮,误操作率高
(2&…
hive 上传数据和创建表格
上传数据
load data local inpath (你的文本路径) overwrite into table 表明创建表格(内部表)
CREATE TABLE dmp_sdm_develop.tmp_exchange( session_id string, mobile string, device_info string)ROW FORMAT DELIMITE…
Hive自定义UDF,UDTF函数
自定义UDF,UDTF,UDAF函数
(1) 自定义UDF:继承UDF,重写 evaluate 方法
(2) 自定义 UDTF:继承自 GenericUDTF,重写 3 个方法:initialize(自定义输出的列名和类型)&#x…
在虚拟机上安装MySQL和Hive
文章目录 零、学习目标一、Hive概述(一)Hive的SQL - HQL(二)数据库与数据仓库(三)Hive的适用场景二、下载、安装和配置MySQL(一)下载MySQL组件压缩包(二)将MySQL组件压缩包上传到虚拟机(三)删除系统自带的MariaDB1、查询mariadb2、删除mariadb(四)安装MySQL组件1…
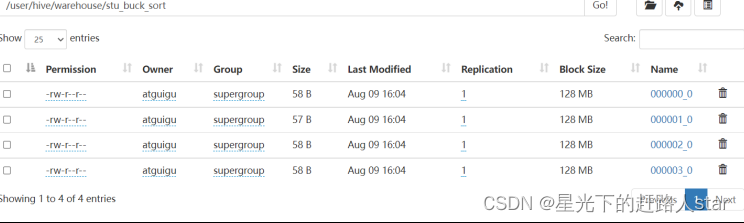
Hive学习---5、分区表和分桶表
1、分区表和分桶表
1.1 分区表
Hive中的分区就是把一张大表的数据按照业务需求分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。
1.1.1 分区表基本语法
1、创建…
Spark SQL数据源:Hive表
文章目录 一、Spark SQL支持读写Hive二、Spark配置hive-site.xml三、准备工作(一)启动Hive的metastore(二)启动Spark Shell 四、Spark读写Hive数据(一)导入SparkSession(二)创建Spar…

3.完成ODS层数据采集操作
将原始数据导入mysql 1 选中mysql 运行脚本 2 验证结果 数据存储格式和压缩方案 存储格式 分类 1.行式存储(textFile) 缺点:可读性较好 执行 select * 效率比较高 缺点:耗费磁盘资源 执行 select 字段 效率比较低 2.列式存储(orc) 优点:节省磁盘空间. 执行 select 字段…
【大数据之Hive】十七、Hive-HQL函数之自定义函数
1 概述 当Hive提供的内置函数无法满足业务处理需求时,可以通过自定义UDF函数来扩展。
用户自定义函数类别: (1)UDF(User-Defined-Function):一进一出。 (2)UDAF…

记录hive无法创建表的问题
一.报错异常如下:
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:An exception was thrown while adding/validating class(es) : Column length too big for column PARAM_VALUE (max 21845); use BLOB or T…
Hive面试题系列第二题-行转列问题
视频讲解地址:https://www.bilibili.com/video/BV1BG4y1v7Ps/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第二题-行转列问题 题目:求语文课程成绩大于英语课程成绩的学生的学号 表结构:
create table score_t…
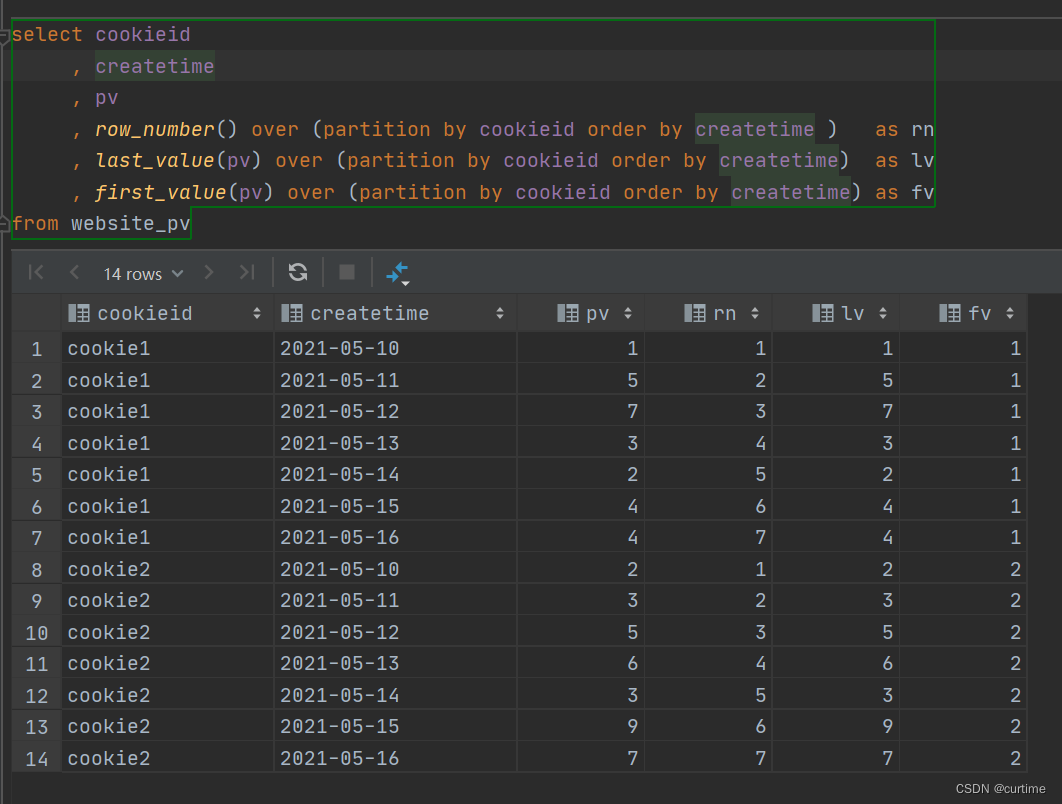
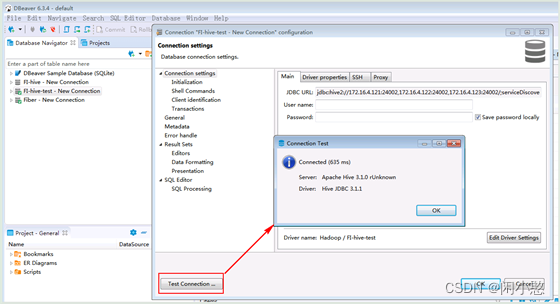
Dbeaver连接Hive数据库操作指导
背景:由于工作需要,当前分析研究的数据基于Hadoop的Hive数据库中,且Hadoop服务端无权限进行操作且使用安全模式,在研究了Dbeaver、Squirrel和Hue三种连接Hive的工具,在无法绕开useKey认证的情况下,只能使用…
hive 列转行与行专列
1. 行转列
SQL SERVER 2005 提供了行转列方法pivot(),以及列转行unpivot()方法;
但hive 里面没有自带pivot函数,以下为自己实现:
实现将原始表 转为目标表 11
select name
,sum(if(coursemath, score, null)) as math
,sum(if…
hive left join 字段不一致
两个hive表left join时,由于关联字段类型不同导致的数据错误(bigint、string),结果会多出来一批数据。
select a.id as id1
,b.id as id2
from table1 a
left join table2 b
on a.id b.id
where a.id 1257829907772824682
-- 1…

hive sql行转列后 列转行
TOC](hive sql行转列后 列转行)
场景: 对拼接的手机号拆分后解密,解密完再拼接 总结 使用函数:concat_ws(’,’,collect_set(column))
说明:collect_list 不去重,collect_set 去重。 column的数据类型要求是string

Hive与SparkSQL语法差异
一、相同函数差异
1、Spark运行时用到的hash函数,与Hive的哈希算法不同,如果使用hash(),结果和Hive的hash()会有差异
2、Hive和SparkSQL使用grouping sets生成的GROUPING_ID不一致
3、regexp_extract未匹配上的话,在HIVE里返回…
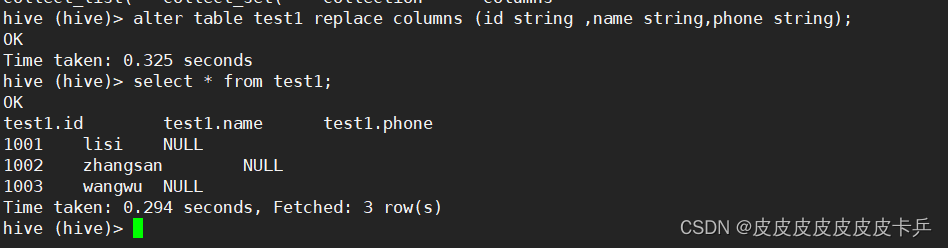
Hive——操作数据库创建修改表(DDL数据定义)
DDL操作1. 数据库操作1.1 创建&查询数据库1.2 修改&删除数据库2. 表操作2.1 创建表2.2 内部表和外部表2.2.1 管理表2.2.2外部表2.2.3管理表与外部表的互相转换2.3 修改表1. 数据库操作
1.1 创建&查询数据库
定义:
CREATE DATABASE [IF NOT EXISTS] d…

Hive内部表与外部表的区别具体说明
目录
1.在/opt/atguigu/目录下,新建两个txt文件
2.在hadoop的web端递归创建一个目录,存储这两个文件
3.查看web端的文件
一、内部表:
1.创建一个内部表,并指定内部表的存储位置
2.查看内部表,内部表中没有数据
…
数据分析-Python连接hive数据库
Python连接hive数据库基于Python建立hive库的连接涉及的python的第三方库code实现(Talking is cheap.)基于Python建立hive库的连接
python🔗一切database
涉及的python的第三方库
python连接dataphin中的hive库,主要涉及&#…
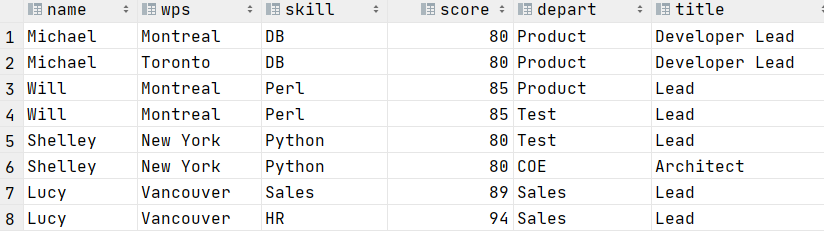
Hive建表高阶语句
CTAS -as select方式建表CREATE TABLE ctas_employee as SELECT * FROM employee;CTE (CTAS with Common Table Expression)CREATE TABLE cte_employee AS
WITH
r1 AS (SELECT name FROM r2 WHERE name Michael),
r2 AS (SELECT name FROM employee WHERE gender Male),
r3 …
Hive优化十八般兵器
前言
Hive 是一个基于 Hadoop 的数据仓库框架,用于处理和分析大量的结构化数据。在 Hive 中,我们可以编写类似于 SQL 的查询语句(HiveQL)来对数据进行处理。下面是一些 Hive 中的 SQL 优化示例,包括具体的数据结构、S…
如何用Spark SQL实现多Catalog联邦查询
目前对多Catalog的支持俨然成为计算引擎的标配,因为在OLAP场景,跨数据源的联合查询是一大刚需。但是,传统的计算引擎如Hive、Spark2对多Catalog支持能力很弱,也许是受Flink、Presto(Trino)的步步紧逼&#…
hive运算时类型自动转化问题
比如table id int ,name string
我们可以
select * from table where id1
select * from table where name1
select * from table where namecast(1 as decimal)
这些都不会报错,因为涉及到了类型的自动转化。
但是 当我们有 nvl(1,1)时 结果类型时什么样呢…

【大数据离线开发】8.2 Hive的安装和配置
8.3 Hive的安装和配置
安装模式:
嵌入模式 :不需要使用MySQL,需要Hive自带的一个关系型数据库:Derby本地模式、远程模式 ----> 需要MySQL数据库的支持
安装 hive 安装包
1、解压tar -zxvf apache-hive-2.3.0-bin.tar.gz -C…

Hive 之 管理表、外部表、分区表
欢迎大家扫码关注我的微信公众号: Hive 之 管理表、外部表、分区表一、 管理表(内部表):二、 外部表:三、 管理表与外部表转换:3.1 内转外:3.2 外传内:四、 分区表:4.1 …

hive静态分区和动态分区
目录
一:静态分区和动态分区介绍
二:静态分区和动态分区区别
三:样例
四:动态分区参数 一:静态分区和动态分区介绍
1、静态分区与动态分区的主要区别在于静态分区是手动指定,而动态分区是通过数据来进…


Hive 之 查询 01-基本查询、where子句、分组
欢迎大家扫码关注我的微信公众号: Hive 之 查询 01-基本查询、where子句、分组一、 基本查询1.1 全表和特定列查询(select ... from)1.1.1 全表查询:1.1.2 特定列查询:1.2 列别名1.2.1 重命名一个列;1.2.2…
Hive 分区表新增字段 cascade
背景
在以前上线的分区表中新加一个字段,并且要求添加到指定的位置列。
模拟测试
加 cascade 操作
创建测试表
create table if not exists sqltest.table_add_column_test(org_col1 string comment 原始数据1,org_col2 string comment 原始数据2
)
comment 增…

Hive的UDF实现两种简单方法+通过编译源码添加UDF
Hive的UDF实现两种简单方法通过编译源码添加UDF
一、实现简单的say_hello
1、打开IDE在pom.xml中添加如下
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version>
</de…
【面试】-- Hive高频面试题目
一、请描述一下数据倾斜,并提供解决方案? 定义:由于数据分布不均匀,导致大量数据集中到一点,造成数据热点。现象是100个 task, 有一个运行了 1个小时,其他99个只有 10分钟。本质是数据量太大。原因:key 分布不均匀、sql倾斜join、建表时类型有问题算子:count、dist…

数据仓库Hive——DML和查询(上)
文章目录三、DML操作1.数据导入1.1Load给表里装入数据1.2通过查询语句向表中插入数据2.数据导出2.1Insert导出2.1.1将查询结果导出到本地2.1.2将查询结果格式化导出到本地2.1.3将查询结果格式化导出到HDFS上2.2Hadoop命令导出到本地2.3Hive Shell命令导出2.4Export导出到HDFS上…

那些年,启动hive踩过的坑
相信你打开这篇博客的时候,你应该也是遇到了启动hive失败的坑。
在安装hive的时候,我们可能遇到了不少的坑,特别是在安装完成,启动hive的时候,他就是启动不成功,报错。经过几天的实战总结了一些经验。
问…

【Hive】位于Hadoop顶层的数据仓库——Hive知识点总结(图解)
content Hive简介Hive工作原理Hive系统架构Hive HAHive编程 Hive简介
▍初见
Hive是一个构建于Hadoop顶层的数据仓库工具某种程度上的用户编程接口——因为Hive本身不存储和处理数据Hive依赖分布式文件系统HDFS存储数据Hive依赖分布式并行计算模型MapReduce处理数据定义了简单…

Hive 统计连续天数
第一步:创建表
-- 创建表
create table if not exists continue_days(
uid int comment 员工id,
tdate string comment 打卡日期,
is_flag int comment 是否打卡)
comment 打卡表
row format delimited fields terminated by ,; 第二步:加载示例数据
-…
sql基础统计,及pandas实现
目录
1 查询前N行
2 查询特定列
3 查询某列的去重数据
4 根据条件筛选数据
5 分组计数
6 按某列分组后,对其它列进行统计
7 横向连接表
8 纵向连接表
9 分组后排序
10 按条件分组
11 按条件更新某个值
12 按条件删除行
13 删除列
14 提取/匹配字符串 …
推荐系统搭建全程图文攻略
推荐系统搭建全程图文攻略 推荐系统架构简介 整体推荐架构图:
推荐整体从数据处理开始,默认数据从关系型数据到每天增量导入到hive,在hive中通过中间表和调用python文件等一系列操作,将数据处理为算法数学建模的入口数据&#x…
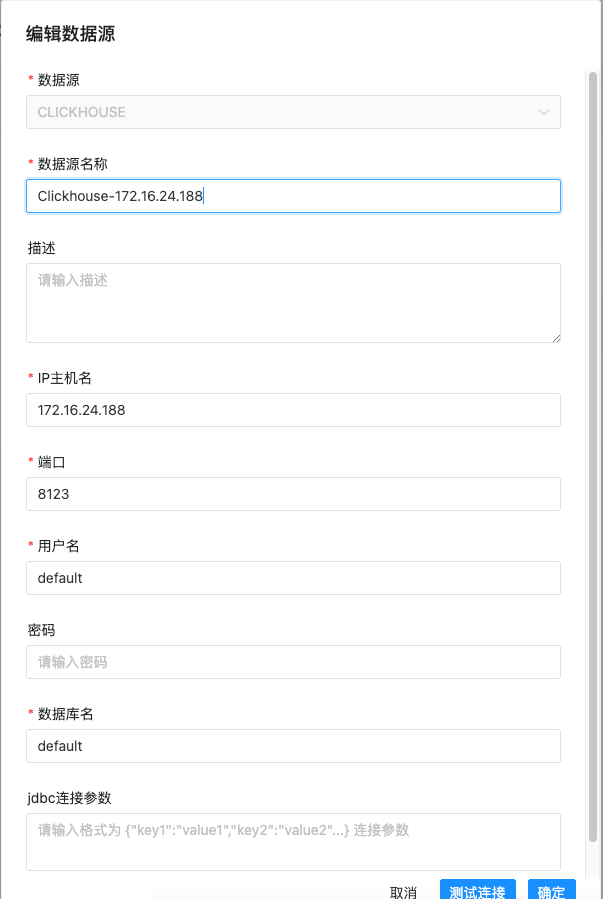
02.DolphinScheduler数据源中心
文章目录 MySQLHIVE数据源使用HiveServer2使用 HiveServer2 HA Zookeeper Clickhouse MySQL
填写参数
数据源:选择 MYSQL数据源名称:输入数据源的名称描述:输入数据源的描述IP 主机名:输入连接 MySQL 的 IP端口:输入…

从零搭建hive环境_ jdk 8 + SSH + hadoop 2.9.2 + hive 3.1.2
目录
一、Ubuntu18.04 安装 jdk 8
二、安装SSH
三、安装hadoop 2.9.2
四、安装hive 3.1.2 Windows 虚拟机安装 Ubuntu18.04 Vim Mysql5.7参照 https://blog.csdn.net/zhsworld/article/details/103740953 一、Ubuntu18.04 安装 jdk 8
1 官网下载 jdk8安装包 2 将jdk8安装…

Java通过poi读取excel中文件
maven依赖 <dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.12</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxm…
Hadoop 4:Hive
数据仓库概念 数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持(Decision Support&#x…
6.Hive函数重要应用案例
1.Hive中的分隔符
默认规则 Hive默认序列化类是LazySimpleSerDe,其中支持使用单字节分隔符(char)来加载文本数据。根据不同文本文件的分隔符,我们可以通过在创建表时使用row format delimited来指定文件中的分隔符。
row_format: DELIMITED…
【Hive实战】Hive 物化视图
Hive 物化视图 (Materialized views) 始于Hive3.0.0 文章目录 Hive 物化视图 (Materialized views)目标Hive中物化视图的管理创建物化视图物化视图管理的其他操作 基于物化视图的查询重写物化视图的维护物化视图的生命周期 目标
传统上,用于…
Hive(16):Partition(分区)DDL操作
1 Add partition
分区值仅在为字符串时才应加引号。位置必须是数据文件所在的目录。
ADD PARTITION会更改表元数据,但不会加载数据。如果分区位置中不存在数据,查询将不会返回任何结果。
--1、增加分区
ALTER TABLE table_name ADD PARTITION (dt=20170101) location /use…

Hive SQL语句的正确执行顺序
关于 sql 语句的执行顺序网上有很多资料,但是大多都没进行验证,并且很多都有点小错误,尤其是对于 select 和 group by 执行的先后顺序,有说 select 先执行,有说 group by 先执行,到底它俩谁先执行呢&#x…
sparksql 与flinksql 建表 与 连表记录
启动flink sql:bin/sql-client.sh
建表
flink建立表
create table iceberg.xxx.xxx
(id STRING comment id,dt STRING comment 分区字段
)PARTITIONED BY (dt)
with (write.format.default parquet, --指定文件存储格式,默认parquetwrite.parquet.c…
pyspark 写入数据到iceberg
pyspark环境搭建
1.D:\Python\python37\Lib\site-packages\pyspark\jars 放入 iceberg-spark3-runtime-0.13.1.jar alluxio-2.6.2-client.jar
2.D:\Python\python37\Lib\site-packages\pyspark 创建conf文件夹 放入 hdfs-site.xml hive-site.xml
代码 import os
import warn…

使用MSCK命令修复Hive表分区
转载网址: http://blog.csdn.net/opensure/article/details/51323220 http://www.cnblogs.com/chinhr/archive/2007/10/17/927506.html http://blog.csdn.net/sparkexpert/article/details/51024392?locationNum5&fps1 http://hadoop.apache.org/docs/r1.0…
Hive SQL执行失败问题记录
概述
Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
Hive数据源跑SQL失败报错信息:Error while processing statement: FAILED: Execution Error, return code 2 from org.apach…
Hive的3种执行引擎区别与适用场景
1. Hive的3种执行引擎适用场景
● Hive底层的计算由分布式计算框架实现,目前支持三种计算引擎,分别是MapReduce、Tez、 Spark。 ● Hive中默认的计算引擎是MapReduce ,由hive. execution. engine参数属性控制。
MapReduce引擎:多job串联,基于磁盘&…
HiveSQL语法练习及答案(三)
文章目录Hive数据表练习建表语句SQL练习Hive数据表练习
建表语句
员工信息表emp:
字段:员工id,员工名字,工作岗位,部门经理,受雇日期,薪水,奖金,部门编号
英文名:EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,BONUS,DEPTNO
create table emp(EMPNO in…

Hive静态分区和动态分区(二)
文章目录Hive静态分区和动态分区1. 静态分区1.1 增加3个分区向每个分区中添加数据1.2 查询数据1.2.1 直接查询1.2.2 添加分区信息查询2. 动态分区开启Hive的动态分区支持2.2 建原始表2.3 建立分区表2.4 加载数据3. 多级分区Hive静态分区和动态分区
1. 静态分区
建立分区表
c…

Apache Ranger控制功能
Apache Ranger控制功能# Apache Ranger 是一个在hadoop平台上使用的组件,可以全面监控和管理数据的安全。有关Ranger的安装见我另一篇博客ranger的安装及问题解决。
Apache Ranger目前支持的组件如下 Ranger-usersync用于同步linux的用户和用户组,在ran…

读取yaml文件,生成runtimeObject
读取yaml文件,生成runtimeObject
package mainimport ("bytes""io/ioutil""k8s.io/apimachinery/pkg/apis/meta/v1/unstructured""k8s.io/apimachinery/pkg/runtime/serializer/yaml""log"
)func main() {yamlB…
比较Hive,Spark,Impala和Presto (转载)简单了解它们都是干什么的而已(转载)
原文地址:如何比较Hive,Spark,Impala和Presto? - 知乎
原文的翻译多少有点瑕疵
Spark,Hive,Impala和Presto是基于SQL的引擎,Impala由Cloudera开发和交付。在选择这些数据库来管理数据库时&…
HIVE通过jdbc连接,使用insert into插入中文数据乱码
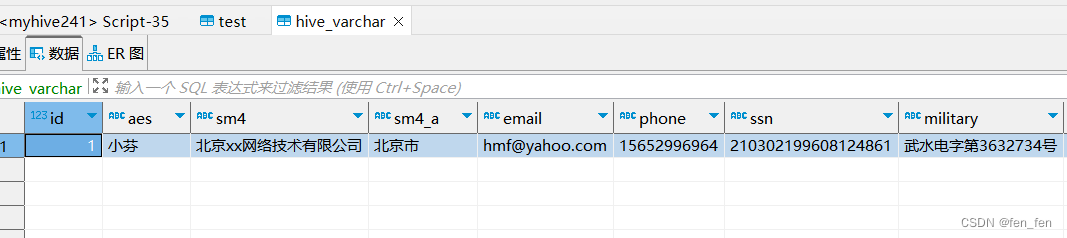
HIVE通过jdbc连接,使用insert into插入中文数据乱码 [2023-03-21 21:36:31] Fetched row string: 1 � �xxQ܀/ Pl� � hmfyahoo.com 15652996964 210302199608124861 f45W,3632734&#x…
Hive执行异常org.apache.hadoop.hdfs.BlockMissingException
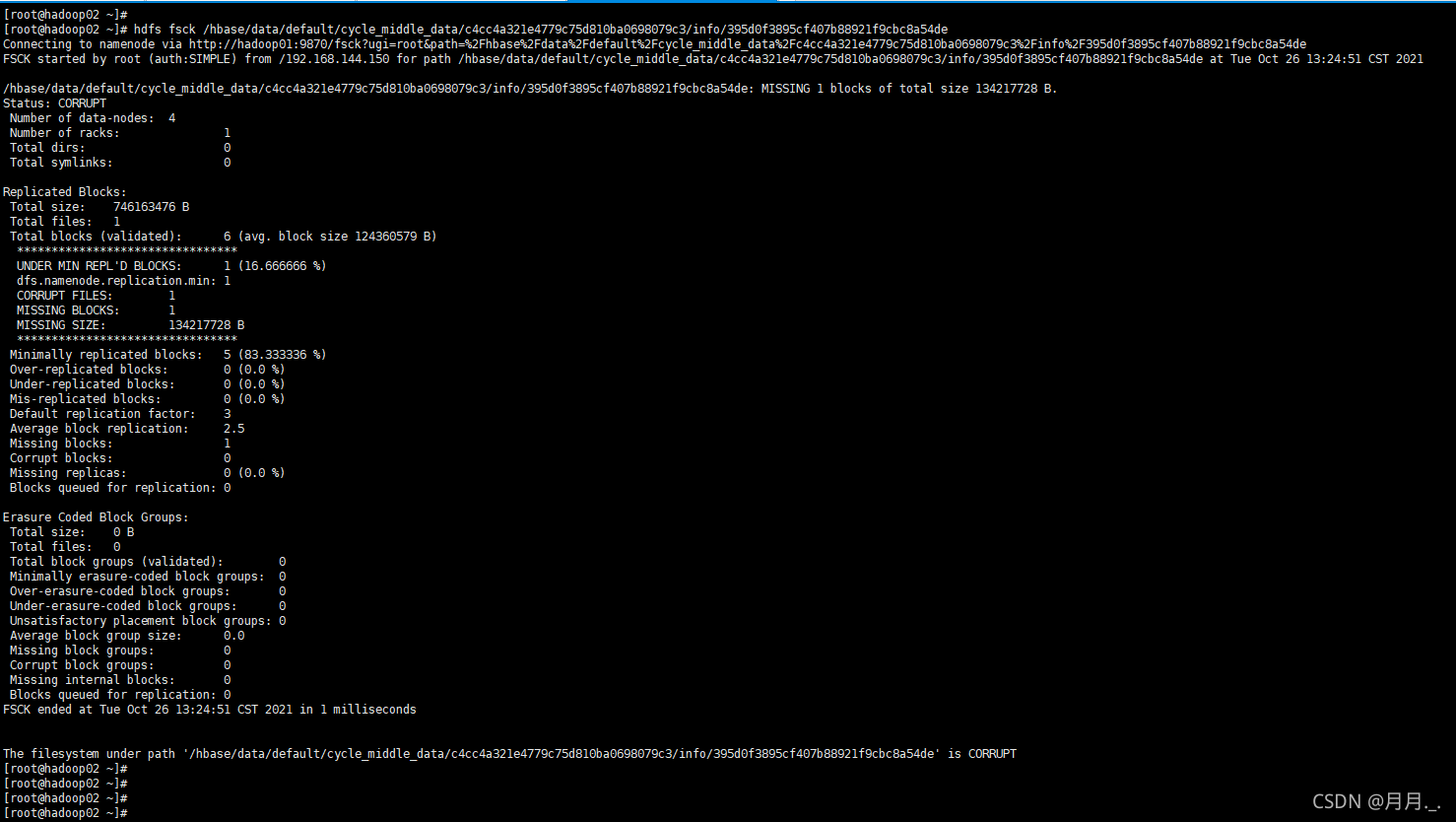
今天hive在执行的时候出现了报错,内容如下:
Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-2040810143-192.168.144.145-1612269795515:blk_1077591653_3851069 file/hbase/data/default/cycle_middle_data/c4…

trino的介绍和安装使用
前言:
最近在研究大数据的一些组件和数据库,本来是要调研下presto怎么用的,结果发现presto因为facebook的关系,导致presto核心开发成员离开, 重新开始创建了trino,个人感觉trino发展会更好,因为…
MetaException(message:Add request failed : INSERT INTO `COLUMNS_V2`....
异常信息:MetaException(message:Add request failed : INSERT INTO COLUMNS_V2 (CD_ID,COMMENT,COLUMN_NAME,TYPE_NAME,INTEGER_IDX) VALUES (?,?,?,?,?) )
报错背景: Hive创建带有中文字段的表。
解决办法: 修改Mysql的COLUMNS_V2表…

Hive 3.1.2安装教程(亲测有效)
Hive 3.1.2安装教程 安装所需的环境 1.ubuntu 18.04 2.hadoop 3.2.1 3.jdk 1.8
4.mysql 5.7 一、Hive的安装 1.hive下载地址:传送门 2.解压
cd ~/下载
sudo tar -zxvf ./apache-hive-1.2.1-bin.tar.gz -C /usr/local
cd /usr/local/
sudo mv ./apache-hive-1.2.1-…
Hive10---explode拆分多行
Intro hive explode操作
import pysparkfrom pyspark.sql import SparkSession
# 创建SparkSession对象,调用.builder类
# .appName("testapp")方法给应用程序一个名字;.getOrCreate()方法创建或着获取一个已经创建的SparkSession
spark Spa…
Hive08---插入数据
分区表插入一条数据至指定分区表
INSERT INTO test_db.table1 PARTITION(ds20210922)
VALUES (123, abc)Ref
[1] https://dwgeek.com/hive-insert-into-partition-table-and-examples.html/
hive中好用的函数
参考: Hive常用函数总结
1. 字符串相关
1.1 字符串替换
select regexp_replace(\n123\n,\n,);
select translate("MOBIN","BIN","M");
-- MOM1.2 查找子串位置
集合查找函数: find_in_set 返回以逗号分隔的字符串中str第一次出现的位置&…
hive字符串拼接常用方法
hive中常用的一些拼接函数
1. concat() 实现把若干个字段(字段类型可不相同)数据拼接起来
用法: concat(string a1, int a2, float a3)
select concat("aa", 11, 2.2);
aa112.2不同字段之间用分隔符连接("_")
select concat("aa","…
15. 查询所有用户的连续登录两天及以上的日期区间
文章目录 题目需求思路一实现一题目来源 题目需求
从登录明细表(user_login_detail)中查询出,所有用户的连续登录两天及以上的日期区间,以登录时间(login_ts)为准。
期望结果如下:
user_id (…

Hive编程指南-学习笔记(四) 查询
一、SELECT ... FROM ...语句
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRAY<STRING>,
deductions MAP<STRING,FLOAT>,
address STRUCT<street:STRING,city:STRING,state:STRING,zip:INT>)
PARTITIONED B…

Hive编程指南-学习笔记(五) 查询内置函数
1、数学函数 2、聚合函数 可以通过设置属性值来提高聚合的性能,需要更多的内存。
SET hive.map.aggrtrue;
3、表生成函数
表生成函数,与聚合函数的过程相反,将单列扩展成多列或者多行。
举例:
hive> SELECT explode(subor…

基于Hadoop的豆瓣电影的数据抓取、数据清洗、大数据分析(hdfs、flume、hive、mysql等)、大屏可视化
目录 项目介绍研究背景国内外研究现状分析研究目的研究意义研究总体设计数据获取网络爬虫介绍豆瓣电影数据的采集 数据预处理数据导入及环境配置Flume介绍Hive介绍MySQL介绍Pyecharts介绍环境配置及数据加载 大数据分析及可视化豆瓣影评结构化分析豆瓣电影类型占比分析豆瓣电影…

Hive编程指南-学习笔记(三) 数据操作
一、向管理表中装载数据
Hive没有行级别的数据插入、更新和删除操作,往表中装载数据的唯一途径就是使用一种“大量”的数据装载操作。
LOAD:向表中装载数据
(1)把目录‘/usr/local/data’下的数据文件中的数据装载进usr表&…

Hive编程指南-学习笔记(二) 数据定义
一、数据库
1、创建数据库:CREATE DATABASE hive;
如果已经存在,会抛出异常,下面的语句不抛出异常:CREATE DATABASE IF NOT EXISTS hive;
数据库的默认位置是hdfs上:/user/hive/warehouse,修改默认位置&…
win10用jdbc连接hiveserver报错client_protocol没有定义
背景
用jdbc连接hiveserver2报错,主要内容如下:
Required field client_protocol is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size1000, use:databasedefault…

Atlas2.1.0实战:安装、配置、导入hive元数据、编译排坑
背景 随着公司数据仓库的建设,数仓hive表愈来愈多,如何管理这些表? 经调研,Atlas成为了我们的选择对象,本文是Atlas实战记录,感谢尚硅谷的学习视频 1.Atlas概述
1.1 Apache Atlas 的主要功能
元数据管理和…

MongoDB数据导入Hive
MongoDB数据导入Hive
方法和Hbase导入hive类似,区别在于,需要现在Mongodb设置一个账户
创建用户
进入mongodb后开始操作:
//创建管理员账户 userAdminAnyDatebase 为管理员权限,可以管理,不能关闭数据库
> use…

Hive自定义函数GenericUDF
文章目录Hive自定义函数GenericUDF编写代码生成jar包使用jar包创建函数Hive自定义函数GenericUDF
编写代码
依赖包继续使用上一篇介绍的内容,这里不做赘述,直接进入代码内容;
Description(name "arrContains",value "loo…

Hive自定义标准函数(UDF)
文章目录Hive自定义标准函数(UDF)继承UDF类或GenericUDF类添加依赖包继承UDF类重写evaluate()方法并实现函数逻辑打包为jar文件编译复制到正确的HDFS路径使用jar创建临时/永久函数创建临时函数并调用创建永久函数并调用总结Hive自定义标准函数(UDF)
继承UDF类或GenericUDF类
…

Hive的视图和侧视图
文章目录Hive的视图和侧视图Hive的视图什么是视图视图的优点视图的语法Hive的侧视图总结视图侧视图Hive的视图和侧视图
Hive的视图
什么是视图
1、通过隐藏子查询、连接和函数来简化查询的逻辑结构
2、虚拟表,从真实表中选取数据
3、只保存定义,不存…

Hive编程指南-学习笔记(一) 数据类型和分隔符
一、Hive概述
Hive定义了类似SQL的查询语言——HiveQL,用户编写HiveQL语句运行MapReduce任务,查询存储在Hadoop集群中的数据。
HiveQL与MySQL最接近,但还是有显著性差异的。Hive不支持行级插入、更新操作和删除操作。Hive不支持事务。HiveQ…
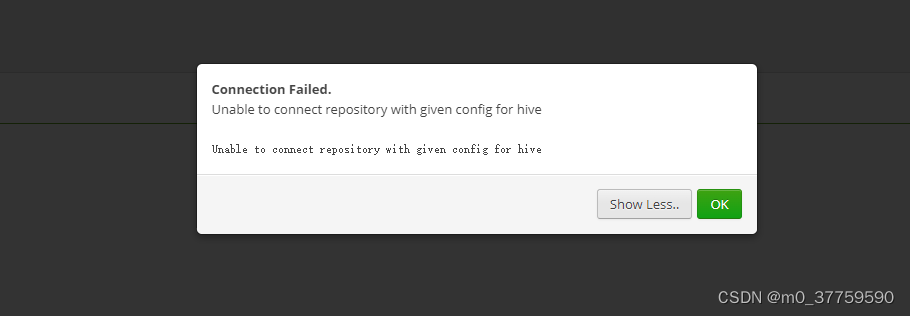
ranger配置hive出錯:Unable to connect repository with given config for hive
ranger配置hive出錯:Unable to connect repository with given config for hive 我一開始我以為是我重啟了ranger-admin導致ranger有點問題,後面排查之後發現是我之前把hiveserver2關閉了,所以只需要重新開啟hiveserver2即可

Hive案例:用户画像
1)原文件如下
字段分别为用户号,下单时间(unixtime),拿到数据的日期、地址、电话;字段间以\t分割,20160219可作为分区名
11723 1249488000 20160219 阳光大道101号8号楼158 1387483647
17955 1259…
sqoop导入数据遇到的参数问题 ,导出–staging-table
sqoop import参数
–query "select XXXXX and $CONDITIONS " 按条件导入
-m1 指定map
在导入的时候采用指定–columns的方式来进行导入 sqoop import --hive-import --hive-database test --create-hive-table --connect jdbc --username user–password user–bi…
元数据管理-技术元数据解决方案
前言
概念 元数据是描述企业数据相关的数据,指在IT系统建设过程中所产生的有关数据定义,目标定义,转换规则等相关的关键数据,包括对数据的业务、结构、定义、存储、安全等各方面对数据的描述 元数据是数仓建设环节中不可缺少的…
hive,从0点到23点用01二进制表示,取字符串转数组,数组炸裂带下标
5、场景题,如下所示为某APP软件用户的上线信息 姓名 24小时上线情况(从0点到23点) 张三 000000001001100000011000 李四 000000001001000000010011 王五 000000000001000000011110 … 使用hive获得结果如下 姓名 24小时上线情况 张三 8,11,12…
Spring boot with Apache Hive
转自
Maven
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.springframework.data</groupId><artifactId>…

Hive lateral view ,get_json_object,json_tuple 用法
要确保被解析的字段是string类型才可以使用json解析.解析map类型不能使用json解析,解析map类型可以使用col_name[key]获取对应key的value. lateral view:如果指定字段名则需要把lateral view查询出的列写到select中,才能在结果中出现;如果直接是select * 则自动会把lateral…
Hive中 HQL高级介绍及用法
SQL关键词执行顺序 from>where条件>group by>having条件>select>order by>limit 注意:一旦slq出现group by,后续的关键词能够操作的字段只有(分组依据字段,组函数处理结果) 常见步骤:
0…
为什么hive会出现_HIVE_DEFAULT_PARTITION分区
问题:
为什么hive表中出现_HIVE_DEFAULT_PARTITION分区?
解答:
因为在业务sql中使用的是动态分区,并且hive启用动态分区时,对于指定的分区键如果存在空值时,会对空值部分创建一个默认分区用于存储该部分…
HIVE SQL通过Lateral View + explode实现列转行
原表:
abAndy<碟中谍>,<谍影重重>,<007>MOMO<小鞋子>,<朋友啊你的家在哪里>
实现效果
abAndy<碟中谍>Andy<谍影重重>Andy<007>MOMO<小鞋子>MOMO<朋友啊你的家在哪里>
实现代码:
selec…
Hive合并小文件的配置项
一、启动压缩
set hive.exec.compress.output=true;
set mapreduce.output.fileoutputformat.compress=true; 二、 输入合并
当有大量小文件时,启动合并,减少map数。
对应参数:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;--默认开启…
Hive 中 json 字符串解析之 get_json_object 与 json_tuple
前言
hive中取多个key时,为什么用了json_tuple,效率反而比get_json_object慢了一些?
文将介绍解析json字符串的两个函数:get_json_object和json_tuple。
测试表
表结构如下:
其中meta 字段数据, 数据表是 test_table
{{"a":1,"b":2},{"a&…
hue oozie OutOfMemoryError: Java heap space
报出的错误:OutOfMemoryError: Java heap space
问题出现的场景:使用hue提交spark作业
本来一个在终端使用spark-submit提交可以运行成功的程序,等配置到hue上竟然堆异常了。关键在hue上也配置了--num-executors等参数,而且和spark submit提交方式的参数一样的。优化了半…
HBase实战:HBase与Hive集成
1.1 HBase与Hive的对比 HiveHBase特点类SQL 数据仓库NoSQL (Key-value)适用场景离线数据分析和清洗适合在线业务延迟延迟高延迟低存储位置存储在HDFS存储在HDFS
1.2 HBase与Hive集成使用
1.环境准备 因为后续可能会在操作Hive的同时对HBase也会产生影响…

hive可视化工具-dbeaver
文章目录前言下载dbeaver安装连接hive前言
在黑窗口操作hive是真的麻烦,而且数据查看也不好看。所以上网去找到了dbeaver,经过一番折腾,终于搞定了。
下载dbeaver
链接:https://dbeaver.io/download/
安装
普通安装即可&…
Hive collect_set与collect_list
1.引言:
collect系列函数顾名思义就是收集,体现在hive中就是把一个key的多个信息收集起来合成一个lsit或者set,唯一的区别是后者可以去重,前者保持原始数据不变,大家也叫这个方法叫列传行,大概意思相同。下…
【hivesql】找出正常日期
select出正常的birthday及其它字段,异常的birthdayselect时 id_number、birthday 输出为空,不是更改
1.union分情况
select accountname, as birthday, dt, gender, as id_number, modify_time
from xsj_acc_real_identity_en
where dt 2022-07-10…
【hive】异常日期查找
1.日期转化为时间戳
只取前面符合日期格式的内容转为时间戳,超出格式的部分忽略,少于格式则格式不符合,date_format也是一样的
select unix_timestamp(2022-2-2, yyyy-MM-dd) unix_timestamp(2022-2-2-2, yyyy-MM-dd) --true
select unix_…
Sqoop实操案例-互联网招聘数据迁移
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…
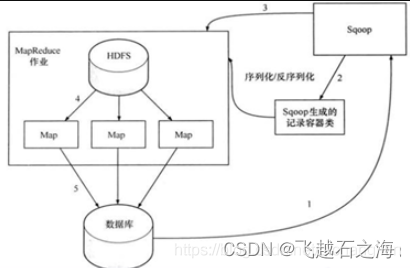
hadoop单机版配置
一、hadoop启动模式: Hadoop集群有三种启动模式:
单机模式:默认情况下运行为一个单独机器上的独立Java进程,主要用于调试环境 伪分布模式:在单个机器上模拟成分布式多节点环境,每一个Hadoop守护进程都作为…

使用元数据服务的方式访问 Hive 使用 JDBC 方式访问 Hive
目录
1.使用元数据服务的方式访问 Hive
2.使用 JDBC 方式访问 Hive 首先一定要开启hadoop集群!!!如果报错连接拒绝,注意有没有开启
1.使用元数据服务的方式访问 Hive
1)在 /opt/module/hive/conf/hive-site.xml 文…
Spark读Hive和写Hive-实例
导入Maven
<properties><spark.version>2.1.1</spark.version><scala.version>2.11.8</scala.version>
</properties>
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-…

使用hive进行数据分析及使用python进行数据可视化
使用hive进行数据分析及使用python进行数据可视化搭建hadoop集群安装hbase搭建Hive安装Hive配置环境配置bashrc配置hive-site.xml配置MySQL安装MySQL启动MySQL更改MySQL密码更改MySQL编码启动Hive使用Hive进行数据分析使用Python进行数据可视化搭建hadoop集群
参考我之前所写的…
hive的数据倾斜解决(Map端、reduce 端 、join中)
hive的数据倾斜解决(Map端、reduce 端 、join中)
lianchaozhao 2020-11-02 15:24:08 667 收藏 4 分类专栏: 工作实践 hive 大数据 文章标签: hive 大数据 版权 hive 的数据倾斜一般我们可以分为 Map倾斜、reduce 倾斜和join 倾…
Yt的Hive参数调优(Hive on Spark)
PS:Spark集群会启动Driver和Executor两种JVM进程。Driver为主控进程,负责创建Context,提交Job,并将Job转化成Task,协调Executor间的Task执行。而Executor主要负责执行具体的计算任务,将结果返回Driver
#设置这个spark任务名称
set spark.app.name=fun_seamless_newGP133…
hive分组拓展函数(grouping sets、with cube、rollup)
在做统计的时候遇到一个需求,要统计某省所有市、所有区县、所有街道的数据。第一反应是根据不同维度group by,然后union all,但是统计的指标很多,这样写出来的代码冗长无比。在group by时善用函数可以省下不少事。
with cube 维度…
hive报错 Exception thrown obtaining schema column information from datastore
报错: Exception thrown obtaining schema column information from datastore
org.datanucleus.exceptions.NucleusDataStoreException: Exception thrown obtaining schema column information from datastoreat org.datanucleus.store.rdbms.schema.RDBMSSchemaH…
hive row_number分组排序top
自从hive 0.11.0 开始,加入了类似orcle的分析函数,很强大,可以查询到分组排序top值 使用方法跟oracle没有差别 贴个小例子 查询的是同一个操作下pv前十的用户 select
*
,row_number() OVER(PARTITION BY t3.action ORDER BY pv desc) AS flag…
HIVE 第一章 数据类型
hive数据: struct(name:string,age:int) struct(dirk,36) {"street":"1 Michigan Ave.","city":"Chicago","state":"IL","zip":60600} map<String,float> map(dirk,36,kedde,38) {&qu…

Hive初始化元数据仓库:java.sql.SQLException : Access denied for user ‘hive‘@‘localhost‘ (using password: YES)
使用命令./bin/schematool -dbType mysql -initSchema初始化元数据仓库时,出现如下错误: 导致报错的原因可能并不相同,这里只写出我遇到的情况(Linux下),有两种解决方法:
方法一:检…
安装Mysql_hive
安装mysql hive
1.Mysql
##1. 安装mysql的yum源的引导
yum -y localinstall mysql-community-release-el6-5.noarch.rpm##2. 安装mysql服务
yum -y install mysql-server##3. 开启mysql服务
service mysqld start/systemctl start mysqld##4. 初始化mysql密码
mysqladmin -ur…
hive元数据库derby和mysql的区别
hive自带的内嵌元数据库是derby,derby只支持一个会话,并发性能差,实际生产不用derby,用derby的话还会遇到这样的问题:
你在哪个路径下,执行hive指令,就在哪路径下生成metastore_db,建一套数据库文件,更换目录执行操作,会找不到相…
影评项目(hive)
现有如此三份数据: 1、users.dat 数据格式为: 2::M::56::16::70072 对应字段为:UserID BigInt,Gender String,Age Int,Occupation String,Zipcode String 对应字段中文解释:用户id,性别,年龄,职…

使用with cube 、 with rollup 或者grouping sets来实现cube
0、hive一般分为基本聚合和高级聚合,而基本聚合就是常见的group by,而高级聚合就是grouping set、cube、rollup等。一般group by与hive内置的聚合函数max、min、count、sum、avg等搭配使用。
1、grouping sets可以实现对同一个数据集的多重group by操作…
hive经典查询,top-N统计,英雄出场率,判断月份连续
1、用户表操作如下:
log_action:
uid time action
1 2019-09-07 12:22:23 read
1 2019-09-07 12:23:23 write
1 2019-09-07 12:26:23 like
1 2019-09-07 12:20:23 share
3 2019-09-07 12:28:23 like
3 2019-09-07 12:29:00 read
3 2019-09-07 12:32:33 comment
4 20…

sqoop 脚本密码管理
1:背景
生产上很多sqoop脚本的密码都是铭文,很不安全,找了一些帖子,自己尝试了下,记录下细节,使用的方式是将密码存在hdfs上然后在脚本里用别名来替代。 2:正文
第一步:创建密码对…

推荐系统——数据库技术栈
数据源相关的技术栈有:
目录
一、Hadoop
二、HBase
三、Hive
四、Apollo
五、Kibana
六、Spark
七、ZooKeeper
八、Redis 一、Hadoop
1、简介:
Hadoop是在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,核心是HD…
mysql中列转行,并多个字段转到一行中的一个字段上,中间用逗号分开
mysql中列转行,并多个字段转到一行中的一个字段上,中间用逗号分开 SELECTgroup_concat(a.id SEPARATOR ,) AS idsFROM(SELECT*FROMtablenameWHERE1 1ORDER BYrand()LIMIT 10) a
TPC-DS 测试是否支持 Glue Data Catalog?
在上一篇文章《在Hive/Spark上执行TPC-DS基准测试 (PARQUET格式)》中,我们详细介绍了具体的操作方法,当时的集群使用的是Hive Metastore,所有操作均可成功执行。当集群启用 Glue Data Catalog 时,在执行add_constraints.sql时会报错:
Optimizing table date_dim (1/24).…
java:Servlet
背景 我们访问浏览器访问一个地址,最终是访问到了这个 java 类,而 java 是运行在 Tomcat 上的,所以 Tomcat 作为一个服务器会把这个访问地址指向这个类中,这个类就是 Servlet,Servlet 就是一个具有一定规范的类&#x…
32. 某周内每件商品每天销售情况
文章目录 题目需求实现一题目来源 题目需求
从订单明细表(order_detail)中查询2021年9月27号-2021年10月3号这一周所有商品每天销售情况。
期望结果如下(截取部分):
sku_id monday tuesday wednesday thursday frid…
hive存储压缩格式对比说明
文本压缩(Text Compression): 压缩算法:Gzip、Snappy、LZO等。特点:压缩率高,但读写性能相对较低。适合非常大的文本文件。适用场景:需要节省存储空间,但同时需要保持数据的可读性。…

大数据学习:Hive常用函数
Hive常用函数
1. Hive的参数传递
1.1 Hive命令行
查看hive命令的参数
[hadoopnode03 ~]$ hive -help语法结构: hive [-hiveconf xy]* [<-i filename>]* [<-f filename>|<-e query-string>][-S] 说明: -i 从文件初始化HQL。-e从命令行执行指定…
Hive生成日期维度表
1、时间维表(完整版)
1)、 建表
-- 时间维表 完整版
create table if not exists dim.dim_date (date_id string comment 日期(yyyymmdd)
,datestr string comment 日期(yyyy-mm-dd)
…
Hive 服务管理脚本
#!/bin/bash
HIVE_HOME/opt/software/hive-3.1.3
HIVE_LOG_HOME/opt/software/hive-3.1.3/logfunction checkLogDir {if [[ ! -e ${HIVE_LOG_HOME} ]]; thenecho "${HIVE_LOG_HOME} 目录不存在,正在创建。"mkdir -p ${HIVE_LOG_HOME}fi
}function checkHi…

Hbase表映射成hive中
Hbase表映射成hive中
一、1.Hive内部表,语句如下 1、hive中建表CREATE TABLE member(m_id string ,address_contry string ,address_province string ,address_city string ,info_age string ,info_birthday string ,info_company string)STORED BY org.apache.had…

大数据平台框架、组件以及处理流程详解
数据产品和数据密不可分作为数据产品经理理解数据从产生、存储到应用的整个流程,以及大数据建设需要采用的技术框架Hadoop是必备的知识清单,以此在搭建数据产品时能够从全局的视角理解从数据到产品化的价值。本篇文章从三个维度:
1.大数据的…
hive lateral view 实践记录(Array和Map数据类型)
目录
一、Array
1.建表并插入数据 2.lateral view explode
二、Map
1、建表并插入数据
2、lateral view explode()
3、查询数据 一、Array
1.建表并插入数据
正确插入数据:
create table tmp.test_lateral_view_movie_230829(movie string,category array&…
chmod: changing permissions of ‘/user/hive/warehouse‘: Permission denied. user=hdfs is not the owner
安装hive后发现无法创建表和写入
在执行Hadoop的创建目录、写数据等情况,可能会出现该异常,而在读文件的时候却不会报错,这主要是由于系统的用户名不同导致的,由于我们进行实际开发的时候都是用Windows操作系统,而编译…
Hive_开窗函数实验注意点
1.数据 numid123356
2.用开窗函数累加第一行至当前行
select sum(id) over(order by id) from num
3.结果
1 3 9 9 14 20
两个9的原因:id为3的有两个,到第一个id为3的时候和第二个id为3的时候都是开窗到第二个id为3的地方。

union union all
相同点:两者作用都是结合两表
区别:union去重,union all不去重
(1)如果需求需要去重,只能选择union
(2)如果需求不需要去重,选择union all
(3)…

Hive的几个重要表
1.metastore数据库的DBS表
包含各表存储信息等 2.metastore数据库的TBLS表
包含各表是否是外部表等 3.metastore数据库的TABLE_PARAMS表
查看numFiles、numRows
(1)如果是刚建表,numFiles、numRows都为0;
(2&…

hive中判断一个表是否存在
1.直接查询,table_name为表名,这个就不多说了,直接上sql
sql:show tables like table_name 2.模糊查询,例如:table_name_,判断hive表中是否存在表明中含有table_name_字段的表
sql:show table…
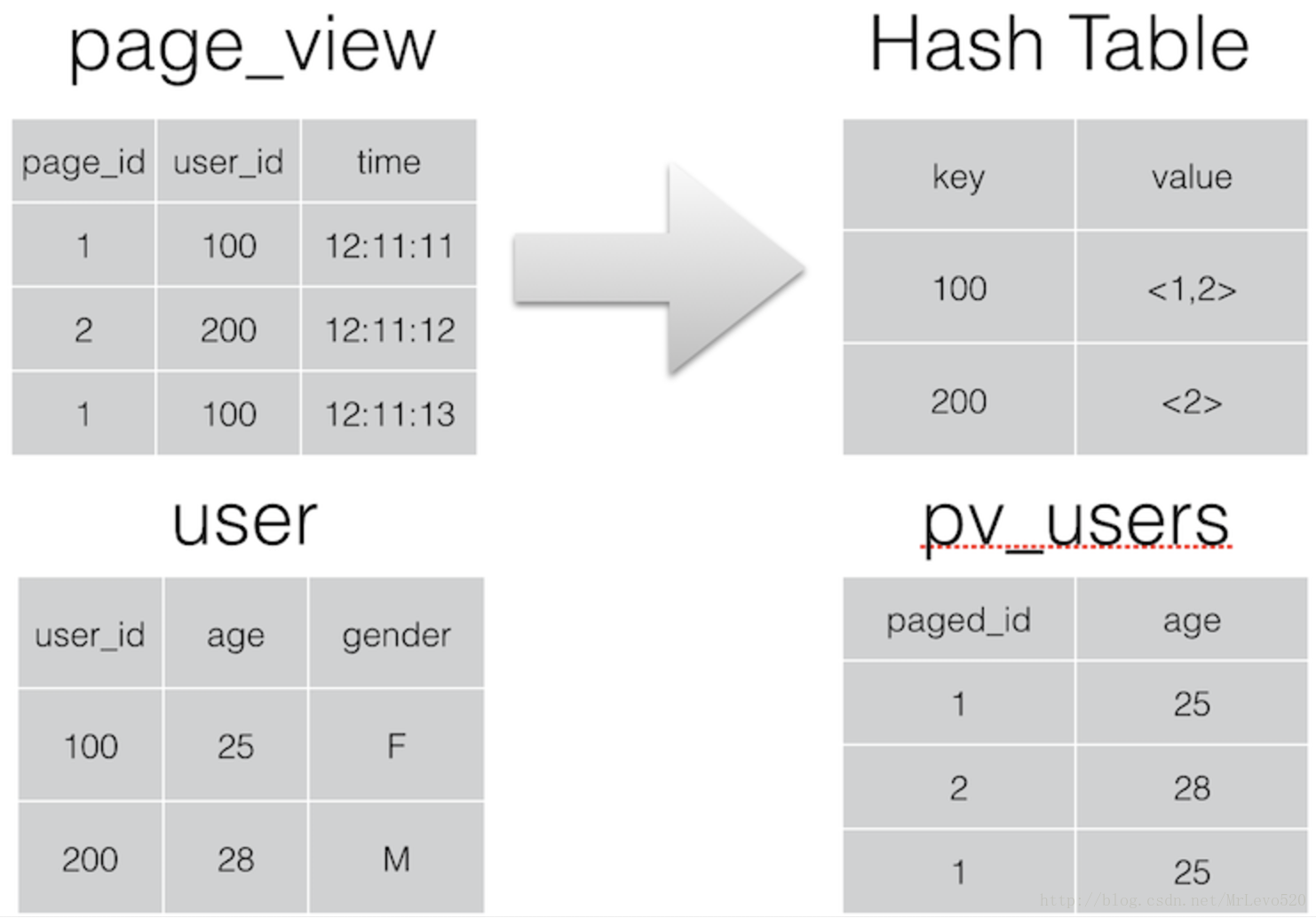
总结:Hive性能优化上的一些总结
Hive性能优化上的一些总结
注意,本文百分之九十来源于此文:Hive性能优化,很感谢作者的细心整理,其中有些部分我做了补充和追加,要是有什么写的不对的地方,请留言赐教,谢谢
前言 今天电话面试突然被涉及到…
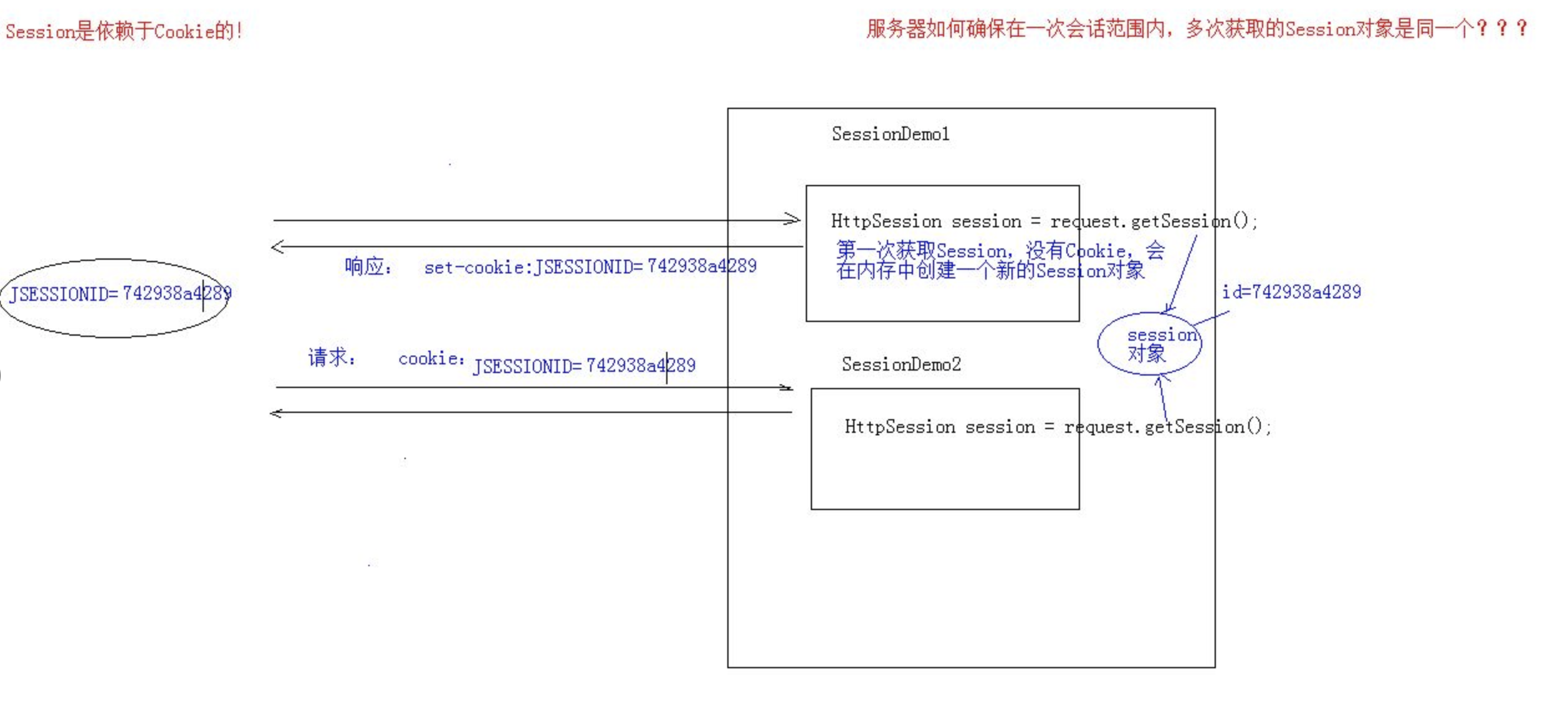
java:操作session
概念
服务器端会话技术,在一次会话的多次请求间共享数据,将数据保存在服务器端的对象中。
一次会话:网页只要不关闭就是一次会话,关闭后会话结束。
示例:会话共享
如下两个Servlet,在浏览器访问 sessio…
笔记:新手的Hive指南
前言 算是对在滴滴实习的这段时间Hive的笔记吧,回学校也有段时间了,应该整理整理了,肯定不会巨细无遗,作为一种学习记录或者入门指南吧 基础
SQL基本语法Python基础语法(HiveStreaming会用到)Java基础语法(写UDF会用到)Hadoop基础…
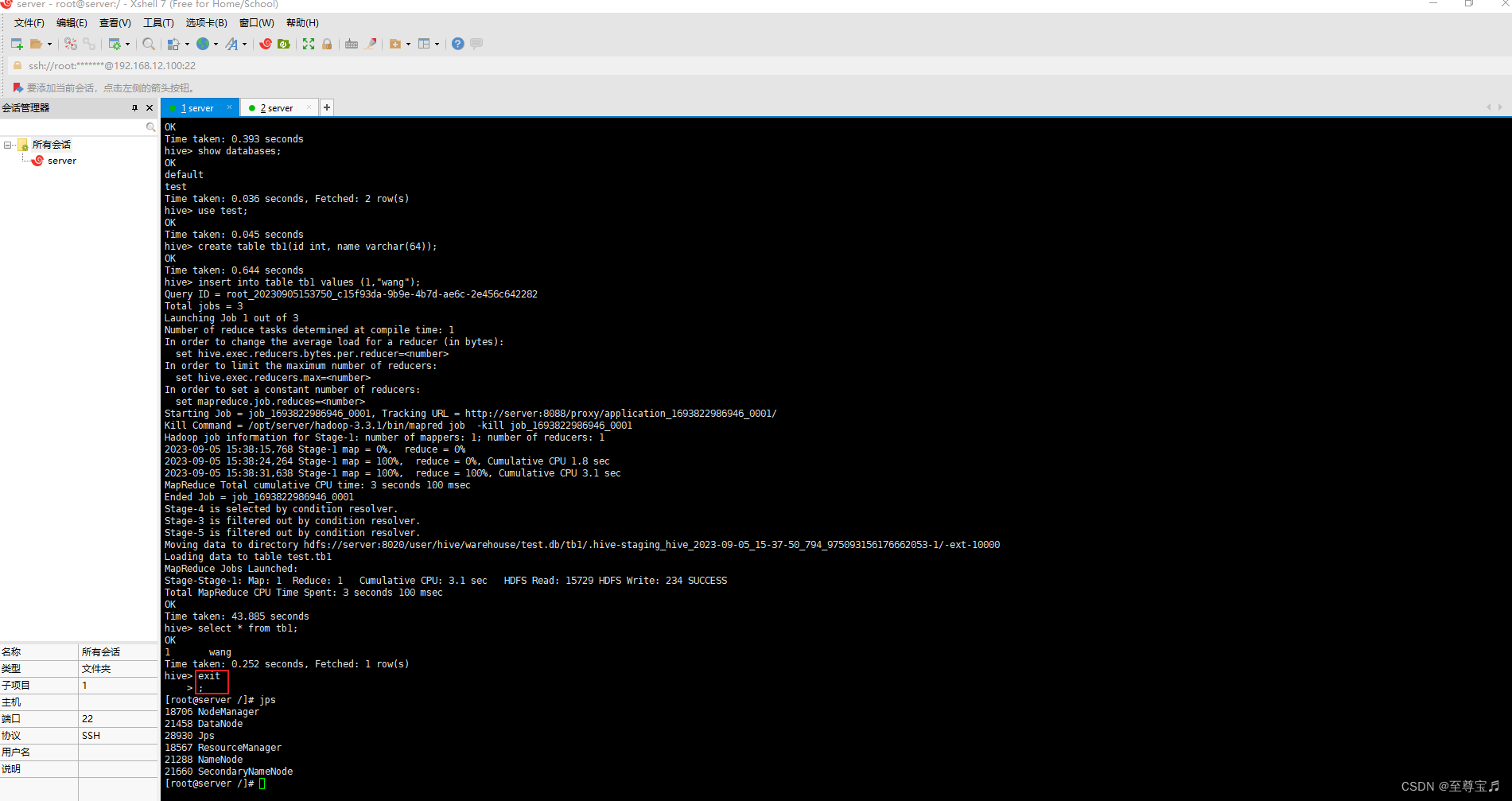
centos7上hive3.1.3安装及配置
1、安装背景;
hive是基于hadoop的数据仓库软件,部署运行在linux系统之上,安装之前必须保证hadoop环境运行正常,hive本身不是分布式软件,它的分布式主要是借助hadoop实现,存储是hdfs,计算是mapr…

一百七十四、Hive——Hive动态分区表加载数据时需不需要指定分区名?
一、目的
在Hive的DWD层和DWS层建立动态分区表后,发现动态插入数据时可以指定分区名,也可以不指定分区名。因此,研究一下它们的区别以及使用场景,从而决定在项目的海豚调度HiveSQL的脚本里需不需要指定动态分区的分区名ÿ…

大数据技术之Hive:先导篇(一)
目录
一、什么是Hive
二、思考如何设计出Hive功能
2.1 提问
2.2 案例分析
2.3 小结
三、掌握Hive的基础架构
3.1 Hive组件 - 元数据存储
3.2 Hive组件 - Driver驱动程序
3.3 Hive组件 - 用户接口 一、什么是Hive 什么是分布式SQL计算 我们知道,在进行数据统…
阿里云大数据实战记录10:Hive 兼容模式的坑
文章目录 1、前言2、什么是 Hive 兼容模式?3、为什么要开启 Hive 模式?4、有什么副作用?5、如何开启 Hive 兼容模式?6、该场景下,能不能不开启 Hive 兼容模式?7、为什么不是DATE_FORMAT(datetime, string)&…

【hive】列转行—collect_set()/collect_list()/concat_ws()函数的使用场景
文章目录 一、collect_set()/collect_list()二、实际运用把同一分组的不同行的数据聚合成一个行用下标可以随机取某一个聚合后的中的值用‘|’分隔开使用collect_set()/collect_list()使得全局有序 一、collect_set()/collect_list()
在 Hive 中想实现按某字段分组,…
前台与后台,为什么要分离?
如果你经历过快速迭代业务,经历过用户量不断上涨,经历过访问并发越来越大,你一定会遇到以下系统问题:
用户访问页面越来越慢系统性能下降,数据库扛不住,连接数经常打满,最终数据库挂掉…
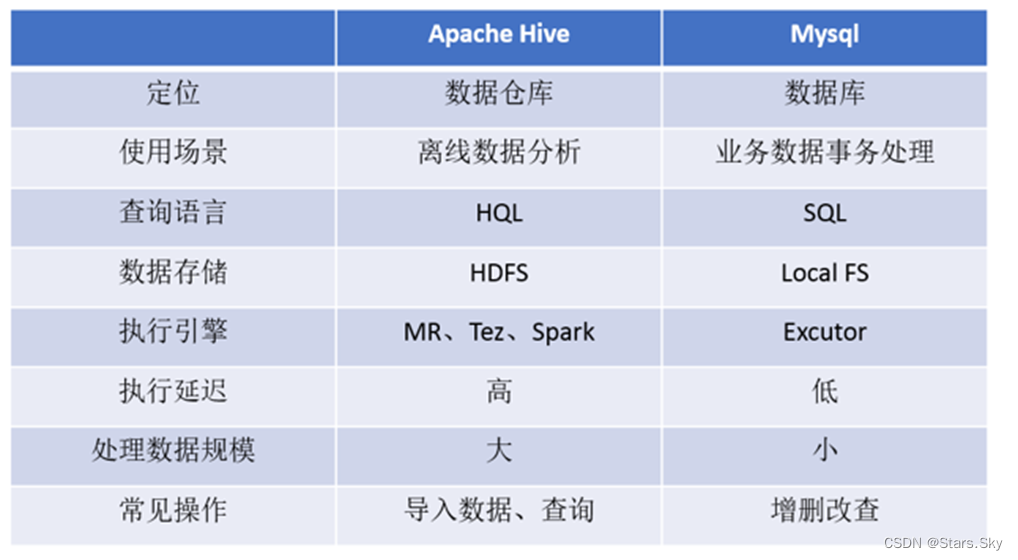
Apache Hive 入门
目录
一、Apache Hive概述
1.1 什么是Hive
1.2 为什么使用 Hive
1.3 Hive 和 Hadoop 关系
二、场景设计:如何模拟实现Hive功能
2.1 如何模拟实现 Apache Hive 的功能
2.2 映射信息记录
2.3 SQL 语法解析、编译
2.4 最终效果
三、Apache Hive 架…
Hive性能调优行之有效的优化方法
您确定您的 Hive 查询正在以最佳状态执行吗?你可能会感到惊讶。 Apache Hive 是当今许多大型企业环境中使用最普遍的查询引擎,但这并不意味着它可以自动优化工作。为了充分利用引擎并实现 Hive 查询优化,调整其性能非常重要。但在深入探讨之前…
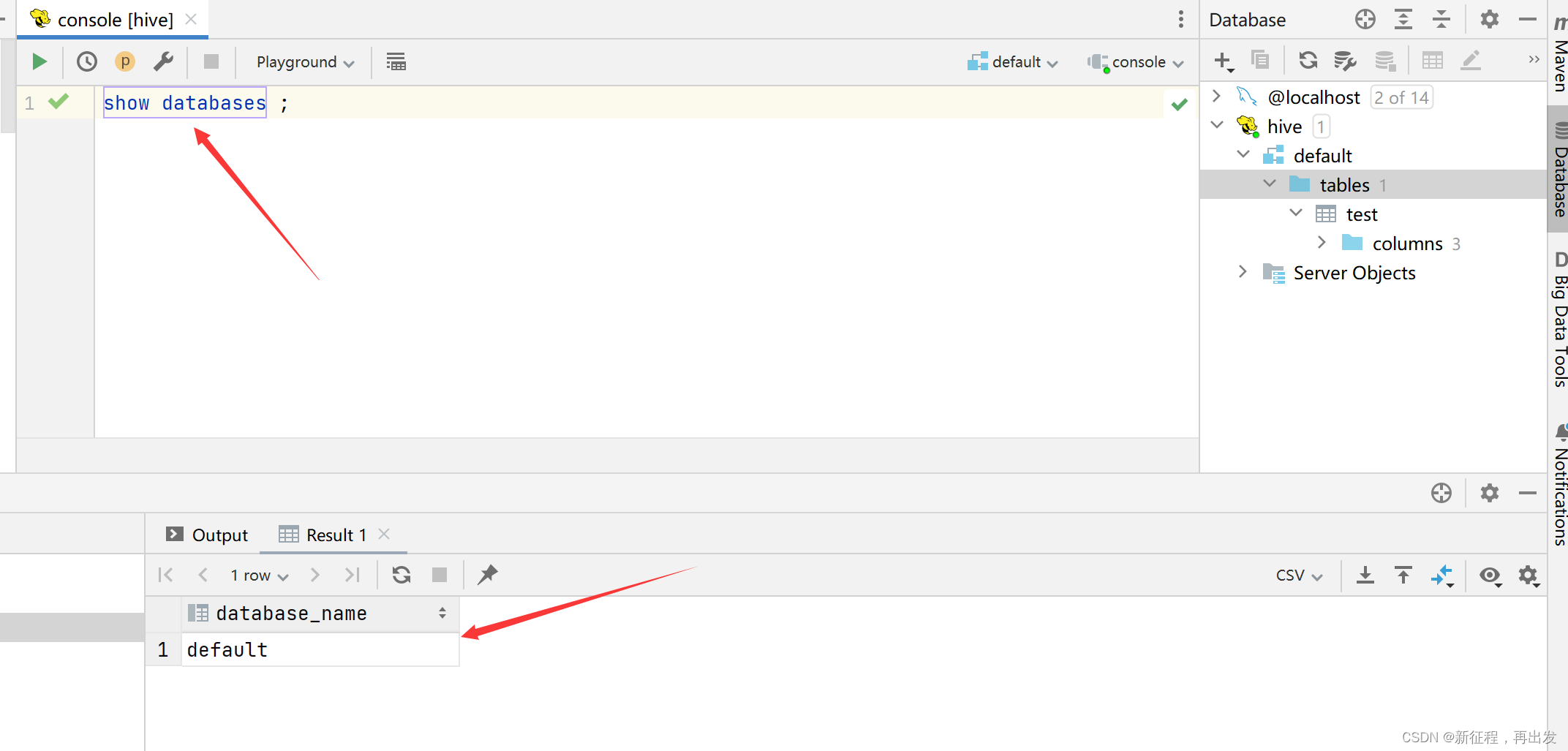
Hive部署,hive客户端
1、Hive部署
Hive是分布式运行的框架还是单机运行的?
Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
1.1、规划
我们知道Hive是单机工具后,就需要准备一台服务…
实验五 熟悉 Hive 的基本操作
实验环境: 1.操作系统:CentOS 7。 2.Hadoop 版本:3.3.0。 3.Hive 版本:3.1.2。 4.JDK 版本:1.8。 实验内容与完成情况:
(1)创建一个内部表 stocks,字段分隔符为英文逗号…
Spark或Hive数仓生命周期管理
在做数仓开发过程中,遇到一个问题就是随着数据量增大,存储空间增加惊人:hdfs的文件要存3份(可以修改副本份数),ods、dwd、dws、ads等各层都需要存储空间,指标计算过程如果内存不够又会缓冲在硬盘…
一百八十七、大数据离线数仓完整流程——步骤六、在ClickHouse的ADS层建表并用Kettle同步Hive中DWS层的结果数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(六)步骤六、在Click…

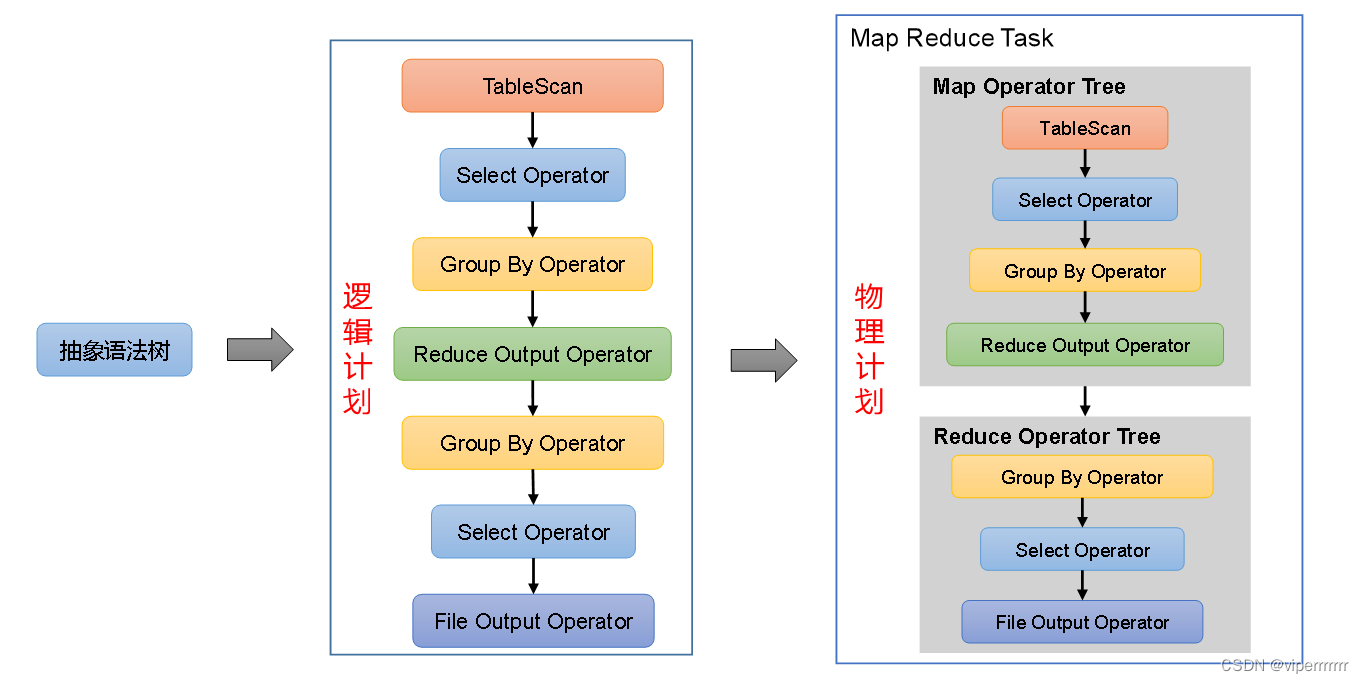
大数据学习(2)Hadoop-分布式资源计算hive(1)
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
Hive+Flume+Kafka章节测试六错题总结
题目2:
EXTERNAL关键字的作用?[多选]
A、EXTERNAL关键字可以让用户创建一个外部表 B、创建外部表时,可以不加EXTERNAL关键字 C、通过EXTERNAL创建的外部表只删除元数据,不删除数据 D、不加EXTERNAL的时候,默认创建内…
hadoop -hive 安装
1.下载hive
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz2.解压/usr/app 目录
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /usr/app3.设置软连接
ln -s /usr/app/apache-hive-3.1.3-bin /usr/app/hive4.修改/usr/app/hive/conf/hive-env.…
大数据学习(4)-hive表操作
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
hive抽取mysql里的表,如果mysql表没有时间字段如何做增量抽取数据
如果MySQL表中没有时间字段,你可以通过其他方式实现增量抽取数据,以下是一些常见的方式:
使用自增主键:如果MySQL表中有自增主键,你可以记录上一次抽取数据时最大的主键值(即上一次抽取数据的结束位置&…
免密码方式获取Hive元数据
前言
开发中可能用到hive的元数据信息 ,如获取hive表列表、hive表字段、hive表数据量大小、hive表文件大小等信息,要想获取hive元数据信息即需要hive元数据库的账号及密码,此次提供的是一种不需要hive元数据库密码及可获取元数据信息的方式&…
数据采集平台项目(四)
1. DataX中null值的输出
mysql经过dataX的传输后,默认会将null转换为空字符串"",而hive中默认的null值存储格式为\N.
解决方案:
修改datax底层源码修改hive默认null值为空字符串
2. Hive的安装
解压安装,修改文件名…

45.复购率问题求解
思路分析: (1)近xx天,最大日期肯定就是最新的一天,故先用max(order_date) over() today计算当天日期 (2)过滤出最近90天的订单并且按照user_id,product_id分组求购买次数; ÿ…
spark集成hive
集群使用ambarihdp方式进行部署,集群的相关版本号如下所示:
ambari版本
Version 2.7.4.0
HDP版本
HDP-3.1.4.0
hive版本
3.1.0
spark版本
2.3.0
集群前提条件:
1.Hdp、Spark、Hive都已部署好
2.Hive数据层建好,在Hdfs生成相应各层目录,后面配…
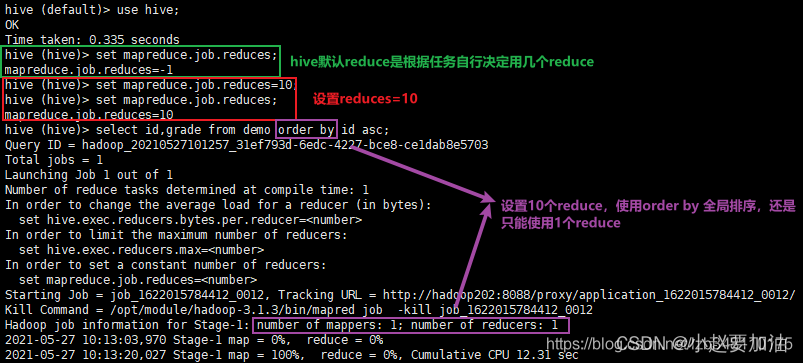
【hive】order by、sort by、distribute by、cluster by的区别
Order By(全局排序)
Order By 用于结果集的排序。也可以称之为全局排序。对于 MR 任务来说,如果我们使用了 Order By 排序,意味着MR 任务只会有一个 Reducer 参与排序。,
在 Hive 中执行脚本时,我们可以通…
大数据技术之Hive SQL题库-高级
第1题 同时在线人数问题1.1 题目需求现有各直播间的用户访问记录表(live_events)如下,表中每行数据表达的信息为,一个用户何时进入了一个直播间,又在何时离开了该直播间。user_id(用户id)live_id(直播间id)in_datetime…
Wallpaper:基于Typecho的壁纸头像站主题
简介:
该主题是本人的一个头像壁纸站点的主题,这个站最初是女朋友要让和她用情侣头像和壁纸,跑到网上转了一圈都没找到一个专门的情侣头像壁纸站,只在知乎某个答案下找到一些情侣头像,而情侣壁纸就更难找了࿰…
在CentOS 7 中安装Hive-1.2.2
安装Hive的过程1. 准备安装文件hive-1.2.22.解压缩Hive安装文件3.配置环境变量4.修改Hive配置文件5.添加MySQL连接的jar资源包6.启动hive1. 准备安装文件hive-1.2.2
注意:安装Hive之前,需要在CentOS 7中先安装MySQL!! 在Windows中…
Hive SQL练习题
1、查询至少连续三天下单的用户
1.1、表结构 create table order_info(order_id string COMMENT 订单id,user_id string COMMENT 用户id,create_date string COMMENT 下单日期,total_amount decimal(16, 2) COMMENT
Hive 建表语句解析
前言
在上篇文章《Hive 浅谈DDL语法》中我留了一个小尾巴,今天来还债了,为大家详细介绍一下Hive的建表语句。
建表语句解析
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)</…
Hive msck 描述
MSCK SQL 语法如下:
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];1. 背景
先创建3个分区,把分区文件删除。这时 metastore 有这个3个分区,文件上不存在。再在文件系统上创建其他两个分区,这两个分区在 metastor…
Hive on Spark调优(大数据技术2)
第2章 Yarn配置
2.1 Yarn配置说明
需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下。
(1)yarn.nodemanager.resource.memory-mb
该参数的含义是,一个NodeManager节点分配给Container使用的内存。该参数的配置&am…
数据治理实践-全面总结:小文件治理
01 背景
小文件是如何产生的: 日常任务及动态分区插入数据(使用的Spark2 MapReduce引擎),产生大量的小文件,从而导致Map数量剧增; Reduce数量越多,小文件也越多(Reduce的个数和输出文件是对应…
一百一十三、DBeaver——从hive同步数据到clickhouse
目标:把hive的DM层结果数据导出到clickhouse数据库,试了kettle、sqoop等多种方法都报错,尤其是kettle,搞了大半天发现还是不行。结果目前就只能用DBeaver同步数据。
准备工作:hive和clickhouse中都建好表
第一步&…
让分区表和数据产生关联的三种方式
如果是自己创建目录,不以正常方式加载数据,则分区表和数据不关联
[atguiguHadoop102 data]$ hadoop fs -mkdir /user/hive/warehouse/dept_par/day2020-10-29
让分区表和数据产生关联的三种方式 :
(1)方式一&#x…
seatunnel 2.3.1全流程部署使用
Seatunnel 2.3.1 部署使用 1 部署1.1 下载解压1.2 下载对应的connector1.3 安装seatunnel⭐1.4 补充一些jar包 2 测试样例2.1 官方demo fake to console2.2 mysql to console2.3 hive to console2.4 mysql to hive 3 欢迎讨论 1 部署
1.1 下载解压
https://dlcdn.apache.org/…
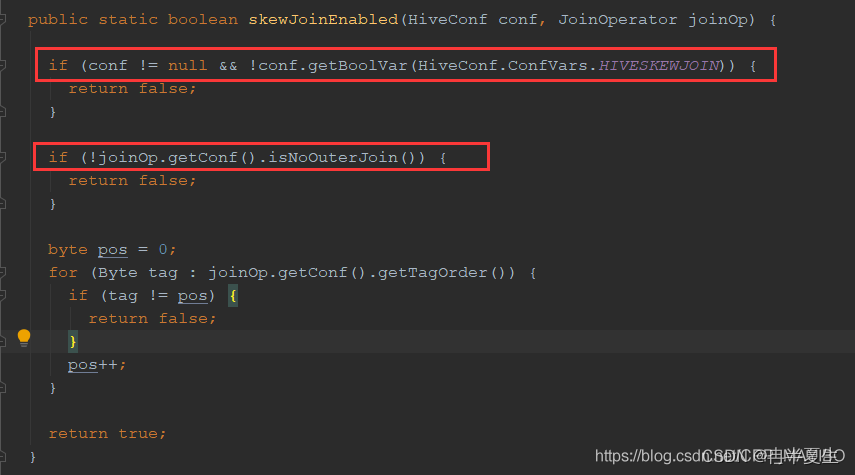
Hive用户中文使用手册系列(三)
JDBC
HiveServer2 有一个 JDBC 驱动程序。它支持对 HiveServer2 的嵌入式和 remote 访问。 Remote HiveServer2 模式建议用于 production 使用,因为它更安全,不需要为用户授予直接 HDFS/metastore 访问权限。
连接 URL
连接 URL 格式
HiveServer2 UR…
Filter与Listener(过滤器与监听器)
1.Filter
1.过滤器概述
过滤器——Filter,它是JavaWeb三大组件之一。另外两个是Servlet和Listener
它可以对web应用中的所有资源进行拦截,并且在拦截之后进行一些特殊的操作
在程序中访问服务器资源时,当一个请求到来,服务器首…
大数据学习(16)-mapreduce详解
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…

hive窗口函数记录
记录工作中和学习中的窗口函数,方便以后使用,本记持续更新和完善,版本:231019 文章目录 1.什么是窗口函数2.窗口函数的表达式3.窗口函数的类型1) 排名函数2) 聚合函数3) 跨行取值函数 4.[frame…
hive 问题解决 Class path contains multiple SLF4J bindings
hive输入命令时出现日志冲突提示(问题不复杂,是个warn,强迫症解决,做项目经常遇到,项目里是处理maven。这里处理方法思路类似。)
问题: SLF4J: Class path contains multiple SLF4J bindings. …

Flink Hive Catalog操作案例
在此对Flink读写Hive表操作进行逐步记录,需要指出的是,其中操作Hive分区表和非分区表的DDL有所不同,以下分别记录。
基础环境
Hive-3.1.3 Flink-1.17.1
基本操作与准备
1、上传依赖jar包到flink/lib目录下
cp flink-sql-connector-hive-…
leecode 数据库:1158. 市场分析 I
数据导入:
SQL Schema: Create table If Not Exists Users (user_id int, join_date date, favorite_brand varchar(10));
Create table If Not Exists Orders (order_id int, order_date date, item_id int, buyer_id int, seller_id int);
Create tab…
hiveserver2经常挂断的原因
hiveserver2经常挂断的原因
HiveServer2 经常挂断可能有多种原因,以下是一些可能导致挂断的常见原因:
资源不足:HiveServer2 需要足够的内存和 CPU 资源来处理查询请求。如果资源不足,可能会导致 HiveServer2 挂断。请确保在配置…
【Hive-Partition】Hive添加分区及修改分区location
【Hive-Partition】Hive添加分区及修改分区location 1)整表修复数据2)单独分区修复 当我们在 Hive 中创建外表时,需要映射 HDFS 路径,数据落入到 HDFS 上时,我们在 Hive 中查询时会发现 HDFS中有数据,Hive …

【hadoop——Hive的安装和配置】保姆式教学
目录 一.Hive的安装和配置
1.Hive并不是hadoop自带的组件,因此我们需要去下载hive,此次课我们使用hive 1.2.1版本,下载地址为:
2.下载完成之后,安装包默认保存在下载文件夹中,解压安装包apache-hive-1.2.…
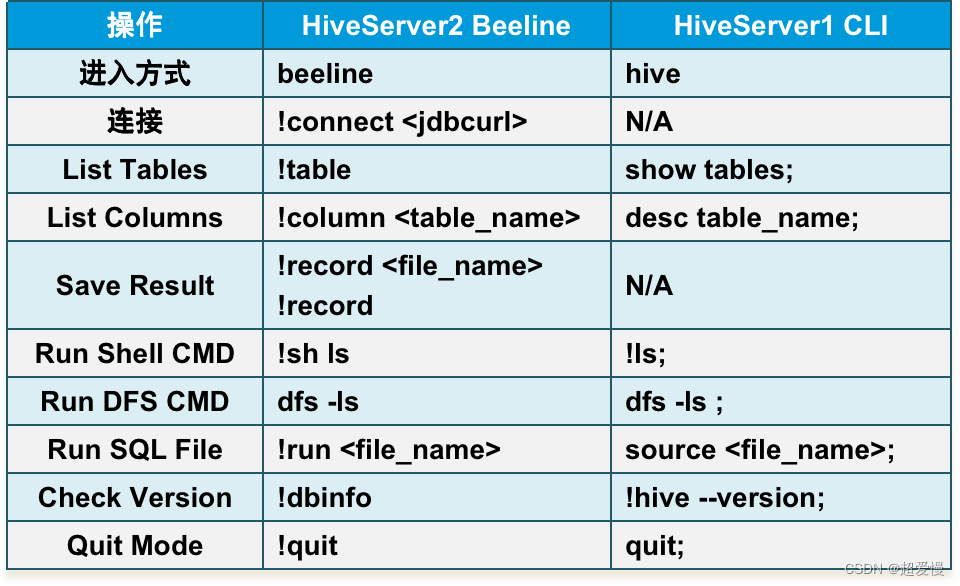
Hadoop + HBase + Hive 完全分布式部署笔记
完全分布式Hadoop HBase Hive 部署过程的的一些问题。
NameNode: 192.168.229.132
DataNode: 192.168.229.133/192.168.229.134 --------------------------------------------------------------------------------
配置 Hadoop
无密码SSH
首先是NameNode需要通过ssh来…
![[WSL] 安装hive3.1.2成功后, 使用datagrip连接失败](https://img-blog.csdnimg.cn/788a9c85126f468ca5a3b5eb7142b0a9.png)
[WSL] 安装hive3.1.2成功后, 使用datagrip连接失败
org.apache.hadoop.ipc.RemoteException:User: xxx is not allowed to impersonate anonymous
下载driver-hive-jdbc-3.1.2-standalone
解决
修改hadoop 配置文件 etc/hadoop/core-site.xml,加入如下配置项
<property><name>hadoop.proxyuser.你的用户名.hosts…
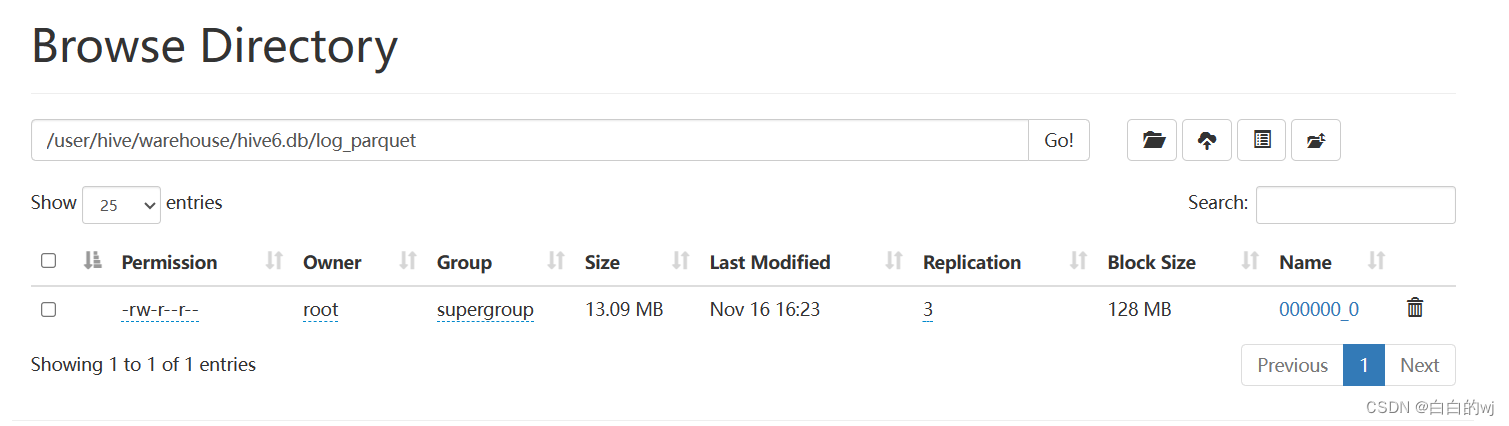
2023.11.17 -hivesql调优,数据压缩,数据存储
目录 1.hive命令和参数配置
2.hive数据压缩
3.hive数据存储
0.原文件大小 18.1MB
1.textfile行存储格式, 压缩后size:18MB
2.行存储格式:squencefile ,压缩后大小8.89MB
3. 列存储格式 orc - ZILIB ,压缩后大小2.78MB 4.列存储格式 orc-snappy ,压缩后大小3.75MB
5…
大数据之Hive:regexp_extract函数案例
目录 一、正则的通配符简介1、正则表达式的符号及意义2、各种操作符的运算优先级: 二、案例数据要求分析实现 一、正则的通配符简介
1、正则表达式的符号及意义
符号含义实列/做为转意,即通常在"/"后面的字符不按原来意义解释如" * “匹…

【hive-解决】HiveAccessControlException Permission denied: CREATEFUNCTION
文章目录 一.任务描述二. 解决 一.任务描述 Error while compiling statement: FAILED: HiveAccessControlException Permission denied: Principal [nameroot, typeUSER] does not have following privileges for operation CREATEFUNCTION [ADMIN PRIVILEGE on INPUT, ADMIN…
2023.11.18 - hadoop之zookeeper分布式协调服务
1.zookeeper简介
ZooKeeper概念: Zookeeper是一个分布式协调服务的开源框架。本质上是一个分布式的小文件存储系统 ZooKeeper作用: 主要用来解决分布式集群中应用系统的一致性问题。 ZooKeeper结构: 采用树形层次结构,没有目录与文件之分,ZooKeeper树中的每个节点被…
关于黑马hive课程案例FineBI中文乱码的解决
文章目录 问题描述情况一的解决情况二的解决 ETL数据清洗知识社交案例参考代码结果展示 问题描述
情况1:FineBI导入表名中文乱码,字段内容正常情况2:FineBI导入表字段中文乱码,表名内容正常
情况一的解决
使用navcat等工具连接…

hive sql 取当周周一 str_to_date(DATE_FORMAT(biz_date, ‘%Y%v‘), ‘%Y%v‘)
select str_to_date(DATE_FORMAT(biz_date, %Y%v), %Y%v)方法拆解
select DATE_FORMAT(now(), %Y%v), str_to_date(202346, %Y%v)
educoder中Hive -- 索引和动态分区调整
第1关:Hive -- 索引 ---创建mydb数据库
create database if not exists mydb;
---使用mydb数据库
use mydb;
---------- Begin ----------
---创建staff表
create table staff(
id int,
name string,
sex string)
row format delimited fields terminated by ,
stored…
HIVE SQL 判断空值函数
目录 nvl()coalesce() nvl()
select nvl(null,2);输出:2
select nvl(,2);输出:‘’
coalesce()
select coalesce(null,2);输出:2
select coalesce(,2);输出:‘’
select coalesce(null,null,2);输出:2
*coalesc…

Hive内置表生成函数
Hive内置UDTF 1、UDF、UDAF、UDTF简介2、Hive内置UDTF 1、UDF、UDAF、UDTF简介 在Hive中,所有的运算符和用户定义函数,包括用户定义的和内置的,统称为UDF(User-Defined Functions)。如下图所示: UDF官方文档…
大数据学习(25)-hive核心总结
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…
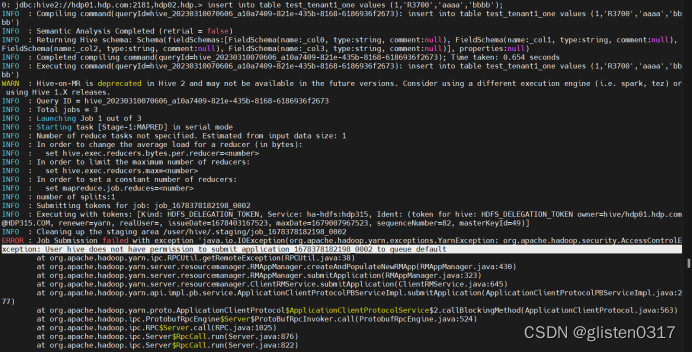
Hadoop学习笔记(HDP)-Part.15 安装HIVE
目录 Part.01 关于HDP Part.02 核心组件原理 Part.03 资源规划 Part.04 基础环境配置 Part.05 Yum源配置 Part.06 安装OracleJDK Part.07 安装MySQL Part.08 部署Ambari集群 Part.09 安装OpenLDAP Part.10 创建集群 Part.11 安装Kerberos Part.12 安装HDFS Part.13 安装Ranger …

记一次CDH集群迁移产生的问题——HIVE
背景
生产环境CDH集群迁移到新的环境,迁移之后使用Hive Client方执行任务一直失败。
问题1:metadata.SessionHiveMetaStoreClient
产生报错:
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.Ru…

hive 命令行中使用 replace 和nvl2 函数报错
1.有时候在命令行的情况下使用 replace 函数时会报错
这个时候可以使用 translate 代替 2.有时候使用 nvl2() 函数的时候会报错 这个时候可以用 case when 来代替
每日HiveSQL_统计即时订单_13
1.订单配送中,如果期望配送日期和下单日期相同,称为即时订单,如果期望配送日期和下单日期不同,称为计划订单。请从配送信息表(delivery_info)中求出每个用户的首单(用户的第一个订单)…
【Hive】启动beeline连接hive报错解决
1、解决报错2、在datagrip上连接hive 1、解决报错
刚开始一直报错:启动不起来 hive-site.xml需要配置hiveserver2相关的
在hive-site.xml文件中添加如下配置信息
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bin…
HIVE学习(hive基础)
HIVE基础介绍 一、HIVE简介二、hive的数据类型1、基本数据类型2、复合数据类型 三、HIVE的DDL操作四、创建一个表1. 建表语句 五、修改表结构1.修改表名2. 列修改或增加3. 修改分区 五、常见函数六、一对一关联left join左关联right join 右关联内连接全连接查询只有A表的数据 …
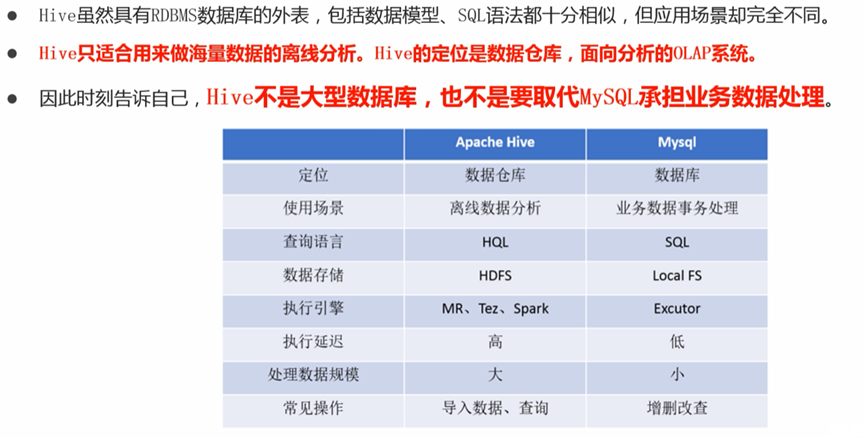
【Hive】——概述
1 什么是Hive 2 Hive 优点 3 Hive和Hadoop 的关系 4 映射信息记录 5 SQL语法解析、编译 Hive能将一个文件映射成为一张表,文件和表之间的关系称为映射 Hive的功能职责是将SQL语法解析编译成为MapReduce
6 Hive 架构
6.1 分析 6.2 架构图 6.3 用户接口 6.4 元数据存…
ambari hive on Tez引擎一直卡住
hive on tez使用./bin/hive启动后一直卡住,无法进入命令行 使用TEZ作为Hive默认执行引擎时,需要在调用Hive CLI的时候启动YARN应用,预分配资源,这需要花一些时间,而使用MapReduce作为执行引擎时是在执行语句的时候才会…
什么是sql的谓词下推
SQL的谓词下推(Predicate Pushdown)是一种数据库查询优化技术,它将查询中的过滤条件(谓词)尽可能地“下推”到查询计划中更早的阶段执行。这意味着,系统尝试在处理和转换数据之前先应用这些过滤条件&#x…
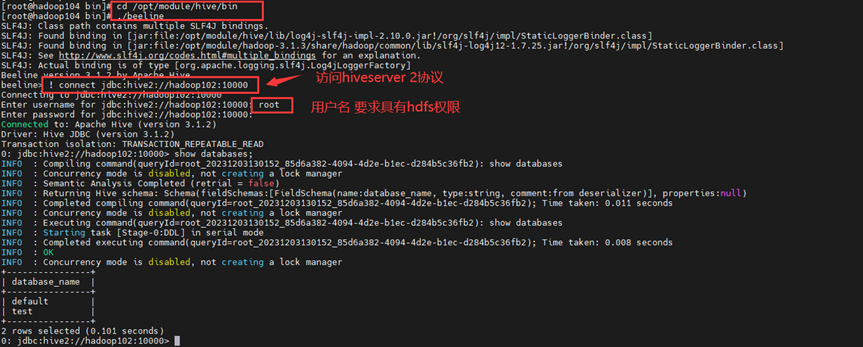
【Hive】——CLI客户端(bin/beeline,bin/hive)
1 HiveServer、HiveServer2 2 bin/hive 、bin/beeline 区别 3 bin/hive 客户端 hive-site.xml 配置远程 MateStore 地址
XML
<?xml version"1.0" encoding"UTF-8" standalone"no"?>
<?xml-stylesheet type"text/xsl" hre…
spark的宽依赖,窄依赖
在 Apache Spark 中,依赖关系是指 RDD(弹性分布式数据集)之间的关系。依赖关系的类型对于理解 Spark 的任务调度、分区和故障恢复等方面至关重要。Spark 中主要有两种类型的依赖关系:窄依赖(Narrow Dependency…


hive常用SQL函数及案例
1 函数简介
Hive会将常用的逻辑封装成函数给用户进行使用,类似于Java中的函数。 好处:避免用户反复写逻辑,可以直接拿来使用。 重点:用户需要知道函数叫什么,能做什么。 Hive提供了大量的内置函数,按照其特…


【Hive】——DML
1 Load(加载数据)
1.1 概述 1.2 语法
LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1val1, partcol2val2 ...)]LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol…

处理SERVLET中的错误和异常
处理SERVLET中的错误和异常
应用服务器服务客户机请求时可能会遇到一些问题,如找不到所请求的资源或运行中的servlet引发异常。例如,在线购物门户中如果用户选择了当前缺货的物品要放入购物车中,就会出现问题, 这种情况下,浏览器窗口中将显示错误消息。您可以在servlet中…
Bug2- Hive元数据启动报错:主机被阻止因连接错误次数过多
错误代码:
在启动Hive元数据时,遇到了以下错误信息:
Caused by: java.sql.SQLException: null, message from server: "Host 192.168.252.101 is blocked because of many connection errors, unblock with mysqladmin flush-hosts&qu…

Hive参数操作和运行方式
Hive参数操作和运行方式
1、Hive参数操作
1、hive参数介绍
hive当中的参数、变量都是以命名空间开头的,详情如下表所示:
命名空间读写权限含义hiveconf可读写hive-site.xml当中的各配置变量例:hive --hiveconf hive.cli.print.headert…

SERVLET间通信
在Web应用程序中,应用程序的servlet等各种组件之间可能需要通信以便处理客户机请求。例如,假设Web应用程序中有一个servlet显示组织的版权信息。您可以使用各种servelt通信技术将此servlet的内容纳入到需要显示版权信息的所有其他应用程序servlet中。同样,如果处理请求时发生…

Hive的小文件问题
目录 一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量 3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…
2024.2.10 HCIA - Big Data笔记
1. 大数据发展趋势与鲲鹏大数据大数据时代大数据的应用领域企业所面临的挑战和机遇华为鲲鹏解决方案2. HDFS分布式文件系统和ZooKeeperHDFS分布式文件系统HDFS概述HDFS相关概念HDFS体系架构HDFS关键特性HDFS数据读写流程ZooKeeper分布式协调服务ZooKeeper概述ZooKeeper体系结构…
(12)Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,count distinct使得map端无法预聚合,容易引发reduce端长尾,以下是count distinct去重调优的几种方式。
解决方案一:group by 替代
原sql 如下:
#7日、14日的app点击的…
[Hive] lateral view explode
当在Hive中使用 LATERAL VIEW EXPLODE 时,
它用于将一个复杂类型(如数组或Map)的列展开成多行数据,
并将这些展开后的数据与其他列进行关联。 下面是一个简单的例子来解释 LATERAL VIEW EXPLODE 的用法:
假设有一个…
Spring Security—Spring MVC 整合
目录
一、EnableWebMvcSecurity
二、MvcRequestMatcher
三、AuthenticationPrincipal
四、异步 Spring MVC 整合
五、Spring MVC 和 CSRF 整合
1、自动包含 Token
2、解析 CsrfToken Spring Security提供了一些与Spring MVC的可选整合。本节将进一步详细介绍这种整合。 …

大数据毕业设计选题推荐-系统运行情况监控系统-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
大数据开发之Hive案例篇8-解析XML
文章目录 一. 问题描述二. 解决方案2.1 官方文档2.2 XML格式不规范 一. 问题描述
今天接到一个新需求,hive表里面有个字段存储的是XML类型数据
数据格式:
<a><b>bb</b><c>cc</c>
</a>二. 解决方案
2.1 官方文档
遇到不懂的…

docker快速部署hue+hue集成hive
首先需要安装hive,hive的安装在HIVE的安装与配置_EEEurekaaa!的博客-CSDN博客
安装完成之后,使用脚本命令启动hdfs和hive的相关服务。
一、安装docker
# 安装yum-config-manager配置工具
$ yum -y install yum-utils
# 设置yum源
$ yum-co…
Hive on Spark环境搭建
Hive 引擎简介
Hive 引擎包括:默认 MR、tez、spark
最底层的引擎就是MR (Mapreduce)无需配置,Hive运行自带
Hive on Spark:Hive 既作为存储元数据又负责 SQL 的解析优化,语法是 HQL 语法,执行…

Spark SQL精华 及与Hive的集成
文章目录一.SQL on Hadoop二.Spark SQL1.Spark SQL前身2.Spark SQL架构3.Spark SQL运行原理三.Spark SQL API1.Dataset (Spark 1.6)2.DataFrame (Spark 1.4)四.Spark SQL支持的外部数据源1.Parquet文件:是一种流行的列…

ubuntu 18.04安装mysql5.7
环境 ubuntu 18.04 64位 hadoop 3.2.1 安装前准备 1.首先看一下系统中是否存在mysql相关的安装包,命令如下
rpm -qa|grep mysql2.如果存在mysql相关的安装包使用以下命令删除。
sudo rpm -e --nodeps mysql-libs-xxxxxx 安装mysql 1.输入如下命令,更新…
Hive优化笔记(1 - 非数据倾斜)
目录
列裁剪和分区裁剪
谓词下推
本地模式(local mode)
并行执行
严格模式
Map端聚合
调整mapper数
调整reducer数
小文件合并优化
设置jvm重用
引擎选择
输出结果压缩 最重要的:查看SQL的执行计划,优化业务逻辑 exp…
【Spark SQL】3、大数据数据仓库Hive的学习
大数据数据仓库Hive
产生背景
MapReduce编程的不变性HDFS上的文件缺失schema
用于处理海量结构化的日志数据统计问题
构建在Hadoop之上的数据仓库
Hive定义了一种类SQL查询语言:HQL(类似SQL但不完全相同)
通常用于进行离线数据处理
支持多种不同的压缩格式(GZIP、LZO、S…

Hive 自定义函数 - Java和Python的详细实现
一 写在前面
1 Hive的自定义函数(User-Defined Functions)分三类:
UDF:one to one,进一出一,row mapping。是row级别操作,类似upper、substr等UDAF:many to one,进多出…
Hive表操作及管理
转载请注明出处:http://blog.csdn.net/u012842205/article/details/72765667Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。…
5.Hive参数配置与函数、运算符使用
1.Hive客户端与属性配置
1.1 CLIs and Commands
1.1.1 Hive CLI
$HIVE_HOME/bin/hive是第一个shell Util,其主要功能有两个 1.交互式或批处理模式运行Hive查询 2.hive相关服务的启动 可以运行“hive -H”或者“hive --help”来查看命令行选项
-e <quoted-que…
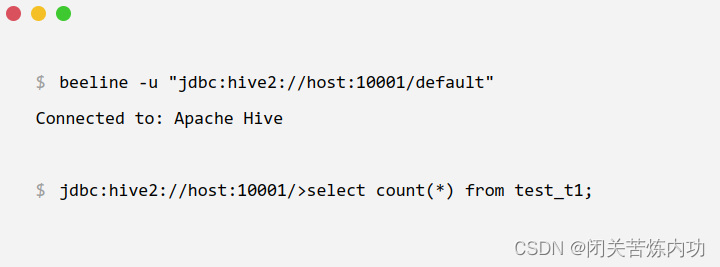
Hive 之 beeline 客户端连接
beeline 客户端连接 Hive beeline -u jdbc:hive2://hadoop10:10000 -n hive 我们下期见,拜拜!
4.HiveSQL 数据操作、查询语言(DML、DQL)
1.Hive SQL-DML-Load加载数据
功能 Load,加载是指将我呢见移动到与Hive表对应的位置,移动时是纯复制、移动操作
语法规则
LOAD DATA [LOCAL] INPATH filepath [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1val1, partcol2val2 ...)]LOAD DA…
Hive获取连续时间用 posexplode
获取连续的日期
假如我们需要获取2020-07-15至2020-07-21间所有的日期,可以像这样写
SELECTpos,date_add( start_date, pos ) dd
FROM( SELECT 2020-07-15 AS start_date, 2020-07-21 AS end_date ) temp lateral VIEW posexplode ( split ( space( datediff( end_date, sta…
HIVE 复制行n次直到某一列等于200
例如需要复制tmp_1表n次,每复制一次,gday1,直到gday200,
借助 lateral view posexplode,首先用space复制多个空格字符串,复制次数200-gday
然后split将字符串分割成数组,此时该数组大小为200-gday
然后l…

常用的hive sql
细节:sql 中有涉及到正则匹配函数的,要注意转义符号 因为在不同语言下正则匹配规则是否需要加转义符号是不同的,举例,regexp_replace 函数,在hive sql的正则匹配规则的 \d 需要前面给它加上转义符号\,而在j…
Hive hql 经典5道面试题
最近在深入了解Hive,尚硅谷的这5道题很经典,有引导意义,分步解题也很有用,故记录之,方便回看 1.连续问题
如下数据为蚂蚁森林中用户领取的减少碳排放量 找出连续 3 天及以上减少碳排放量在 100 以上的用户 id dt lowc…
Hive:查询、排序、索引、存储格式、函数、调优
目录
1、查询
1.1、基本查询(select from)
Hive避免进行MapReduce的情况
1.2、where语句
like和rlike
1.3、分组
1.4、join语句
join优化
map端join优化
2、排序
2.1、order/soted by
2.2、含有sort by 的 ditribute by
2.3、cluster by
2.4、抽样(分桶)查询
2.…

sparkSQL-基础编程(巩固篇)
基本创建
DSL语法
SQL语法 基本创建 Session对象创建 //提供Session对象val session SparkSession.builder() //构建器.appName("sparkSQL") //序名称程.master("local[*]") //执行方式:本地.enableHiveSupport() //支持hive相关操作.getO…
02.用户信息UserDetails相关入门
1. 前言
前一篇介绍了 Spring Security 入门的基础准备。从这篇开始我们来一步步窥探它是如何工作的。我们又该如何驾驭它。本篇将通过 Spring Boot 2.x 来讲解 Spring Security 中的用户主体UserDetails。以及从中找点乐子。
2. Spring Boot 集成 Spring Security
这个简直…
基于MapReduce的Hive数据倾斜场景以及调优方案
文章目录 1 Hive数据倾斜的现象1.1 Hive数据倾斜的场景1.2 解决数据倾斜问题的优化思路 2 解决Hive数据倾斜问题的方法2.1 开启负载均衡2.2 引入随机性2.3 使用MapJoin或Broadcast Join2.4 调整数据存储格式2.5 分桶表、分区表2.6 使用抽样数据进行优化2.7 过滤倾斜join单独进行…
(十七)大数据实战——Hive的hiveserver2服务安装部署
前言
HiveServer2 是 Apache Hive 的一个服务器端组件,用于支持客户端与 Hive 进行交互和执行查询。HiveServer2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能。HiveServer2 允许多个客户端同时连接并与 Hive 交互。这些客户端可以通…

Hive:命令行界面、数据类型、DDL数据定义(数据库及表操作/分区分桶)、DML数据操作(数据导入导出)
目录
1、Hive命令行界面
1.1、选项列表
1.2、变量和属性
1.2.1、Hive中变量和属性命名空间
1.2.2、用户自定义变量
1.2.3、.hiverc文件
1.3、一次使用的命令
1.4、从文件中执行Hive查询
1.5、操作命令历史
1.6、Hive内部可直接使用dfs命令
2、数据类型和文件格式
2…
Hive:基于MySQL的Hive安装搭建、Hive JDBC访问(hiverserver2和beeline)
目录
1、基于MySQL的Hive安装搭建
1.1、Hive安装
1.2、MySql安装
1.2.1、在线模式
1.2.2、离线安装Mysql
1.3、Hive设置使用MySQL
2、Hive JDBC访问
2.1、hiverserver2
2.2、beeline
2.3、配置 1、基于MySQL的Hive安装搭建 1.1、Hive安装
Hive的安装比较简单&#x…
你知道数据发散和数据倾斜么?
该问题已同步到小程序:全栈面试题
问题
在数据开发日常工作当中,数据发散和数据倾斜问题是比较常见的。那么我们该如何判断呢?同时该如何规避这两种问题呢?注意:该问题也经常会被面试官拿来提问面试者
解答
基于以…
十分钟带你走进Hive世界(每走一步都是为了离你更近些)
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料
该文基于Hive专题-从SQL聊Hive底层执行原理进一步的深入学习Hive,相信大多数童鞋对于Hive底层的执行流程只是局限于理论层面。那么本篇将带大家花半个小时左右的时间在自己…

面试官问:UDF是在Map端执行还是Reduce端执行?
感谢兄弟们的关注与支持,如果觉得有帮助的话,还请来个点赞、收藏、转发三操作
该文章已更新到语雀中,后台回复“语雀”可获取进击吧大数据整个职业生涯持续更新的所有资料
感谢
首先感谢linxiang同学提供的文章素材,linxiang在…
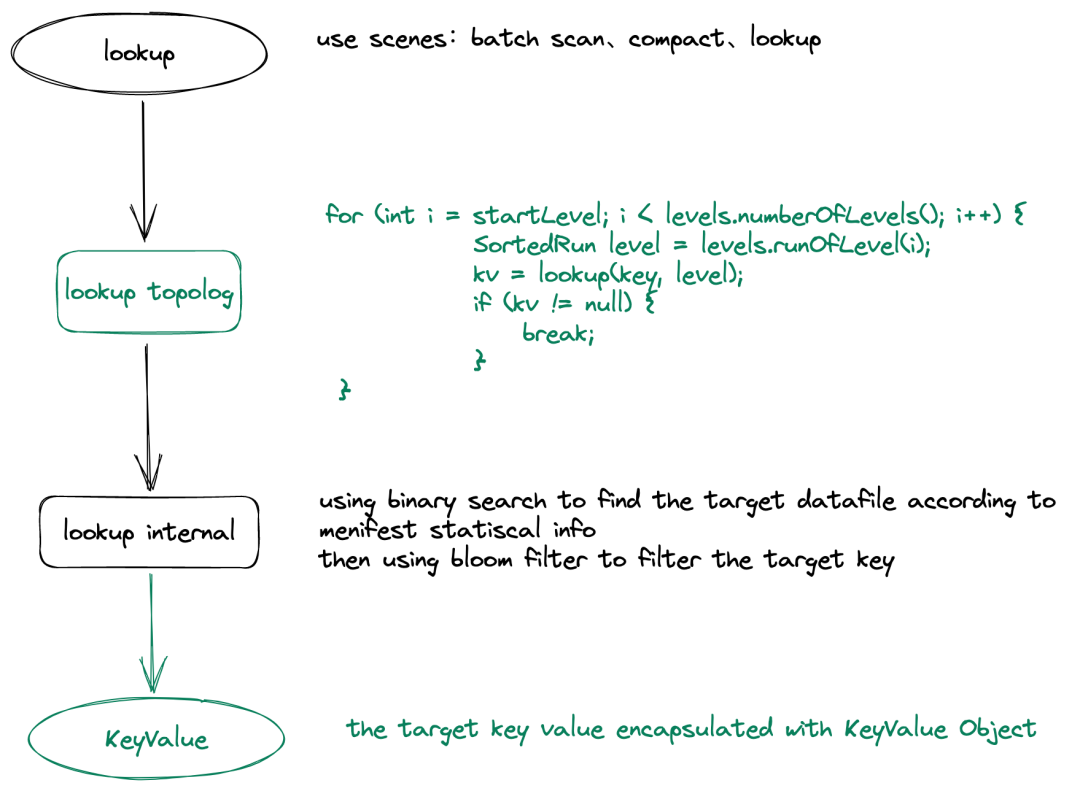
为什么Paimon值得期待?
前段时间 Flink table store 更名为 Apache Pimon ,并重新进入Apache incubator。截止目前,incubator-paimon项目已经在github上收获了600 Star(https://github.com/apache/incubator-paimon):之前虽然了解到Fink tabl…

Linux虚拟机安装sqoop-1.4.5-cdh5.3.6
下载
cdh5.3.6 密码:bqgj
【cdh】 链接: https://pan.baidu.com/s/1ASwsAS2eRrV7WpymuQS3-w 密码: bqgj
官方下载地址
配置
1.sqoop-env-template.sh 去除template
//更新前
#Set path to where bin/hadoop is available
#export HADOOP_COMMON_HOME#Set path to where h…
Hive 作业中Reduce个数设置多少合适呢?
前言
在上一篇文章《Hive 作业产生的map数越多越好还是越少越好?》中介绍了map个数设置多少合适的问题,那么Reduce个数设置多少合适呢?今天就给小伙伴们聊一下Reduce个数设置方法以及设置多少合适的原则!
1. Reduce个数设置方法
方法1
首先我们来看下reduce数的计算公式…
hive查询除某些字段的其余字段
在日常使用hive的时候,难免会遇到查询除某些字段的其余字段,比如使用开窗函数分组取第一条,那有没有一种方法能达到这个效果呢?答案是有的。
首先需要设置一个参数: set hive.support.quoted.identifiersNone; 然后指…
hive常用日期函数
工作原因有时候需要使用到hive的日期函数,但是很多东西都记不住,每次网上去找又浪费时间,干脆自己整理一个。 获取日期 select current_date(); --返回2021-04-26获取时间戳 # 单位:秒 返回bigint
select unix_timestamp(); --返回…
写hive到clickhouse的脚本遇到的问题及解决办法
文章目录背景步骤背景
最近有个需求,就是需要把hive的数据导入到clickhouse,目前的做法是先用waterdrop把hive的数据导入clickhouse的本地表中,然后再清洗写入分布式表中。手动处理已经是完全可以的,但是想做成定时调度ÿ…
大数据之使用datax完成rds到hdfs,hdfs到rds的导入导出
1、前言 mysql等数据存储技术,随着海量数据的不断增加,已经不能满足正常的业务需求。大数据技术带来的数据仓库为此带来很多解决方案。今天基于京东云的环境简单的搭建一个数据数据仓库,使用阿里出品的datax完成数据的导入和导出。
2、导入导…
Hudi学习笔记(1)
使用注意 从 0.10.0 版本开始,primaryKey 为必须的,不再支持没有主键的表。 primaryKey、primaryKey 和 type 均大小写敏感。 对于 MOR 类型的表,preCombineField 为必须的。 当设置 primaryKey、primaryKey 或 type 等 hudi 配置时&#…

2.Hive创建数据库
1.数据库操作
1.1 创建数据库
create database test comment Just for test location /abcd
with dbproperties(aaabbb);
comment后面指的是注释;location后面是数据库存放路径;dbproperties代表了数据库的属性
ps.避免要创建的数据库已经存在错误&…
【大数据学习篇4】Hive安装与操作
1. 安装MariaDB
在Centos7使用Yum安装MariaDB
全部删除MySQL/MariaDB
MySQL 已经不再包含在 CentOS 7 的源中,而改用了 MariaDB;
1.1 使用rpm -qa | grep mariadb搜索 MariaDB 现有的包:
如果存在,使用rpm -e --nodeps mariadb-*全部删除…
【大数据学习篇1】linux常用命令
查看目录下有什么文件信息
//list查看当前目录下有什么文件 ls //list -list 通过详细内容形式查看目录下的文件内容 ls -l 或 ll //查看指定目录下文件名字信息 ls 目录 //以详细列表形式查看指定目录下文件名字信息 ls -l 目录 //list all 查看全部文件,包括隐藏…
Hive Full Join多个表与Union All多个表
一.引言
假设有如下三张表,里面分别记录了三类不用用户的购买记录,现在想将下属记录合并为 > | 用户 | 果蔬购买量 | 饮品购买量 | 零食购买量 | ,没有购买则为 Null:
Table A:用户在超市近一个月购买果蔬的记录
Table B&am…
hive 删除表中数据,删除表,删除某条信息
删除表中数据
truncate table 表名(dmp_sdm_develop.tmp_exchange);
删除表
drop table if exists 表名(dmp_sdm_develop.tmp_exchange);
删除表中特定数据
insert overwrite table 表名(dmp_sdm_develop.tmp_exchange) select * from dmp_sdm_develop.tmp_exchange where…
hive删除数据、删除分区、删除库表
hive删除数据、删除分区、删除库表
-- 删除库
drop database if exists db_name;
-- 强制删除库
drop database if exists db_name cascade;-- 删除表
drop table if exists employee;-- 清空表
truncate table employee;
-- 清空表,第二种方式
insert overwr…
Hive2.3.9部署
Hive2.3.9部署
解压安装改名
tar -zxvf apache-hive-2.3.9-bin.tar.gz -C /opt
cd /opt/
mv apache-hive-2.3.9-bin/ hive
cd hive
cd conf/
mv hive-env.sh.template hive-env.sh
vim hive-env.sh添加以下内容
export HADOOP_HOME/opt/hadoop
export HIVE_CONF_DIR/opt/hiv…

List 集合相关方法 Sucha
List 集合相关方法 Sucha 1、将集合List中的对象,根据对象的id进行数据合并 问题描述: 比如业务员每天销售额归总 再比如我查询后台的相关数据,需要区分信息,字段内相同的id下,可能有用户1类型和用户2类型,…
Linux服务器搭建单机版Hive与搭建Hive集群
Linux服务器搭建单机版Hive与搭建Hive集群HiveHive概述Hive架构Hive计算引擎Linux安装Hive下载Hive解压及重命名配置hive-env.sh创建hive-site.xml配置日志添加驱动包配置环境变量初始化数据库启动HiveHive的交互方式使用bin/hive使用hiveServer2使用sql语句或者sql脚本Hive集群…

HIVE以及MySQL的安装配置
1)卸载已安装的mysql 2)安装mysql
wget http://repo.mysql.com/mysql80-community-release-el7.rpm
rpm -ivh mysql80-community-release-el7.rpm
yum install mysql-server
#chown user:user -R /var/lib/mysql
mysqld --initialize
systemctl start m…
统计hive-hdfs文件大小日常腾出磁盘
1 home目录下 klist -kt hdfs.keytab
2 kinit -kt hdfs.keytab hdfs/p-nc1mutapp02.jemincare.comNC1MUTAPP.JEMINCARE.COM
3 hdfs dfs -du -h /user/jmkx_data/hive_db/jmkx_data.db/ > ./a.txt 全量大小
4 hdfs dfs -du -s -h /user/jmkx_data/hive_db/jmkx_data.db/*/…
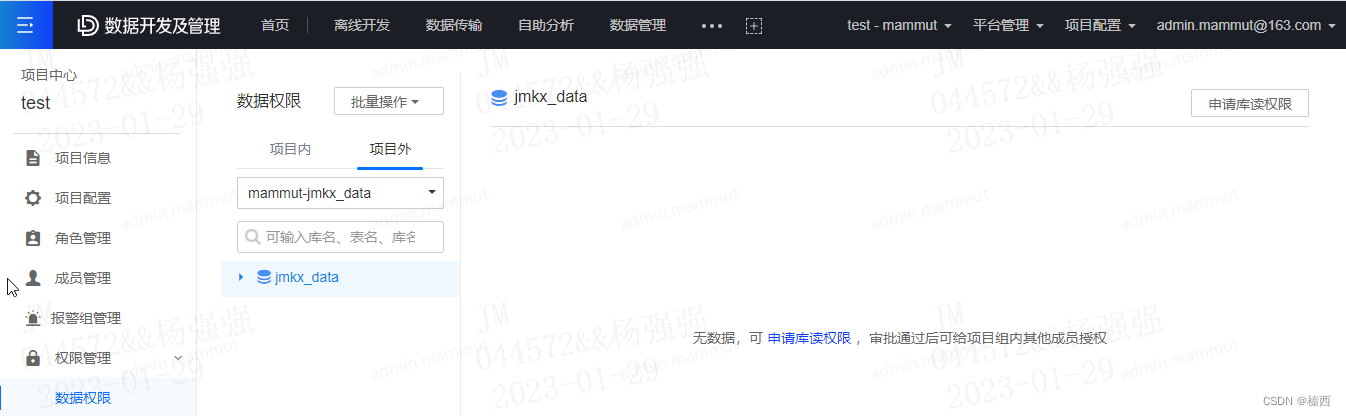
数据平台权限控制-基于猛犸
设置多项目: 专注本项目的逻辑和代码,不在本项目内的人员无法查看代码逻辑,但是可查询表 每张表的存储路径 如下 hdfs://cluster1/user/jmkx_data/hive_db/jmkx_data.db/ods_plm_newbudget_budgetcostreport_dd
在hive查询 两种方式都可以
…
Spark/Hive如何解析嵌套Json
Hive解析嵌套Json用get_json_object
数据是string类型,拆分的时候get_json_object的逗号后要加个空格 {"KdProjCode":"A20160518015NB","DTjType":"调价","xmlns:xsi":"http://www.w3.org/2001/XMLSchema-instance&q…

Hive中TDengine关联其他数据源查询时对YARN执行日志的误解
文章目录一、背景介绍 二、表介绍 三、问题场景 四、查看和分析YARN日志1.查看日志2.日志解读五、问题分析 1.确定InputFormat类与切片是否对应 2. 加日志分析 3. 构建源码包并重新上传六、再次分析 1.查看日志 2.最终结论七、问题解决一、背景介绍
在前一篇文章TDengine在Apa…
Hive参数调整详细
--压缩配置:
-- map/reduce 输出压缩(一般采用序列化文件存储)
set hive.exec.compress.output=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set mapred.output.compression.type=BLOCK;--任务中间压缩
set hive.exec.compress.i…
Hive学习使用一周感悟
最近一段时间主要在学习Hive SQL语句并完成了一个小任务,熟悉了Hive SQL的基本语法和应用,对进一步学习使用Hive SQL来分析处理数据打下了一个基础。 数据科学领域最重要的在于数据本身,一起技能和工具都是过程,数据既是开始也是结…
Hive的rename表 增加字段
Hive表更名问题——RENAME TABLE
ALTER TABLE table_name RENAME TO new_table_name 这个命令可以让用户为表更名。数据所在的位置和分区名并不改变。换而言之,老的表名并未“释放”,对老表的更改会改变新表的数据? 不,数…
Hive SQL 数据去重简析
hive的很多表中或在执行表的join命令后,有可能在若干字段上存在重复现象,为了后续业务的需要,减少计算量,需要对表的重复记录去重,最近几天,在学习使用HQL的应用,也尝试着处理表的重复记录问题。…

Hive SQL中join的使用
Hive SQL中的join有以下几种常用的方式: 1.left (outer) join,以join的左边表为基础输出,在结果表中满足on的条件的记录中增加右边表的字段值,以上图左一所示:
2. right (outer) join, 以join的右边表为基础输出&…
Hive的analyze
1、使用
分区表,无论字段
analyze TABLE td.pt_pmart_ceo_FIN_TRSF_CTR_SITE_MAP partition (dt) COMPUTE STATISTICS noscan
ps:一致报错的可能性在UDF函数建在了某个库下 ,只有在hue上的active database选择某个库的时候才能用UDF
2、目的
见名知意,它的目的就是为…
Hive表的删改都只能在事务表才可行
orc事务分桶表
CREATE TABLE table_name (id int,name string
)
CLUSTERED BY (id) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional""true","compactor.mapreduce.map.memory.mb""2048", …
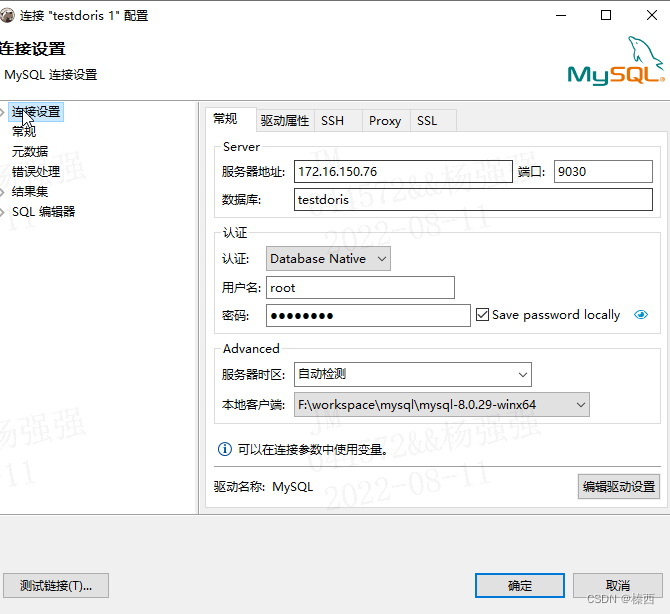
DBeaver使用-Hive-Phoenix链接hbase-Doris
Dbeaver跑动态分区不太行,开启不了,需要命令行去弄
下载
Download | DBeaver Community从左边下载社区版使用,zip版解压可以直接使用
文件->新建->DBeaver->数据库连接
连接Mysql 如果缺少对应驱动要确定下载 连接帆软FineDB
准…
Hive SQl语句的执行
1. hive语句执行时哪些在map执行,哪些在reduce执行呢 Map/Reduce是在物理执行计划的地方生成的。 很简单,ReduceSinkOpertor之前的在Map执行,ReduceSinkOperator之后的在Reduce执行,ReduceSinkOperator的作用是把数据从Map发到Re…
Sqoop的安装、配置与使用
本文目录如下:Sqoop的安装、配置与使用1.虚拟机环境准备2.Linux环境下安装Sqoop环境2.1 安装Sqoop3.使用Sqoop进行数据导入导出3.1 Sqoop 与 HDFS 之间的导入导出3.2 Sqoop 与 Hive 导入导出Sqoop的安装、配置与使用
1.虚拟机环境准备 (1) 虚拟机准备 虚拟机的创建…
hive中order by、distribute by、sort by和cluster by的区别和联系
order by
order by 会对数据进行全局排序,和oracle和mysql等数据库中的order by 效果一样,它只在一个reduce中进行所以数据量特别大的时候效率非常低。
而且当设置 :set hive.mapred.modestrict的时候不指定limit,执行select会报错…
spark-sql读写Hive遇到关于hive异常:Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaSt
我的机器是从主节点克隆的 ,需要把hive初始化一下 在Linux任意工作目录下, schematool -dbType mysql -initSchema 初始化的时候遇到错误Error: Duplicate key name ‘PCS_STATS_IDX’ (state42000,code1061) 只需要把mysql中的hive库删除掉 重新初始化hive就好了

38. 连续签到领金币数
文章目录 题目需求思路一实现一题目来源 题目需求
用户每天签到可以领1金币,并可以累计签到天数,连续签到的第3、7天分别可以额外领2和6金币。
每连续签到7天重新累积签到天数。
从用户登录明细表中求出每个用户金币总数,并按照金币总数倒…
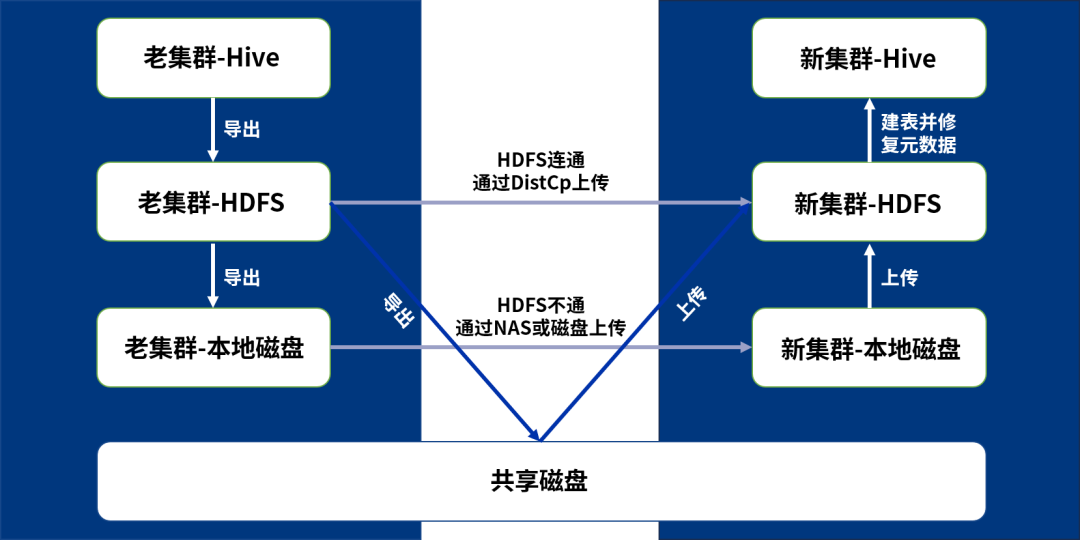
技术实践|Hive数据迁移干货分享
导语
Hive是基于Hadoop构建的一套数据仓库分析系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。它的优点是可以通过类SQL语句快速实现简单的MapReduce统计,不用再开发专门的MapReduce应用程序,从而降低…
Hive UDF、UDAF和UDTF函数详解
在 Hive 中,可以编写和使用不同类型的自定义函数,包括 UDF(User-Defined Functions)、UDAF(User-Defined Aggregate Functions)和 UDTF(User-Defined Table Functions)。这些自定义函数允许你扩展 Hive 的功能,以执行自定义的数据处理操作。 UDF(User-Defined Functi…
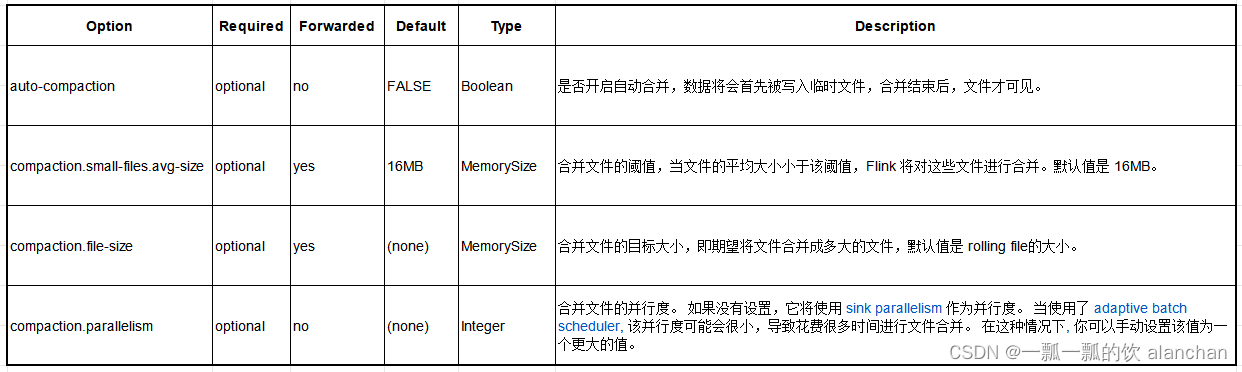
43、Flink之Hive 读写及详细验证示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…
hive anti join 的几种写法
t_a 表的记录如下
c1 | :———— | a | b | c |
生成 SQL 如下:
create table t_a(c1 string);
insert into t_a values("a"),("b"),("c");t_b 表的记录如下
c1bm
生成 SQL 如下:
create table t_b(c1 string);
in…
【Hive-Exception】return code 1 from org.apache.hadoop.hive.ql.exec.DDLTaskHIVE
解决方案:
set hive.msck.repair.batch.size1;
set hive.msck.path.validationignore;
MSCK REPAIR TABLE table_name;如果不能设置值,会报错。 Error: Error while processing statement: Cannot modify hive.msck.path.validation at runtime. It is …

实时数仓分层之DWM存在的意义
采集层,就是ODS(原始数据)层DWD层,离线数仓中在这一层当中分为了两块内容,一个是DWD,还有一个叫DIM,主要是针对于这个业务数据而言的,那如果说行为数据很简单,就都是DWD&…

Apache Hive之数据查询
文章目录 版权声明数据查询环境准备基本查询准备数据select基础查询分组、聚合JOINRLIKE正则匹配UNION联合Sampling采用Virtual Columns虚拟列 版权声明
本博客的内容基于我个人学习黑马程序员课程的学习笔记整理而成。我特此声明,所有版权属于黑马程序员或相关权利…
hive解决了什么问题
hive出现的原因
Hive 出现的原因主要有以下几个:
传统数据仓库无法处理大规模数据:传统的数据仓库通常采用关系型数据库作为底层存储,这种数据库在处理大规模数据时效率较低。MapReduce 难以使用:MapReduce 是一种分布式计算框架…
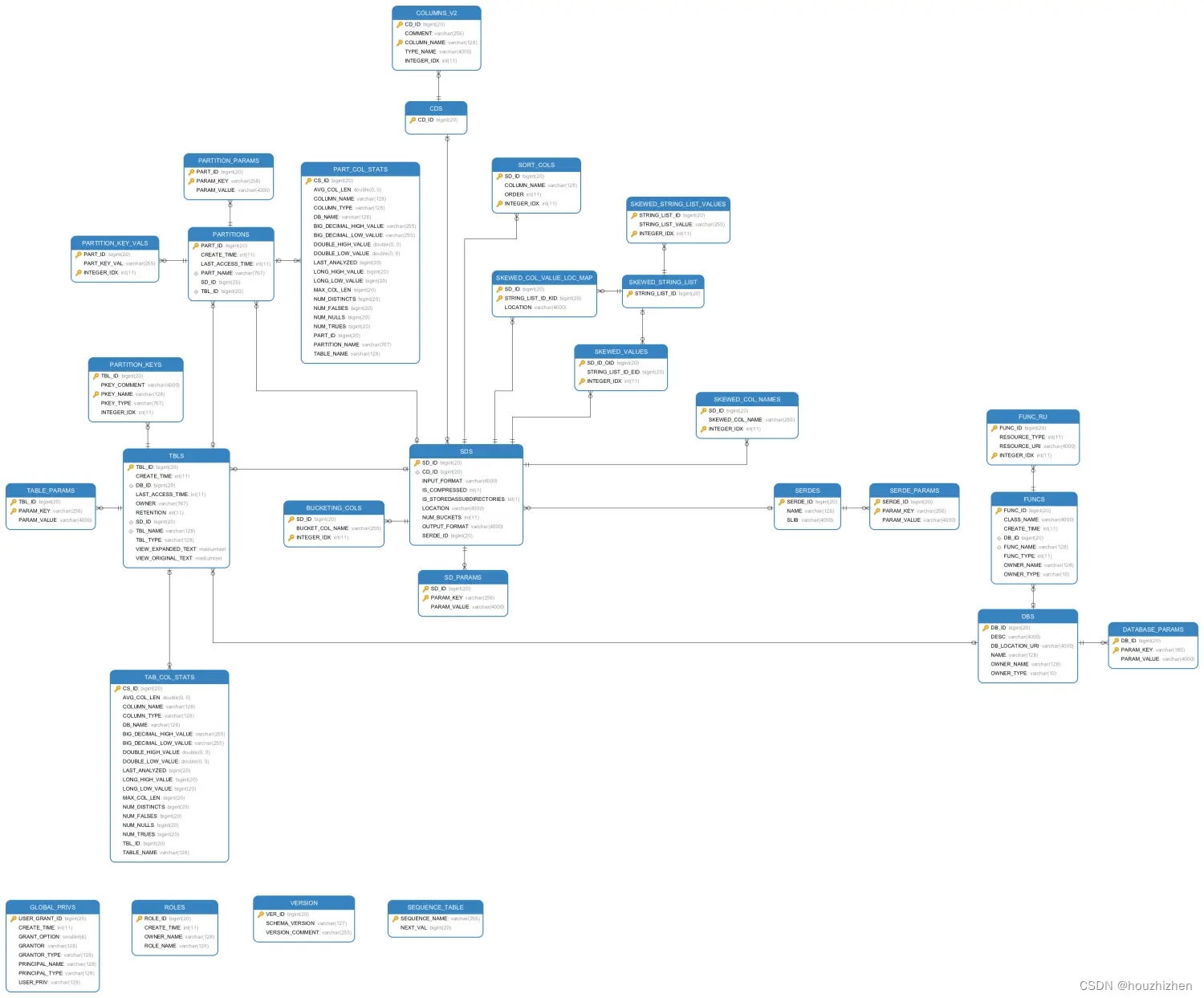
Hive Metastore 表结构
Hive MetaStore 的ER 图如下。 部分表结构和说明。
CTLGS(CATALOGS)
catalogs 可以隔离元数据。默认只有1行。一个 CATALOG 可以有多个数据库。
mysql> DESC CTLGS;
--------------------------------------------------------
| Field | Type | Null |…
Datax与Sqoop的对比
Sqoop主要特点
1、可以将关系型数据库中的数据导入hdfs、hive或者hbase等hadoop组件中,也可将hadoop组件中的数据导入到关系型数据库中;
2、sqoop在导入导出数据时,充分采用了map-reduce计算框架,根据输入条件生成一个map-reduc…
大数据基本操作锦集之Hive的基本操作
目录
简介hive的数据类型hive的数据存储hive的数据模型hive的DDL(数据库定义语言)hive的DML操作hive加载数据hive导出数据hive udf使用介绍正文 简介
hive在hadoop生态圈属于数据仓库角色,他能够管理hadoop中的数据,同时可以查询…

spark运行./tpcds-setup.sh后spark-sql进入找不到数据库问题解决
这里写目录标题一、问题二、解决一、问题
本人新建了一个tpcds,在导入tpcds 2G的数据时,发现导入hive后,在spark-sql进去找不到该数据库。
二、解决
实际上是安装spark和hive的问题,在安装hive时有个配置文件hive-site.xml&am…

【大数据之Hive】十九、Hive之文件格式和压缩
1 Hadoop压缩概述
Hive中的压缩算法与Hadoop中的压缩算法保持一致,可以把Hive当作Hadoop的一个客户端。 【大数据之Hadoop】十八、MapReduce之压缩
2 Hive文件格式 Hive表中常用的数据存储格式:text file(行式存储)、orc&#x…

一百八十六、大数据离线数仓完整流程——步骤五、在Hive的DWS层建动态分区表并动态加载数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(五)步骤五、在Hive的…
【dbeaver】win环境的kerberos认证和Clouders集群中Kerberos认证使用Dbeaver连接Hive和Phoenix
一、下载驱动
cloudera官网
1.1 官网页面下载
下载页面 的Database Drivers 挑选比较新的版本即可。
1.2 集群下载
Hive可能集群没有驱动包。驱动包名称:HiveJDBC42.jar。41结尾的包也可以使用的。注意Jar包的大小一定是十几MB的。几百KB的是thin包不可用。 …

datax同步数据翻倍,.hive-staging 导致的问题分析
一、背景
有同事反馈 Datax 从 Hive 表同步数据到 Mysql 数据翻倍了。通过查看 Datax 任务日志发现,翻倍的原因是多读取了 .hive-staging_xx 开头的文件。接下里就是有关 .hive-staging 的分析。
二、环境
Hive 版本 2.1.1
三、分析
3.1 .hive-staging_hive 产…
数仓开发常用hive命令
在做数仓开发或指标开发时,是一个系统工程,要处理的问题非常多,经常使用到下面这些hive命令: 内部表转外部表
alter table ${tablename} set tblproperties (EXTERNALTrue); 外部表转内部表
alter table ${tablename} set tblpr…
数据库:Hive转Presto(二)
继续上节代码,补充了replace_func函数,
import re
import os
from tkinter import *class Hive2Presto:def __int__(self):self.t_funcs [substr, nvl, substring, unix_timestamp] \[to_date, concat, sum, avg, abs, year, month, ceiling, floor]s…
HIVE SQL regexp_extract和regexp_replace配合使用正则提取多个符合条件的值
《平凡的世界》评分不错,《巴黎圣母院》改变成的电影不错,还有<<1984>>也蛮好看。 如何使用regexp_extract®exp_replace函数将以上文本中所有书籍名称都提取出来?
select substr(regexp_replace(regexp_extract(regexp_…
【Ambari】银河麒麟V10 ARM64架构_安装Ambari2.7.6HDP3.3.1问题总结
🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁 🦄 个人主页——🎐开着拖拉机回家_大数据运维-CSDN博客 🎐✨🍁 🪁🍁 希望本文能够给您带来一定的帮助🌸文…
Hive实战-表创建
Hive实战-表创建 使用ORC压缩储存空间 使用ORC压缩储存空间
什么是ORC? ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式。
ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。文件…
Hive【Hive(五)函数-高级聚合函数、炸裂函数】
高级聚合函数
多进一出(多行输入,一个输出)
普通聚合函数:count、sum ...
1)collect_list():收集并形成 list 集合,结果不去重
select sex,collect_list(job)
from e…
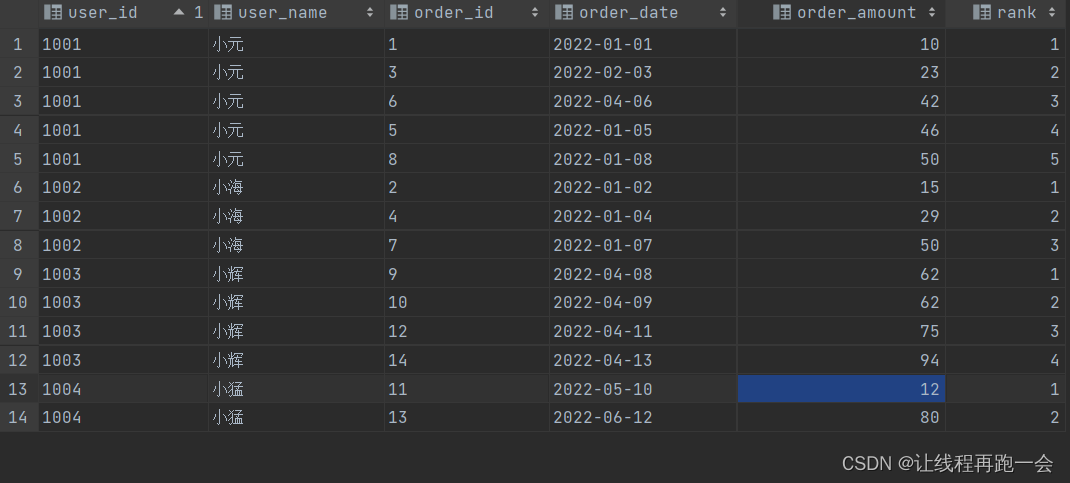
Hive 【Hive(七)窗口函数练习】
窗口函数案例
数据准备
1)建表语句
create table order_info
(order_id string, --订单iduser_id string, -- 用户iduser_name string, -- 用户姓名order_date string, -- 下单日期order_amount int -- 订单金额
);
2)装载语句
i…
Hive中生成自增序列的常用方法
在日常业务开发过程中,通常遇到需要hive数据表中生成一列唯一ID,当然连续递增的更好。
最近在结算业务中,需要在hive表中生成一列连续且唯一的账单ID,于是就了解生成唯一ID的方法
1. 利用row_number函数
语法:row_n…

Python操作Hive数据仓库
Python连接Hive 1、Python如何连接Hive?2、Python连接Hive数据仓库 1、Python如何连接Hive? Python连接Hive需要使用Impala查询引擎
由于Hadoop集群节点间使用RPC通信,所以需要配置Thrift依赖环境
Thrift是一个轻量级、跨语言的RPC框架&…

关于hive的时间戳
unix_timestamp()和 from_unixtime()的2个都是格林威治时间 北京时间 格林威治时间8 from_unixtme 是可以进行自动时区转换的 (4.0新特性)
4.0之前可以通过from_utc_timestamp进行查询 如果时间戳为小数,是秒&#…
大数据学习(6)-hive底层原理Mapreduce
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
hive复合类型的数据查询
hive数据表创建-CSDN博客 --第一个名字以M开头的 访问数组array 数组( array) 引用方式 列名 [ 元素索引 _ 以 0 开始 ] select * from emp
where emp_name[0] rlike "^M"; -- 出生日期是在 5 几年 访问 Map map 引用方式 列名 ["Key"] selec…
spark3使用hive zstd压缩格式总结
ZSTD(全称为Zstandard)是一种开源的无损数据压缩算法,其压缩性能和压缩比均优于当前Hadoop支持的其他压缩格式,本特性使得Hive支持ZSTD压缩格式的表。Hive支持基于ZSTD压缩的存储格式有常见的ORC,RCFile,Te…
关于hive sql进行调优的理解
这是一个面试经常面的问题,很不幸,在没有准备的时候,我面到了这个题目,反思了下,将这部分的内容进行总结,给大家一点分享。 hive其实是基于hadoop的数据库管理工具,底层是基于MapReduce实现的&a…

【大数据】图解 Hadoop 生态系统及其组件
图解 Hadoop 生态系统及其组件 1.HDFS2.MapReduce3.YARN4.Hive5.Pig6.Mahout7.HBase8.Zookeeper9.Sqoop10.Flume11.Oozie12.Ambari13.Spark 在了解 Hadoop 生态系统及其组件之前,我们首先了解一下 Hadoop 的三大组件,即 HDFS、MapReduce、YARN࿰…
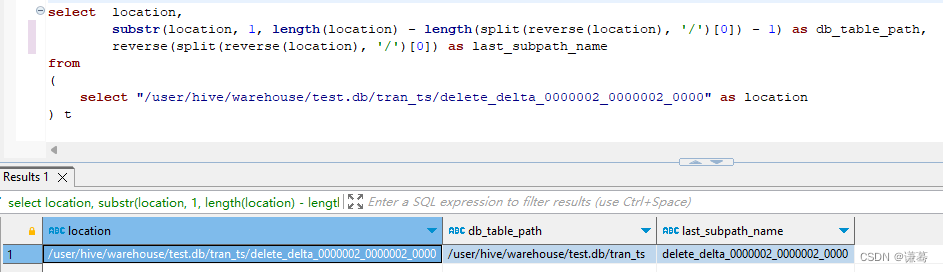
【Hive SQL】统计同名路径下目录数量(基于reverse、split和substr函数)
首先,Hive事务表所产生的的路径信息如下: PS:其中路径信息格式为
/user/hive/warehouse/${database_name}.db/${table_name}/*/user/hive/warehouse/test.db/tran_ts/delete_delta_0000002_0000002_0000
/user/hive/warehouse/test.db/tran_…
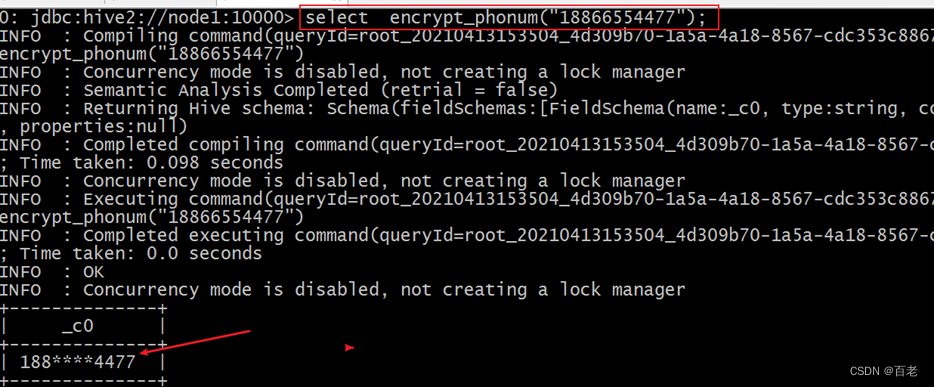
10分钟学会Hive之用户自定义函数UTF开发
1. 用户自定义函数概述 用户自定义函数简称UDF,源自于英文user-defined function。自定义函数总共有3类,是根据函数输入输出的行数来区分的,分别是:
UDF(User-Defined-Function)普通函数ÿ…

hive创建hbase表映射
将hbase中的表映射至hive中,便于表的操作
create external table student_info(id string,student_name string,gender string,pwd string,school_name string,location string
)
stored by org.apache.hadoop.hive.hbase.HBaseStorageHandler withserdeproperties…
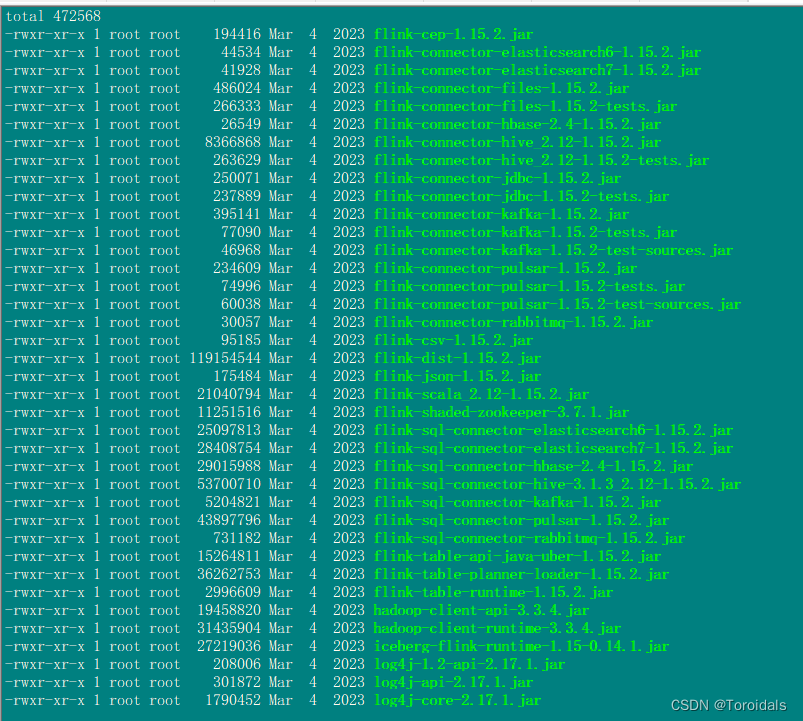
Flink、Spark、Hive集成Hudi
环境描述:
hudi版本:0.13.1
flink版本:flink-1.15.2
spark版本:3.3.2
Hive版本:3.1.3
Hadoop版本:3.3.4 一.Flink集成Hive
1.拷贝hadoop包到Flink lib目录
hadoop-client-api-3.3.4.jar
hadoop-client-runtime-3.3.4.jar
2.下载上传flink-hive的jar包
flink-co…
hive读取Hbase的数据
1、文档(不会的直接找文档最方便)
HBaseIntegration 2、拷贝jar文件
2.1 将Hbase/bin目录下面文件拷贝到Hive/bin目录下 cd /home/hbase/lib cp ./* /home/hive/lib
2.2 把Hive的lib目录下面的hive-hbase-handler-0.13.1.jar拷贝到Hbase的lib目录下面
cp /home/hive/lib/h…

Hive:从HDFS回收站恢复被删的表
场景 一张手工维护的内部表,本来排查没有使用,然后删掉了,发现又需要使用,只能恢复这张表了。
1.确认HDFS是否开启回收站功能 2.查看回收站中的数据
被删除的数据会放在删除数据时使用的用户目录下,如:使…
查看Hive表信息及占用空间的方法
一、Hive下查看数据表信息的方法
方法1:查看表的字段信息 desc table_name;
方法2:查看表的字段信息及元数据存储路径 desc extended table_name;
方法3:查看表的字段信息及元数据存储路径 desc formatted table_name;
方法4:…
datax同步clickhouse数据到hive
1.准备数据 1.1 clickhouse建表并插入数据 CREATE TABLE cell_towers_10
(radio Enum8( = 0, CDMA = 1,
hive 创建 s3 外表
背景
有个比较大的技术侧需求: 将数据从 HDFS 迁移到 s3。当然在真正迁移之前,还需要验证迁移到 s3 的数据,和上层查询器(hive、presto 之间的兼容性)
这里我们对一张业务表的数据做个简单的迁移测试
验证
数据迁移
为了让 h…
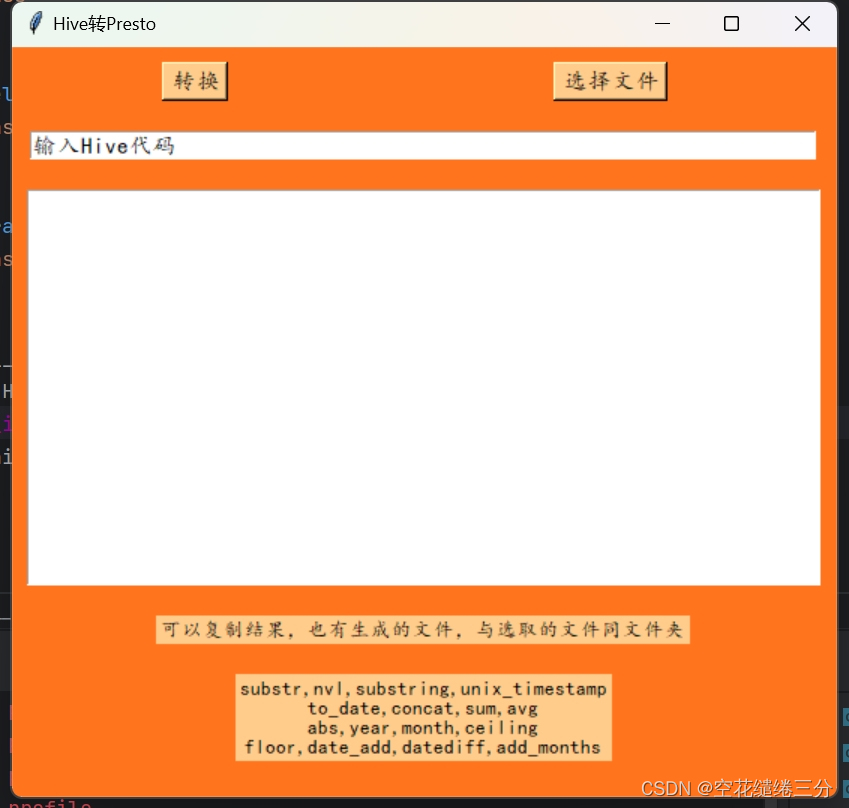
数据库:Hive转Presto(一)
本人因为工作原因,经常使用hive以及presto,一般是编写hive完成工作,服务器原因,presto会跑的更快一些,所以工作的时候会使用presto验证结果,所以就要频繁hive转presto,为了方便,我用…
datart导入hive连接包
datart读取hive数据时,需要先在datart的lib目录下导入hive jdbc相关的包,这里面有几个坑记录下:
1.和springboot中commons-lang3冲突
2.hive中带的jetty和springboot冲突
3.hive jdbc的包的版本号一定要小于登录hive服务端的版本ÿ…

大数据毕业设计选题推荐-河长制大数据监测平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…
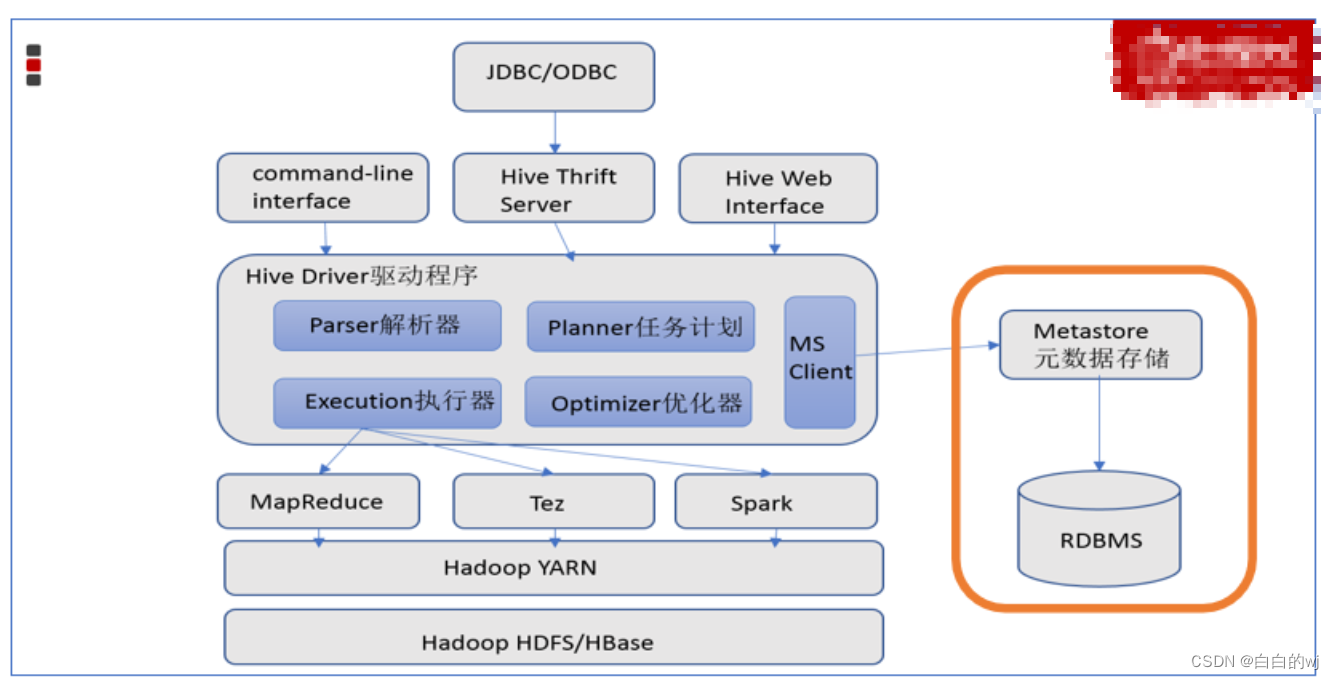
2023.11.10 hadoop,hive框架概念,基础组件
目录
分布式和集群的概念:
hadoop架构的三大组件:Hdfs,MapReduce,Yarn
1.hdfs 分布式文件存储系统 Hadoop Distributed File System
2.MapReduce 分布式计算框架
3.Yarn 资源调度管理框架
三个组件的依赖关系是:
hive数据仓库处理工具
hive的大体流程:
Apache hive的…
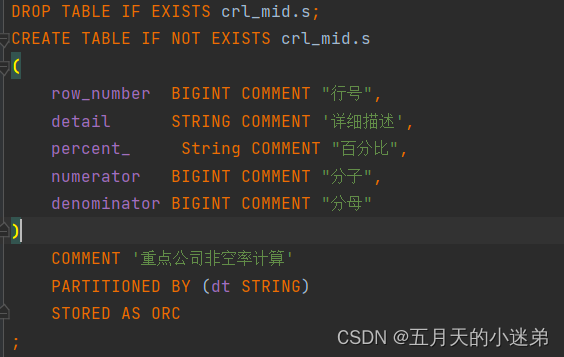
hive里因为列名用了关键字导致建表失败
代码 现象 ParseException line 6:4 cannot recognize input near percent String COMMENT in column name or primary key or foreign key 23/11/13 11:52:57 ERROR org.apache.hadoop.hive.ql.Driver: FAILED: ParseException line 6:4 cannot recognize input near percent …
Flink SQL --Flink 整合 hive
1、整合
# 1、将依赖包上传到flink的lib目录下
flink-sql-connector-hive-3.1.2_2.12-1.15.2.jar# 2、重启flink集群
yarn application -list
yarn application -kill application_1699579932721_0003
yarn-session.sh -d# 3、重新进入sql命令行
sql-client.sh
2、Hive cata…

2023.11.14-hive之表操作练习和文件导入练习
目录 需求1.数据库基本操作
需求2. 默认分隔符案例 需求1.数据库基本操作 -- 1.创建数据库test_sql,cs1,cs2,cs3
create database test_sql;
create database cs1;
create database cs2;
create database cs3;
-- 2.1删除数据库cs2
drop database cs2;
-- 2.2在cs3库中创建…
hive更改表结构的时候报错
现象 FAILED: ParseException line 1:48 cannot recognize input near ADD COLUMN compete_company_id in alter table statement 23/11/14 17:59:27 ERROR org.apache.hadoop.hive.ql.Driver: FAILED: ParseException line 1:48 cannot recognize input near ADD COLUMN compe…

2023.11.14-hive的类SQL表操作之,4个by区别
目录 1.表操作之4个by,分别是
2.Order by:全局排序
3.Cluster by
4.Distribute by :分区
5. Sort by :每个Reduce内部排序
6.操作练习
步骤一.创建表
步骤二.加载数据 步骤三.验证数据 1.表操作之4个by,分别是
order by 排序字段名
cluster by 分桶并排序字段名
dis…
hive数据质量规范
当谈到大数据处理和分析时,数据质量成为至关重要的因素。Hive作为一种常用的大数据查询和分析工具,也需要遵循一定的数据质量规范以确保数据的准确性、一致性和可靠性。本文将介绍Hive数据质量规范的相关内容,并提供代码示例来说明如何在Hive…
2023.11.16 hivesql 函数之类型转换,脱敏,与加密函数
1.类型转换函数
cast:主要用于类型转换,如果转换失败则返回null
select cast(3.14 as int); -- 3
select cast(3.14 as string) ; -- 3.14
select cast(3.14 as float); -- 3.14
select cast(3.14 as int); -- 3
select cast(binzi as int); -- null
很多时候,底层也默认做了…
2023.11.15-hivesql之炸裂函数explode练习
把一个容器的多个数据炸裂出单独展示: explode(容器) 需求:将NBA总冠军球队数据使用explode进行拆分,并且根据夺冠年份进行倒序排序。
1.建表
--step1:建表
create table the_nba_championship(team_name string,champion_year array<string>
) row format…
Hive入门--学习笔记
1,Apache Hive概述
定义: Hive是由Facebook开源用于解决海量结构化日志的数据统计,它是基于大数据生态圈Hadoop的一个数据仓库工具。 作用: Hive可以用于将结构化的数据文件【映射】为一张表,并提供类SQL查询功能。 H…
2023.11.16 hivesql高阶函数之json
目录
1.数据准备
2.操作
-- 方式1: 逐个(字段)处理, get_json_object UDF函数 最大弊端是一次只能解析提取一个字段
-- 方式2: 逐条处理. json_tuple 这是一个UDTF函数 可以一次解析提取多个字段 -- 方式3: 在建表时候, 直接处理json, row format SerDe 能处理Json的SerDe类…
Educoder中Hive综合应用案例——用户学历查询
第1关:查询每一个用户从出生到现在的总天数
---------- 禁止修改 ----------drop database if exists mydb cascade;
---------- 禁止修改 -------------------- begin ----------
---创建mydb数据库
create database mydb;---使用mydb数据库
use mydb;---创建表user
create …
ECRS生产工时分析软件:工业效率提升的隐形引擎
降本增效往往是企业开工规划的第一步。那到底降什么本,增什么效呢,对于很多企业来说,都是从采购成本入手,结果采购成本是降下来了,但是整体品质却下降了。实际上,要降本增效,优化现场管理才是企…
Hive日志默认存储在什么位置?
在hive-log4j.properties配置文件中,有这么一段配置信息 hive.log.thresholdALL
hive.root.loggerWARN,DRFA
hive.log.dir${java.io.tmpdir}/${user.name}
hive.log.filehive.log hive.log.dir就是日志存储在目录/tmp/${user.name}(当前用户名)/下
而hive.log就是h…
ke12Servlet规范有三个高级特性,,文件上传下载
1Servlet规范有三个高级特性
分别是Filter、Listener和文件的上传下载。Filter用于修改request、response对象,Listener用于监听context、session、request事件。 熟悉Filter的生命周期 了解Filter及其相关API 掌握Filter的实现 掌握Filter的映射与过滤器链的使用…
【大数据】Apache Hive数仓(学习笔记)
一、数据仓库基础概念
1、数仓概述
数据仓库(数仓、DW):一个用于存储、分析、报告的数据系统。 OLAP(联机分析处理)系统:面向分析、支持分析的系统。 数据仓库的目的:构建面向分析的集成化数据…
Hive引擎MR、Tez、Spark
Hive引擎包括:默认MR、Tez、Spark
不更换引擎hive默认的就是MR。
MapReduce:是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化࿰…
大数据Hadoop之——部署hadoop+hive+Mysql环境(window11)
一、安装JDK8 【温馨提示】对应后面安装的hadoop和hive版本,这里使用jdk8,这里不要用其他jdk了,可能会出现一些其他问题。 1)JDK下载地址
http://www.oracle.com/technetwork/java/javase/downloads/index.html 按正常下载是需要…
hive往es映射表写数据报错
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转…
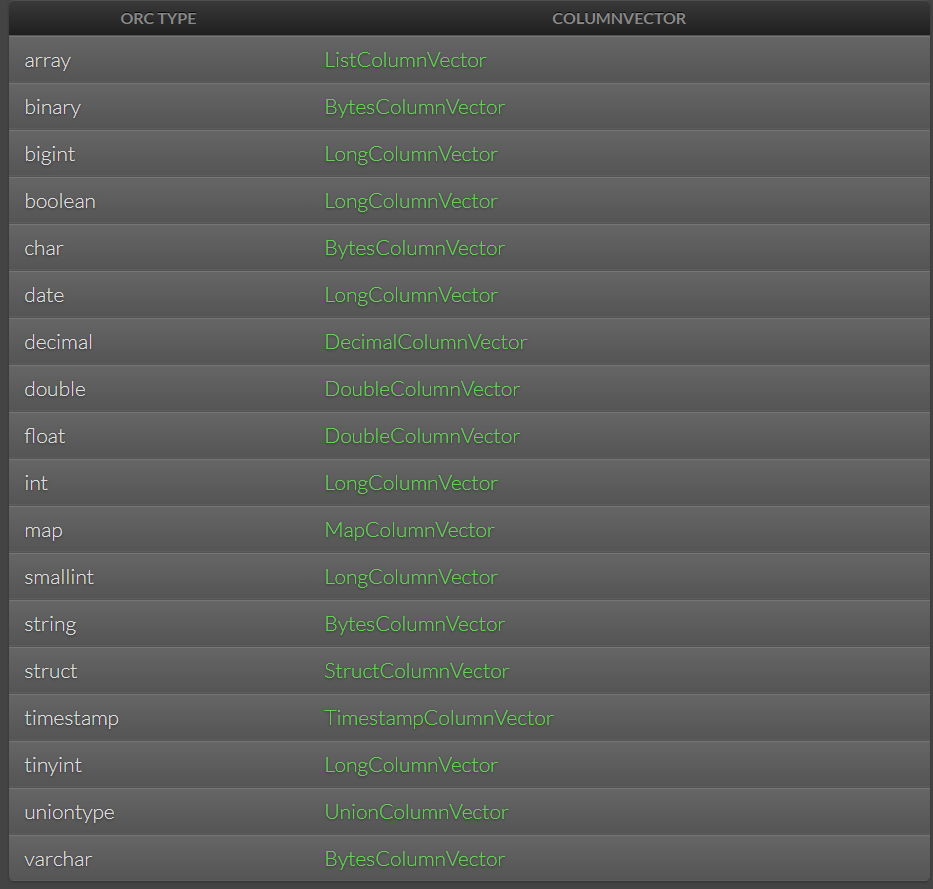
JAVA生成ORC格式文件
一、背景
由于需要用到用java生成hdfs文件并上传到指定目录中,在Hive中即可查询到数据,基于此背景,开发此工具类
ORC官方网站:https://orc.apache.org/
二、支持数据类型 三、工具开发
package com.xx.util;import com.alibab…
Hive 中级练习题(40题 待更新)
前言
最近快一周没更了,主要原因是最近在忙另一件事情(关于JavaFX桌面软件开发),眼看大三上一半时间就要过去了,抓紧先学Hive,完了把 Spark 剩下的补了,还有 Kafka、Flume,任务还是…
Hive insert插入数据与with子查询
1. insert into 与 insert overwrite区别
insert into 与 insert overwrite 都可以向hive表中插入数据,但是insert into直接追加到表中数据的尾部,而insert overwrite会重写数据,既先进行删除,再写入
注意:如果存在分…
![[Hive] explode](https://img-blog.csdnimg.cn/89a7d7071c1345e6a89c9118c1d4edb9.png)
[Hive] explode
在 Hive 中,explode 函数用于将数组(Array)或者Map类型的列拆分成多行,
每个元素或键值对为一行。这允许我们在查询中对数组或 Map 进行扁平化操作。 下面是使用 explode 函数的示例:
假设我们有一个包含数组字段的表…
hive针对带有特殊字符非法json数据解析
一、背景
有的时候前端或者后端进行埋点日志,会把json里面的数据再加上双引号,或者特殊字符,在落日志的时候,组装的格式就不是正常的json数据了,我们就需要将带有特殊字符的json数据解析成正常的json数据。
二、正则…
hive插入动态分区数据时,return code 2报错解决
目录
一、完整报错
二、原因
三、其他 一、完整报错 Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask 二、原因 大概率是因为没有开启允许动态分区或单次动态分区个数太小了。
-- 动态分区前…
Kafka To HBase To Hive
目录 1.在HBase中创建表
2.写入API
2.1普通模式写入hbase(逐条写入)
2.2普通模式写入hbase(buffer写入)
2.3设计模式写入hbase(buffer写入)
3.HBase表映射至Hive中 1.在HBase中创建表
hbase(main):00…
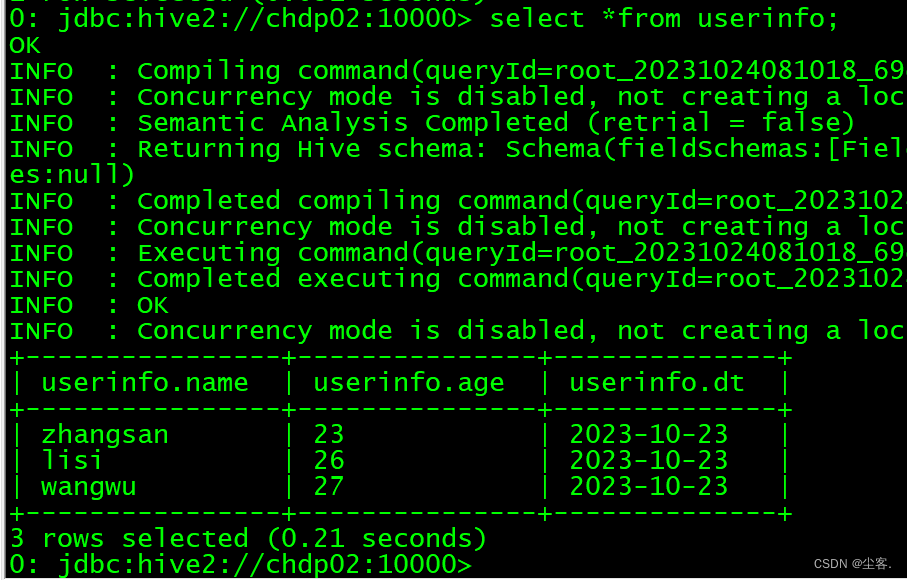
Hive安装配置笔记
版本说明
hadoop-3.3.6(已安装) mysql-8(已安装) hive-3.1.3 将hive解压到对应目录后做如下配置:
基本配置与操作
1、hive-site <configuration><!-- jdbc连接的URL --><property><name>ja…
hive的安装配置笔记
1.上传hive安装包
2.解压
3.配置Hive(在一台机器上即可) mv hive-env.sh.template hive-env.sh 4.运行hive 发现内置默认的metastore存在问题(1.换执行路径后,原来的表不存在了。2.只能有一个用户访问同一个表) 5.配置mysql的meta…

【hive】—原有分区表新增加列(alter table xxx add columns (xxx string) cascade;)
项目场景:
需求:需要在之前上线的分区报表中新增加一列。 实现方案:
1、创建分区测试表并插入测试数据
drop table test_1;
create table test_1
(id string,
score int,
name string
)
partitioned by (class string)
row format delimit…

大数据毕业设计选题推荐-旅游景点游客数据分析-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
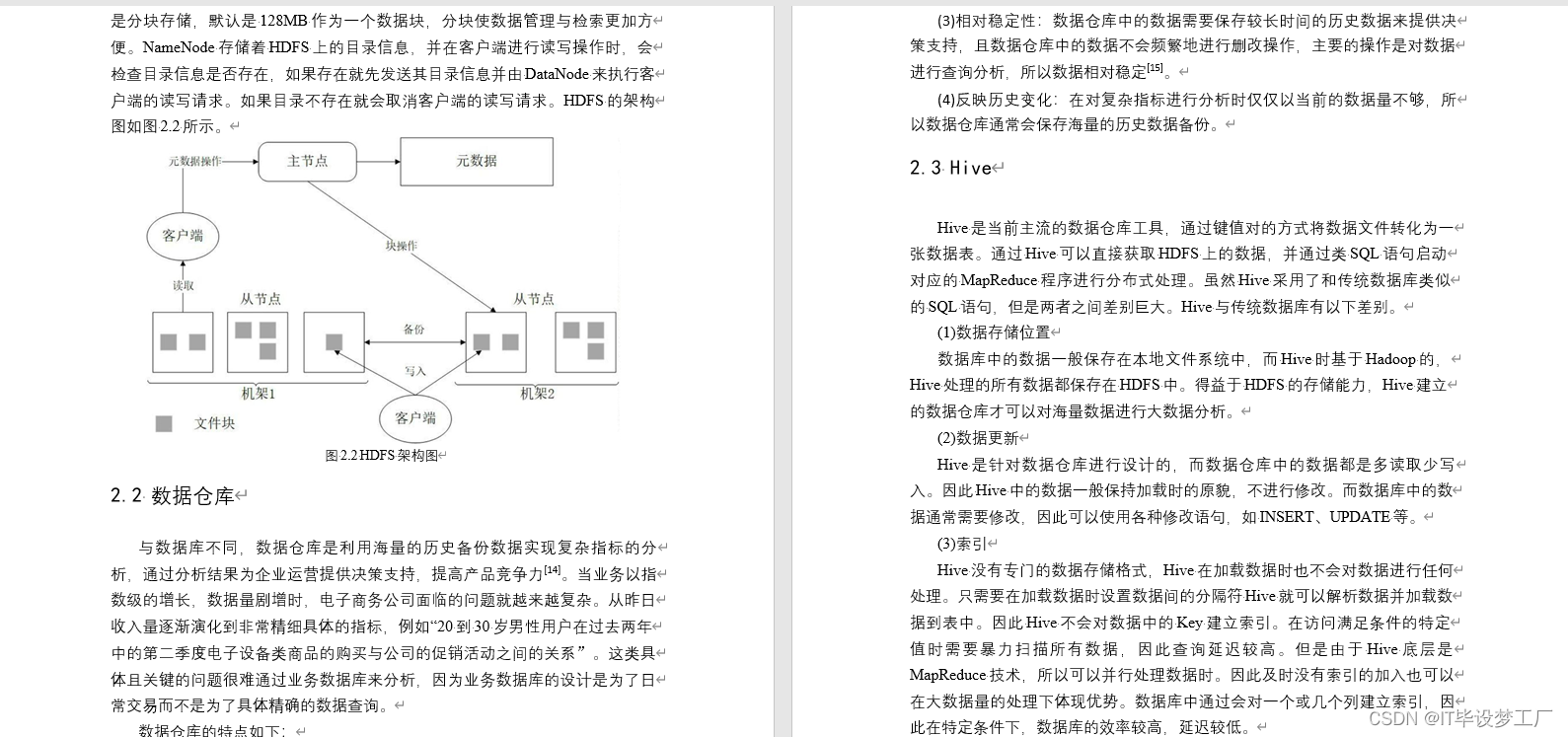
大数据毕业设计选题推荐-无线网络大数据平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…

分布式数据库·Hive和MySQL的安装与配置
一、版本要求:Hadoop:hadoop-2.10.1、MySQL:mysql-8.0.35、
HIVE:apache-hive-3.1.2、MySQL驱动:mysql-connector-java-5.1.49
安装包网盘链接:阿里云盘分享
安装位置 Hive:master、MySQL:slave1
二、卸载已安装的…

大数据毕业设计选题推荐-市天气预警实时监控平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…
Hive的安装配置、初始化元数据、启动
Hive的安装配置、初始化元数据、启动
1、解压hive到指定目录/usr/local/src 改名,将mysql的驱动包拷贝到hive的lib目录下 2、环境变量
1) vi /etc/profile export HIVE_HOME/usr/local/src/hive export PATH P A T H : PATH: PATH:HIVE_HOME/bin
echo…
【Hive】——数据仓库
1.1 数仓概念
数据仓库(data warehouse):是一个用于存储,分析,报告的数据系统 目的:是构建面向分析的集成化数据环境,分析结果为企业提供决策支持 特点: 数据仓库本身不产生任何数据…
Apache Hive(部署+SQL+FineBI构建展示)
Hive架构 Hive部署 VMware虚拟机部署
一、在node1节点安装mysql数据库
二、配置Hadoop
三、下载 解压Hive
四、提供mysql Driver驱动
五、配置Hive
六、初始化元数据库
七、启动Hive(Hadoop用户)
chown -R hadoop:hadoop apache-hive-3.1.3-bin hive
阿里云部…
【数据开发】Hive 多表join中的条件过滤与指定分区
1、条件过滤
left join 中 on 后面加条件 where 和 and 的区别
1、 on条件是在生成临时表时使用的条件,它不管and中的条件是否为真,都会保留左边表中的全部记录。2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有le…
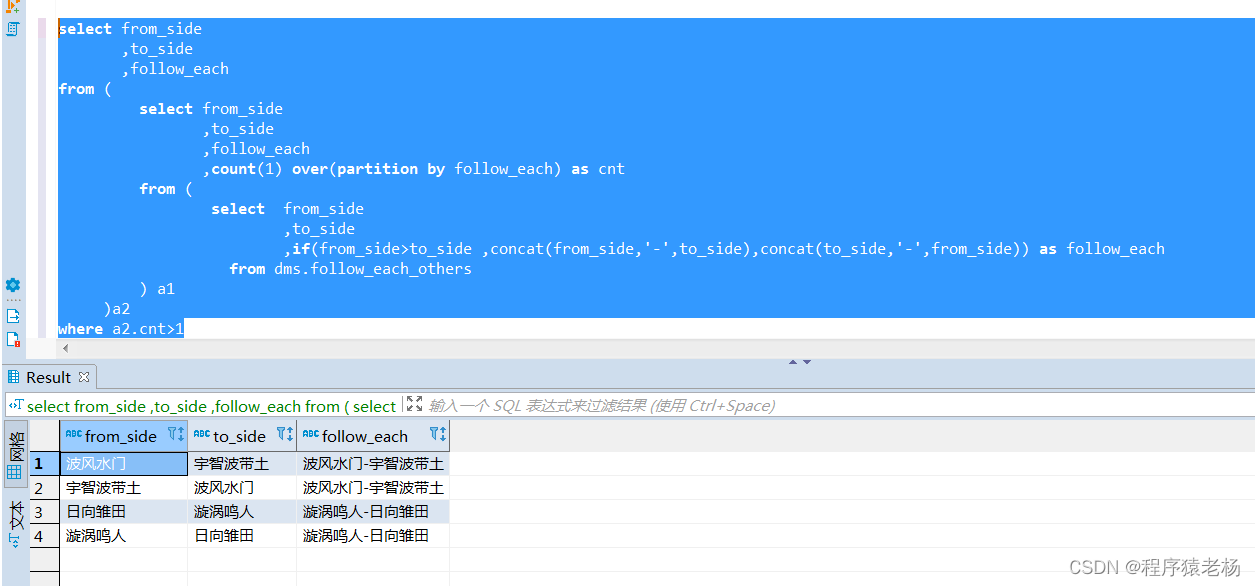
sql面试题之“互相关注的人”(方法二)
题目:某社交平台有关注这个功能,关注的同时也会被关注。现有需求需要找出平台上哪些用户之间互相关注。 文章目录 题目如下:一、数据准备二、建表并导入数据1.建表2.导入数据3.题目分析4.小结 题目如下:
某社交平台后端有user_re…
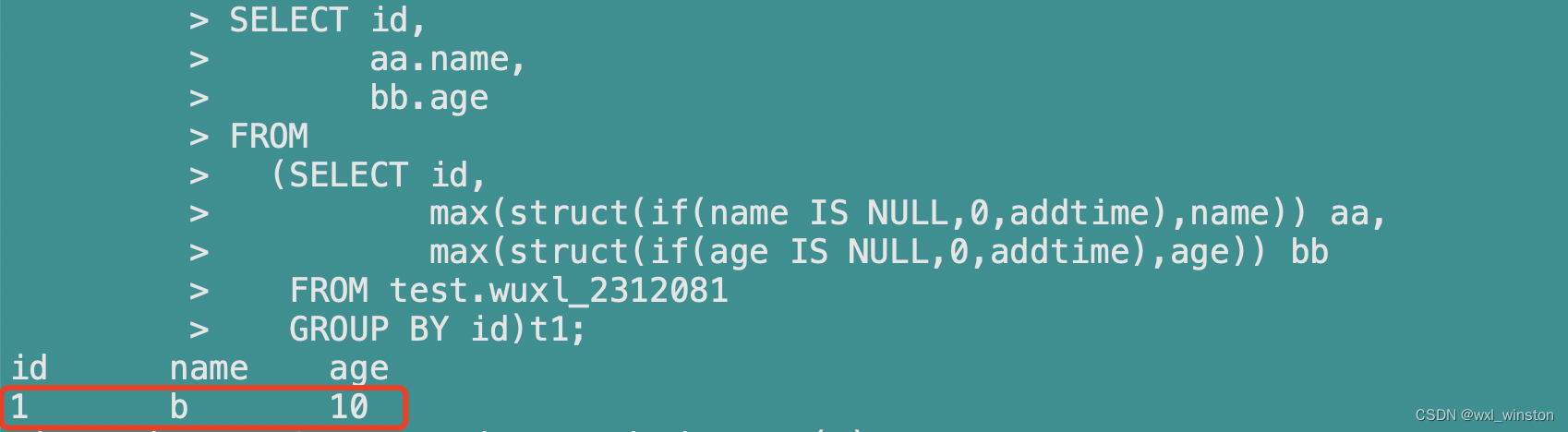
记录hive/spark取最新且不为null的方法
听标题可能听不懂我想表达的意思,我来描述一下我要做的事: 比如采集同学对某一网站进行数据采集,同一个用户每天会有很多条记录,所以我们要取一条这个用户最新的状态,比如用户改了N次昵称,我们只想得到最后…
Sqoop入门:如何下载、配置和使用
下载和配置
Sqoop是Apache的一个开源工具,主要用于在Hadoop和关系数据库之间传输数据。以下是一些关于如何下载和配置Sqoop的步骤: 下载Sqoop:你可以从Apache的官方网站下载Sqoop。大多数企业使用的Sqoop版本是Sqoop1,例如sqoop-…
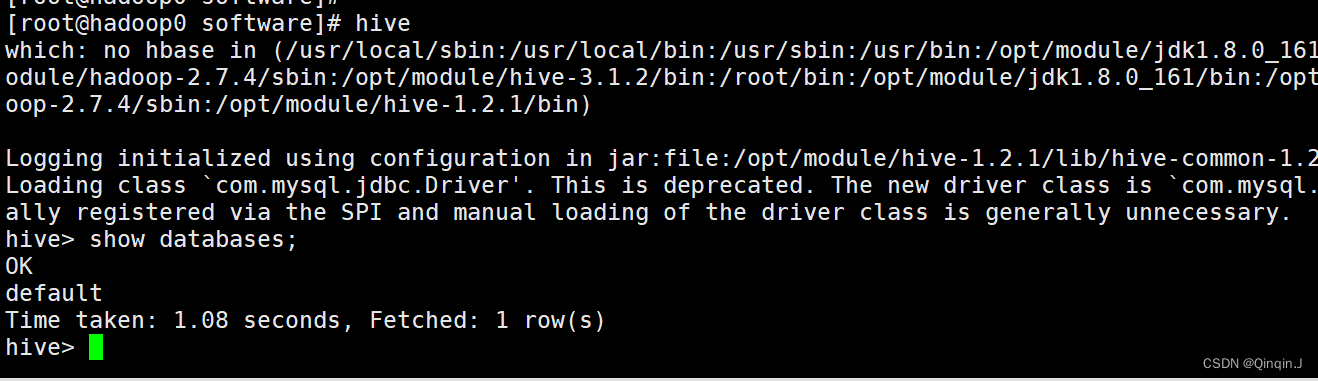
Hadoop学习总结(Hive的安装)
Hive的安装模式分为3种,分别是嵌入模式、本地模式、远程模式。 (1)嵌入模式:使用内嵌的 Derby 数据库存储元数据,这种方式是 Hive 的默认安装方式,配置简单,但是一次只能连接一个客户端…
导入pgsql中的保存的html数据到hive时,换行符无法被repalce
数据如图所示: 当我使用replace函数 \r\n 、\r 、 \n替换时。无论如何都无法替换
最终发现可以使用chr(ASCII码) 可以匹配到,坑我好久。
replace(replace(replace(replace(replace(bid_html_con, chr(9),),chr(10),),chr(13),),chr(160),),chr(32),)
查看hive表储存在hdfs的哪个目录下
查看hive表储存在hdfs的哪个目录下
使用Hive的DESCRIBE FORMATTED命令。
具体步骤如下: 打开Hive终端,并连接到Hive数据库。 运行以下命令,将表名替换为你要查询的表名:
DESCRIBE FORMATTED your_table_name;在输出中&#x…
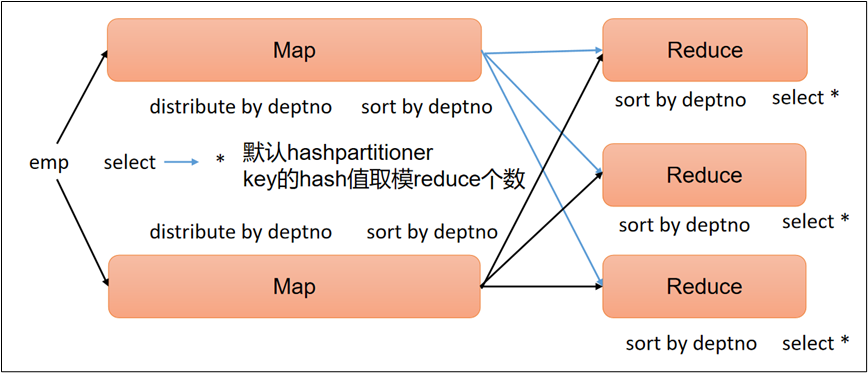
【Hive_02】查询语法
1、基础语法2、基本查询(Select…From)2.1 全表和特定列查询2.2 列别名2.3 Limit语句2.4 Where语句2.5 关系运算函数2.6 逻辑运算函数2.7 聚合函数 3、分组3.1 Group By语句3.2 Having语句3.3 Join语句(1)等值与不等值Join&#x…
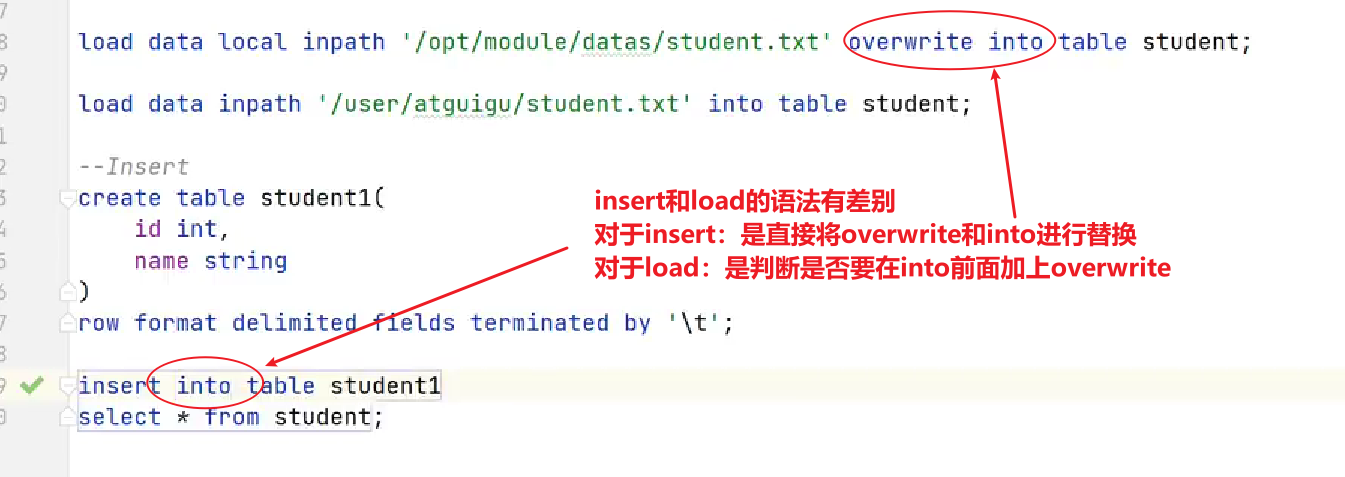
【Hive_01】hive关于数据库和表的语法
1、Hive常见使用技巧1.1 交互式与非交互式1.2 hive参数配置方式 2、DDL数据定义2.1 创建数据库(1)创建数据库(2)查询数据库(3)修改数据库(4)删除数据库(5)切换…
Hive数据库与表操作
文章目录 一、准备工作二、Hive数据库操作(一)Hive数据存储(二)创建数据库(三)查看数据库(四)修改数据库信息 一、准备工作 二、Hive数据库操作
(一)Hive数据…
Hive进阶函数:inline() 和 struct() ,一列转多行
一、使用场景 如果存在一张表,记录的是每位学生的各科成绩,现在想把表转换为纵向存储 比如: name|english|math|history tom |80 |90 |100 转换为: name&…
【运维】hive 高可用详解: Hive MetaStore HA、hive server HA原理详解;hive高可用实现
文章目录 一. hive高可用原理说明1. Hive MetaStore HA2. hive server HA 二. hive高可用实现1. 配置2. beeline链接测试3. zookeeper相关操作 一. hive高可用原理说明
1. Hive MetaStore HA Hive元数据存储在MetaStore中,包括表的定义、分区、表的属性等信息。 hi…

玩转大数据:2-揭秘Hadoop家族神秘面纱
1. 初识Hadoop家族
在当今的数字化时代,大数据已成为企业竞争的关键因素之一。为了有效地管理和分析这些庞大的数据,许多企业开始采用Hadoop生态系统。本文将详细介绍Hadoop生态系统的构成、优势以及应用场景。
首先,让我们来了解一下什么是…
hive里如何高效生成唯一ID
常见的方式: hive里最常用的方式生成唯一id,就是直接使用 row_number() 来进行,这个对于小数据量是ok的,但是当数据量大的时候会导致,数据倾斜,因为最后生成全局唯一id的时候,这个任务是放在一个…
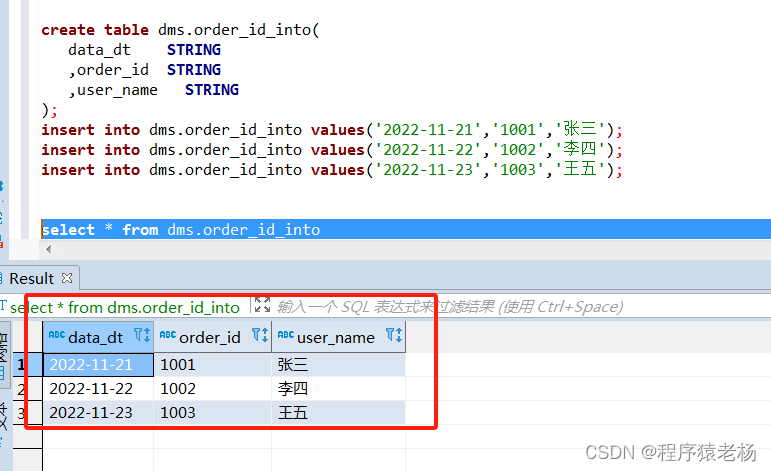
HIVE 中INSERT INTO 和 INSERT OVERWRITE 的区别,以及OVERWRITE哪些隐藏的坑
HIVE 中INSERT INTO 和 INSERT OVERWRITE 的区别,以及 overwrite 在分区表和非分区表中使用时的注意事项。
概要 1.hive中insert into 和 inset overwrite 的区别 2.hive中overwrite 在分区表和非分区表中使用时的注意事项
insert into 和 insert overwrite 我们都知道在hi…
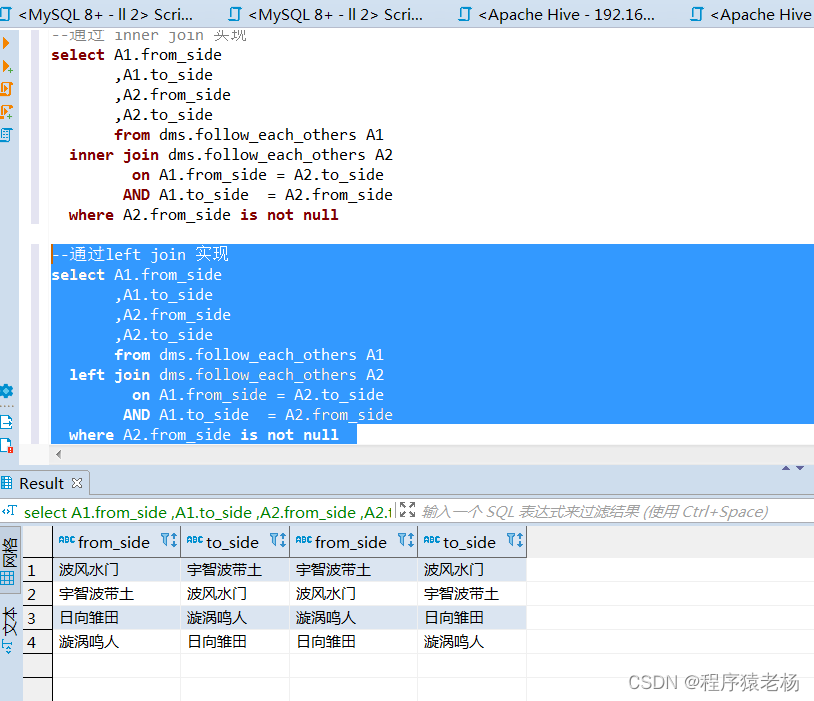
sql面试题之“互相关注的人”(方法三)
题目:某社交平台有关注这个功能,关注的同时也会被关注。现有需求需要找出平台上哪些用户之间互相关注。 文章目录 题目如下:一、数据准备二、建表并导入数据1.建表2.导入数据3.数据分析和实现思路小结: 题目如下:
某社…
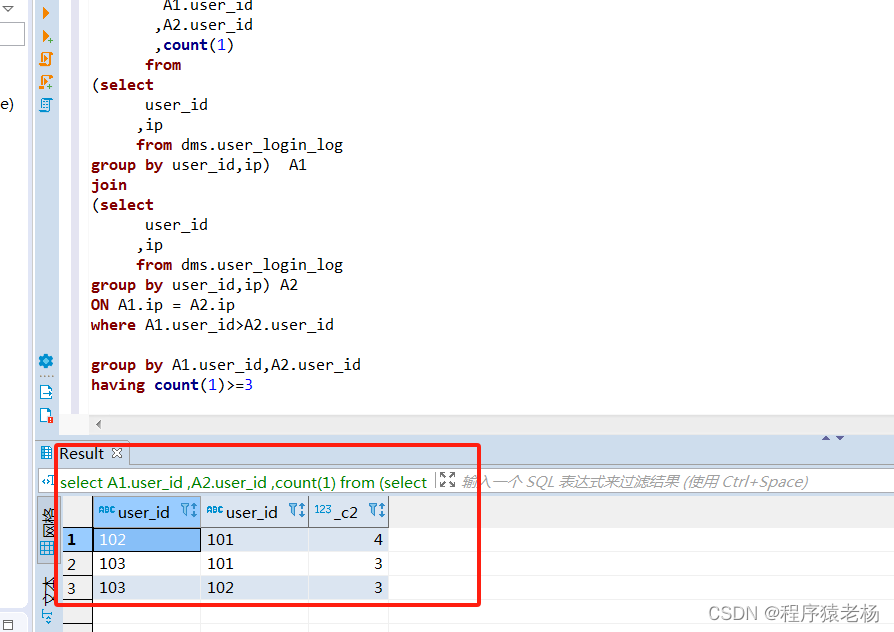
sql面试题之”找出使用相同ip的用户“
现有一张表,里面有三个字段为user_id、ip、log_time,现有需求要找出用户共同使用ip数量大于等于3个的用户对找出来。 1.表数据准备 --建表语句 create table dms.user_login_log(user_id string ,ip string,log_time string);
--插入数据 insert into dms…
Hive jar包冲突问题排查解决
1、报错情况
hiveserver2启动失败,查看日志报错:
2022-07-04T20:14:53,315 WARN [main]: server.HiveServer2 (HiveServer2.java:startHiveServer2(1100)) - Error starting HiveServer2 on attempt 1, will retry in 60000ms
java.lang.NoSuchMethod…
hive sql常用函数
目录 一、数据类型
二、基础运算
三、字符串函数
1、字符串长度函数: length()
2、字符串反转函数:reverse
3、字符串连接函数
4、字符串截取函数
5、字符串分割函数:split
6、字符串查找函数
7、ascii
8、base64
9、character_length
10、c…

Hive-high Avaliabl
hive—high Avaliable
hive的搭建方式有三种,分别是
1、Local/Embedded Metastore Database (Derby)
2、Remote Metastore Database
3、Remote Metastore Server
一般情况下,我们在学习的时候直接使用hive –service metastore的方式…

SpringBoot 3 集成Hive 3
前提条件:
运行环境:Hadoop 3.* Hive 3.* MySQL 8 ,如果还未安装相关环境,请参考:Hive 一文读懂
Centos7 安装Hadoop3 单机版本(伪分布式版本)
SpringBoot 2 集成Hive 3
pom.xml
<?xml ver…

十八、本地配置Hive
1、配置MYSQL
mysql> alter user rootlocalhost identified by Yang3135989009;
Query OK, 0 rows affected (0.00 sec)mysql> grant all on *.* to root%;
Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)2、…
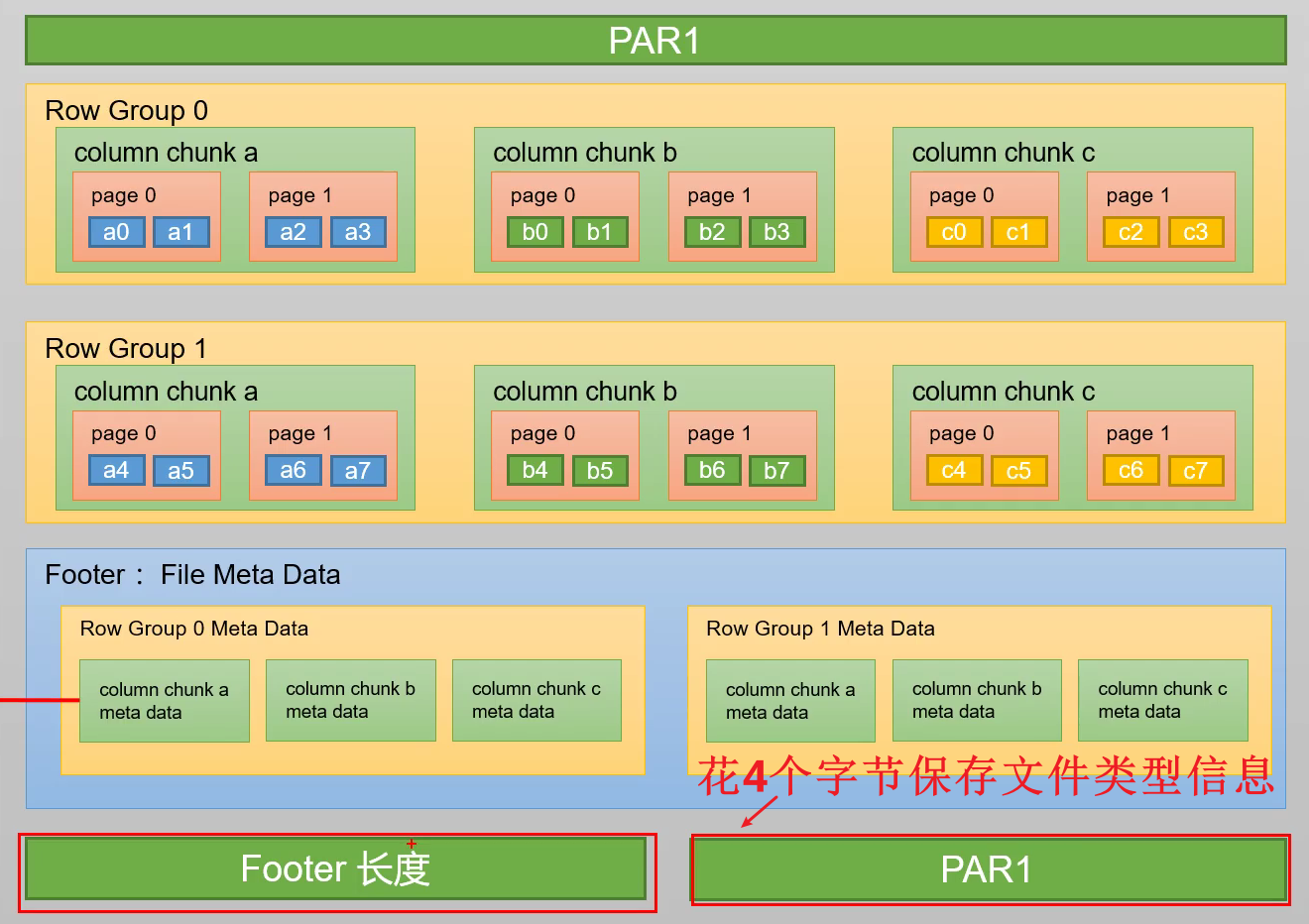
【Hive_04】分区分桶表以及文件格式
1、分区表1.1 分区表基本语法(1)创建分区表(2)分区表读写数据(3)分区表基本操作 1.2 二级分区1.3 动态分区 2、分桶表2.1 分桶表的基本语法2.2 分桶排序表 3、文件格式与压缩3.1 Hadoop压缩概述3.2 Hive文件…
Hive01_安装部署
Hive的安装 上传安装包 解压 tar zxvf apache-hive-3.1.2-bin.tar.gz
mv apache-hive-3.1.2-bin hive解决Hive与Hadoop之间guava版本差异 cd /export/software/hive/
rm -rf lib/guava-19.0.jarcp cp /export/software/hadoop/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0…
hive中struct相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释
hive官网函数大全地址:添加链接描述
Return TypeNameDescriptionstructstruct(val1, val2, val3, …)Creates a struct with the given field values. Struct field names will be col1, col2, …structnamed_str…
[hive] sql中distinct的用法和注意事项
在 Hive SQL 中,DISTINCT 用于去重查询结果中的行。它返回唯一的行,消除结果集中的重复项。以下是 DISTINCT 的基本用法和一些注意事项:
基本用法:
-- 获取列1和列2的唯一组合
SELECT DISTINCT column1, column2 FROM your_tabl…
Hive-数据模型详解(超详细)
文章目录 一、Hive数据模型1. 概述2. 数据库和表(1) 创建数据库(2) 使用数据库(3) 创建表格(4) 查看表结构 3. 分区与桶(1) 分区(2) 桶 4. 数据加载与查询(1) 数据导入(2) 查询语句 5. 总结 一、Hive数据模型
1. 概述
Hive是基于Hadoop的数据仓库工具,它提供了类似…
HBase基础知识(六):HBase 对接 Hive
1. HBase 与 Hive 的对比 1.Hive (1) 数据仓库 Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以 方便使用 HQL 去管理查询。
(2) 用于数据分析、清洗 Hive 适用于离线的数据分析和清洗,延迟较高。
(3) 基于…
【Hive_05】企业调优1(资源配置、explain、join优化)
1、 计算资源配置1.1 Yarn资源配置1.2 MapReduce资源配置 2、 Explain查看执行计划(重点)2.1 Explain执行计划概述2.2 基本语法2.3 案例实操 3、分组聚合优化3.1 优化说明(1)map-side 聚合相关的参数 3.2 优化案例 4、join优化4.1…
【Hadoop-OBS-Hive】利用华为云存储对象 OBS 作为两个集群的中间栈 load 文件到 Hive
【Hadoop-OBS-Hive】利用华为云存储对象 OBS 作为两个集群的中间栈 load 文件到 Hive 1)压缩文件2)上传文件到 OBS 存储对象3)crontab 定时压缩上传4)从 obs 上拉取下来文件后解压缩5)判断对应文件是否存在6࿰…
hive 常见存储格式和应用场景
1.存储格式 textfile、sequencefile、orc、parquet sequencefile很少使用(不介绍了),常见的主要就是orc 和 parquet 建表声明语句是:stored as textfile/orc/parquet行存储:同一条数据的不同字段都在相邻位置ÿ…
23. 常用shell之 df - 显示磁盘空间使用情况 的用法和衍生用法
df(disk free)是一个在 Unix 和类 Unix 系统(如 Linux 和 macOS)中用于显示磁盘空间使用情况的命令。这个命令对于系统管理员和用户来说非常重要,因为它可以帮助监控和管理磁盘空间的使用情况。
基本用法
df 命令的基…

将Sqoop与Hive集成无缝的数据分析
将Sqoop与Hive集成是实现无缝数据分析的重要一步,它可以将关系型数据库中的数据导入到Hive中进行高级数据处理和查询。本文将深入探讨如何实现Sqoop与Hive的集成,并提供详细的示例代码和全面的内容,以帮助大家更好地了解和应用这一技术。
为…

【Hive】——DDL(TABLE)
1 查询指定表的元数据信息
如果指定了EXTENDED关键字,则它将以Thrift序列化形式显示表的所有元数据。 如果指定了FORMATTED关键字,则它将以表格格式显示元数据。
describe formatted student;2 删除表
如果已配置垃圾桶且未指定PURGE&…
Spark-Streaming+HDFS+Hive实战
文章目录 前言一、简介1. Spark-Streaming简介2. HDFS简介3. Hive简介二、需求说明1. 目标:2. 数据源:3. 数据处理流程:4. HDFS文件保存:5. Hive外部表映射:三、实战示例演练1. 编写gbifdataset.properties配置文件2. 导入依赖3. 编写ConfigUtils类4. 编写FieldUtils类5. …
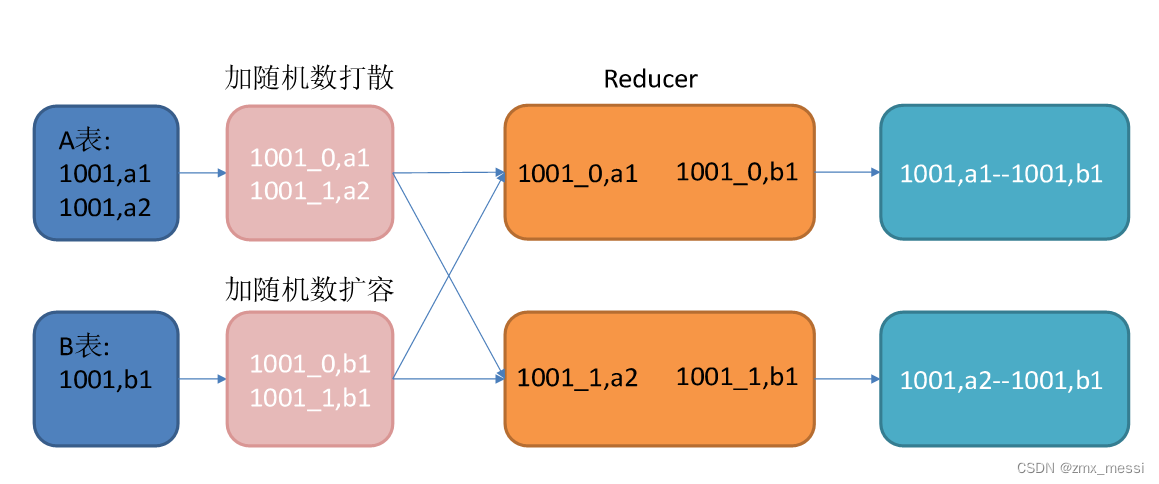
HQL优化之数据倾斜
group by导致倾斜 前文提到过,Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。…
【机器学习】5分钟掌握机器学习算法线上部署方法
5分钟掌握机器学习算法线上部署方法 1. 三种情况2. 如何转换PMML,并封装PMML2.1 什么是PMML2.2 PMML的使用方法范例3. 各个算法工具的工程实践4. 只用Linux的Shell来调度模型的实现方法5. 注意事项参考资料本文介绍业务模型的上线流程。首先在训练模型的工具上,一般三个模型训…

Hive05_DML 操作
1 DML 数据操作
1.1 数据导入
1.1.1 向表中装载数据(Load)
1)语法
hive> load data [local] inpath 数据的 path [overwrite] into table
student [partition (partcol1val1,…)];(1)load data:表示加载数据 &…

Hive04_DDL操作
Hive DDL操作
1 DDL 数据定义
1.1 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_nameproperty_value, ...)];[IF NOT EXISTS] :判断是否存在
[COMMENT database_c…
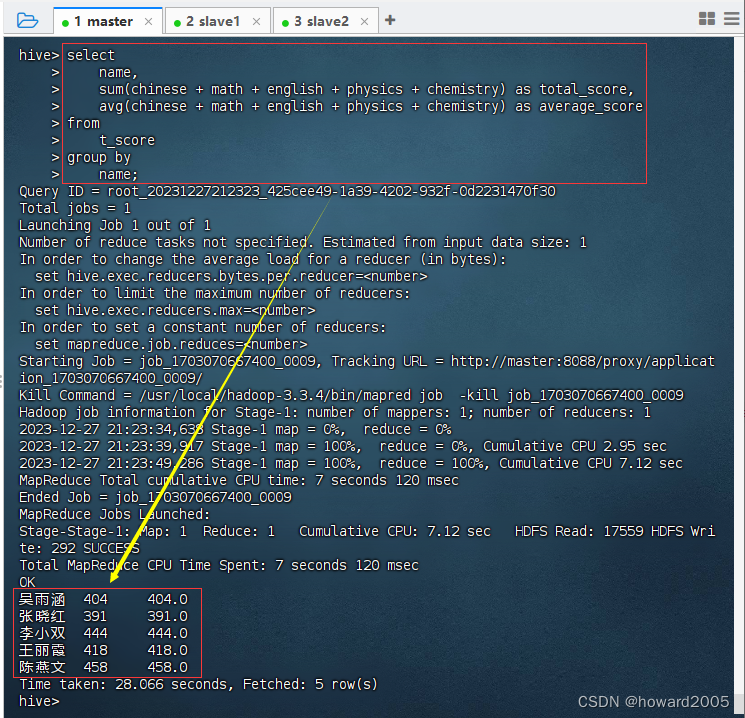
Hive实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、创建Hive表,加载HDFS数据文件…
hive的分区表和分桶表详解
分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中的表达式选择查询所需要的分区,这样的查询效率会提高很多。
静态分区表基本语法
创建分区表
create table dept_p…

hive 用户自定义函数udf,udaf,udtf
udf:一对一的关系 udtf:一对多的关系 udaf:多对一的关系
使用Java实现步骤
自定义编写UDF函数注意: 1.需要继承org.apache.hadoop.hive.ql.exec.UDF 2.需要实现evaluete函数 编写UDTF函数注意: 1.需要继承org.apache…
Hive SQL判断一个字符串中是否包含字串的N种方式及其效率
Hive SQL判断一个字符串中是否包含字串的N种方式及其效率 背景方案1:regexp_extract方案2:instr方案3:locate方案4:like方案5: rlike方案6:strpos 计算效率对比 背景
这是个常见需求,某个表tab中,需要判断某个string类型的字段中,哪些数据含…


hive企业级调优策略之CBO,谓词下推等优化
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
CBO优化
优化说明
CBO是指Cost based Optimizer,即基于计算成本的优化…

SparkSQL函数操作
1.5 SparkSQL函数操作
1.5.1 函数的定义
SQL中函数,其实说白了就是各大编程语言中的函数,或者方法,就是对某一特定功能的封装,通过它可以完成较为复杂的统计。这里的函数的学习,就基于Hive中的函数来学习。
1.5.2 函…
HiveServer2
HiveServer2
基本概念介绍
1、HiveServer2基本介绍
HiveServer2 (HS2) is a server interface that enables remote clients to execute queries against Hive and retrieve the results (a more detailed intro here). The current implementation, based on Thrift RPC, i…
hive企业级调优策略之小文件合并
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
优化说明
小文件合并优化,分为两个方面,分别是Map端输入的小…
Hive-分区与分桶详解(超详细)
文章目录 前言一、Hive分区1. 什么是分区2. 分区的优势3. 如何创建分区表4. 如何插入分区数据5. 如何查询分区数据6. 分区因素 二、Hive分桶1. 什么是分桶2. 分桶的优势3. 如何创建分桶表4. 如何插入分桶数据5. 如何查询分桶数据6. 分桶因素7. 分区和分桶的综合应用 总结 前言 …
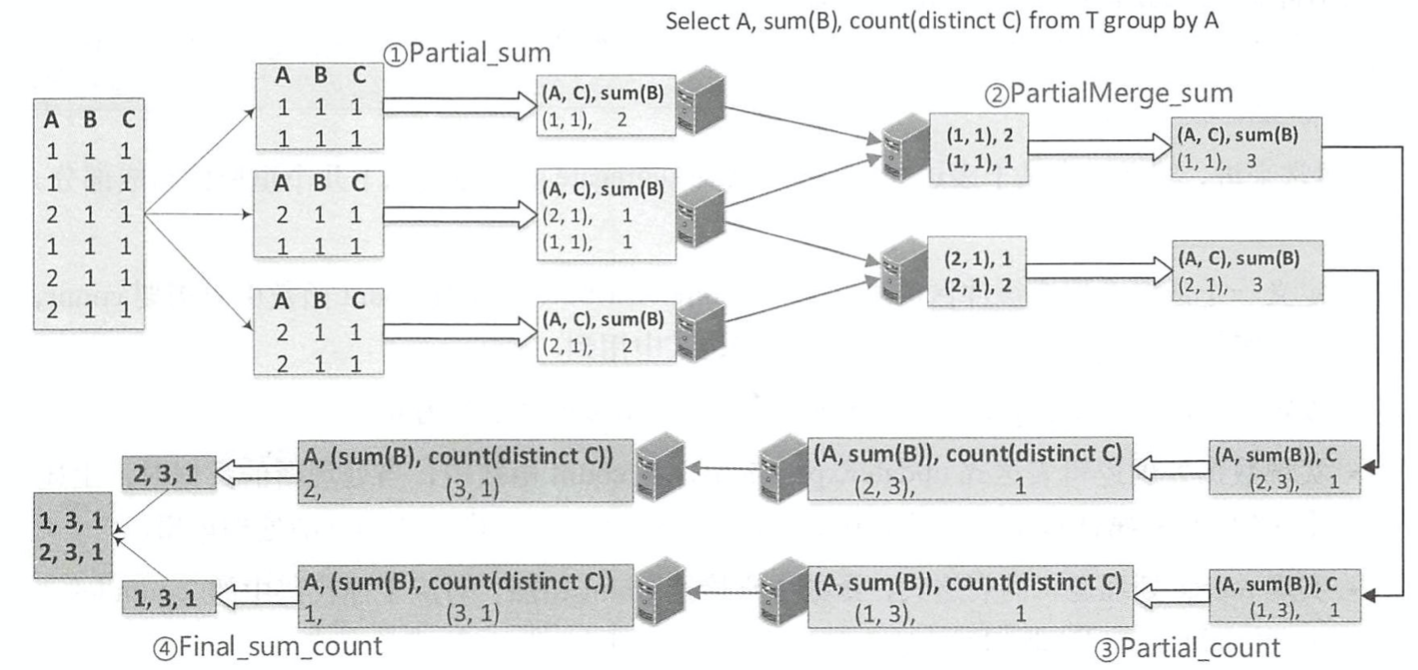
【Spark精讲】一文讲透SparkSQL聚合过程以及UDAF开发
SparkSQL聚合过程
这里的 Partial 方式表示聚合函数的模式,能够支持预先局部聚合,这方面的内容会在下一节详细介绍。 对应实例中的聚合语句,因为 count 函数支持 Partial 方式,因此调用的是 planAggregateWithoutDistinct 方法&a…
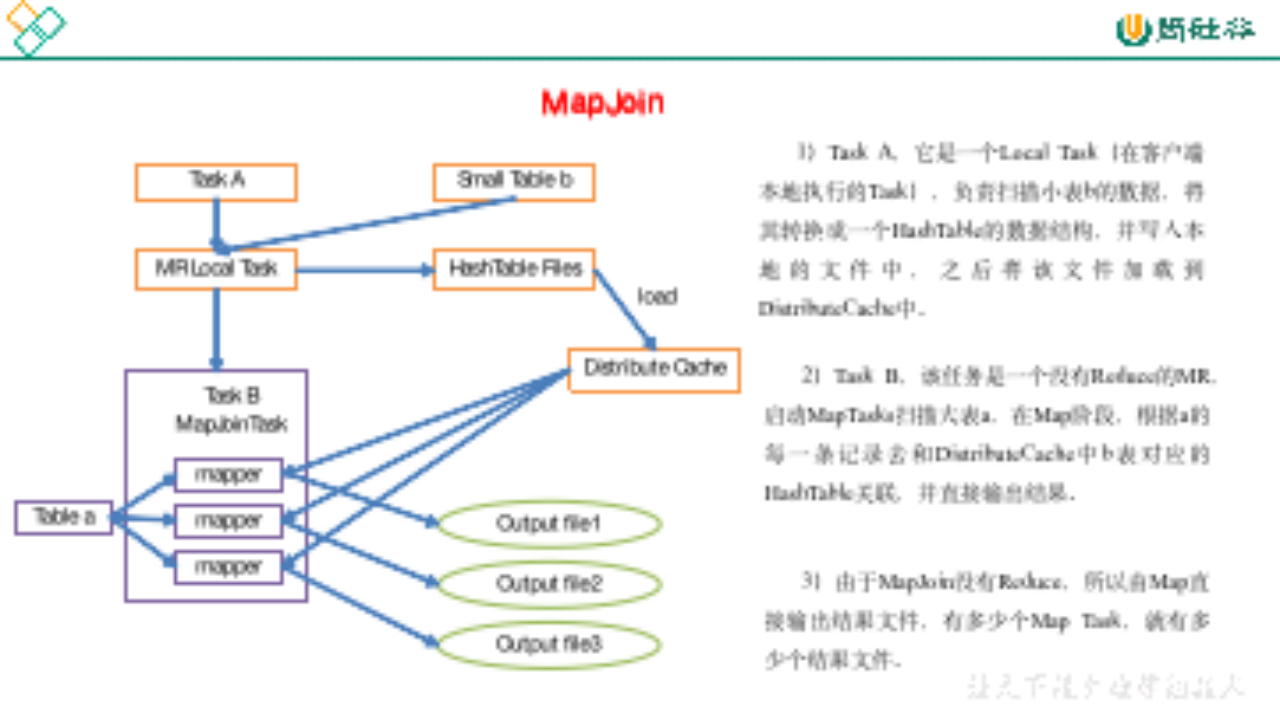
Hive生产调优介绍
1.Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。 在hive-default.xml…
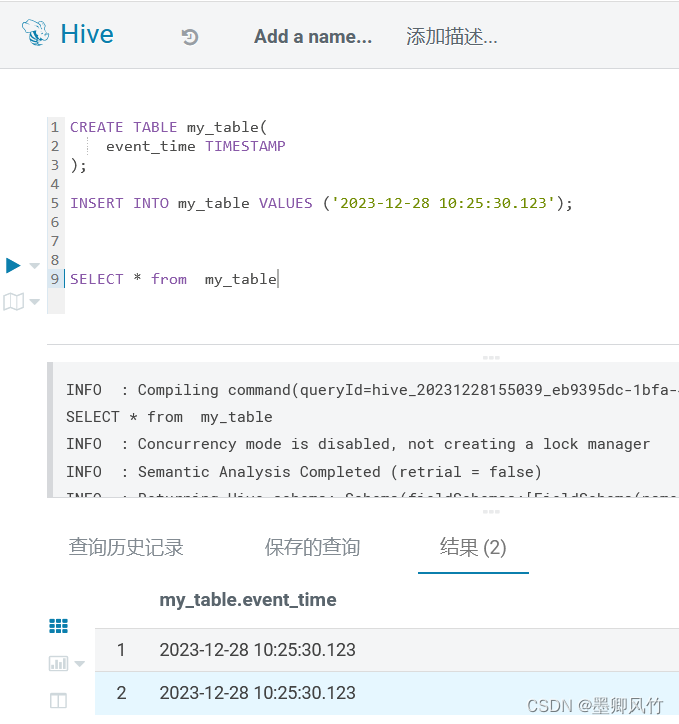
Hive中支持毫秒级别的时间精度
实际上,Hive 在较新的版本中已经支持毫秒级别的时间精度。你可以通过设置 hive.exec.default.serialization.format 和 mapred.output.value.format 属性为 1,启用 Hive 的时间精度为毫秒级。可以使用以下命令进行设置:
set hive.exec.defau…
Hive调优——合并小文件
目录 一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量 3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…
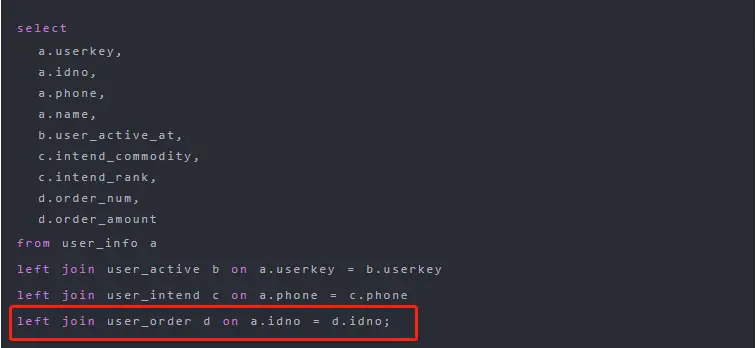
测试环境搭建整套大数据系统(六:搭建sqoop)
一:下载安装包 https://archive.apache.org/dist/sqoop/ 二:解压修改配置。
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt
cd /opt
mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.7修改环境变量
vi /etc/profile#SQOOP_HOME
export SQOOP_…
[Hive] Map类型在表中是如何存储的
在 Hive 中,Map 类型是指键值对的集合,其中键和值都可以是任意数据类型。
在 Hive 表中,Map 类型通常被存储为结构体或者键值对列表。
具体来说,在表中,Map 类型通常分为以下两种存储方式: 文章目录 结构…

大数据毕业设计选题推荐-收视点播数据分析-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…

大数据毕业设计选题推荐-家具公司运营数据分析平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…

大数据毕业设计选题推荐-农作物观测站综合监控平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
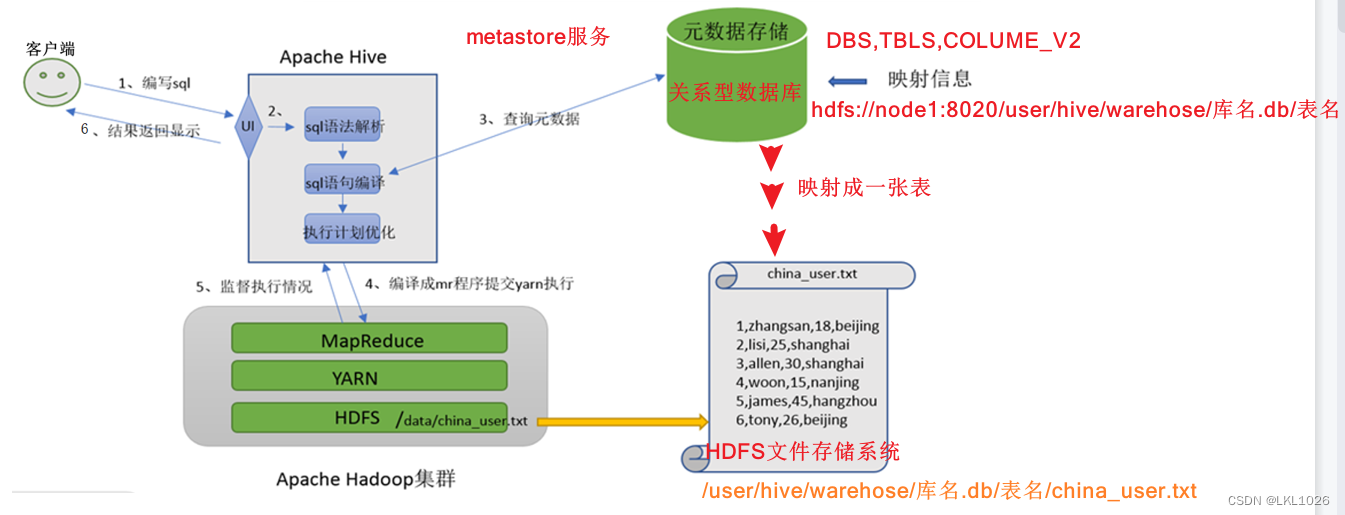
Hadoop架构、Hive相关知识点及Hive执行流程
Hadoop架构 Hadoop由三大部分组成:HDFS、MapReduce、yarn HDFS:负责数据的存储 其中包括: namenode:主节点,用来分配任务给从节点 secondarynamenode:副节点,辅助主节点 datanode:从节点&#x…
2023.11.12 hive中分区表,分桶表与区别概念
1.分区表 分区表的本质就是在分目录
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。…
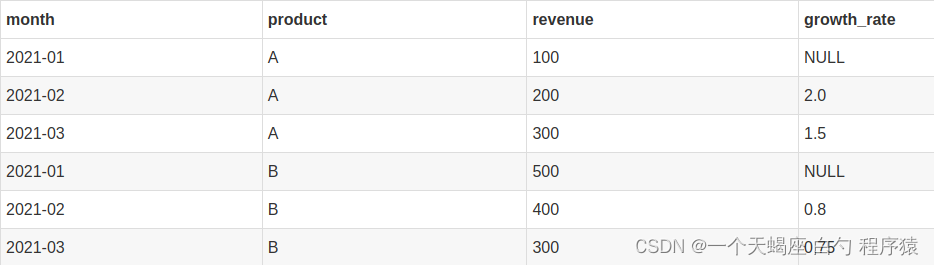
Hive学习(13)lag和lead函数取偏移量
hive里面lag函数
在数据处理和分析中,窗口函数是一种重要的技术,用于在数据集中执行聚合和分析操作。Hive作为一种大数据处理框架,也提供了窗口函数的支持。在Hive中,Lag函数是一种常用的窗口函数,可以用于计算前一行…
利用python将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
将excel文件转成txt文件,再将txt文件上传hdfs,最后传入hive中
注意的点 (1)先判断写入的txt文件是否存在,如果不存在就需要创建路径 (2)如果txt文件已经存在,那么先将对应的文件进行…
Hive实战处理(二十三)hive整合phoenix
背景: 业务表使用hbase存储,使用hive整合phoenix,使用sql语句进行数据查询 (如果可以的话使用网关API对外提供服务)统一接口调用,查询上线比较高效。
1、hive整合phoenix的原理 Hive支持使用HDFS之外的存储系统作为底…
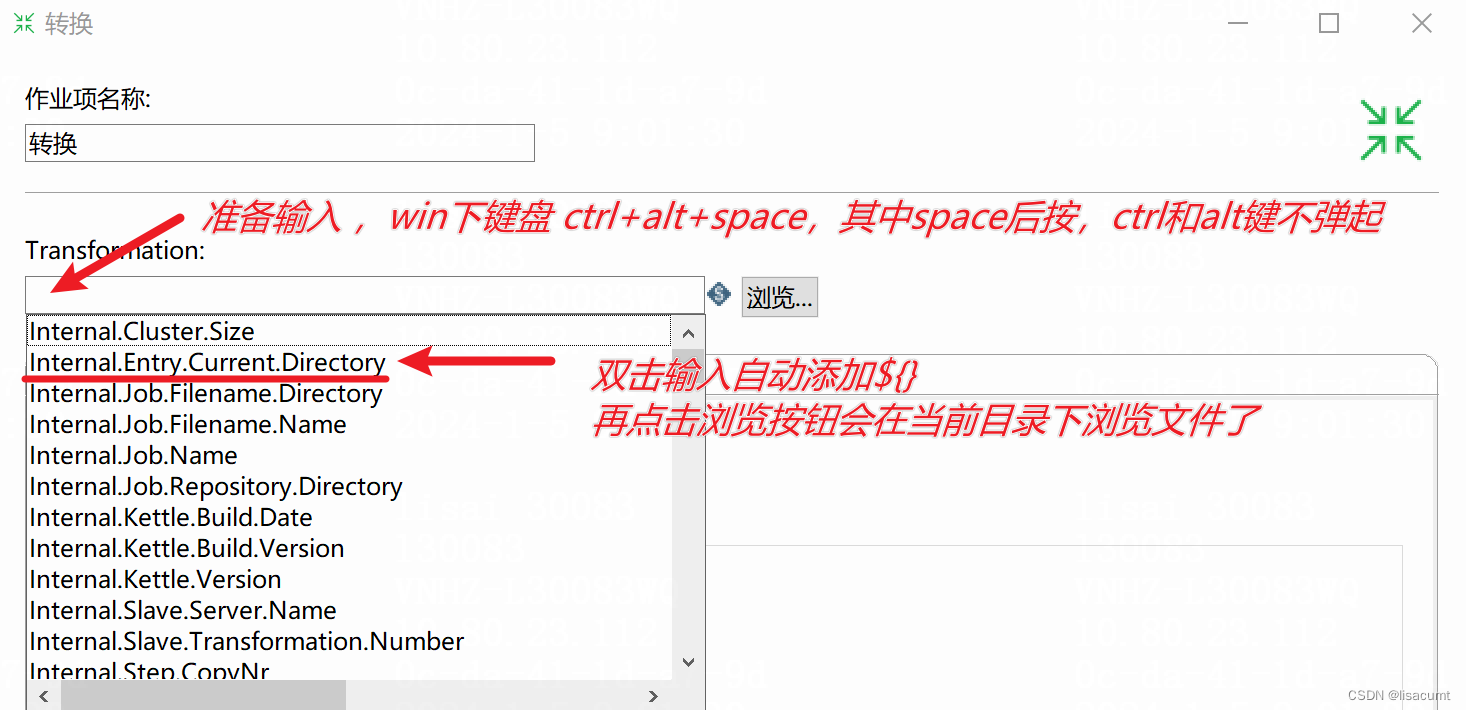
【kettle】pdi/data-integration 集成kerberos认证连接hdfs、hive或spark thriftserver
一、背景
kerberos认证是比较底层的认证,掌握好了用起来比较简单。 kettle完成kerberos认证后会存储认证信息在jvm中,之后直接连接hive就可以了无需提供额外的用户信息。
spark thriftserver本质就是通过hive jdbc协议连接并运行spark sql任务。
二、…

【数据仓库与联机分析处理】数据仓库工具Hive
目录
一、Hive简介
(一)什么是Hive
(二)优缺点
(三)Hive架构原理
(四)Hive 和数据库比较
二、MySQL的安装配置
三、Hive的安装配置
1、下载安装包
2、解压并改名
3、配置环…
Hive的时间处理函数from_unixtime和unix_timestamp
一、概述
hive时间处理函数from_unixtime和unix_timestamp的实现以及实例,从而方便后续的时间处理。
二、具体功能实现
1.unix_timestamp(date[, pattern]):
默认的时间格式是yyyy-MM-dd HH:mm:ss,如果日期不是这种格式无法识别ÿ…
Hive之set参数大全-1
A
控制是否允许在需要时按需加载用户定义函数(UDF)
hive.allow.udf.load.on.demand 是 Apache Hive 中的一个配置属性,用于控制是否允许在需要时按需加载用户定义函数(UDF)。
在 Hive 中,UDFs是用户编写…
maven的scop作用域依赖问题导致idea社区版报错
1. 错误:代码没改,卸了专业版后改用社区版出现以下报错
2024-01-08 16:34:29.374 ERROR [main] org.springframework.boot.SpringApplication.reportFailure:823 Application run failed java.lang.IllegalStateException: Error processing condition …

Spark on Hive及 Spark SQL的运行机制
Spark on Hive
集成原理 HiveServer2的主要作用: 接收SQL语句,进行语法检查;解析SQL语句;优化;将SQL转变成MapReduce程序,提交到Yarn集群上运行SparkSQL与Hive集成,实际上是替换掉HiveServer2。是SparkSQL…
Hive命令调优大全
– explain语法查询**
– explain解析执行计划
– 以下优化为hive层面优化,常开****
– 读取零拷贝 set hive.exec.orc.zerocopy=true; – 默认false – 关联优化器 set hive.optimize.correlation=true; – 默认false – fetch本地抓取 set hive.fetch.task.conversion=min…
【数据开发】HiveSQL 临时表分步执行(with, as )与时间函数(时间戳unix_timestamp)
1、分步执行(with…as…)
Hive SQL中的WITH…AS…语句可以用于分步执行,即将一个大的查询语句拆分成多个小的查询语句,每个小的查询语句都可以使用WITH…AS…语句定义一个临时表,然后在后面的查询语句中使用这些临时表…
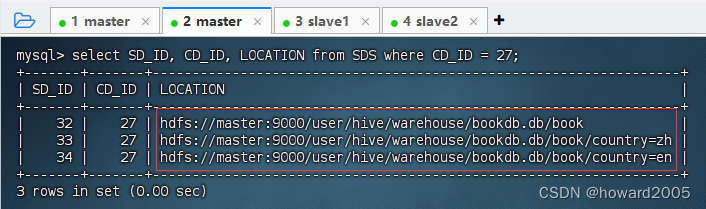
Hive分区表实战 - 单分区字段
文章目录 一、实战概述二、实战步骤(一)创建图书数据库(二)创建国别分区的图书表(三)在本地创建数据文件(四)按分区加载数据1、加载中文书籍数据到countrycn分区2、加载英文书籍数据…

熟悉 Hive 的基本操作
4、实验步骤
(一)创建一个内部表 stocks,字段分隔符为英文逗号,表结构下所示。 col_namedata_typeexchangestringsymbolstringymdstringprice_openfloatprice_highfloatprice_lowfloatprice_closefloatvolumeintprice_adj_closefloat创建内部表stocks:
create table if …
【数据库学习】hive
1,HIVE
Hadoop 的数据仓库处理工具,数据存储在Hadoop 兼容的文件系统(例如,Amazon S3、HDFS)中。hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中hive 设定的目录下。
1…
Hive调优一文打尽
一、调优概述
Hive 作为大数据领域常用的数据仓库组件,在平时设计和查询时要特别注意效率。影响 Hive 效率的几乎从不是数据量过大,而是数据倾斜、数据冗余、Job或I/O过多、MapReduce 分配不合理等等。对Hive 的调优既包含 Hive 的建表设计方面,对HiveHQL 语句本身的优化,…
2024.1.15 Spark 阶段原理,八股,面试题
目录
1. 简述什么是Spark?
2. 简述Spark的四大特点
3. 简述Spark比Mapreduce执行效率高的原因
4. 简述Spark on Yarn的两种部署模式的区别和特点
5. Spark底层工作原理是怎样的
6. RDD算子分成了哪几类,各自的特点是什么?
7. RDD的五大特性和五大特点
8. RDD中的重分…
Hive之set参数大全-8
指定LLAP(Low Latency Analytical Processing)的执行模式
hive.llap.execution.mode 是Apache Hive中的一个配置属性,用于指定LLAP(Low Latency Analytical Processing)的执行模式。该属性用于决定Hive查询是否使用LL…
Hive / Presto 行转列 列转行
Hive / Presto 行转列 列转行 行转列1、Hive:2、Presto: 列转行Hive1、split将order_ids拆分成数组,lateral view explode将数组炸裂开 Presto1、split将order_ids拆分成数组,cross join unnest将数组炸裂开2、炸裂 map 行转列
…
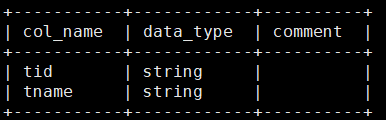
Hive---sqoop安装教程及sqoop操作
sqoop安装教程及sqoop操作 文章目录sqoop安装教程及sqoop操作上传安装包解压并更名添加jar包修改配置文件添加sqoop环境变量启动sqoop操作查看指定mysql服务器数据库中的表在hive中创建一个teacher表跟mysql的mysql50库中的teacher结构相同将mysql中mysql50库中的sc数据导出到h…
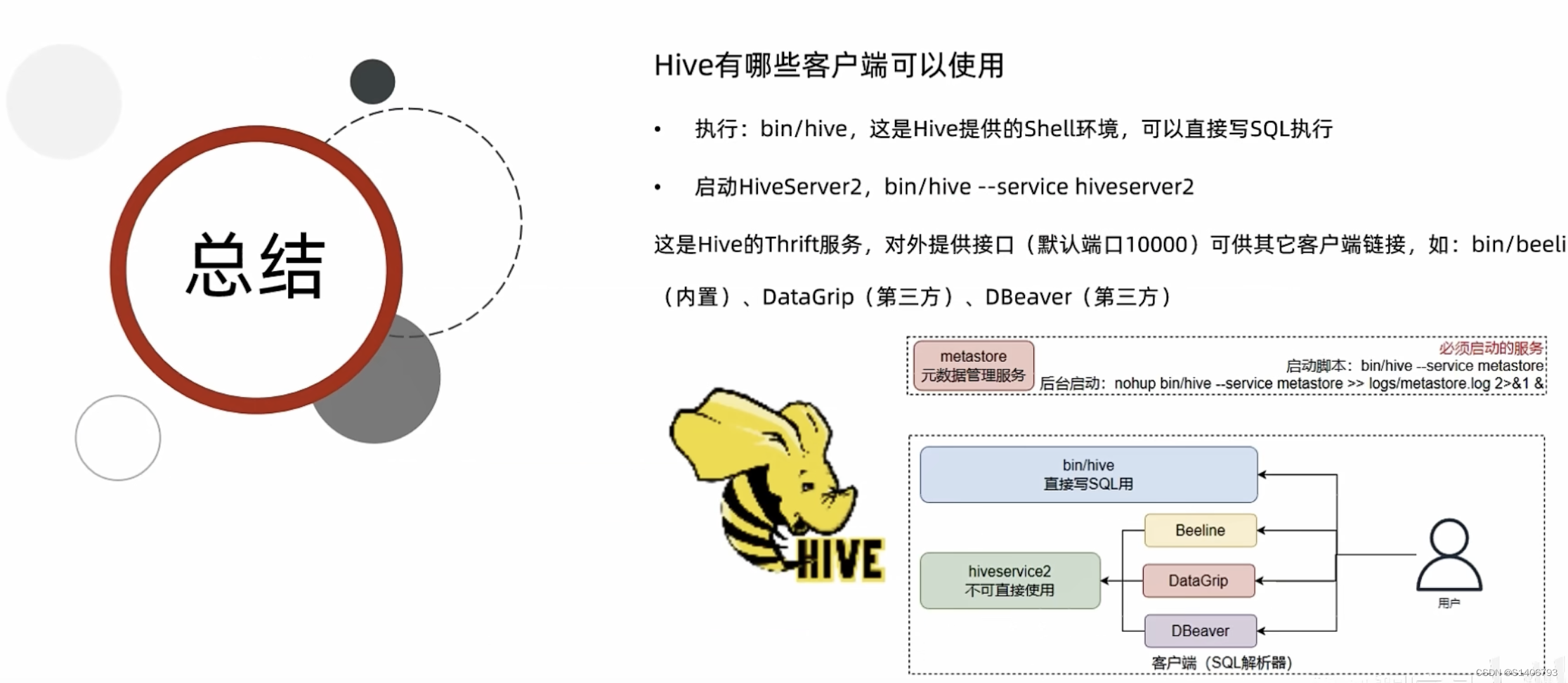
03-黑马程序员大数据开发:Apache Hive
一、 Apache Hive概述
1. 目的:了解什么是分布式SQL计算;了解什么是Apache Hive
2. 使用Hive处理数据的好处
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)底层执行MapReduc…
大数据分析组件Hive-集合数据结构
Hive的数据结构 前言一、array数组类型二、map键值对集合类型三、struct结构体类型 前言
Hive是一个基于Hadoop的数据仓库基础设施,用于处理大规模分布式数据集。它提供了一个类似于SQL的查询语言(称为HiveQL),允许用户以类似于关…

Hive中left join 中的where 和 on的区别
目录
一、知识点
二、测试验证
三、引申 一、知识点 left join中关于where和on条件的知识点:
多表left join 是会生成一张临时表。on后面: 一般是对left join 的右表进行条件过滤,会返回左表中的所有行,而右表中没有匹配上的数…
(三)hadoop之hive的搭建1
下载
访问官方网站https://hive.apache.org/
点击downloads 点击Download a release now! 点击https://dlcdn.apache.org/hive/ 选择最新的稳定版 复制最新的url 在linux执行下载命令
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz 2.解压…
2024-02-05(Hive)
1.Hive中抽样表数据
对表进行随机抽样是非常有必要的。
大数据体系下,在真正的企业环境中,很容易出现很大的表,比如体积达到TB级别的。
对这种表一个简单的SELECT * 都会非常的慢,哪怕LIMIT 10想要看10条数据,也会走…

【Hive】【Hadoop】工作中常操作的笔记-随时添加
文章目录 1、Hive 复制一个表:2、字段级操作3、hdfs 文件统计 1、Hive 复制一个表:
直接Copy文件
create table new_table like table_name;hdfs dfs -get /apps/hive/warehouse/ods.db/table_nameload data local inpath /路径 into table new_table;修复表:
m…
解决hive表新增的字段查询为空null问题
Hive分区表新增字段,查询时数据为NULL的解决方案 由于业务拓展,需要往hive分区表新增新的字段,hive版本为2点多。
于是利用
alter table table_name add columns (col_name string )新增字段,然后向已存在分区中插入数据&#x…
hive load data未正确读取到日期
1.源数据CSV文件日期字段值: 2.hive DDL语句:
CREATE EXTERNAL TABLE test.textfile_table1(id int COMMENT ????, name string COMMENT ??, gender string COMMENT ??, birthday date COMMENT ????,.......)
ROW FORMAT SERDE org.apache.…
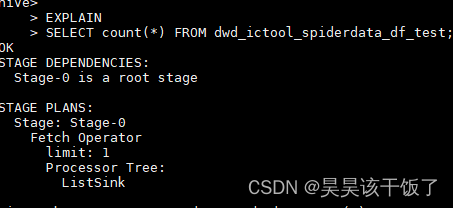
提升Hive效能:实用技巧与最佳实践
导读:帮助大家更有效地使用这个强大的数据仓库工具。
目录
优化Hive查询性能
分区(Partitioning)
代码示例
分桶(Bucketing)
代码示例
使用合适的文件格式
ORC文件格式
使用Vectorization
管理和优化表结构 …
hive中map相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释
hive官网函数大全地址: hive官网函数大全地址
Return TypeNameDescriptionmapmap(key1, value1, key2, value2, …)Creates a map with the given key/value pairs.arraymap_values(Map<K.V>)Returns an un…
Hadoop入门学习笔记——六、连接到Hive
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8
Hadoop入门学习笔记(汇总) 目录 六、连接到Hive6.1. 使用Hive的Shell客户端6.2. 使用Beel…
ClickHouse(19)ClickHouse集成Hive表引擎详细解析
文章目录 Hive集成表引擎创建表使用示例如何使用HDFS文件系统的本地缓存查询 ORC 输入格式的Hive 表在 Hive 中建表在 ClickHouse 中建表 查询 Parquest 输入格式的Hive 表在 Hive 中建表在 ClickHouse 中建表 查询文本输入格式的Hive表在Hive 中建表在 ClickHouse 中建表 资料…
Hive 最全面试题及答案(基础篇)
基本知识 hive元数据存储 Hive 元数据存储了关于表、分区、列、分桶等信息。 在生产环境中,通常会将 Hive 的元数据存储在外部的关系型数据库中,如 MySQL 或 PostgreSQL。这样可以提供更好的性能、可扩展性和容错性。通过配置 Hive 的元数据存储为 MySQL 或 PostgreSQL,可以…
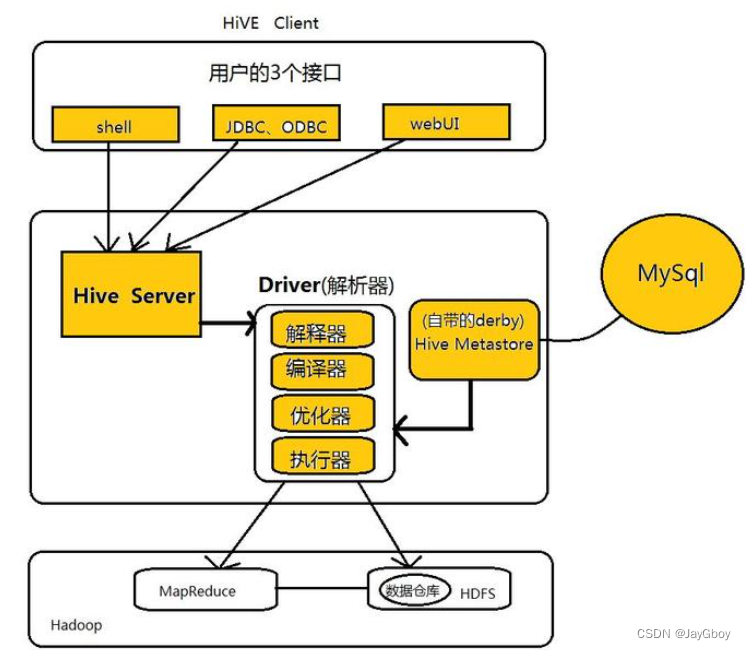
Hive入门,Hive是什么?
1.1Hive是什么?
Hive是一个开源的数据仓库工具,主要用于处理大规模数据集。它是建立在Hadoop生态系统之上的,利用Hadoop的分布式存储和计算能力来处理和分析数据。 Hive的本质是一个数据仓库基础设施,它提供了一种类似于SQL的查询…
hadoop hive spark flink 安装
下载地址
Index of /dist
ubuntu安装hadoop集群
准备
IP地址主机名称192.168.1.21node1192.168.1.22node2192.168.1.23node3 上传
hadoop-3.3.5.tar.gz、jdk-8u391-linux-x64.tar.gz
JDK环境
node1、node2、node3三个节点
解压
tar -zxvf jdk-8u391-linux-x64.tar.gz…
Hive和Spark生产集群搭建(spark on doris)
1.环境准备
1.1 版本选择
序号bigdata-001bigdata-002bigdata-003bigdata-004bigdata-005MySQL-8.0.31mysqlDataxDataxDataxDataxDataxDataxSpark-3.3.1SparkSparkSparkSparkSparkHive-3.1.3HiveHive
1.2 主要组件官网
hive官网: https://hive.apache.org/ hive…
Hive讲课笔记:内部表与外部表
文章目录 一、导言二、内部表1.1 什么是内部表1.1.1 内部表的定义1.1.2 内部表的关键特性 1.2 创建与操作内部表1.2.1 创建并查看数据库1.2.2 在park数据库里创建student表1.2.3 在student表插入一条记录1.2.4 通过HDFS WebUI查看数据库与表 三、外部表2.1 什么是外部表2.2 创建…
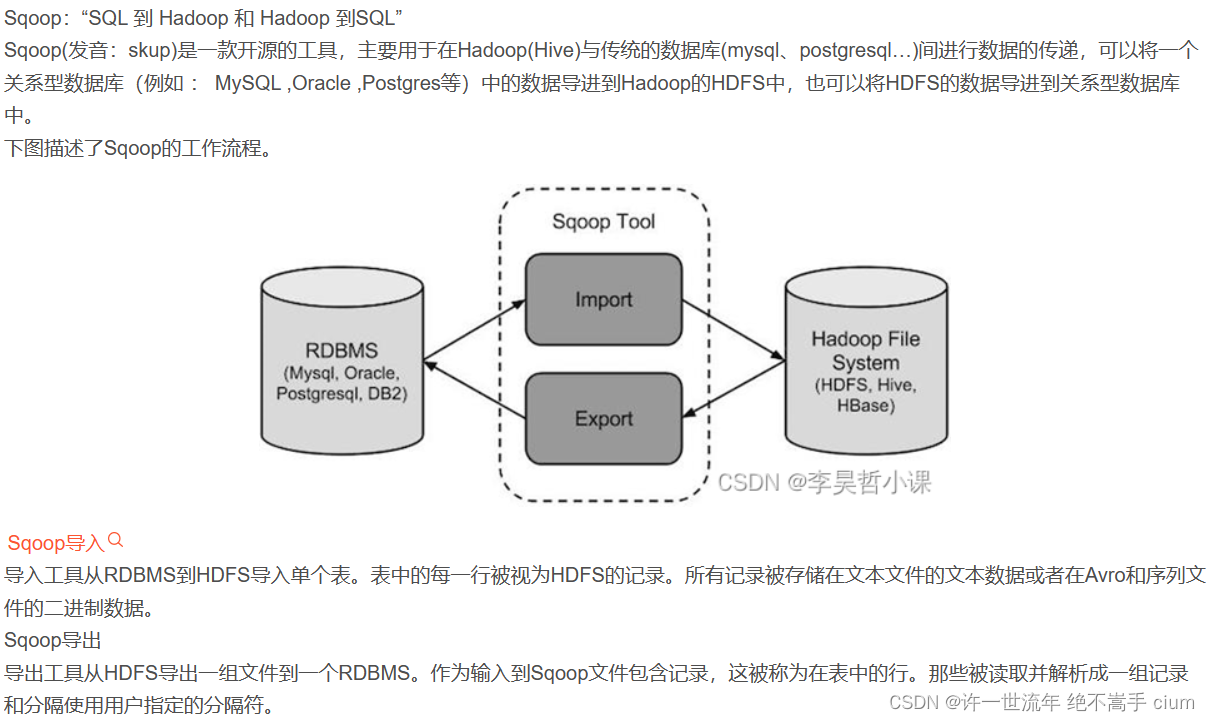
hql、数据仓库、sql调优、hive sql、python
SQL/HQL
HQL(Hibernate Query Language) 是面向对象的查询语言 SQL的操作对象是数据列、表等数据库数据 ; 而HQL操作的是类、实例、属性
#FROM
String hql "from com.demo.bean.User" "select * from user"
#WHERE
"form User u where u.id 1…

Hive03_数据类型
数据类型
1 案例实操
(1)假设某表有如下一行,我们用 JSON 格式来表示其数据结构。在 Hive 下访问的格式为
{"name": "wukong","friends": ["bajie" , "lili"] , //列表 Array, "c…
2024.1.1 hive_sql 题目练习,开窗,行列转换
重点知识: 在使用group by时,select之后的字段要么包含在聚合函数里,要么在group by 之后 进行行转列,行转列的核心就是使用concat_ws函数拼接(分隔符,内容), -- 以及collect_list函数进行收集,list不去重, set去重无序 列转行,核心就是使用炸裂函数把东…
CDH 6.3.2 升级Hive 2.3.9
升级背景
DolphinScheduler 3.1.1安装好后,其源码中集成的是Hive 2.1.1,版本太低,当在数据中心连接Hive数据源时报错,所以升级CDH自带的Hive为2.3.9版本。
一、准备工作
1、下载hive2.3.9并解压
下载地址:http://a…

云计算与大数据之间的羁绊(期末不挂科版):云计算 | 大数据 | Hadoop | HDFS | MapReduce | Hive | Spark
文章目录 前言:一、云计算1.1 云计算的基本思想1.2 云计算概述——什么是云计算?1.3 云计算的基本特征1.4 云计算的部署模式1.5 云服务1.6 云计算的关键技术——虚拟化技术1.6.1 虚拟化的好处1.6.2 虚拟化技术的应用——12306使用阿里云避免了高峰期的崩…

hive数据倾斜(超详细)
说到hive的数据倾斜,可能有的小伙伴还不了解什么是数据倾斜,所以咱们这一次就从hive数据倾斜的表现、hive数据倾斜发生的原因、hive数据倾斜的解决方案这三个方面来聊一聊hive的数据倾斜 1、hive数据倾斜的表现
我们都知道hive的底层其实是mr࿰…
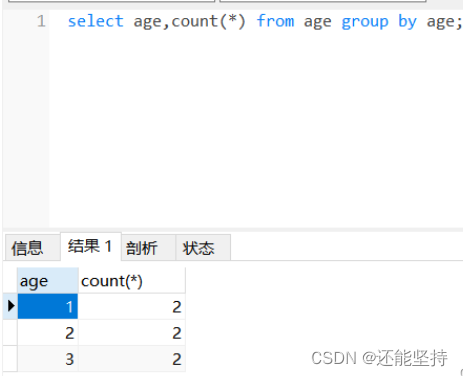
SQL:数据去重的三种方法
1、使用distinct去重
distinct用来查询不重复记录的条数,用count(distinct id)来返回不重复字段的条数。用法注意:
distinct【查询字段】,必须放在要查询字段的开头,即放在第一个参数;只能在SELECT 语句中使用&#…
Hive 连接及使用
1. 连接
有三种方式连接 hive:
cli:直接输入 bin/hive 就可以进入 clihiveserver2、beelinewebui
1.1 hiveserver2/beeline
1、开启 hiveserver2 服务
// 前台运行,当 beeline 输入命令时,服务端会返回 OK
[roothadoop1 bin]…
基于Hive的河北新冠确诊人数分析系统的设计与实现
项目描述
临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…
Hive行列转换应用:多行转多列、 多行转单列、多列转多行、单列转多行
Hive行列转换应用 文章目录Hive行列转换应用多行转多列多行转单列多列转多行单列转多行多行转多列
通过条件转换CASE WHEN函数实现多行转多列,即取出对应的数据放在对应的位置。例1:
写法一:
SELECTid,CASEWHEN id < 2 THEN aWHEN id …
Hive JSON数据处理:get_json_objec、json_tuple、用JSON Serde加载数据
Hive JSON数据处理 文章目录Hive JSON数据处理将JSON保存为字符串,用JSON函数处理get_json_objectjson_tuple用JSON Serde加载数据将JSON保存为字符串,用JSON函数处理
使用get_json_object、json_tuple实现将JSON数据中每个字段独立解析出来,…
关于Java连接Hive,Spark等服务的Kerberos工具类封装
关于Java连接Hive,Spark等服务的Kerberos工具类封装
idea连接服务器的hive等相关服务的kerberos认证注意事项
idea 本地配置,连接服务器;进行kerberos认证,连接hive、HDFS、Spark等服务注意事项:
本地idea连接Hadoo…
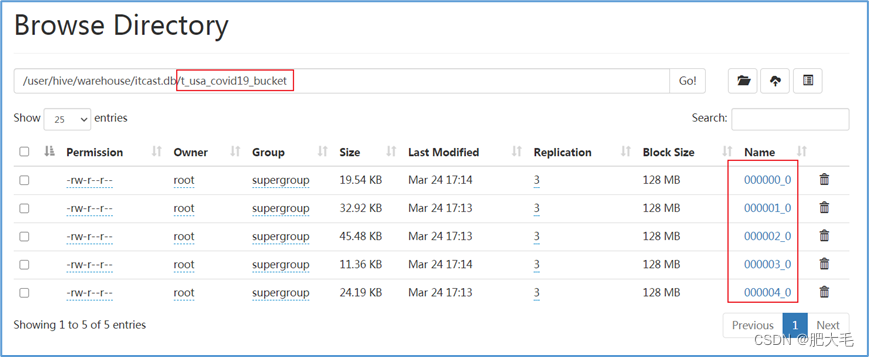
Hive---DDL
文章目录1.hive数据类型1.1 原生数据类型1.2 复杂数据类型1.3 数据类型转换2.Hive读写机制2.1 SerDe2.2 hive读取文件机制2.3 hive写文件机制2.4 SerDe语法3.Hive存储路径3.1 指定存储路径4.Hive建表高阶4.1 hive内部表、外部表4.2 分区表4.2.1 静态分区4.2.2 动态分区4.2.3 分…

如何借力Alluxio推动大数据产品性能提升与成本优化?
内容简介
随着数字化不断发展,各行各业数据呈现海量增长的趋势。存算分离将存储系统和计算框架拆分为独立的模块,Alluxio作为如今主流云数据编排软件之一,为计算型应用(如 Apache Spark、Presto)和存储系统࿰…
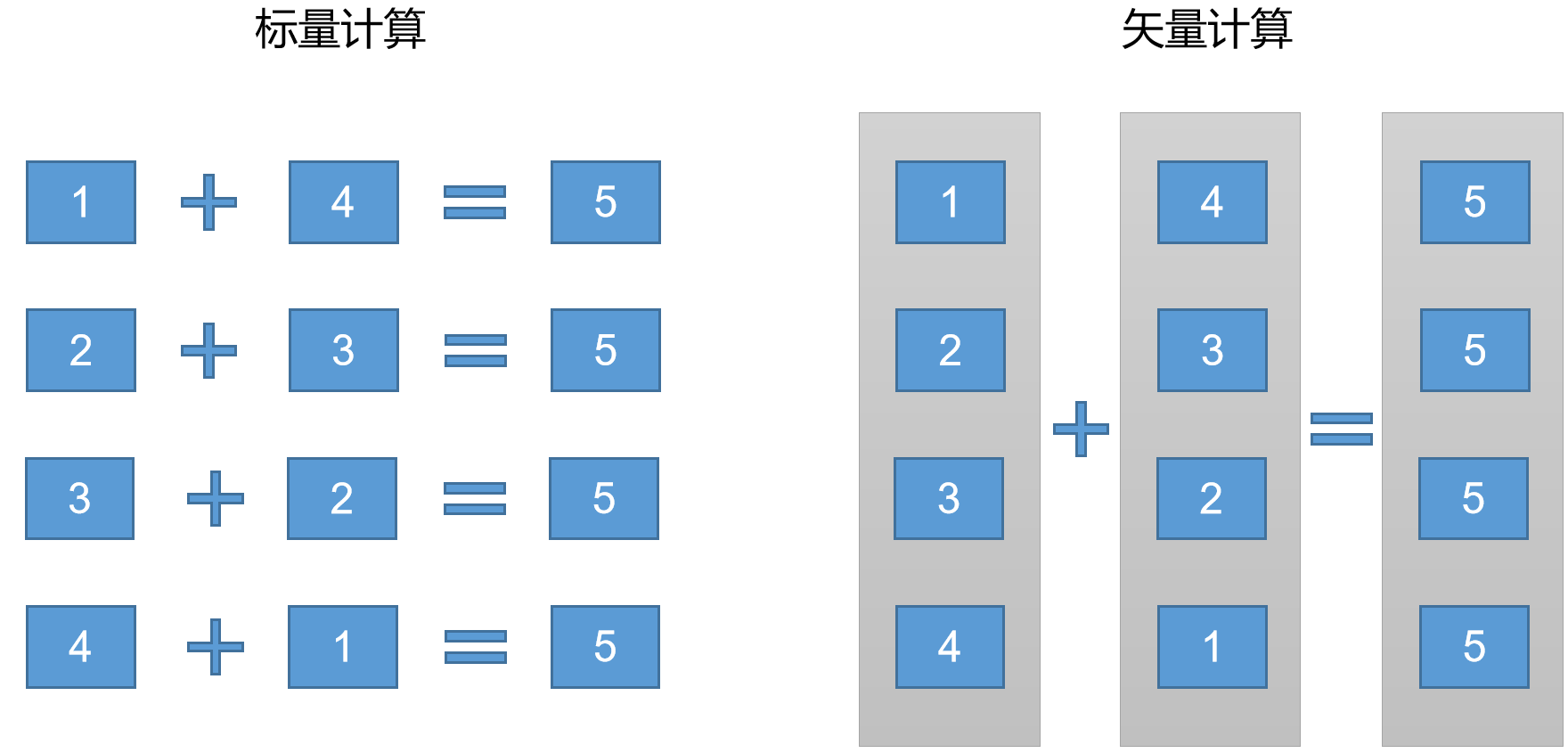
大数据框架之Hive:第12章 企业级调优
第12章 企业级调优
12.1 计算资源配置
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
12.1.1 Yarn资源配置
1)Yarn配置说明
需要调整的Yarn参数均与CPU、内存等资源有关,核心配置参数如下
(1)yarn.nodem…
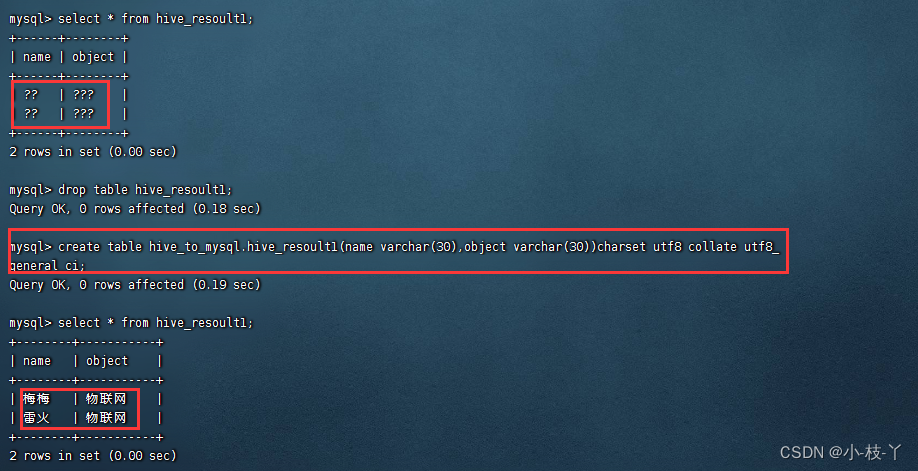
sqoop将hive中的数据导入MySQL不能正常显示中文——已解决
问题: 原因:
结果查看 问题:
在做练习利用sqoop工具将hive中的表导入到MySQL之后,在MySQL查看中文部分不能正常显示 输入sqoop执行语句 sqoop export -connect "jdbc:mysql://HadoopMaster:3306/hive_to_mysql?useUnicode…
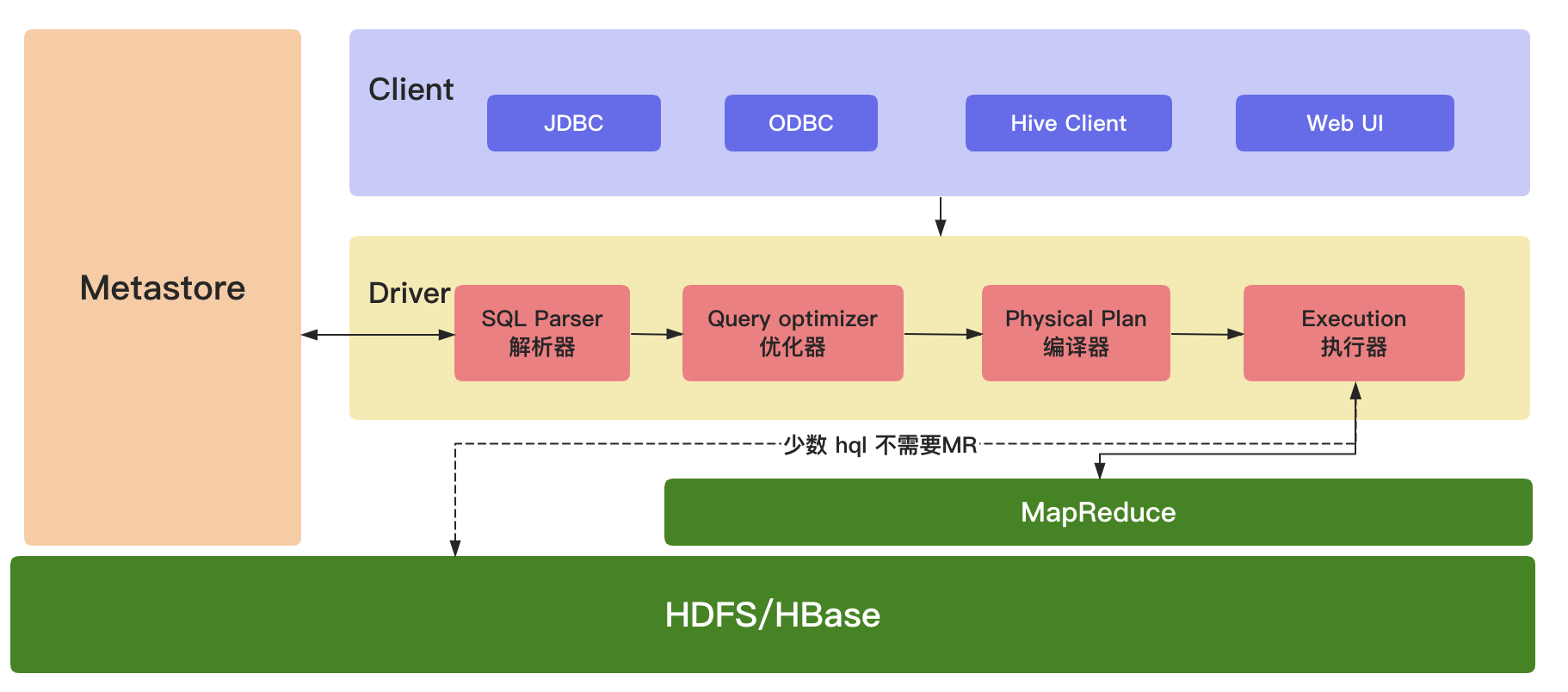
【Hive基础】-- hive sql 的执行原理和流程
Hive SQL是一种高级语言,用于查询存储在 Hadoop 分布式文件系统(HDFS)的大型数据集。它为分析数据提供了一个类似于 SQL 的接口,并支持 Hadoop 生态系统的 MapReduce 处理框架。本质:将 Hive SQL 转化成 MapReduce 程序。 可以用一张图描述 Hive SQL的执行原理和执行流程,…
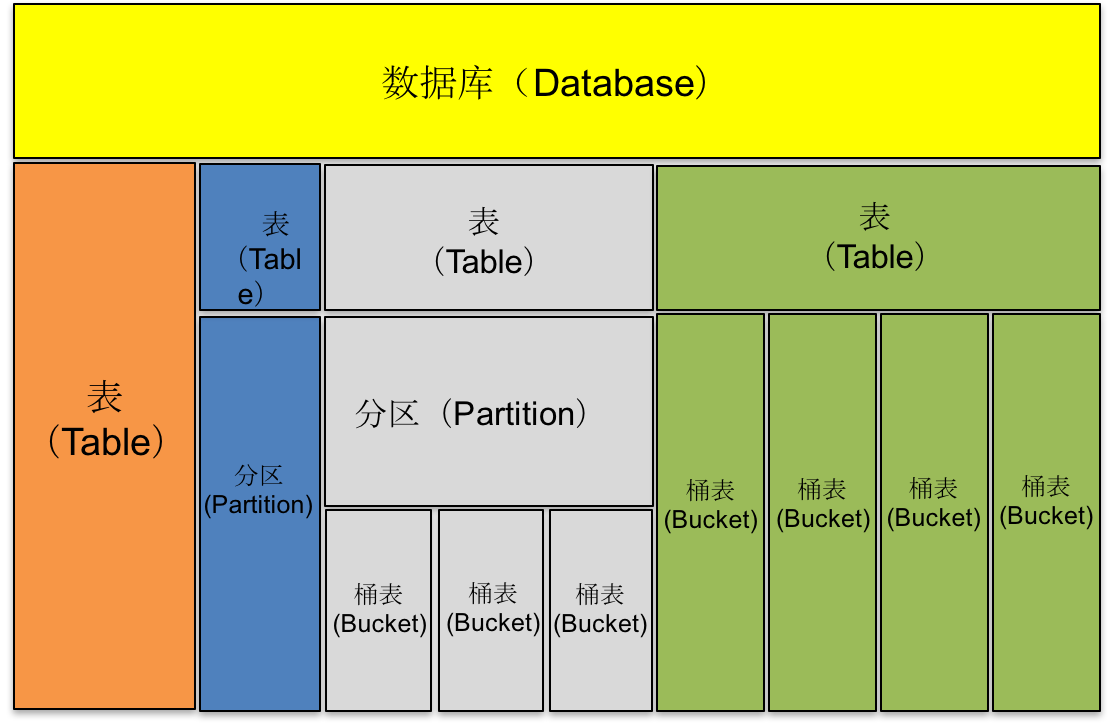
Hive数据仓库简介
文章目录Hive数据仓库简介一、数据仓库简介1. 什么是数据仓库2. 数据仓库的结构2.1 数据源2.2 数据存储与管理2.3 OLAP服务器2.4 前端工具3. 数据仓库的数据模型3.1 星状模型3.2 雪花模型二、Hive简介1. 什么是Hive2. Hive的发展历程3. Hive的本质4. Hive的优缺点4.1 优点4.2 缺…
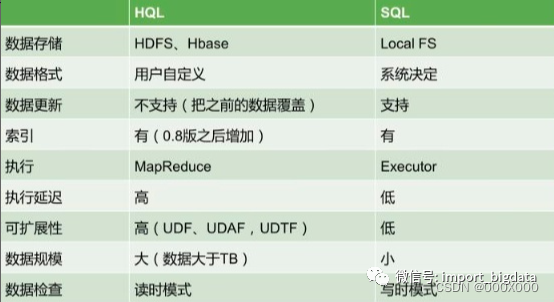
2023-Hive调优最全指南
本文基本涵盖以下内容: 一、基于Hadoop的数据仓库Hive基础知识 二、HiveSQL语法 三、Hive性能优化 四、Hive性能优化之数据倾斜专题 五、HiveSQL优化十二板斧 六、Hive面试题(一) 七、Hive/Hadoop高频面试点集合(二) 01-基于Hadoop的数据仓库Hive基础知识
Hi…
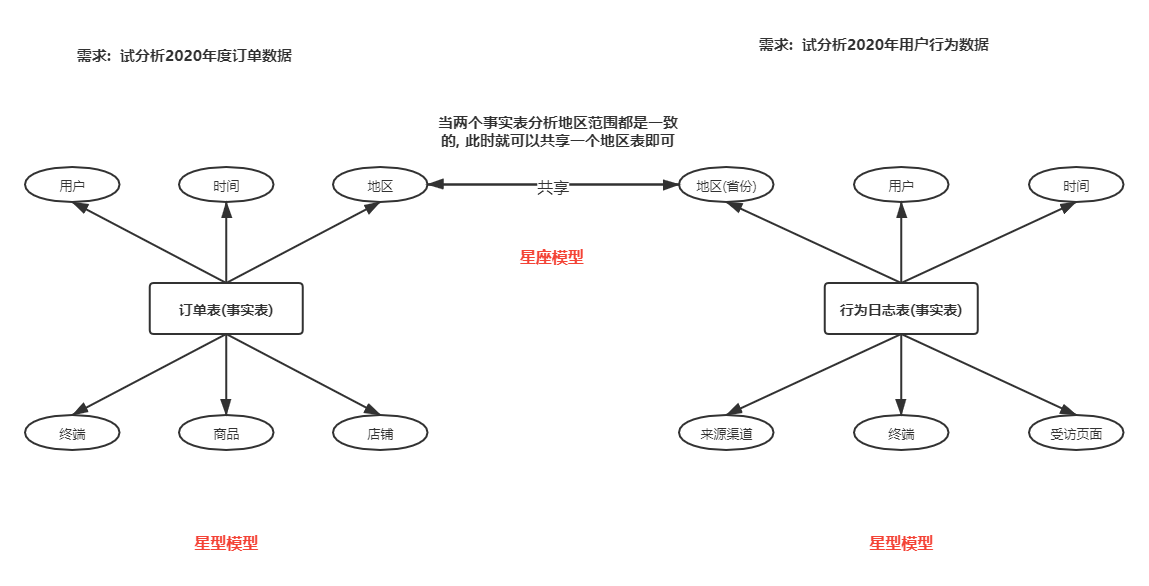
黑马在线教育数仓实战1
1. 教育项目的架构说明
项目的架构: 基于cloudera manager大数据统一管理平台, 在此平台之上构建大数据相关的软件(zookeeper,HDFS,YARN,HIVE,OOZIE,SQOOP,HUE...), 除此以外, 还使用FINEBI实现数据报表展示
各个软件相关作用: zookeeper: 集群管理工具, 主要服务于…
【Hive基础】-- Hive Catalog
目录
1.介绍
1.1 什么是 Hive Catalog
1.2 Hive Catalog 的作用
2.Hive Catalog 的基础知识
2.1 Hive Catalog 的类型
大数据技术架构(组件)——Hive:环境准备1
1.0.1、环境准备1.0.1.0、maven安装1.0.1.0.1、下载软件包1.0.1.0.2、配置环境变量1.0.1.0.3、调整maven仓库打开$MAVEN_HOME/conf/settings.xml文件,调整maven仓库地址以及镜像地址<settings xmIns"http://maven.apache.org/SETTINGS/1.0.0"xmIns:xsi…
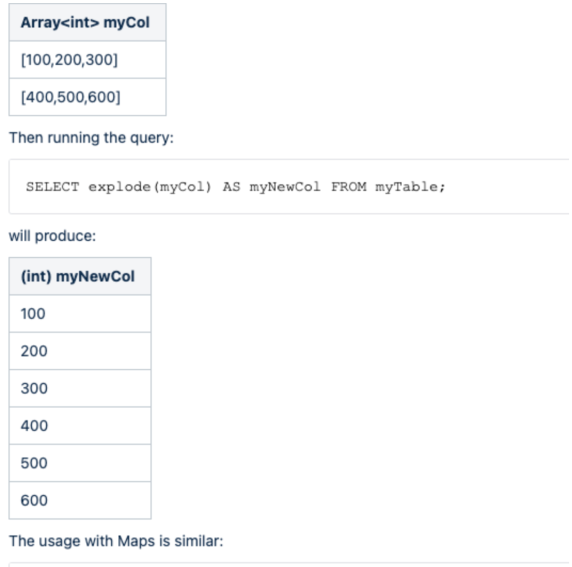
大数据技术架构(组件)8——Hive:Function Cases UDF/UDTF/UDAF 1
1.3、Function Cases1.3.1、窗口函数row_number:使用频率 ★★★★★rank :使用频率 ★★★★dense_rank:使用频率 ★★★★rank/dense_rank/row_number对比first_value:使用频率 ★★★last_value:使用频率 ★lead&am…
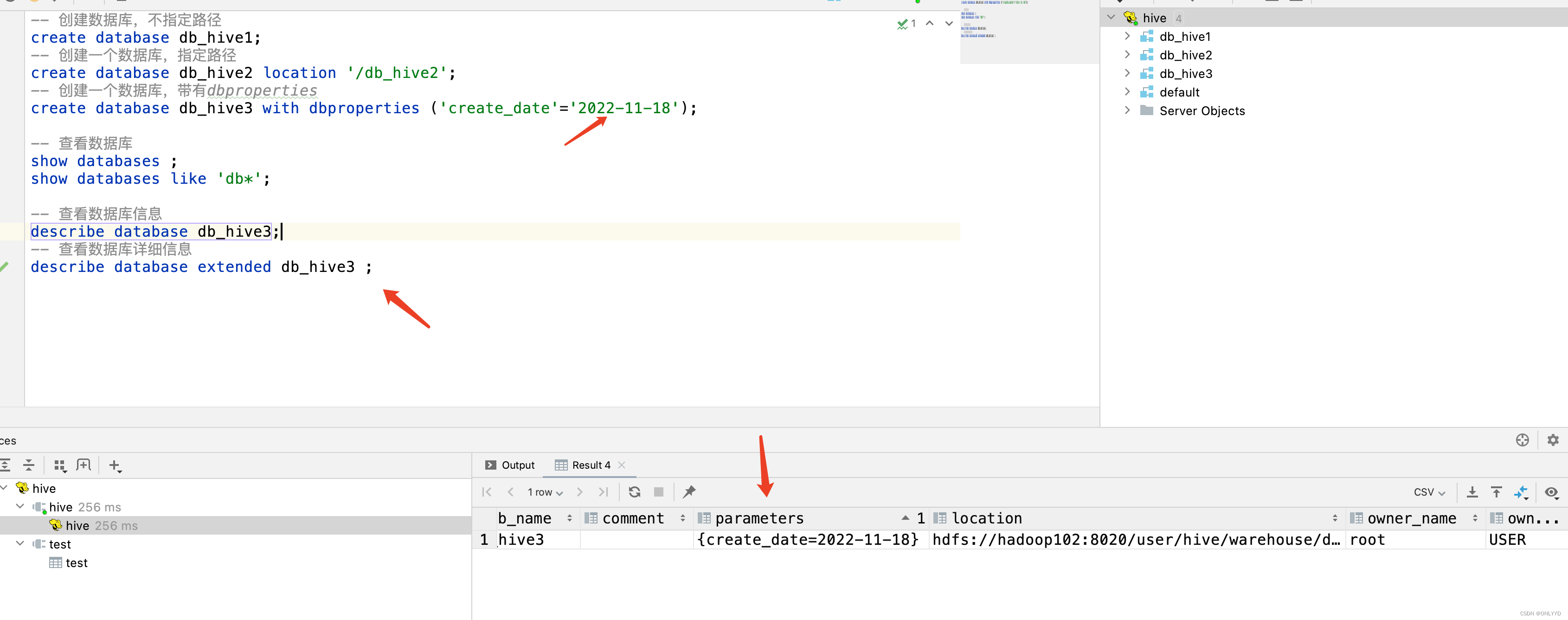

hive的基本操作语句
背景:记录一下hive创建数据库,建表,添加数据,创建分区等的语句吧,省得总百度,😄
第一步:hive的建库语句
create database pdata_dynamic;查看是否创建成功了 show databases;显示如…
apache hive release notes
hive release notes位置
https://github.com/apache/hive/blob/master/RELEASE_NOTES.txt
如何查看不同版本的release note
HiveSQL 工作实战总结
记录一些工作中有意思的统计指标,做过一些简化方便大家阅读,记录如有错误,欢迎在评论区提问讨论~
问题类型
连续问题 两种思路第一种:日期减去一列数字得出日期相同,主要是通过row_number窗口函数第二种:…
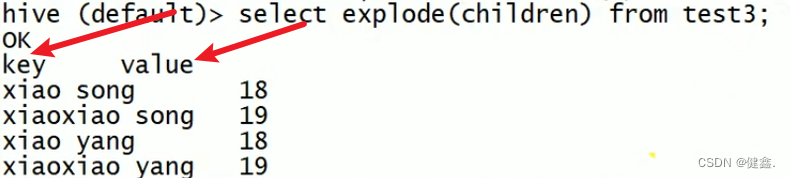

Hive SQL语言:DDL建库、建表
Hive SQL语言:DDL建库、建表
Hive数据模型总览 Hive SQL之数据库与建库
SQL中DDL语法的作用
⚫ 数据定义语言(Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言ÿ…

必须要知道的hive调优知识(上)
Hive数据倾斜以及解决方案
1、什么是数据倾斜
数据倾斜主要表现在,map/reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其…


实践数据湖iceberg 第四十一课 iceberg的实时性-业界的checkpoint配置
系列文章目录
实践数据湖iceberg 第一课 入门 实践数据湖iceberg 第二课 iceberg基于hadoop的底层数据格式 实践数据湖iceberg 第三课 在sqlclient中,以sql方式从kafka读数据到iceberg 实践数据湖iceberg 第四课 在sqlclient中,以sql方式从kafka读数据到…
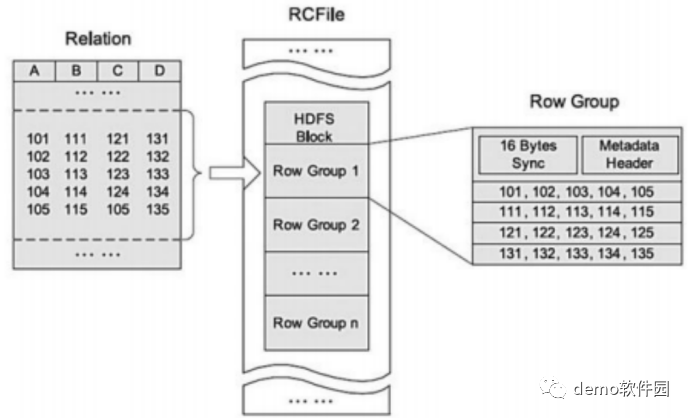
锁屏面试题百日百刷-Hive篇(八)
锁屏面试题百日百刷,每个工作日坚持更新面试题。锁屏面试题app、小程序现已上线,官网地址:https://www.demosoftware.cn。已收录了每日更新的面试题的所有内容,还包含特色的解锁屏幕复习面试题、每日编程题目邮件推送等功能。让你…
Hive---数据导出
数据导出 文章目录数据导出Insert 导出将查询的结果导出到本地将查询的结果格式化导出到本地将查询的结果导出到 HDFS 上Hadoop 命令导出到本地Hive Shell 命令导出Export 导出到 HDFS 上sqoop导出Insert 导出
表为student
将查询的结果导出到本地
insert overwrite local d…
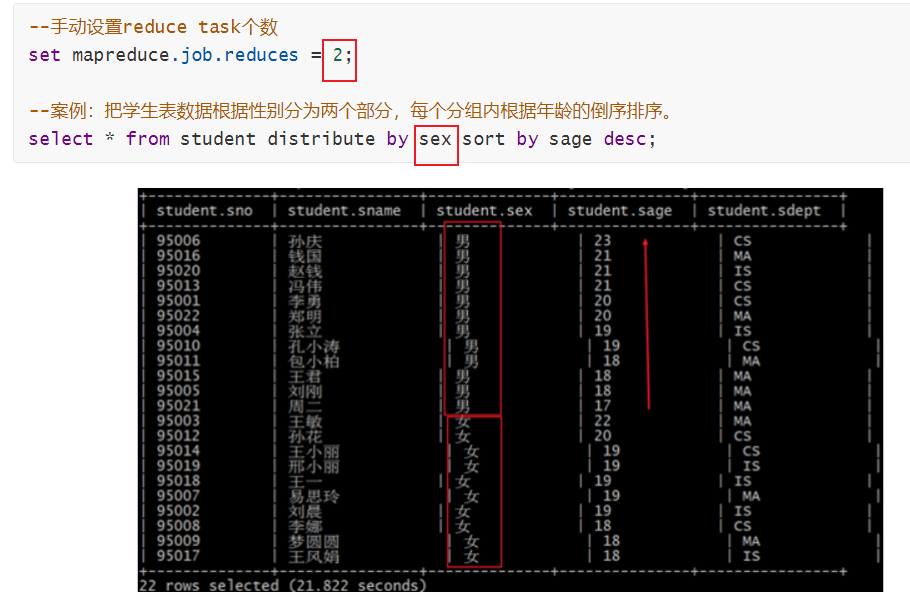
Hive语言2(大数据的核心:窗口函数)
1、Common Table Expressions(CTE)> 重点 公用表达式(CTE)是一个临时结果集,该结果集是从WITH子句中指定的简单查询派生而来的,该查询紧接在SELECT或INSERT关键字之前。 2.inner join(内连接)、left joi…
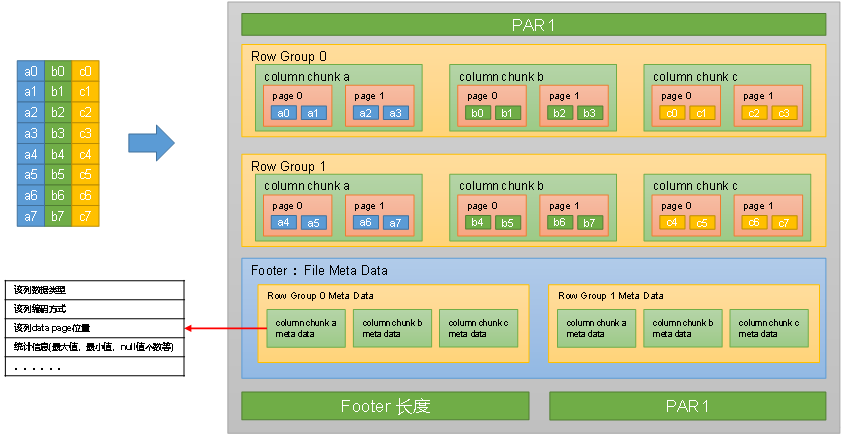
大数据框架之Hive:第11章 文件格式和压缩
第11章 文件格式和压缩
11.1 Hadoop压缩概述
压缩格式算法文件扩展名是否可切分DEFLATEDEFLATE.deflate否GzipDEFLATE.gz否bzip2bzip2.bz2是LZOLZO.lzo是SnappySnappy.snappy否
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示&#…
Sqoop ---- 简介、原理、安装
Sqoop ---- 简介、原理、安装 1. Sqoop 简介2. Sqoop 原理3. Sqoop 安装1. 下载并解压2. 修改配置文件3. 拷贝JDBC驱动4. 验证Sqoop5. 测试Sqoop是否能够成功连接数据库 1. Sqoop 简介
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgre…
大数据技术之Hive SQL题库-中级
第1章 环境准备1.1 用户信息表1)表结构user_id(用户id)gender(性别)birthday(生日)101男1990-01-01102女1991-02-01103女1992-03-01104男1993-04-012)建表语句hive> DROP TABLE IF EXISTS user_info;create table user_info(user_id string COMMENT 用…
Java(113):Java通过jdbc连接hive
Java(113):Java通过jdbc连接hive
maven引用: <dependency><groupId>org.appache.hive</groupId><artifactId>hive-jdbc-uber</artifactId><version>2.6.5.0-292</version><scope>system</scope><systemP…
华为MRS_HADOOP集群 beeline使用操作
背景
由于项目测试需要,计划在华为hadoop集群hive上创建大量表,并且每表植入10w数据,之前分享过如何快速构造hive大表,感兴趣的可以去找一下。本次是想要快速构造多表并载入一些数据。 因为之前同事在构造相关测试数据时由于创建…
JDK1.8下多线程使用JDBC加载ClickHouse和hive驱动问题
JDK1.8下多线程使用JDBC加载CH和hive驱动问题 文章目录JDK1.8下多线程使用JDBC加载CH和hive驱动问题现象重现DriverManager加载驱动过程分析猜想实验1实验2实验3小结解决方案JVM深度分析在线程池里并行加载ClickHouse和Hive驱动时,发现程序无反应。通过日志发现均卡…
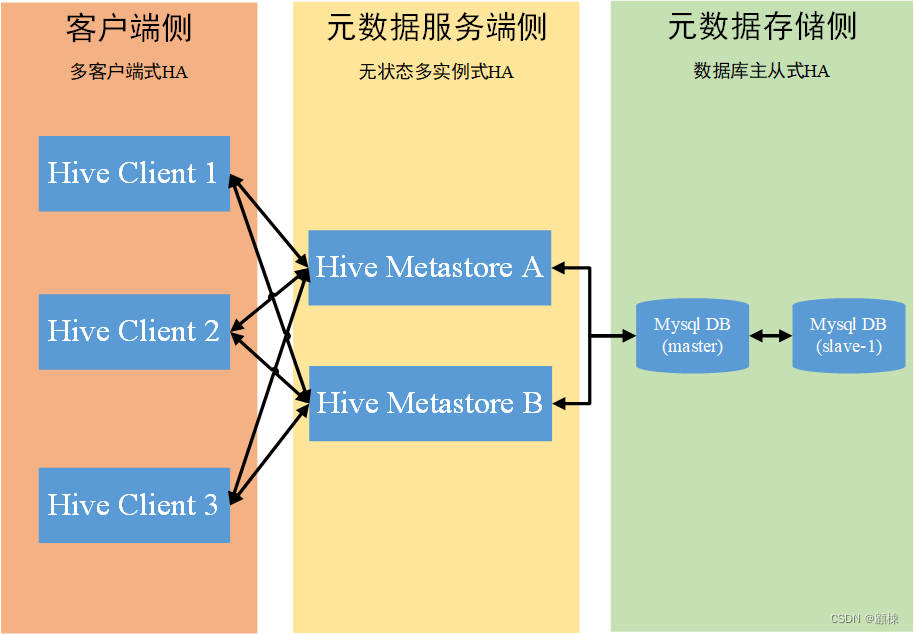
【Hive实战】探索Hive 2.X以及更早版本的MetaStore
探索Hive 2.X以及更早版本的MetaStore 文章目录 探索Hive 2.X以及更早版本的MetaStore概述配置元数据服务和元数据存储库基础配置参数其他配置参数默认配置配置元服务数据库使用内嵌模式的Derby库使用远程数据存储库 配置元数据服务本地/内嵌服务配置远程服务配置 元数据服务配…

从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
从Hive源码解读大数据开发为什么可以脱离SQL、Java、Scala
前言
【本文适合有一定计算机基础/半年工作经验的读者食用。立个Flg,愿天下不再有肤浅的SQL Boy】
谈到大数据开发,占据绝大多数人口的就是SQL Boy,不接受反驳,毕竟大…
数据湖Iceberg-Hive集成Iceberg(3)
文章目录 Hive集成Iceberg环境准备Hive与Iceberg的版本对应关系如下上传jar包,拷贝到Hive的auxlib目录中修改hive-site.xml,添加配置项启动 HMS 服务启动 Hadoop 创建和管理 Catalog默认使用 HiveCatalog指定 Catalog 类型使用 HiveCatalog使用 HadoopCa…
Hive ---- DML(Data Manipulation Language)数据操作
Hive ---- DML(Data Manipulation Language)数据操作 1. Load2. Insert1. 将查询结果插入表中2. 将给定Values插入表中3. 将查询结果写入目标路径 3. Export&Import 1. Load
Load语句可将文件导入到Hive表中。
1. 语法
LOAD DATA [LOCAL] INPATH …
[Hive基本概念之--hive分区]
目录
前言:
添加MyBatis和Hive依赖
配置MyBatis和Hive连接信息
在Spring Boot应用中定义MyBatis Mapper,例如: 定义实体类
MyBatis Mapper接口 Batis Mapper接口,insert方法对应Mapper中的insert方法,selectByPartition方法对…
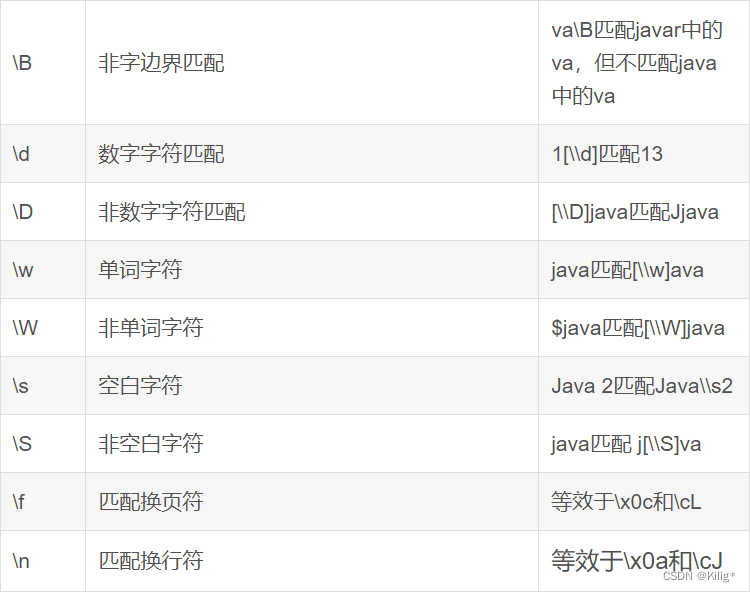

pyspark null类型 在 json.dumps(null) 之后,会变为字符串‘null‘
在将 hive 数仓数据写入 MySQL 时候,有时我们需将数据转为 json 字符串,然后再存入 MySQL。但 hive 数仓中的 null 类型遇到 json 函数之后会变为 ‘null’ 字符串,这时我们只需在使用 json 函数之前对值进行判断即可,当值为 null…
hive 入门 配置hiveserver2 (三)
1、简介
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
2、用户模拟功能
在远程访问Hive数据时,客户端并未直…

Kettle7.0同步数据(简单操作步骤hive-hive)
一、Kettle说明介绍和原理说明 Kettle是一款免费的ETL工具。 ETL分别是“Extract”、“ Transform” 、“Load”三个单词的首字母缩写,也就是代表ETL过程的三个最主要步骤:“抽取”、“转换”、“装载”,但我们平时往往简称其为数据抽取。 ET…
SQL必知必会(第五版)
SQL必知必会
了解SQL
1.数据库
数据库就像是一个容器,存放各种表。需要与DBMS区分
1.1表
一个结构化的清单,存储各种数据。
sql全称是struct query language 结构化查询语言
描述表的信息就是 模式 schema,当然模式也可以描述数据库。…

NIFI大数据进阶_实时同步MySql的数据到Hive中去_可增量同步_实时监控MySql数据库变化_操作方法说明_01---大数据之Nifi工作笔记0033
然后我们来看如何把mysql数据实时同步到hive中去
可以看到,其实就是使用
CaptureChangeMySql来获取mysql中变化的数据,具体就是增删改数据
然后再用RouteOnAttribute通过属性,也就是根据是增删改的话,根据这个属性进行路由
把数据路由到不同的位置
然后再用EvaluateJsonPa…

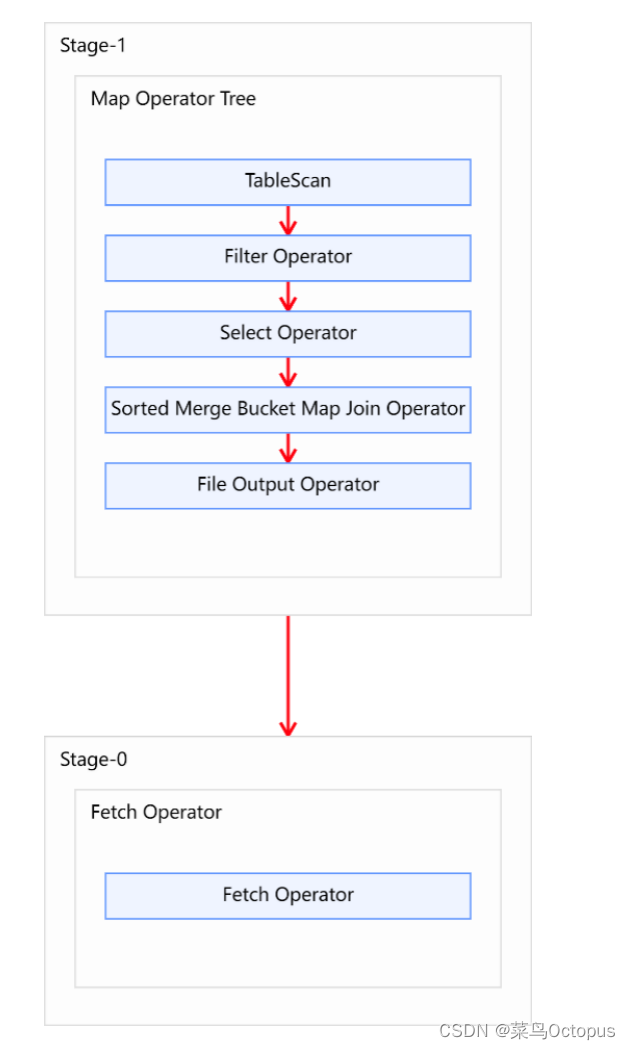
Hive on Spark调优(大数据技术6)
第6章 Join优化
6.1 Hive Join算法概述
Hive拥有多种join算法,包括common join,map join,sort Merge Bucket Map Join等。下面对每种join算法做简要说明:
1)common join
Map端负责读取参与join的表的数据ÿ…
Hadoop集群实现时间同步
一.为什么要对集群实现时间同步 因为我们在集群使用hive,mysql,hdfs之间等使用sqoop传输数据的时候,如果集群之间没有同步时间的话,那么就会报错,无法实现数据的传输。 不仅如此,在集群的使用当中ÿ…
【学习记录】大数据课程-学习二十三周总结
5.5.排序
5.5.1.Order By-全局排序 Order By:全局排序,一个reduce 1、使用 ORDER BY 子句排序 ASC(ascend): 升序(默认) DESC(descend): 降序 2、ORDER BY 子句在SELECT语句的结尾。…

Hive数据分层有哪些优点?具体每一层含义是什么?
为什么要分层?
作为一名数据的规划者,我们肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确被设计者和使用者感知到。直观来讲就是如图这般层次清晰、依赖关系直观。 但是,大多数情况下,我们完成的数据体系却…
Hive ---- 函数
Hive ---- 函数 1. 函数简介2. 单行函数1. 算术运算函数2. 数值函数3. 字符串函数4. 日期函数5. 流程控制函数6. 集合函数7. 案例演示 3. 高级聚合函数案例演示 4. 炸裂函数1. 概述2. 案例演示 5. 窗口函数1. 概述2. 常用窗口函数3. 案例演示 6. 自定义函数7. 自定义UDF函数 1.…
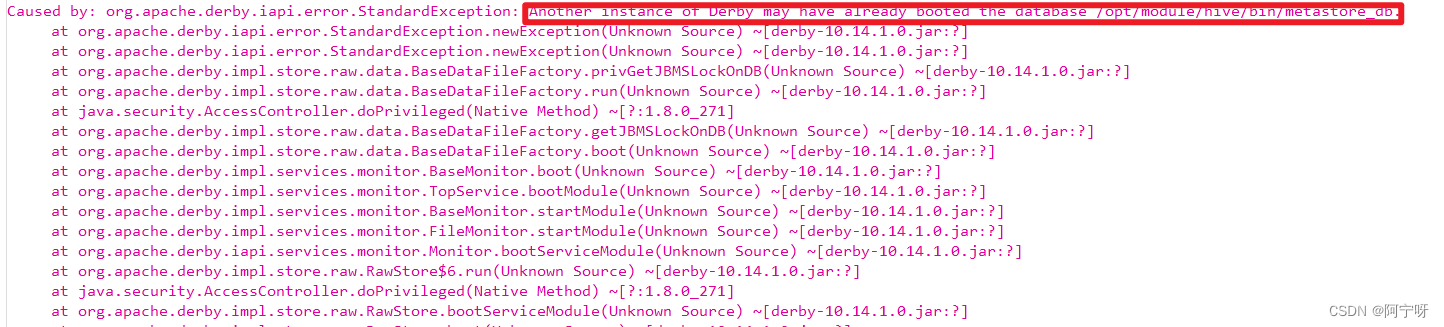
【大数据之Hive】二、Hive安装
Hive安装部署(最小化部署) 安装部署Hive(最小化只用于本机测试环境中,不可用于生产环境),并运行。
步骤: (1)把apache-hive-3.1.3-bin.tar.gz解压到/opt/module/目录下&…
hive:创建自定义python UDF
由于Hadoop框架是用Java编写的,大多数Hadoop开发人员自然更喜欢用Java编写UDF。然而,Apache也使非Java开发人员能够轻松地使用Hadoop,这是通过使用Hadoop Streaming接口完成的!
Java-UDF vs. Python-UDF
Java 实现 UDF,需要引用…

Hive优化篇-Hive数据存储格式
前言
本文讲解 Hive 的数据存储,是 Hive 操作数据的基础。选择一个合适的底层数据存储文件格式,即使在不改变当前 Hive SQL 的情况下,性能也能得到数量级的提升。这种优化方式对学过 MySQL 等关系型数据库的小伙伴并不陌生,选择不…

Hive学习---1、Hive入门、Hive 安装
1、Hive入门
1.1 什么是Hive
1、Hive简介 Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 2、Hive本质 Hive是一个Hadoop客户端,用于将HQL(Hive SQL…

Hive 之 数据的导入与导出及删除
欢迎大家扫码关注我的微信公众号: Hive 之 数据的导入与导出及删除一、数据导入1.1 向表中加载数据(load): 用的很多1.2 通过查询语句向表中插入数据(insert): 用的很多1.2.1 基本模式插入: &a…
【Hadoop】Hive用户自定义函数UDF
1: hive用户自定义函数udf,实现对字符串的格式化操作 引入maven依赖:
<dependency><groupId>commons-lang</groupId><artifactId>commons-lang</artifactId><version>2.6</version></depende…

【Hadoop】Hadoop相关错误及解决方案
1:hive运行错误 :
HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
不能实例化org.apache.hadoop.hive.ql.metadata这个包下的SessionHiveMetaStoreClientÿ…
Apache Hive2.1.0安装笔记
Hive2.x已经足够稳定了,前面也安装过hive0.x和Hive1.x的版本,今天我们来看下hive2.x如何安装使用。环境:centos7.1Hadoop2.7.3JDK8Hive2.1.01,首先需要下载hive最新的稳定版本的包,并保证的你Hadoop集群已经是能够正常…
如何使用Hive集成Solr?
(一)HiveSolr简介 Hive作为Hadoop生态系统里面离线的数据仓库,可以非常方便的使用SQL的方式来离线分析海量的历史数据,并根据分析的结果,来干一些其他的事情,如报表统计查询等。 Solr作为高性能的搜索服…
Hadoop可视化分析利器之Hue
先来看下hue的架构图:
[img]http://dl2.iteye.com/upload/attachment/0108/7048/ae2bc982-c44b-3786-b287-76bc357542f5.jpg[/img](1)Hue是什么?Hue是一个可快速开发和调试Hadoop生态系统各种应用的一个基于浏览器的图形化用户接口…

Hive ---- 文件格式和压缩
Hive ---- 文件格式和压缩 1. Hadoop压缩概述2. Hive文件格式1. Text File2. ORC3. Parquet3. 压缩1. Hive表数据进行压缩2. 计算过程中使用压缩 1. Hadoop压缩概述 为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示:
Hadoo…
CDH 之 hive 数据迁移
当你想切换了集群想把hive迁移至新集群,两个集群之间又互不相通,一个最简单快捷的方法,就是批量导出元数据信息,同时把数据文件下载上传至新服务器的数据文件存放目录下
批量导出云数据:
# database 即是数据库名称
…
MapReduce常用参数调优
一、资源相关参数
mapred-default.xml
配置参数参数说明mapreduce.map.memory.mb一个MapTask可使用的资源上限(单位:MB),默认为1024。如果MapTask实际使用的资源量超过该值,则会被强制杀死。mapreduce.reduce.memory.mb一个Redu…

Hive知识点的回顾
一、Hive的序列化和反序列化 Hive读取文件机制:读取文件中的每一行 > 反序列化 > 通过分隔符进行切割,返回数据表中的每一行对象。 Hive写文件机制:把数据表中的每一行Row对象 > 调用LazySimpleSerde类中的序列化方法 > 把Row对象…
火山引擎DataLeap的Catalog系统搜索实践(一):背景与功能需求
火山引擎DataLeap的Data Catalog系统通过汇总和组织各种元数据,解决了数据生产者梳理数据、数据消费者找数和理解数的业务场景,其中搜索是Data Catalog的主要功能之一。本文详细介绍了火山引擎DataLeap的Catalog系统搜索实践:功能的设计与实现…
锁屏面试题百日百刷-Hive篇(七)
锁屏面试题百日百刷,每个工作日坚持更新面试题。锁屏面试题app、小程序现已上线,官网地址:https://www.demosoftware.cn。已收录了每日更新的面试题的所有内容,还包含特色的解锁屏幕复习面试题、每日编程题目邮件推送等功能…
Hive存储原理,数据库/表基本操作
官方文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual 一 数据存储
Hive 数据分两部分:一部分是真实的数据文件,存放在hdfs上;另一份是真实数据的元数据(即数据的描述信息,比如说存…
hive性能测试hive-testbench
参考文档:
Hive基准测试神器-hive-testbench_shining_yyds的博客-CSDN博客
GitHub - hortonworks/hive-testbench
hive tpcds-benchmark 测试_houzhizhen的博客-CSDN博客
1. 构造测试数据
1.1
数据单位为G,最小的数据大小为2,构造数据…
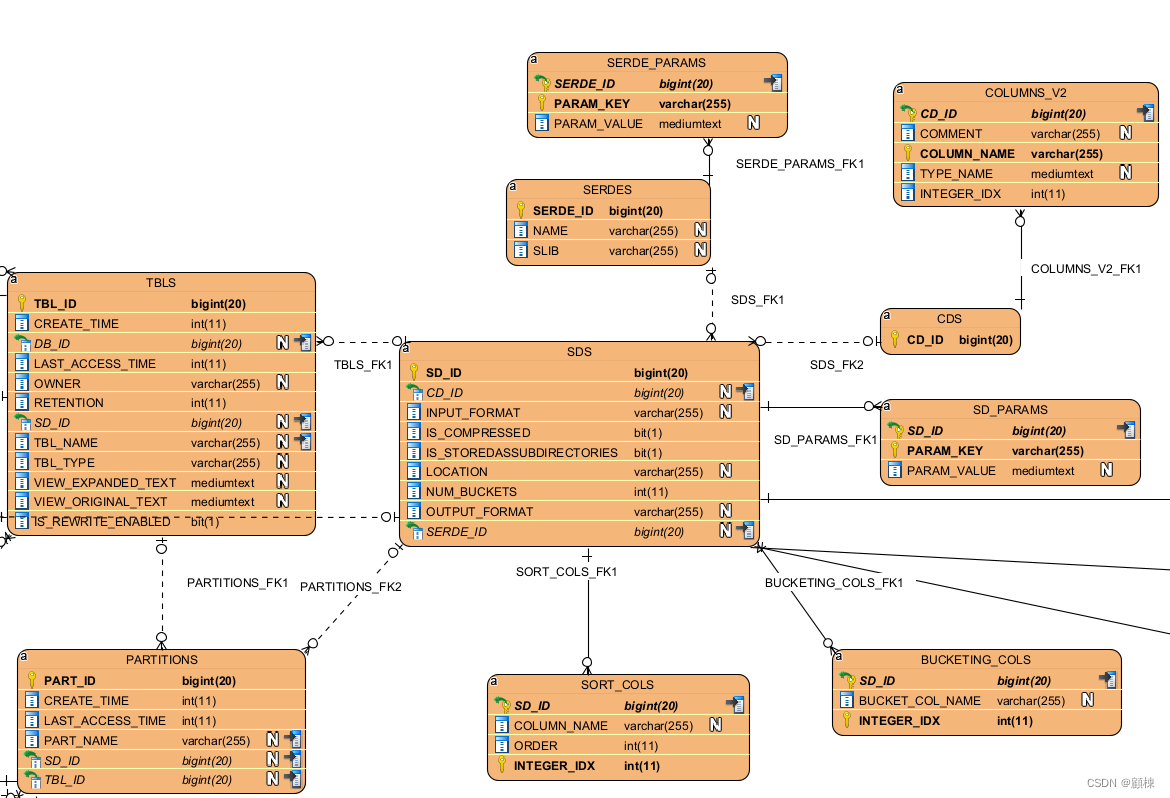
【Hive实战】Hive元数据存储库数据增多的分析
Hive元数据存储库数据增多的分析 2023年5月8日 文章目录 Hive元数据存储库数据增多的分析问题新增Hive相关的DDL操作创建Hive库库授权到用户 创建Hive表 内部表非分区表表授权到用户一级分区表二级分区表分桶表分桶排序表 查询指令核心表分析表关系图表以库表为主以hive表为主以…
Hive学习---DDL(Data Definition Language)数据定义 (创建数据库、创建表、修改表)
1、DDL(Data Definition Language)数据定义
1.1 数据库(Database)
1.1.1 创建数据库
1、语法
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (propert…
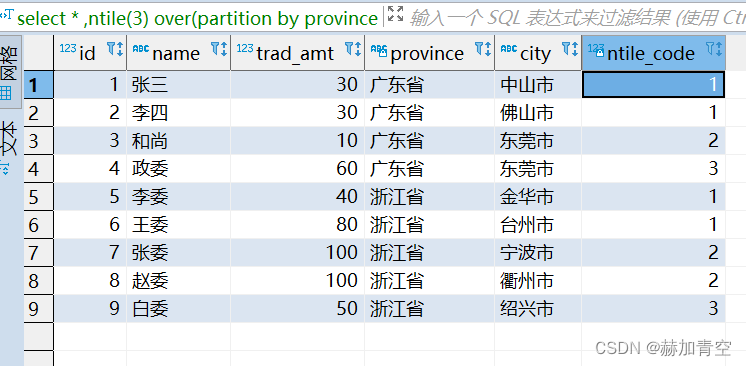
SQL使用技巧(6)HIVE开窗函数
专题:SQL使用技巧——实践是检验SQL函数的唯一标准 一.构建数据二.排序开窗三.sum开窗(重点内容)3.1累加与求和3.2窗口表达式3.3场景模拟 四.count开窗4.1计数规则4.2计数与排序 五.max和min开窗六.lead和lag开窗七.first_value和last_value开…
Hive从小时表中删除重复数据
Hive从小时分区中删除重复数据 一、小时分区数据去重二、重写小时分区数据 一、小时分区数据去重
小时分区数据去重后,写入到hive临时表中
with to_json_map as (
select distinct _track_id,time,distinct_id,to_json(lib) as lib,event,to_json(properties) as …
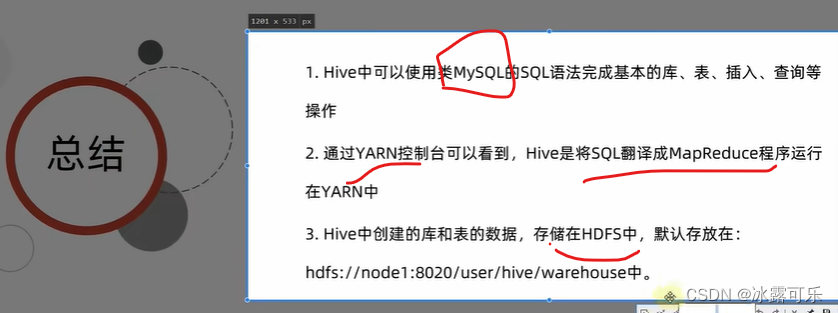
大数据:Apache hive分布式sql计算平台,hive架构,hive部署,hive初体验
大数据:Apache hive分布式sql计算平台
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle&a…
秒级数据写入,毫秒查询响应,天眼查基于 Apache Doris 构建统一实时数仓
导读: 随着天眼查近年来对产品的持续深耕和迭代,用户数量也在不断攀升,业务的突破更加依赖于数据赋能,精细化的用户/客户运营也成为提升体验、促进消费的重要动力。在这样的背景下正式引入 Apache Doris 对数仓架构进行升级改造&a…
hive的详细使用文档和使用案例
目录 Hive 简介安装连接到Hive创建数据库创建表加载数据查询数据修改表删除表 使用案例结论 Hive 简介
Hive是一个基于Hadoop的数据仓库工具,可以将结构化数据映射到Hadoop HDFS上,并提供SQL查询功能。Hive的设计目标是让那些熟悉SQL语言的用户能够在Ha…
结合Sqoop练习一下columns、where和query参数
1、前期的数据准备
1》创建一个学生表
create table student(id char(30),name char(30),age int,phone char(100),address char(100));
2》插入数据
insert into student values("1001","zhanghuan","21","1111","guiyang&q…
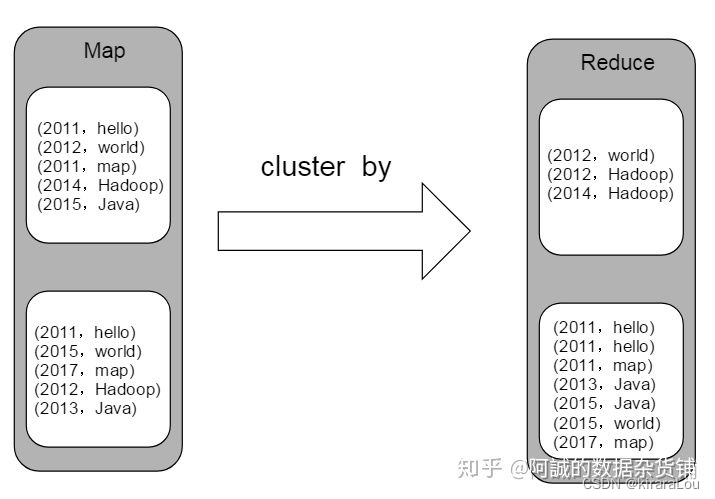
【hive】hive order、sort、distribute、cluster by区别与联系
1、order by
hive中的order by 会对查询结果集执行一个全局排序,这也就是说所有的数据都通过一个reduce进行处理的过程,对于大数据集,这个过程将消耗很大的时间来执行。
2、sort by
hive的sort by 也就是执行一个局部排序过程。这可以…
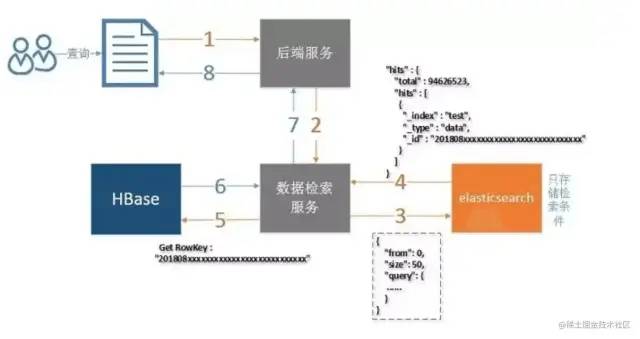
如何在千万级数据中查询 10W 的数据并排序
前言
在开发中遇到一个业务诉求,需要在千万量级的底池数据中筛选出不超过 10W 的数据,并根据配置的权重规则进行排序、打散(如同一个类目下的商品数据不能连续出现 3 次)。
下面对该业务诉求的实现,设计思路和方案优…

Hive:概述、体系架构、工作流程
目录
1、Hive概述
1.1、Hive是什么
1.2、数据仓库的特点
1.3、Hive优缺点
1.3.1、优点
1.3.2、缺点
1.4、Hive与传统数据库对比
1.4.1、读时模式与写时模式
1.4.2、更新
1.4.3、索引
1.4.4、数据存储
1.4.5、可扩展性
1.5、Hive与HBase
2、Hive体系架构
3、工作…
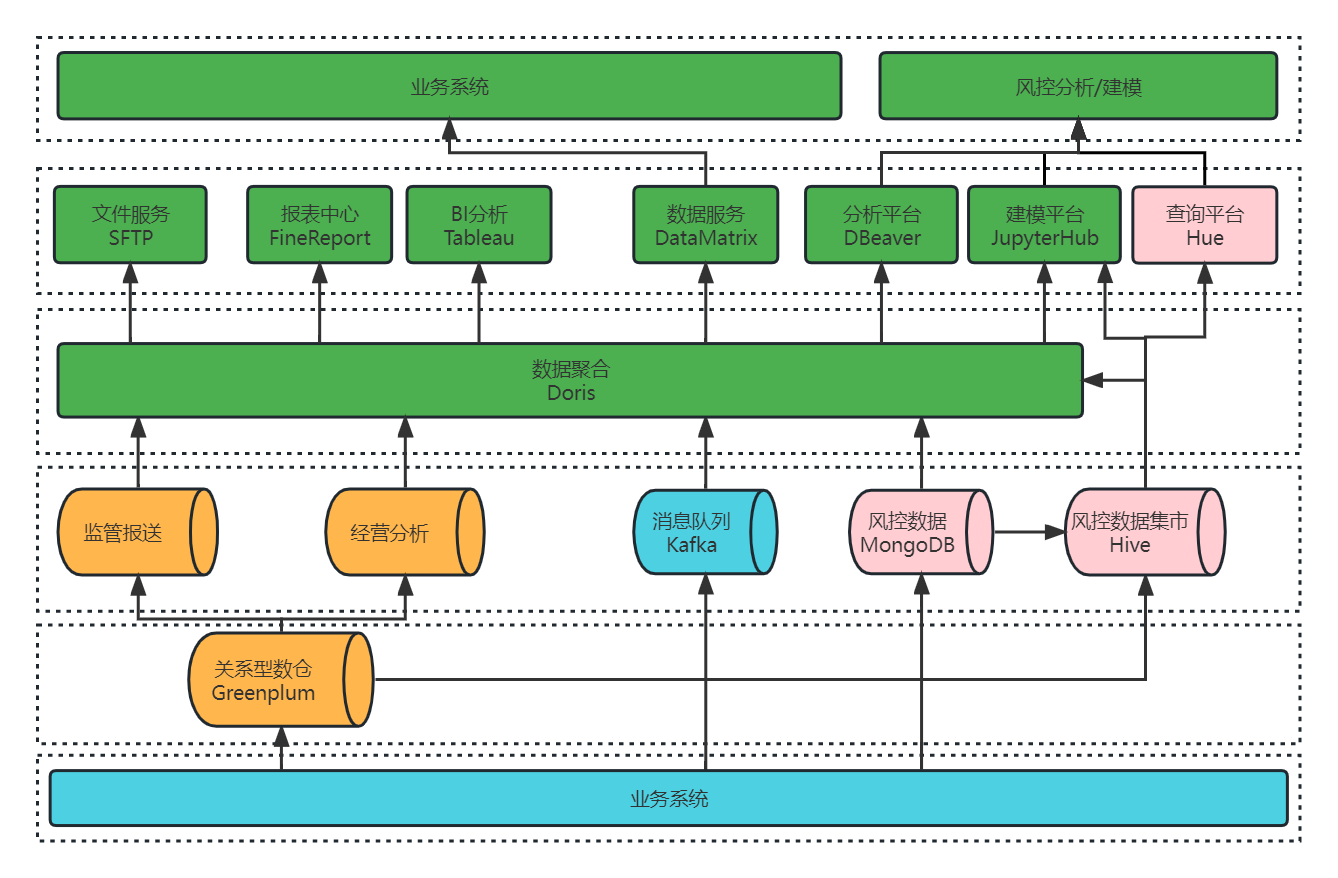
杭银消金基于 Apache Doris 的统一数据查询网关改造
导读: 随着业务量快速增长,数据规模的不断扩大,杭银消金早期的大数据平台在应对实时性更强、复杂度更高的的业务需求时存在瓶颈。为了更好的应对未来的数据规模增长,杭银消金于 2022 年 10 月正式引入 Apache Doris 1.2 对现有的风…
Hadoop学习全程记录——hive入门
hive是Facebook的产品,很不错。 官方文档:http://wiki.apache.org/hadoop/Hive/GettingStarted有很详细说明。 基本上根据文档能对hive快速入门。在使用过程中可能会出现以下问题: 当执行下面命令时:
Java代码
$ $HIVE_HOME/bin…
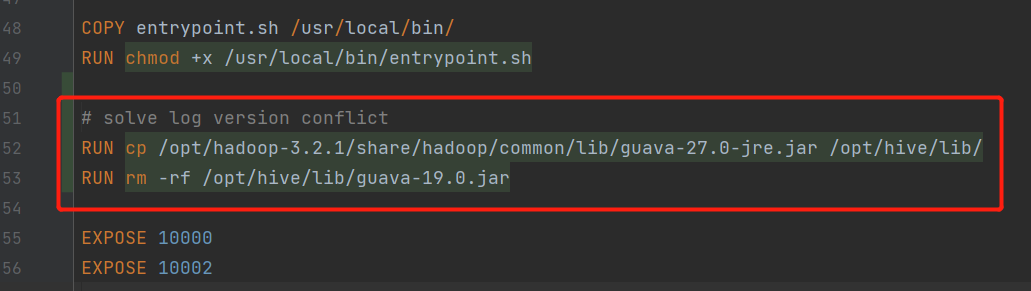
3.Hive系列之docker-compose部署升级总结
1. 版本号修改
对于升级而言,我们最先考虑的是docker hub中有的较新的版本,然后我们需要简单了解下hadoop2与hadoop3的区别,首先明确的是端口号有所改变,如下图所示 2. Hive镜像构建
刚刚我们修改了Hive为bde2020/hive:3.1.2-po…
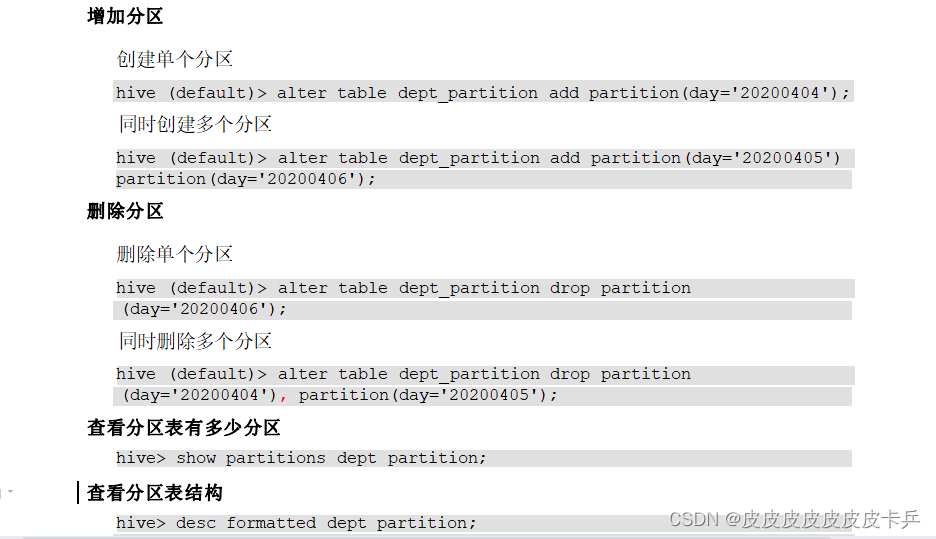
Hive——详细总结Hive中各大查询语法
✅作者简介:最近接触到大数据方向的程序员,刚入行的小白一枚 🍊作者博客主页:皮皮皮皮皮皮皮卡乒的博客 🍋当前专栏:Hive学习进阶之旅 🍒研究方向:大数据方向,数据汇聚&a…
Apache Hive 的 SQL 执行架构
前言
本文隶属于专栏《大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢! 本专栏目录结构和参考文献请见大数据技术体系 正文
本文介绍 Apache Hive 如何将 SQL 转化为 Map…
Hive面试题系列第六题-互为好友问题
视频讲解地址: https://www.bilibili.com/video/BV1at4y1J7Bq/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第六题-互为好友问题
题目:根据用户好友列表user_table,求互为共同好友的人有多少对。 表结构:
cre…
Hive面试题系列第五题-Uv累加趋势图问题
视频讲解地址: https://www.bilibili.com/video/BV1114y1b7eP/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178 Hive面试题系列第五题-uv累加趋势图问题 题目:每个用户访问店铺shop_id的商品时都会产生一条访问日志,求每…
Hive面试题系列第四题-Pv累加趋势图问题
视频讲解地址:https://www.bilibili.com/video/BV1L14y1b7Ur/?spm_id_from333.788&vd_sourceaa4fb0436f6d978af872cafb81a01178
Hive面试题系列第四题-pv累加趋势图问题 题目:求每个用户截止到每月月底(累计到该月)的总访问…
hive和hbase的一些数据导入导出操作
一、hive 数据导入导出
1、distcp 分布式拷贝
新旧集群之间如果能直接通讯,在不考虑影响业务的情况下,最便捷的方式是使用分布式拷贝,但是又分为相同版本和不同版本直接拷贝,以下为相同版本之间拷贝的方式。
hadoop distcp -D …

深入理解 Hive UDAF
1. 概述
用户自定义聚合函数(UDAF)支持用户自行开发聚合函数完成业务逻辑。从实现上来看 Hive 有两种创建 UDAF 的方式,第一种是 Simple 方式,第二种是 Generic 方式。
1.1 简单 UDAF
第一种方式是 Simple(简单) 方式,即继承 org.apache.hadoop.hive.ql.exec.UDAF 类,并…
Hive架构以及应用介绍
Hive这个框架在Hadoop的生态体系结构中占有及其重要的地位,在实际的业务当中用的也非常多,可以说Hadoop之所以这么流行在很大程度上是因为Hive的存在。那么Hive究竟是什么,为什么在Hadoop家族中占有这么重要的地位,本篇文章将围绕…

Sqoop实现mysql与hive数据表互相导入
文章目录1. 上传解压搭建sqoop1.1 解压后改名1.2 修改配置文件1.3 重命名1.4修改配置文件1.5拷贝mysql驱动包到/usr/sqoop/lib库下1.6 sqoop version查看版本1.7 测试连接2.将mysql中学生表导入到hive中2.1 先清空hive中的student表2.2 MysqlToHive.opt 文件内容2.3 执行命令3.…
hive on spark模式hive的配置
安装Hive环境
使用编译好的源码软件
# 上传安装文件
apache-hive-3.1.2-bin.tar.gz
# 解压到指定目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /bigdata/server/
# 创建软链接
ln -s apache-hive-3.1.2-bin hive配置环境变量
# vim /etc/profile.d/custom_env.sh
## h…
[Exceptions]运行hive sql报错NoViableAltException
报错内容
NoViableAltException(380[212:1: tableName : (db identifier DOT tab identifier -> ^( TOK_TABNAME $db $tab) |tab identifier -> ^( TOK_TABNAME $tab) );])
理解报错
关键信息理解
这个报错信息提供了以下几个关键信息: 错误类型ÿ…
大数据常见面试题之hive
文章目录一.描述一下Hive动态分区和分桶使用场景和使用方法1.分区2.分桶二.Hive是怎么集成HBase三.Hive join查询的时候on和where有什么区别四.Hive里面的left join是怎么执行的?五.Hive内部表,外部表,分区表六.Hive和mysql有什么区别,大数据为什么不用M…
hive 获取日期范围内数据
日期加减
date_sub(2021-08-22,2) //日期向前减两天
date_add(2021-08-22,2) //日期向后加两天确定日期的范围
eg:获取2021-08-20~2021-08-24的日期条件datediff(to_date(dt),2021-08-20)>0 and datediff(to_date(dt),2021-08-24)<0字符串转日期
to_date(dt)

数据仓库经典销售案例
文章目录一、业务库1.1 数据模型1.2生成数据二、数据仓库2.1 模型搭建2.1.1 选择业务流程2.1.2 粒度2.1.3 确认维度2.1.4 确认事实2.1.4.1 建立物理模型2.1.4.2 建库、装载数据三.编写脚本配合 crontab 命令实现 ETL 自动化一、业务库
1.1 数据模型
源系统是 mysql 库&#x…

hadoop组件之hive环境搭建
文章目录一.什么是Hive?二.Hive与传统数据库比对三.Hive部署1.下载与安装2.Hive需要提前装好MySQL3.Hive配置文件修改4.启动(需要先启动hdfs)一.什么是Hive?
Hive是建立在Hadoop上的工具.能够帮助用户屏蔽掉复杂的MapReduce逻辑,只需要用户使用简单的SQL语句即可完成一定的查…
hive连接mysql之疯狂踩坑
这次真的是非常吐血,虽然网上有很多排错教程,但介于我踩的坑实在太多,所以记录一下整个汇总信息
故事要从hive启动开始,如果你的hive启动不起来, 是因为你的$HADOOP_HOME/etc/hadoop/hadoop-env.sh 当中的HADOOP_CLAS…


Spring的import注解解析及使用场景
一、导言 在spring框架下做开发时,会给容器中导入组件,通常我们给容器中注入组件的方式,可以通过Spring的xml配置方式,也可以通过注解,如Component等,也可以通过java配置类的方式给容器中导入,I…
面试题-js数组扁平化
这是我参与更文挑战的第3天,活动详情查看: 更文挑战 写在前面: 数组扁平化是指将一个多维数组变为一维数组,如: 将多维数组:
[1, [2, 3, [4, 5]]]
转为一维数组:
[1, 2, 3, 4, 5] 如何实现&am…
Hive09---字符串拼接,转json等
Intro 常用hive字符串拼接函数,转json等操作
import pysparkimport pyspark.sql.functions
from pyspark.sql import SparkSession
# 创建SparkSession对象,调用.builder类
# .appName("testapp")方法给应用程序一个名字;.getOrCr…
Hive 实战调优参数大全
-- 开启动态分区,写入数据时需要
set hive.optimize.sort.dynamic.partitiontrue;
-- 默认值是strict,默认要求分区字段必须有一个是静态的分区值
set hive.exec.dynamic.partition.modenonstrict;-- 控制在同一个sql中的不同的job是否可以同时运行。默认…
Hive优化笔记(3 - 一些参数)
动态分区
静态分区:手动指定分区名。动态分区:根据查询语句自动生成的分区名
https://blog.csdn.net/weixin_34104341/article/details/89795410
-- 开启动态分区。默认值是true
set hive.exec.dynamic.partitiontrue;
-- 默认值是strict,…
解决Hive在DataGrip 中注释乱码问题
注释属于元数据的一部分,同样存储在mysql的metastore库中,如果metastore库的字符集不支持中文,就会导致中文显示乱码。
不建议修改Hive元数据库的编码,此处我们在metastore中找存储注释的表,找到表中存储注释的字段&a…
Hive的视图和索引
Hive的视图和索引
1、Hive Lateral View
1、基本介绍
Lateral View用于和UDTF函数(explode、split)结合来使用。 首先通过UDTF函数拆分成多行,再将多行结果组合成一个支持别名的虚拟表。主要解决在select使用UDTF做查询过程中&#…
flink使用sql-client-defaults.yml无效
希望在flink sql脚本启动时自动选择catalog,减少麻烦。于是乎配置sql-client-defaults.yaml:
catalogs:- name: hive_catalogtype: icebergcatalog-type: hiveproperty-version: 1cache-enabled: trueuri: thrift://localhost:9083client: 5warehouse: …
hive多分隔符外表支持
在hive 外表关联文本的时候 有时会遇到不是一个长度的分割符比如"~" 这种。这个时候使用shell命令多处理一步处理成单分隔符也可以,但是会有出错的风险。我们可以通过hive中指定的序列类来完成多分隔符的识别。 CREATE EXTERNAL TABLE text_mid1(
id STRI…
Hive用户自定义函数之UDF开发
在进行大数据分析或者开发的时候,难免用到Hive进行数据查询分析,Hive内置很多函数,但是会有一部分需求需要自己开发,这个时候就需要自定义函数了,Hive的自定义函数开发非常方便,今天首先讲一下UDF的入门开发…
【大数据进阶第三阶段之Hive学习笔记】Hive安装
1、环境准备 安装hadoop 以及 zookeeper、mysql
【大数据进阶第二阶段之Hadoop学习笔记】Hadoop 运行环境搭建-CSDN博客
《zookeeper的安装与配置》自行百度
《Linux环境配置MySQL》自行百度 2、下载安装 CSDN下载:https://download.csdn.net/download/liguohuat…
【Hive】在博客系统中如何应用 Hive 进行离线数据管理
简介: 博客系统作为一个信息发布平台,处理的数据量通常很大。为了更高效地管理和分析这些数据,离线数据处理变得非常重要。Hive 是一个开源的数据仓库基础设施,它能够在博客系统中提供强大的离线数据管理能力。本文将详细介绍如何在博客系统中…
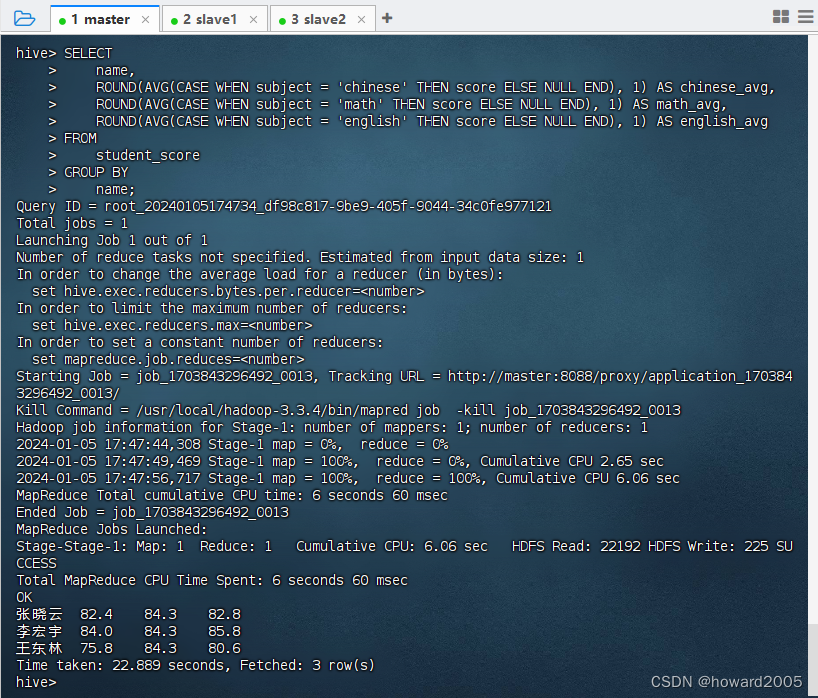
Hive实战:分科汇总求月考平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、创建分区的学生成绩表4、按分区加载数据5、查看分区…
Hive自定义函数支持国密SM4解密
当前项目背景需要使用到国密SM4对加密后的数据进行解密,Hive是不支持的,尝试了华为DWS数仓,华为只支持在DWS中的SM4加密解密,不支持外部加密数据DWS解密 新建Maven工程
只需要将引用的第三方依赖打到jar包中,hadoop和…
2024.1.5 Hadoop各组件工作原理,面试题
目录 1 . 简述下分布式和集群的区别
2. Hadoop的三大组件是什么?
3. 请简述hive元数据服务配置的三种模式?
4. 数据库与数据仓库的区别?
5. 简述下数据仓库经典三层架构?
6. 请简述内部表和外部表的区别?
7. 简述Hive的特点,以及Hive 和RDBMS有什么异同
8. hive中无…
数仓工具—Hive进阶之常见的StorageHandler(24)
这里我们介绍一下常见的StorageHandler,但是由于目前StorageHandler的种类还是比较多的,主要包括官方的和非官方的,我们使用的时候需要注意的是版本的兼容性。
常见的StorageHandler
Apache Hive提供了多个存储处理程序(Storage Handler),允许用户集成Hive查询和分析引…
【大数据进阶第三阶段之Hive学习笔记】Hive常用命令和属性配置
目录
1、Hive安装
2、HiveJDBC访问
2.1、启动hiveserver2服务
2.2、连接hiveserver2服务
2.3、注意
3、Hive常用交互命令
3.1、“-e”不进入hive的交互窗口执行sql语句
3.2、“-f”执行脚本中sql语句
4、Hive其他命令操作
4.1、退出hive窗口
4.2、在hive cli命令窗口…
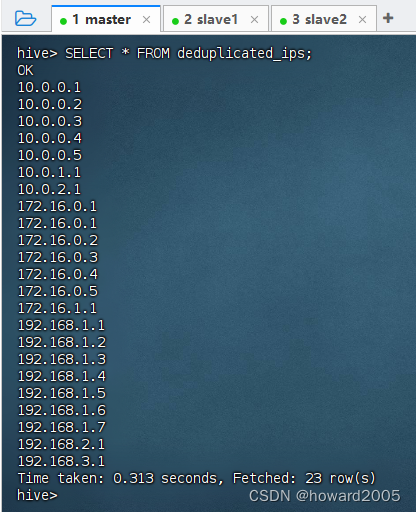
Hive实战:网址去重
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、基于HDFS数据文件创建Hive外部表4、利用Hive SQL实…

一文弄清楚hive窗口函数
1 定义
窗口函数,又称分析函数
Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group.
The group of rows is called a window and is defined by…

hive3.1安装配置与底层表存储原理
Hive3.1 安装配置与底层存储原理
前言:基于自建Hadoop集群,单节点配置hive服务,主要用于验证工作中的hsql和hive的底层表架构原理(hive外部表数据在哪,分区表在hadoop是怎么存储的等等)。纸上得来终觉浅&a…
Apache Hive2.1.1安装部署
转载请注明出处:http://blog.csdn.net/u012842205/article/details/71713842 一、Apache Hive简介
Apache Hive是基于Hadoop的一个数据仓库工具,用于使用SQL语法查询、读取、写入和管理大数据量的分布式数据结构。可以将结构化的数据文件映射为一张数据…

8. 查询每日新用户数
文章目录 题目需求思路一实现一题目来源 题目需求
从用户登录明细表(user_login_detail)中查询每天的新增用户数,若一个用户在某天登录了,且在这一天之前没登录过,则任务该用户为这一天的新增用户。
期望结果如下&am…
vmware虚拟机转hyper虚拟机
主要是转硬盘格式,使用StarWind V2V Image Converter,选择vmware中的硬盘,转为hyper格式。
因为原有虚拟机中存在hadoop,spark,hive,mysql,tomcat,hbase,docker,所以改动各种配置:
1.修改硬盘中ip, /etc/network/interfaces中的ip等信息。s…
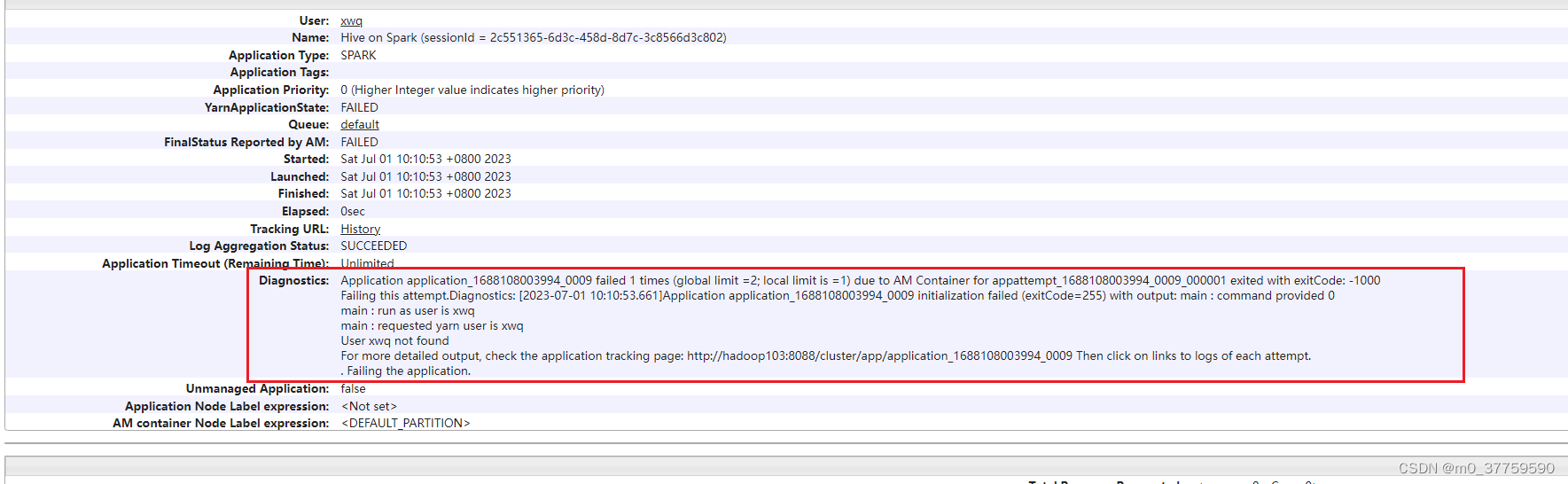
hive中的datagrip和beeline客户端的权限问题
hive中的datagrip和beeline客户端的权限问题
使用ranger和kerberos配置了hadoop和hive,今天想用来测试其权限 测试xwq用户: 1.首先添加xwq用户权限,命令如下:
useradd xwq -G hadoop
echo xwq | passwd --stdin xwq
echo xwq …

23年hadoop单机版+hive
文章目录 说明分享环境信息安装jdkhadoop配置core-site.xml mysqlhive安装配置hive-site.xml配置hive-env初始化mysql数据库启动验证hive命令hiveserver2方式 总结 说明 工作需要研究hive功能,线上环境不能动,搭建单机版hadoophive测试环境,使…
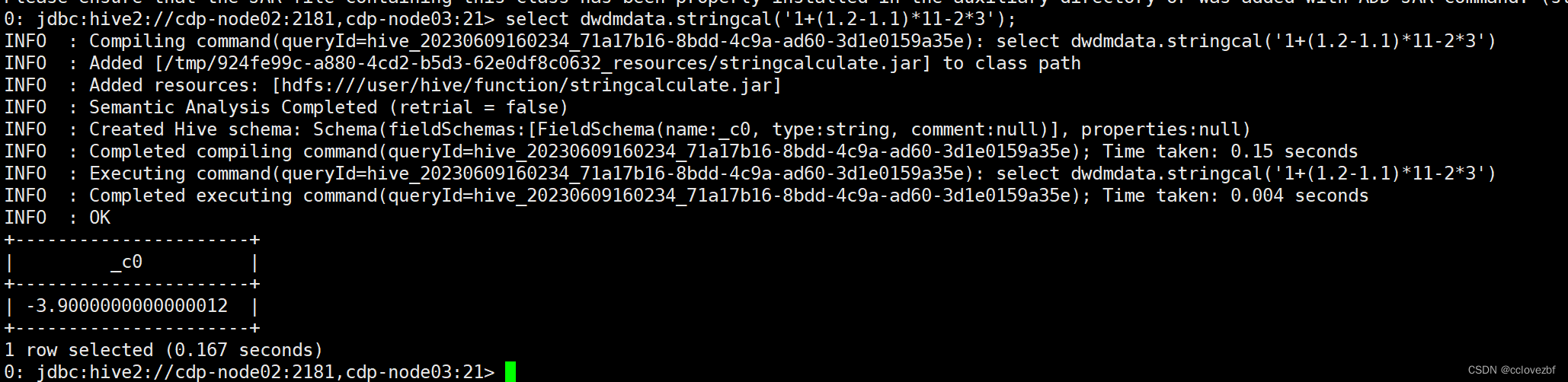
hive创建udf函数流程
1.编写udf函数
引入pom文件 <dependencies> <dependency> <!-- 这个属于额外的jar包 自己按需引用 比如你想搞得函数 里面要连接mysql 这里肯定需要引入mysql的驱动包 我这个包是为了计算字符串的表达式的。 --> <groupId>org.apache.com…
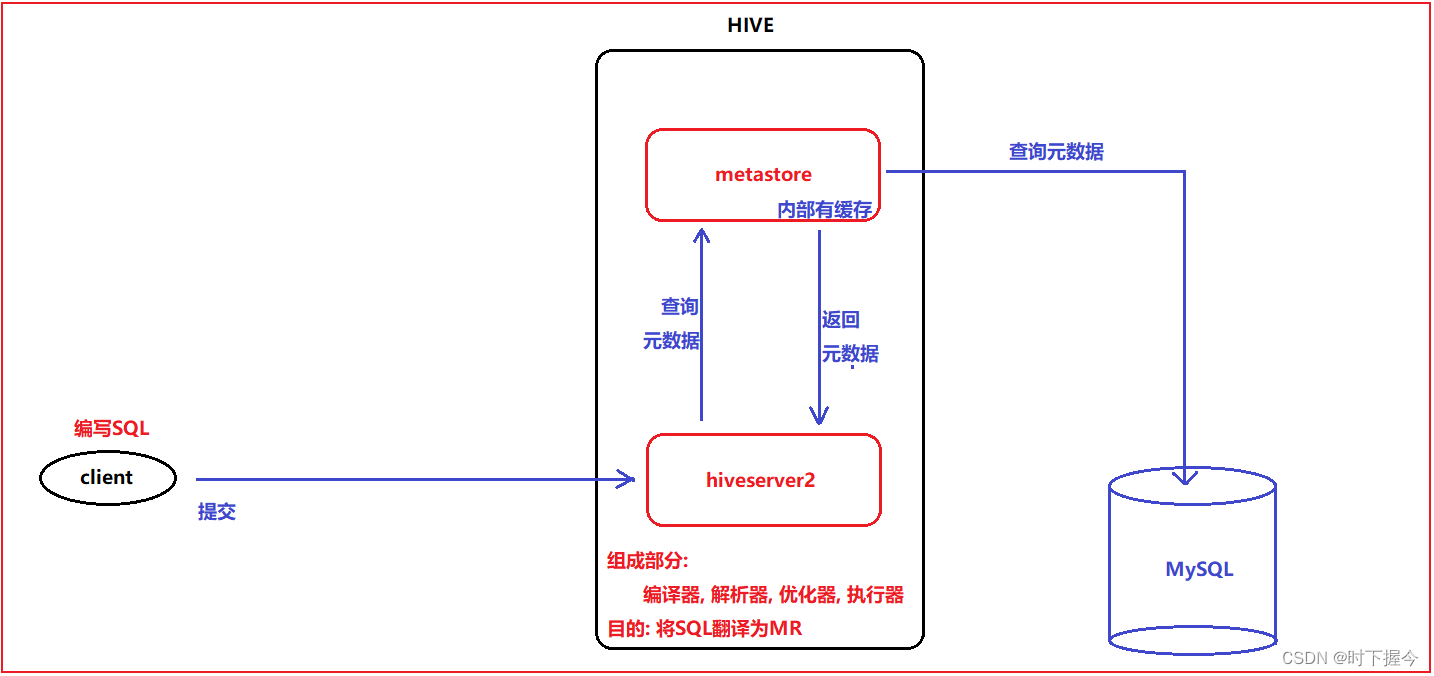
SparkSQL与Hive整合(Spark On Hive)
1. Hive的元数据服务
hive metastore元数据服务用来存储元数据,所谓元数据,即hive中库、表、字段、字段所属表、表所属库、表的数据所在目录及数据分区信息。元数据默认存储在hive自带的Derby数据库。在内嵌模式和本地模式下,metastore嵌入在…

Hive知识点总结(面试)
目录
Hive元数据为何不存放在内置的derby数据库中?
Hive中的四种排序?
Hive与MySQL数据库区别?
HQL的执行流程?
Hive 工作原理?
内部表与外部表?
Hive分组排序的方式?
Hive中的文件格式…
揭秘大数据时代秒级查询响应引擎的架构设计
近年来,大数据技术发展迅速,从过去的 Hive、Spark,到现在的 Flink、ClickHouse、Iceberg 等,各种大数据技术推陈出新,不断演进大数据存储和引擎系统的架构,来适应大数据时代的海量数据处理需求。
而随着技…

数仓利器-Hive高频函数合集
文章目录前言数据准备数据集建表语句窗口函数row_number:使用频率 ★★★★★rank :使用频率 ★★★★dense_rank:使用频率 ★★★★rank/dense_rank/row_number对比first_value:使用频率 ★★★last_value:使用频率 ★…
Hive中MySQL数据库的安装及绑定
Hive中MySQL的安装及绑定
Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库derby数据库只支持单用户访问且不与其他客户端共享数据MySQL数据库可支持多用户访问且可与其他客户端共享数据将 Hive 的元数据地址改为 MySQL数据库
[mnlgXJ202 ~]$ my_…
Hive(HQL)数据库的安装及配置
点击可查看Hive中MySQL数据库的安装及绑定
Hive的特点
Hive与SQL语句相像能将SQL语句转变成MapReduce任务来执行Hive要依赖于yarn只能用于结构化Hive只能处理离线数据,处理大型数据
Hive在集群上的操作
1.Hive安装及配置
(1)点击XShell&…
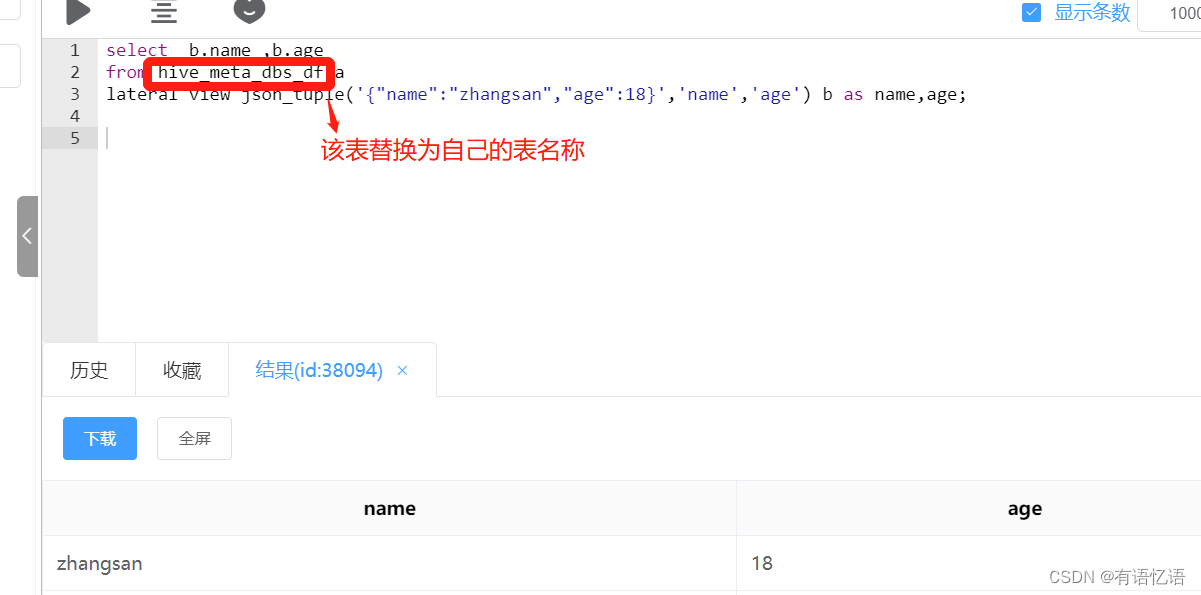
HIVE获取json字段特定值(单个json或者json数组)
1.获取单个json字符串里的某一特定值
函数:get_json_object(单个json,‘$.要获取的字段’)
示例:
代码:SELECT get_json_object(‘{“NAME”:“张三”,“ID”:“1”}’,‘$.NAME’) as name;
SELECT get_json_object(‘{“NAME”:“张三”…

【大数据之Hive】九、Hive之DDL(Data Definition Language)数据定义语言
1 数据库
[ ] 里的都是可选的操作。
1.1 创建数据库
语法:
create database [if not exists] database_name
[comment database_comment(注释)]
[location hdfs_path]
[with dbproperties (property_name-propertyproperty_value,...)]; 如:
creat…

Hive/Presto中函数grouping sets用法详解(踩坑总结,看到赚到)
目录 1. 问题讨论1.1 数据准备1.2 问题描述1.3 其它方法多维度聚合(union、with cube) 2. Hive中的grouping sets函数2.1 grouping sets方法多维度聚合2.2 grouping sets在联结join中使用的踩坑点2.3 grouping sets函数使用补充事项2.4 计算grouping__id…
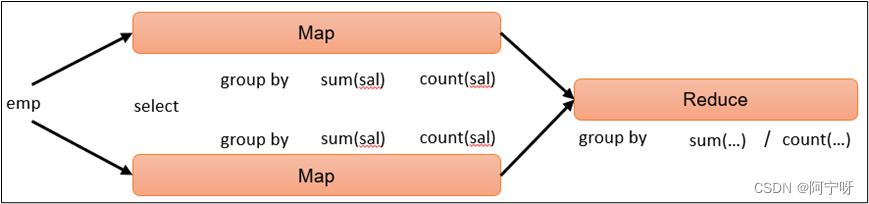
【大数据之Hive】十一、Hive-HQL查询之基本查询
基础语法
select [all | distinct] select_expr,select_expr, ...from table)name --从什么表查[where where_condition] --过滤[group by col_list] --分组查询[having col_list] --分组后过滤[order by col_list] --排序[cluster by col_list | …

Apache Hive安装部署
Apache Hive安装部署
🚃Hive元数据
描述数据的数据,主要描述数据属性信息,用来支持如指示存储位置,历史数据,资源查找,文件记录等功能。存储在关系型数据库中。如hive内置Derby,或第三方MySql…

hive优化大全(hive的优化这一篇就够了)
文章目录写在前面一、概述1.1 数据倾斜1.2 MapReduce二、产生原因三、解决方案和避免方案3.1 Hive语句初始化配置3.1.1 join过程的配置3.1.2 map join过程的设置3.1.3 combiner过程3.1.4 group by 过程3.1.5 map 或者reduce 过程3.1.6 mapper 设置3.1.7 reducer设置3.1.8 存储与…
Spark创建Hive表
前言
实习生带着一脸坚毅的神情,斩钉截铁的告诉我: Spark有bug,用Sparksql创建一个简单的外部表都报错:
create external table must be accompanied by location我:你怎么创建的? 实习生:就下面一个简单的sql语句啊
spark.sql("""
CREATE EXTERNAL T…
[大数据 Sqoop,hive,HDFS数据操作]
目录
🥗前言:
🥗实现Sqoop集成Hive,HDFS实现数据导出
🥗依赖:
🥗配置文件:
🥗代码实现:
🥗控制器调用:
🥗Linux指令导入导出:
🥗使用Sqoop将数据导入到Hive表中。例如&#…
【Hive实战】Hive治理方向探讨(请留意见)
Hive治理方向探讨 文章目录 Hive治理方向探讨Hive治理项治理临时性质的表控制分区表的分区数量和分区层级限制建表时使用的存储格式表或分区记录的location对应的HDFS路径实际不存在表级路径应是分区路径的前缀内部表使用非内部表路径外部表使用内部表路径表的属性个数异常按时…

Hive的元数据信息
Hive将表中的元数据信息存储在数据库中,如derby(自带的)、Mysql(实际工作中配置的)。通过Mysql进行示例说明: Hive数据仓库中:
MySql数据库中存储的相应元数据信息:
Navicate(远程连接的MySql)对应的元数据信息: Hive中创…
源码编译 DolphinScheduler 1.3.9 海豚调度,修改Hadoop、Hive组件版本兼容
大前提: maven3 jdk8 环境
maven 私服换成国内镜像,推荐阿里云 maven 镜像 maven-3.6.3\conf\settings.xml <mirrors><mirror><id>aliyunmaven</id><mirrorOf>*</mirrorOf><name>阿里云公共仓库</name&g…

mysql jdbc在hive中没有安装导致的两个问题
问题–hive操作的时候抛出异常:
hive> show databases;
FAILED: Error in metadata: javax.jdo.JDOFatalInternalException: Error creating transactional connection factory
NestedThrowables:
java.lang.reflect.InvocationTargetException
FAILED: Executi…

大数据开发技术与实践期末复习(HITWH)
目录
分布式文件处理系统HDFS
分布式文件系统
HDFS简介
块(block)
主要组件的功能
**名称节点
FsImage文件
名称节点的启动
名称节点运行期间EditLog不断变大的问题
SecondaryNameNode的工作情况
数据节点
HDFS体系结构
HDFS体系结构的局限…
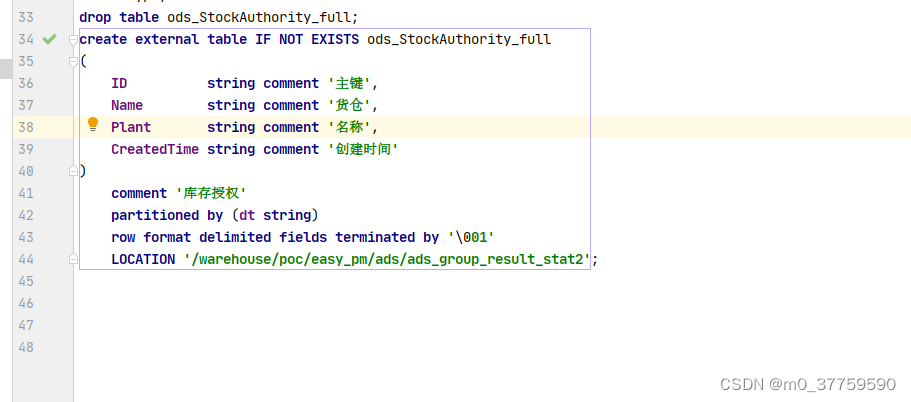
ranger,hive,hdfs的三者的权限管理
ranger,hive,hdfs的三者的权限管理
情况一:连接datagrip
用户在hdfs上的权限
可以看出只给了用户write权限,尝试登录xwq用户,在datagrip上登录成功 经过实验验证:要想使用datagrip或者hive-cli登录hive…
使用DataX,从Greenplum将数据传输到Hive分区表中
我司使用Greenplum作为计算库,实时计算统计数据,但是数据量大了之后影响计算速度。所以将每天的数据通过Datax传输到Hive的按日分区的分区表中,用于备份,其他数据放在Greenplum中作为实时数据计算。 Greenplum内核还是PostgreSQL&…

hive设置设置中文支持
在hive元数据库中(MySQL)执行以下语句 -- 设置注释支持中文
ALTER TABLE COLUMNS_V2 CHANGE COMMENT COMMENT VARCHAR(256) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL;
-- 设置字段支持中文
ALTER TABLE COLUMNS_V2 CHANGE COLUMN_NAME COLUMN_…
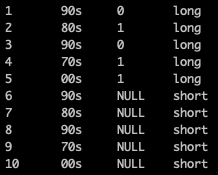
Hive - Load Data 数据过长或过短
一.引言
Hive 可以通过 load data inpath 加载本地或者 hdfs 的数据到 hive 表中,有时会出现生成数据长于 hive 表字段或者短于 hive 表字段的情况,经过测试,两种情况下 Load Data 到 hive 表中均没有问题。
首先建立测试的 Hive 表&#x…
学习大数据技术,Hive实践分享之存储和压缩的坑
在学习大数据技术的过程中,HIVE是非常重要的技术之一,但我们在项目上经常会遇到一些存储和压缩的坑,本文通过科多大数据的武老师整理,分享给大家。
大家都知道,由于集群资源有限,我们一般都会针对数据文件…
Hive中高频常用的函数和语法梳理及业务场景示例
Hive中高频常用的函数和语法梳理及业务场景示例
聚合函数
collect_list - 收集列值到一个数组
collect_list函数用于将指定列的值收集到一个数组中,并返回该数组作为结果。它通常在GROUP BY子句中使用,以将相同键的值收集到一个数组中进行聚合操作
以…

hive 行转列 lateral view 与 explode函数
hive 中通过lateral view 与explode 实现行转列功能 explode作用是处理map结构的字段,使用案例如下(hive自带map,struct,array字段类型):
drop table if exists XX;
create table XX(area string,goods_id…

Hive的sql语句
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进…
MySQL常用语句汇总
给user表的id字段增加主键约束
alter table user add primary key(id);
alter table user modify id int primary key;给user表的id字段删除主键约束
alter table user drop primary key; 外键约束
create table classes(id int primary key,name varchar(20)
);create tabl…
Python——hive数据库迁移到mysql数据库
可能需要先看的内容(主要是依赖安装和连接hive时的报错问题解决) sublimepythonhive
pip install 文件
from impala.dbapi import connect
import time
import pymysqltables[list_day]#所有要迁移的表名数组,本hive数据库和mysql数据库表名相同,字段也…
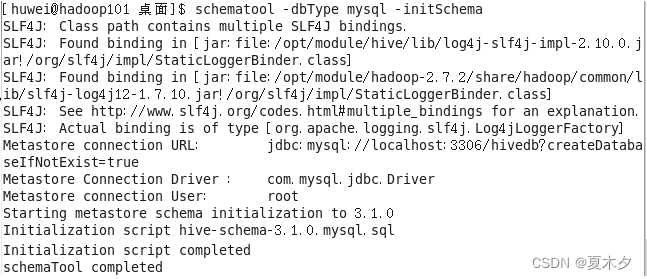
记录python使用pymysql连接mysql数据库,使用impyla、ibis-framework[impala]连接hive\impala(kerberos)数据库(备以后查阅)
记录python使用pymysql连接mysql数据库,使用impyla、ibis-framework[impala]连接hive\impala(kerberos)数据库(备以后查阅) 连接mysql 数据库 # time: 2022/1/21 13:12
# function : 连接mysql数据库import pymysql
i…
MARK :Hive 的 自定义 Inputformat
Hive默认创建的表字段分隔符为:\001(ctrl-A),也可以通过 ROW FORMAT DELIMITED FIELDS TERMINATED BY 指定其他字符,但是该语法只支持单个字符,如果你的分隔符是多个字符,则需要你自定义InputFormat来实现,…

Hive基本原理(修订版)
Hive的本质是一个翻译器。它的任务就是将一种类SQL(HQL)的语句翻译成Mapreduce任务,通过执行Mapreduce任务来对海量数据仓库进行处理。从表面上来看它就是一个数据仓库能够查询与分析数据。它与Hadoop的关系如下图所示: 与传统数据…

HiveSQL解析原理:包括SQL转化为MapReduce过程及MapReduce如何实现基本SQL操作
HiveSQL解析原理:包括SQL转化为MapReduce过程及MapReduce如何实现基本SQL操作一、MapReduce实现基本SQL操作的原理1、join的实现原理Map Join的实现原理CommonJoinResolver优化器Reduce Join的实现原理3、Group By的实现原理二、SQL转化为MapReduce的过程Hive是基于…

hive数据类型 、常用Linux命令
基础数据类型:
TINYINT SMALLINT INTBIGINTBOOLEAN FLOAT DOUBLE STRING BINARY TIMESTAMP DECIMAL CHAR VARCHAR DATE
复杂数据类型:
struct:和c语言中的struct类似,都可以通过“点”符号访问元素内容,例如&#x…

Hive08_分区表
一 分区表
1 概念:
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所
有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据
集。在查询时通过 WHERE 子句中的表达式选择查询…

Hive数据定义(1)
hive数据定义是hive的基础知识,所包含的知识点有:数据仓库的创建、数据仓库的查询、数据仓库的修改、数据仓库的删除、表的创建、表的删除、表的修改、内部表、外部表、分区表、桶表、表的修改、视图。本篇文章先介绍:数据仓库的创建、数据仓…
使用spark将MongoDB数据导入hive
使用spark将MongoDB数据导入hive
一、pyspark
1.1 pymongospark
代码
import json,sys
import datetime, time
import pymongo
import urllib.parse
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType127.0.0.1 27…
Flink集成Hive之Hive Catalog
流程流程:
Flink消费Kafka,逻辑处理后将实时流转换为表视图,利用HiveCataLog创建Hive表,将实时流 表insert进Hive,注意分区时间字段需要为 yyyy-MM-dd形式,否则抛出异常:java.time.format.DateTimeParseException: Text 20240111 could not be parsed 写入到hive分区表
strea…
Spark与Hive的集成与互操作
Apache Spark和Apache Hive是大数据领域中两个非常流行的工具,用于数据处理和分析。Spark提供了强大的分布式计算能力,而Hive是一个用于查询和管理大规模数据的数据仓库工具。本文将深入探讨如何在Spark中集成和与Hive进行互操作,以充分利用它…
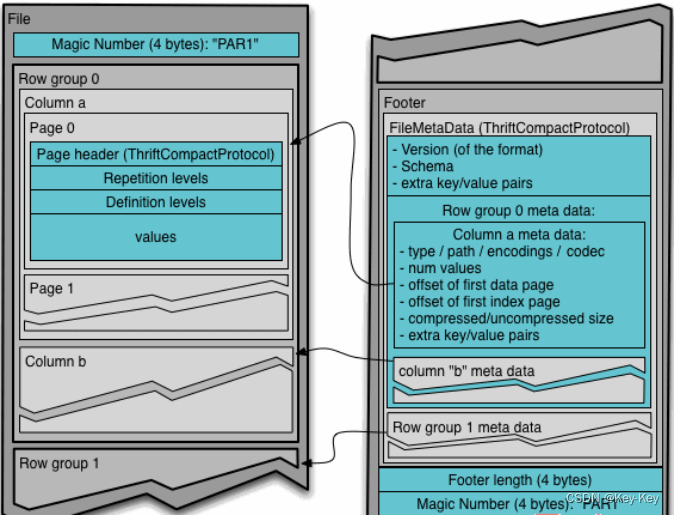
大数据开发之Hive(压缩和存储)
第 9 章:压缩和存储
Hive不会强制要求将数据转换成特定的格式才能使用。利用Hadoop的InputFormat API可以从不同数据源读取数据,使用OutputFormat API可以将数据写成不同的格式输出。 对数据进行压缩虽然会增加额外的CPU开销,但是会节约客观…

Hive映射Hbase
依赖条件
已有Hadoop、Hive、Zookeeper、HBase 环境。
为什么Hive要映射Hbase
HBase 只提供了简单的基于 Key 值的快速查询能力,没法进行大量的条件查询,对于数据分析来说,不太友好。
hive 映射 hbase 为用户提供一种 sqlOnHbase 的方法。…
SparkSQL和Hive语法差异
SparkSQL和Hive语法差异
1、仅支持Hive
SparkSQL关联条件on不支持函数rand()创建零时表时,Spark不支持直接赋值nullSpark无法读取字段类型为void的表SparkSQL中如果表达式没有指定别名,SparkSQL会将整个表达式作为别名,如果表达式中包含特殊…
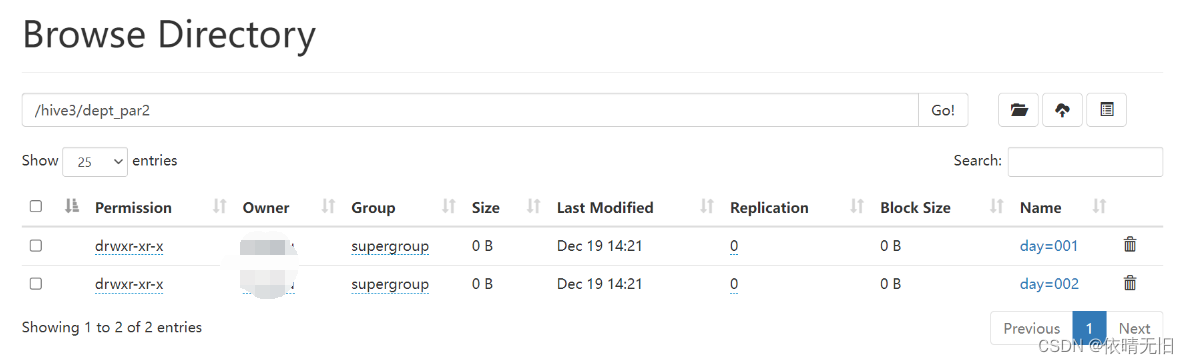
Hive基础知识(十六):Hive-SQL分区表使用与优化
1. 分区表
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过 WHERE 子句中的表达式选择查询所需要的指定的分区&…
Hive条件函数详细讲解
Hive 中的条件函数允许你在查询中基于某些条件执行逻辑操作。以下是你提到的条件函数的详细讲解,包括案例和使用注意事项: IF() 功能:根据条件返回两个表达式中的一个。语法:IF(boolean_test, value_if_true, value_if_false)案例…
大数据学习(32)hive优化方法总结
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…
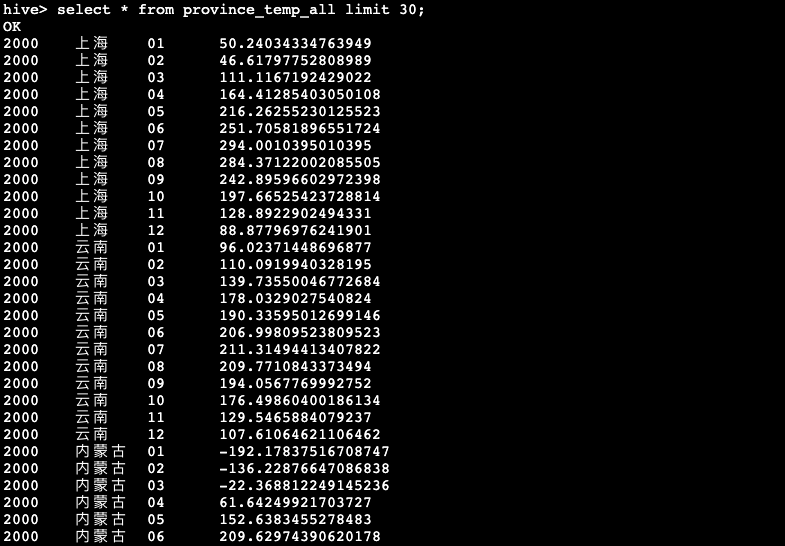
任务15:使用Hive进行全国气象数据分析
任务描述
知识点:
使用Hive进行数据分析
重 点:
掌握Hive基本语句熟练使用Hive对天气数据进行分析
内 容:
使用Hive创建外部表使用Hive对数据进行统计分析
任务指导
1. 使用Hive创建基础表
将China_stn_city.csv文件上传到HDFS的/…
Hive建表时候用的参数及其含义
1.序列化与反序列化
序列化器(Serializer)和反序列化器(Deserializer)
SerDe 是两个单词的拼写 serialized(序列化) 和 deserialized(反序列化)。 什么是序列化和反序列化呢?
当进程在进行远程通信时,彼…
Hive之set参数大全-11
设置 Map Join 操作中优化哈希表的工作集大小(working set size)
hive.mapjoin.optimized.hashtable.wbsize 是 Apache Hive 中的一个配置属性,用于设置 Map Join 操作中优化哈希表的工作集大小(working set size)。 …
Hive 数仓及数仓设计方案
数仓(Data Warehouse)
数据仓库存在的意义在于对企业的所有数据进行汇总,为企业各个部门提供一个统一、规范的出口。做数仓就是做方案,是用数据治理企业的方案。
数据仓库的特点
面向主题集成 公司中不同的部门都会去数据仓库中拿数据,把独…
数仓建设学习路线(三)元数据管理
什么是元数据?
简单来说就是描述数据的数据,更直白来说就是描述表名、表制作者、表字段、表生命周期、表存粗等信息的数据 元数据该如何管理
工具化 开源: 可通过atlas获取表依赖及信息做二次开发,或者完成可视化界面 平台化&am…
hive - explode 用法以及练习
hive explode 的用法以及练习
一行变多行 explode 例如: 临时表 temp_table ,列名为1st
1st1,2,34,5,6
变为 1 2 3 4 5 6 方式一:直接使用 explode
select explode(split(1st,,)) from temp_table;方式二:使用 lateral view…

Windows下hive中insert语句报错
报错信息
我的hadoop和hive版本都是3.0版本(建议hadoop3.x版本、hive2.x版本,我在使用中发现有些问题)
[08S01][2] Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask解决过程 1.查看…
Hive之set参数大全-15
指定 HiveServer2 使用的认证方式
hive.server2.authentication 是 Hive 中的一个参数,用于指定 HiveServer2 使用的认证方式。该参数决定了 HiveServer2 如何进行用户身份验证。
以下是设置 hive.server2.authentication 参数的一般规则:
SET hive.s…
[hive] 在hive sql中定义变量
在Hive SQL中,可以使用SET命令来定义变量。
变量可以用于存储和引用常量或表达式的值,以便在查询中重复使用。
下面是定义和使用变量的示例:
-- 定义一个变量
SET my_var Hello, World!;-- 在查询中使用变量
SELECT * FROM my_table WHER…
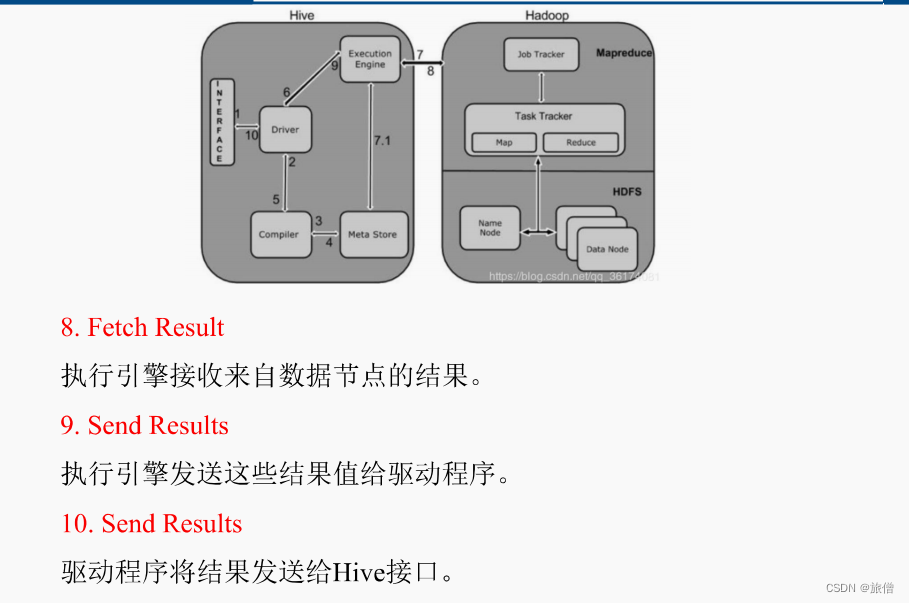
Hive底层如何和数据库进行交互
Hive
hive是hadoop底层用于管理和查询结构化数据的系统。
hive的功能实现是由HDFSMapreduce结合起来使用的。
hive支持类SQL的查询语言
驱动器和编译器
驱动器收到HiveQL之后会唤醒编译器,编译器将这个声明翻译成一个由Mapreduce组成的有向无环图的计划。 文件…

【Hive】——DQL
1 SELECT
1.1 语法
从哪里查询取决于FROM关键字后面的table_reference。可以是普通物理表、视图、join结果或子查询结果。
[WITH CommonTableExpression (, CommonTableExpression)*]
SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE wh…

被我们忽略的HttpSession线程安全问题
1. 背景
最近在读《Java concurrency in practice》(Java并发实战),其中1.4节提到了Java web的线程安全问题时有如下一段话:
Servlets and JPSs, as well as servlet filters and objects stored in scoped containers like ServletContext and HttpSe…
【hive】相关性函数进行相关性分析
文章目录 CORRCOVAR_POPCOVAR_SAMPSTDDEV_POPSTDDEV_SAMP 在Hive SQL中,使用类似的相关性函数进行相关性分析。常见的相关性函数包括CORR、COVAR_POP、COVAR_SAMP、STDDEV_POP、STDDEV_SAMP等。
CORR
举个例子,假设有一个表格sales,其中包含…
HIVE的数据类型-整型
1、HIVE的数据类型-整型
本次调试用到的hive数据类型:
TINYINT — 微整型,1字节的有符号位整数-128-127。
SMALLINT– 小整型,2个字节的有符号整数,-32768-32767。
INT– 4个字节的带符号整数
BIGINT– 8字节的带符号整数 …
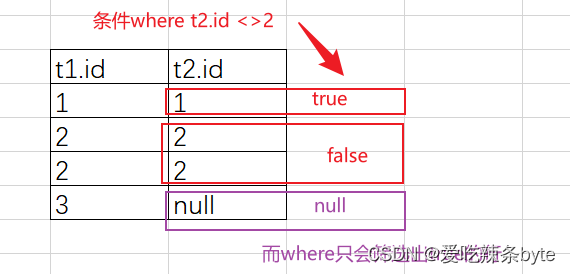
sql指南之null值用法
注明:参考文章:
SQL避坑指南之NULL值知多少?_select null as-CSDN博客文章浏览阅读2.9k次,点赞7次,收藏21次。0 引言 SQL NULL(UNKNOW)是用来代表缺失值的术语,在表中的NULL值是显示…
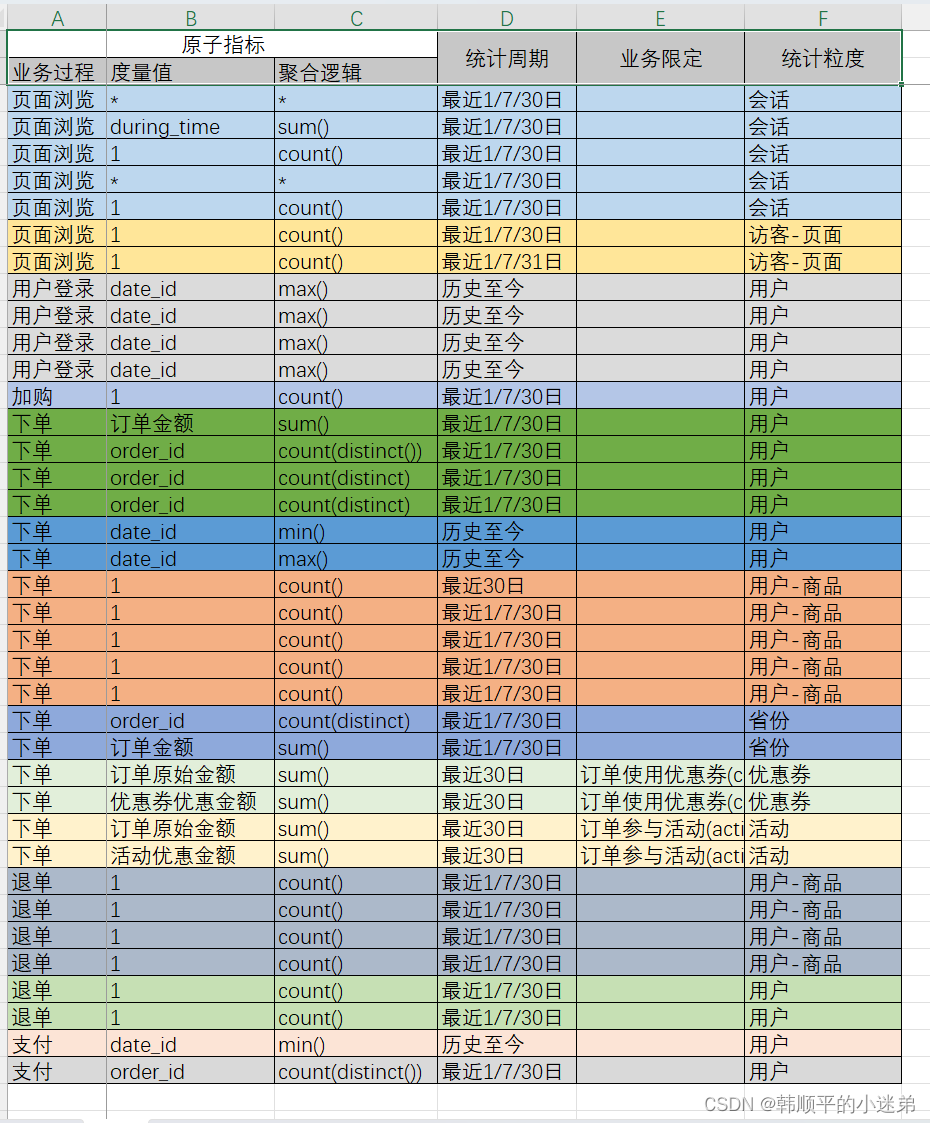
数仓建模维度建模理论知识
0. 思维导图 第 1 章 数据仓库概述
1.1 数据仓库概述 数据仓库是一个为数据分析而设计的企业级数据管理系统。数据仓库可集中、整合多个信息源的大量数据,借助数据仓库的分析能力,企业可从数据中获得宝贵的信息进而改进决策。同时,随着时间的…
Fink CDC数据同步(三)Flink集成Hive
1 目的
持久化元数据
Flink利用Hive的MetaStore作为持久化的Catalog,我们可通过HiveCatalog将不同会话中的 Flink元数据存储到Hive Metastore 中。
利用 Flink 来读写 Hive 的表
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据…

大数据环境搭建(一)-Hive
1 hive介绍
由Facebook开源的,用于解决海量结构化日志的数据统计的项目
本质上是将HQL转化为MapReduce、Tez、Spark等程序
Hive表的数据是HDFS上的目录和文件
Hive元数据 metastore,包含Hive表的数据库、表名、列、分区、表类型、表所在目录等。
根据Hive部署模…
Hive与PrestoSQL中的并列列转行
并列列转行 1、背景描述2、Hive实现3、PrestoSQL实现 1、背景描述 通常我们在处理数据时,如果遇到一个字段存储多个值,常常需要把一行数据转换为多行数据,形成标准的结构化数据
例如,将下面的两列数据并列转换为三行,…
hive 创建表 字段类型
hive 创建表 字段类型 在Hive中创建表时可以指定不同的字段类型。常见的字段类型包括:
数值类型(Numeric Types):
TINYINT:8位有符号整数
SMALLINT:16位有符号整数
INT:32位有符号整数
BIG…
(13)Hive调优——动态分区导致的小文件问题
前言 动态分区指的是:分区的字段值是基于查询结果自动推断出来的,核心语法就是insertselect。 具体内容指路文章:
https://blog.csdn.net/SHWAITME/article/details/136111924?spm1001.2014.3001.5501文章浏览阅读483次,点赞15次…
Hive 存储与压缩
文章目录存储格式行存储与列存储存储格式解析TextFile 格式ORC 格式Parquet 格式存储效率对比TextFile 格式ORC 格式(推荐)Parquet 格式对比压缩ORC —— ZLIB 压缩ORC —— SNAPPY 压缩Parquet —— GZIP 压缩Parquet —— SNAPPY 压缩总结本文中用到的…
Hive---浅谈Hive
浅谈Hive 文章目录浅谈HiveHive文件映射Hive组件元数据(Metadata)元数据存储元数据服务(Metastore)Metastore配置方式Metastore远程模式Hive启动方式第一种(本地)第二种beelineHive
Apache Hive作为一款大…
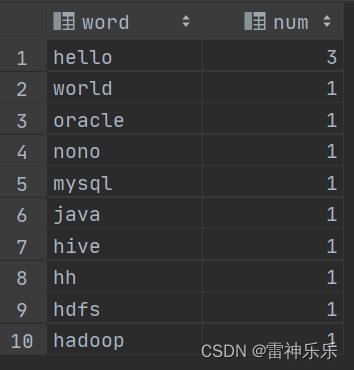
Hive学习——分桶抽样、侧视图与炸裂函数搭配、hive实现WordCount
目录
一、分桶抽样
1.抽取表中10%的数据
2.抽取表中30%的数据
3.取第一行
4.取第10行
5.数据块抽样
6.tablesample详解
二、UDTF——表生成函数
1.explode()——炸裂函数
2.posexpolde()——只能对array进行炸裂
3.inline()——炸裂结构体数组
三、UDTF与侧视图的搭…
Hive SQL 执行计划
我们在写Hive SQL的时候,难免会在运行的时候有报错,所以知道Hive SQL的执行计划具体是什么,然后假如在之后的运行过程中有报错,可以根据执行计划定位问题,调试自己的SQL开发脚本。
一、含义
Hive SQL的执行计划描述S…
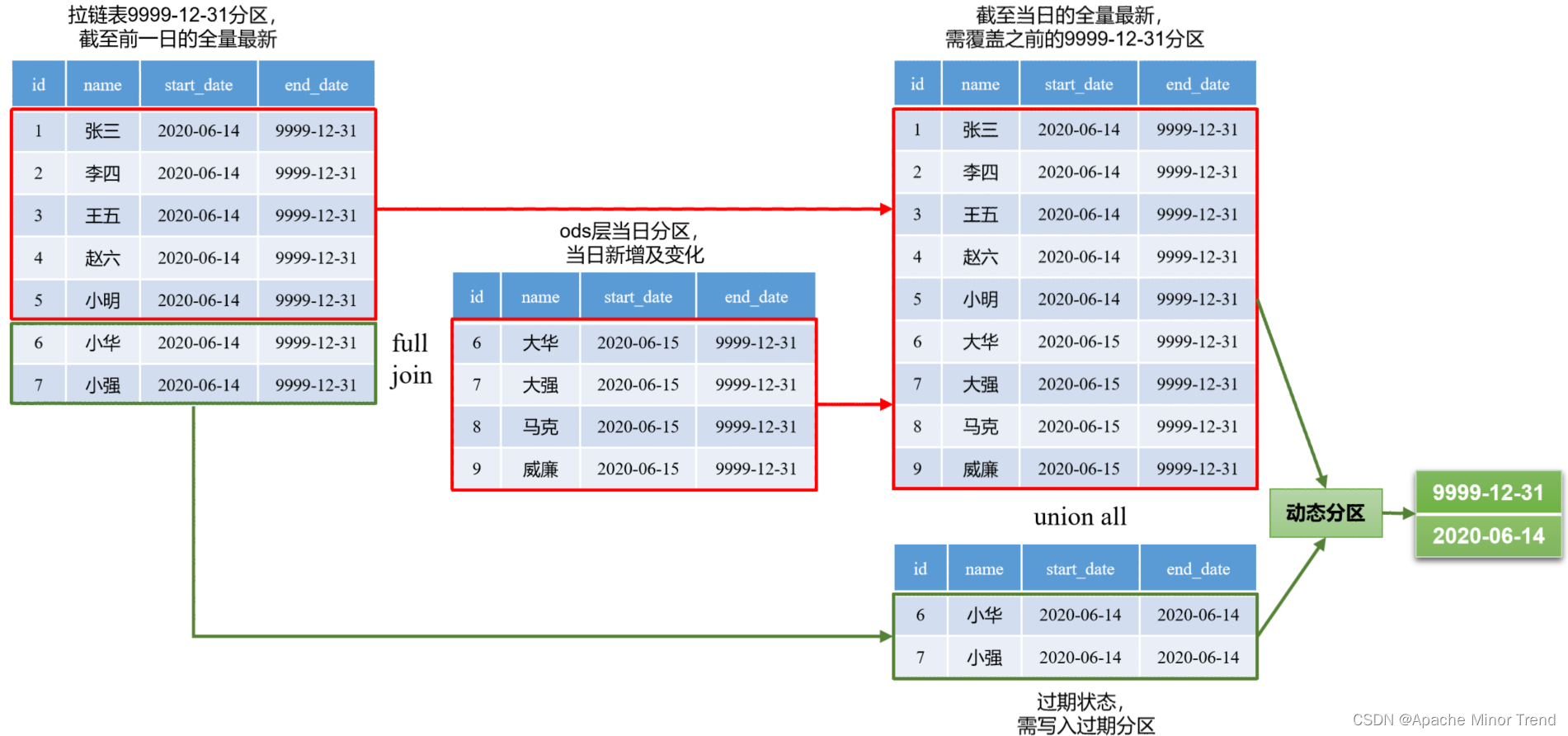
【离线数仓-7-数据仓库开发DIM层设计要点-拉链表同步装载脚本】
离线数仓-7-数据仓库开发DIM层设计要点-拉链表同步&装载脚本离线数仓-7-数据仓库开发DIM层设计要点-拉链表同步&装载脚本一、DIM层 维度模型 设计要点6.用户维度表 -拉链表1.用户维度表 前期梳理2.分析与之关联的每个表格中的具体字段,抽离出来“用户维度表…

hive解析json字段
1、get_json_object
格式:get_json_object(待解析的字段,‘.$要取的属性’)
eg:待解析的字符串: {“code”:“0001”,“dept”:“市场部”},分别获取code 和dept
select get_json_object({"code":"…

Hive中的基础函数(一)
一、hive中的内置函数根据应用归类整体可以分为8大种类型。
1、 String Functions 字符串函数 主要针对字符串数据类型进行操作,比如下面这些:
字符串长度函数:length
•字符串反转函数:reverse
•字符串连接函数:…

Hive中的高阶函数(二)
1、UDTF之explode函数 explode(array)将array列表里的每个元素生成一行; explode(map)将map里的每一对元素作为一行,其中key为一列,value为一列; 一般情况下,explode函数可以直接使用即可,也可以根据需要结…
Spark SQL整合Hive与concat有关的三个函数concat(),concat_ws(),group_concat() 笔记
Spark SQL整合Hive
1、拷贝Hive conf文件夹中的 hive-site.xml 文件夹到 spark的conf下(配置需要与资料中的文件保持一致!)
2、将Hadoop etc/hadoop文件夹中的 hdfs-site.xml、core-site.xml 拷贝到spark的conf下
3、确保 spark-env.sh 中配置了HADOOP_CONF_DIR …
Hive---窗口函数
Hive窗口函数
其他函数: Hive—Hive函数 文章目录Hive窗口函数开窗数据准备建表导入数据聚合函数window子句LAG(col,n,default_val) 往前第 n 行数据LEAD(col,n, default_val) 往后第 n 行数据ROW_NUMBER() 会根据顺序计算RANK() 排序相同时会重复,总数不会变DENSE…
【大数据】Hive系列之- Hive-分区表(静态分区和动态分区)
分区表分区表分区表基本操作创建分区表语法加载数据到分区表中准备数据加载数据增加分区创建单个分区同时创建多个分区删除分区删除单个分区同时删除多个分区查看分区表有多少分区查看分区表结构二级分区创建二级分区表正常的加载数据加载数据到二级分区表中查询分区数据把数据…
SparkSQL-SparkOneHive
部署
连接Hive操作
小试牛刀:Hive版本的WordCount
从MySQL中读取数据存储到hive中 部署 1、Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下 2、把 Mysql 的驱动 copy 到 jars/目录下 3、 如果访问不到 hdfs,则需要把 core-site.xml 和…

Hive实战篇-动态分区导致小文件过多
一、问题描述
为了支撑相应的业务需求,本次生产环境通过Hive SQL来完成动态插入分区表数据的脚本开发。但是,动态分区的插入往往会伴随产生大量的小文件的发生。而小文件产生过多的影响主要分为以下两种情况: (1) 从H…

Hive 流量分析(含维度和不含维度计算)
流量分析: 指标:PV,UV,访问次数,平均访问时长,人均访问次数、人均访问深度,人均访问时长,回头客占比等... 维度:时间维度,地域维度,设备维度等... pageview:页面浏览事件…

黑马在线教育数仓实战3
3.4 访问咨询主题看板_建模操作
思考: 在创建表的时候, 需要考虑那些问题呢? 1) 表需要采用什么存储格式 2) 表需要采用什么压缩格式 3) 表需要构建什么类型表 3.4.1 数据存储格式和压缩方案
存储格式选择: 情况一: 如果数据不是来源于普通文本文件的数据, 一般存储格式…
【学习记录】大数据课程-学习十四周总结
Hive一键启动脚本
这里,我们写一个expect脚本,可以一键启动beenline,并登录到hive。expect是建立在tcl基础上的一个自动化交互套件, 在一些需要交互输入指令的场景下, 可通过脚本设置自动进行交互通信。 3.4.1.安装expect yum -y install ex…
Hive 事务和锁的功能测试
Hive 事务和锁的功能测试
Hive 的事务和锁,可以在会话级别设置。
1. 无事务、无锁的方式
各云厂商,如阿里云,百度云默认都采用此方案。如果不使用此方案,用户需要手动改配置。 此方案读写表都没有限制。任务的执行时间可以估计…
[hive SQL] 预约业务线
这两天有个数据需求,记录一下。 原始需求说明产品写得很乱不清晰确认了半天无语死了(开始骂人),直接列转换后的问题了 问题1: 现有一张办事预约服务记录表reservation_order,包含字段用户id、服务名称、服务…
Hive UDTF、窗口函数、自定义函数
目录
1 UDTF
1.1 概述
1.2 explode
1.3 posexplode
1.4 inline
1.5 Lateral View
2 窗口函数(开窗函数)
2.1 定义
2.2 语法
2.2.1 语法--函数
2.2.2 语法--窗口 2.2.3 常用窗口函数
3 自定义函数
3.1 基本知识
3.2 实现自定义函数
3.2.1 …
hive常用函数整理
关于日期datediff(date1, date2)返回date1与data2之间的天数;date_sub(start_day, num_days)返回start_day前num_days的日期;timestampdiff(): timestampdiff(year|month|day|hour|minute|second,date1,date2)#对于比较的两个时间…
Hive 拉链表的两种实现方式
目录 1.什么是拉链表
2.拉链表的产生背景
2.1数据同步
2.1.1全量同步
2.1.2增量同步
2.2增量同步和拉链表
3.拉链表的实现方式
3.1数据准备
3.2思路1
3.3思路2 1.什么是拉链表
我们首先要知道,拉链表是一个逻辑上的概念。
拉链表记录的是增量数据&#x…
Hive自定义udf函数
1.继承UDF类 2.重写evaluate方法 3.把项目打成jar包 4.hive中执行命令add jar /home/jrjt/dwetl/PUB/UDF/udf/GetProperty.jar; 5.创建函数create temporary function get_pro as jd.Get_Property//jd.jd.Get_Property为类路径; 自带函数 1. 字符串长度函数:…
[Hadoop实现Springboot之HDFS数据查询和插入 ]
目录
🎃前言:
🎃Spring Boot项目中添加Hadoop和HDFS的依赖。可以使用Apache Hadoop的Java API或者使用Spring Hadoop来简化操作。
🎃 需要配置Hadoop和HDFS的连接信息,包括Hadoop的配置文件和HDFS的连接地址等。
Ἰ…
大数据之Hive(二)
文章目录前言一、Hive数据库和表操作(一)数据库操作1. 创建数据库2. 删除数据库(二)数据表操作1. 内部表和外部表的操作1.1 内部表操作1.2 外部表操作2. 复杂类型操作2.1 Array类型2.2 map类型2.3 struct类型前言
#博学谷IT学习技…
[Sqoop 安装配置]
目录
🍗前言:
🍗 下载地址:
🍗首先需要有Java环境,确定是否安装Java和Hadoop
🍗压缩包解压指令:
#重命名sqoop目录[roothadoop01 local]#mv sqoop-1.4.7 sqoop 修改文件名称
🍗配置环境变量:
🍗刷…
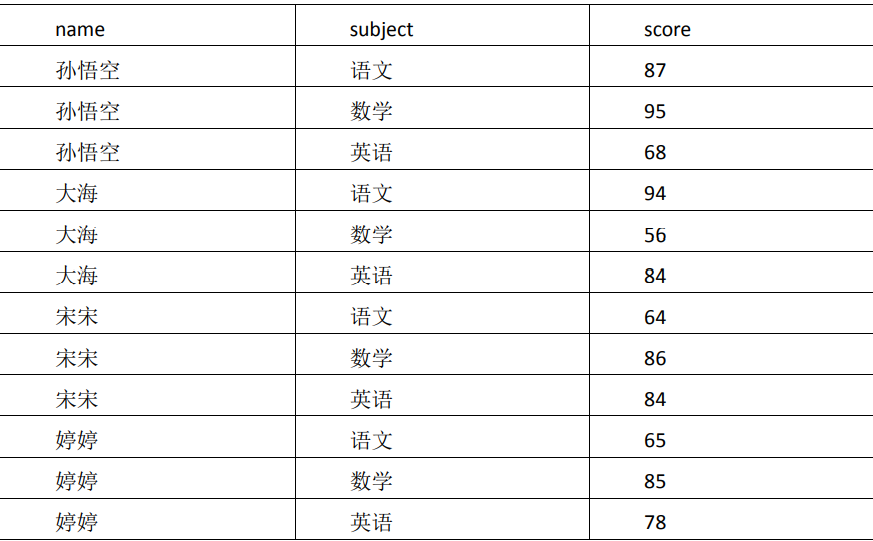

Hive——Hive常用内置函数总结
✅作者简介:最近接触到大数据方向的程序员,刚入行的小白一枚 🍊作者博客主页:皮皮皮皮皮皮皮卡乒的博客 🍋当前专栏:Hive学习进阶之旅 🍒研究方向:大数据方向,数据汇聚&a…

IDEA Windows下SPARK连接Hive
IDEA Windows下SPARK连接Hive 文章目录IDEA Windows下SPARK连接Hive一、本地Windows环境配置二、IDEA项目配置1. POM配置2. 资源文件配置3. 测试验证一、本地Windows环境配置
本地构建HADOOP客户端
将大数据平台的HAODOP环境打包拿到本地环境来:
#压缩整个HADOOP…

☀️☀️基于Spark、Hive等框架的集群式大数据分析流程详述
本文目录如下:基于Spark、Hive等框架的集群式大数据分析流程详述第1章 淘宝双11大数据分析—数据准备1.1 数据文件准备1.2 数据预处理1.3 启动集群环境1.4 导入数据到 Hive 中1.4.1 把目标文件上传到 HDFS 中1.4.2 将数据导入至 Hive 中第2章 淘宝双11大数据分析—H…
1.Spark 学习成果转化—德国人贷款情况分析—各职业人群贷款目的Top3
本文目录如下:第1例 德国贷款群体情况分析1.1 数据准备1.1.1 数据库表准备1.1.2 数据库表字段解释1.1.3 在 IDEA 中 创建数据库表 并 导入数据1.2 需求1:各职业人群贷款目的Top31.2.1 需求简介1.2.2 需求分析1.2.3 功能实现注: Spark 学习成果转化中系列…
Hive基础之:hive数据倾斜原因及解决方案
hive数据倾斜产生的原因
数据倾斜的原因很大部分是join倾斜和聚合倾斜两大类
一、Hive倾斜之group by聚合倾斜
原因: 分组的维度过少,每个维度的值过多,导致处理某值的reduce耗时很久; 对一些类型统计的时候某种类型的数据量特…

Hive基础之:Order By、Sort By、distribute by 、cluster by的区别
Order By
order by 排序出来的数据是全局有序的,在hive mr引擎中将会只有1个reduce
Sort By
sort by 排序出来的数据是局部有序的,但是全局无序。即partition内部是有序的,但是partition与partition之间的数据是没有顺序关系的
distrib…
HIVE的安装及基础操作
前提:成功搭建Hadoop集群 实验要求:搭建基本hive运行平台,并初步了解HIVE shell的基本操作命令 MySQL版本:mysql-5.7.16-1.el7.x86_64.rpm-bundle.tar Hive版本:apache-hive-1.2.2-bin.tar.gz 链接: https://pan.baid…
大数据Storm相比于Spark、Hadoop有哪些优势
摘要: 一、可能很多初学大数据的伙伴不知道strom是什么,先给大家介绍一下strom:分布式实时计算系统,storm对于实时计算的意义类似于hadoop对于批处理的意义。
一、可能很多初学大数据的伙伴不知道strom是什么,先给大家…

集群搭建--搭建spark集群集成hive
下载 spark-2.4.0-bin-hadoop2.7.tgz
链接:https://pan.baidu.com/s/1dlZlEcvwPck1JpSdBbXyYw 提取码:3y22
解压 spark-2.4.0-bin-hadoop2.7.tgz
[hadoopspark1 softwares]$ tar spark-2.4.0-bin-hadoop2.7.tgz -C /usr/local/modules/
cd /…
在hadoop上搭建hive环境
目录一、下载安装包并解压二、配置环境变量三、安装Mysql四、配置hive-site.xml五、配置hive-env.sh六、初始化数据库并启动hive七、启动和停止脚本七、问题记录一、下载安装包并解压
在官网下载最新版的hive包,apache-hive-3.1.3-bin.tar.gz,并进行解压
tar -zvx…
beeline的使用方法以及导出csv需要注意的问题
文章目录概述参数示例注意问题概述
最近需要导出hive的数据到clickhouse,但是由于某些原因使用不了datax,只有使用beeline导出数据csv,在写入clickhouse。
Beeline是Hive新的命令行客户端工具,是从 Hive 0.11版本引入的。
参数…
3、Hive安装部署
1)把apache-hive-3.1.2-bin.tar.gz上传到linux的/opt/software目录下
链接: 百度网盘 请输入提取码 提取码: yded
2)解压apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面
[shuidihadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.…
hive not in
当前HIVE 不支持 not in 中包含查询子句的语法,形如如下的HQ语句是不被支持的: 查询在key字段在a表中,但不在b表中的数据 Sql代码 select a.key from a where key not in(select key from b) 可以通过left outer join进行查询,(假设B表中包…
hive与hbase安装
单独安装hive使用Derby数据库的安装方式什么是Derby安装方式•Apache Derby是一个完全用java编写的数据库,所以可以跨平台,但需要在JVM中运行•Derby是一个Open source的产品,基于Apache License 2.0分发•即将元数据存储在Derby数据库中&…
hbase,hive报错:NoRouteToHostException: No route to host
今天早上打开ClouderaManager集群发现HBase和Hive的服务都报错了,有问题就解决吧 先看下HBase的错误日志, HBase的报错:
Session 0x0 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.NoR…
DataGrip 配置 HiveServer2 远程连接访问
文章目录 集群配置 HiveServer2 服务DataGrip 配置 HiveServer2 访问 Hive 集群配置 HiveServer2 服务
1.在 Hive 的配置文件 hive-site.xml 中添加如下参数: <!-- 指定 HiveServer2 运行端口,默认为:10000 --><property><na…
Hadoop Hbase Hive 版本对照一览
这里写目录标题 一、Hadoop 与 Hbase 版本对照二、Hadoop 与 Hive 版本对照 官网内容记录,仅供参考 一、Hadoop 与 Hbase 版本对照 二、Hadoop 与 Hive 版本对照
Spark操作Hive表幂等性探索
前言
旁边的实习生一边敲着键盘一边很不开心的说:做数据开发真麻烦,数据bug排查太繁琐了,我今天数据跑的有问题,等我处理完问题重新跑了代码,发现报表的数据很多重复,准备全部删了重新跑。
我:你的数据操作具备幂等性吗?
实习生:啥是幂等性?数仓中的表还要考虑幂等…
Hive报错:FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
Hive报错,主要错误信息:
java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask 原因分析:
Hive sql语句过长,并在sql中调用自…
在 docker 中快速启动 Apache Hive
介绍
在伪分布式模式下,在Docker容器内运行Apache Hive,可以提供以下功能:快速启动/调试/为Hive准备测试环境。
快速开始
1. 拉取镜像
从DockerHub:https://hub.docker.com/r/apache/hive/tags中拉取镜像。目前发布了3个镜像&…
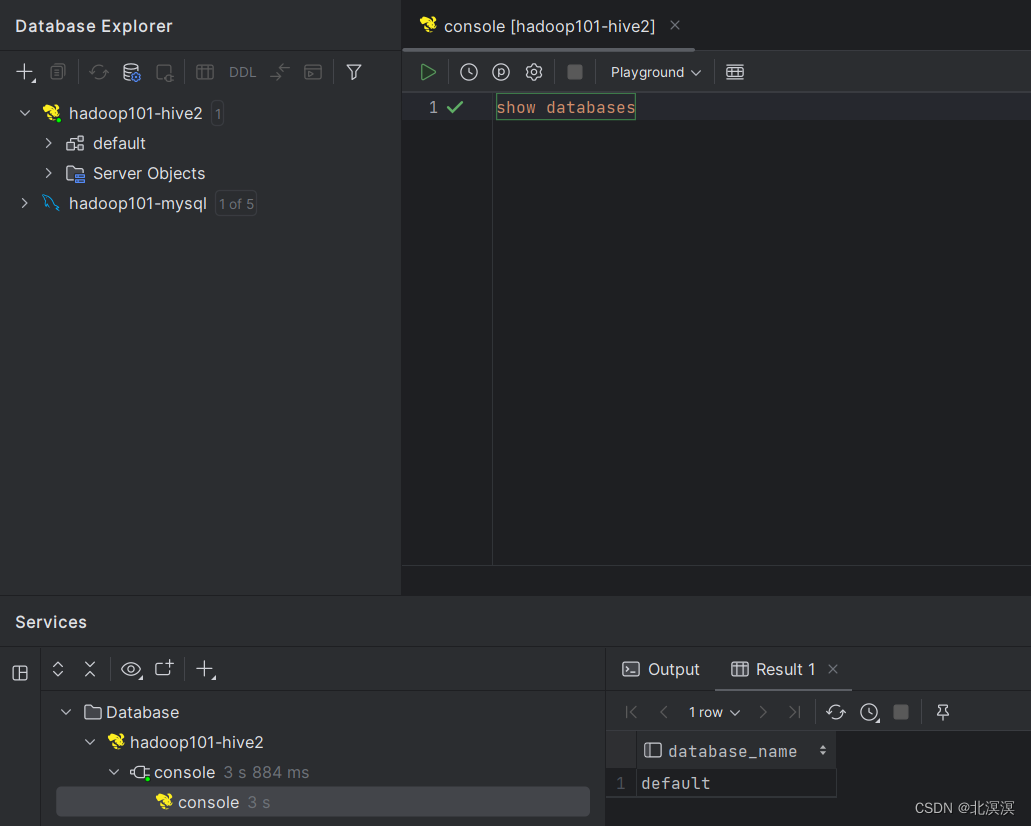
(十八)大数据实战——Hive的metastore元数据服务安装
前言
Hive的metastore服务作用是为Hive CLI或者Hiveserver2提供元数据访问接口。Hive的metastore 是Hive元数据的存储和管理组件,它负责管理 Hive 表、分区、列等元数据信息。元数据是描述数据的数据,它包含了关于表结构、存储位置、数据类型等信息。本…
HIVE SQL实现分组字符串拼接concat
在Mysql中可以通过group_concat()函数实现分组字符串拼接,在HIVE SQL中可以使用concat_ws()collect_set()/collect_list()函数实现相同的效果。 实例:
abc2014B92015A82014A102015B72014B6
1.concat_wscollect_list 非去重拼接
select a ,concat_ws(-…
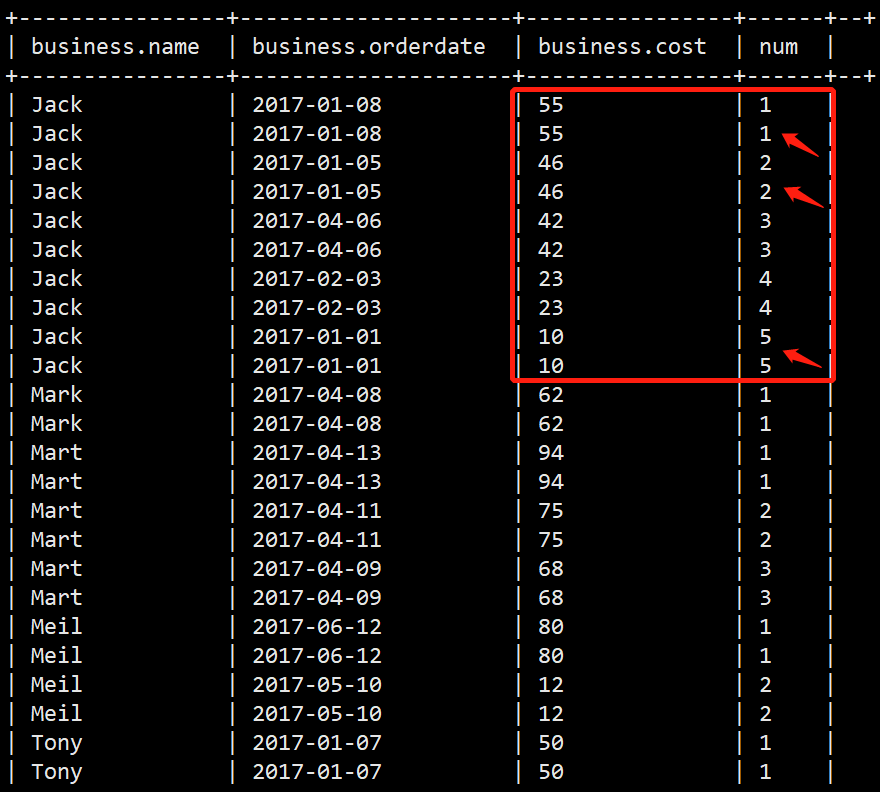
【hive】hive中row_number() rank() dense_rank()的用法
hive中row_number() rank() dense_rank()的用法
一、函数说明
主要是配合over()窗口函数来使用的,通过over(partition by order by )来反映统计值的记录。
rank() over()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)dense_rank() …

【hive】hive分桶表的学习
hive分桶表的学习
前言:
每一个表或者分区,hive都可以进一步组织成桶,桶是更细粒度的数据划分,他本质不会改变表或分区的目录组织方式,他会改变数据在文件中的分布方式。
分桶规则:
对分桶字段值进行哈…
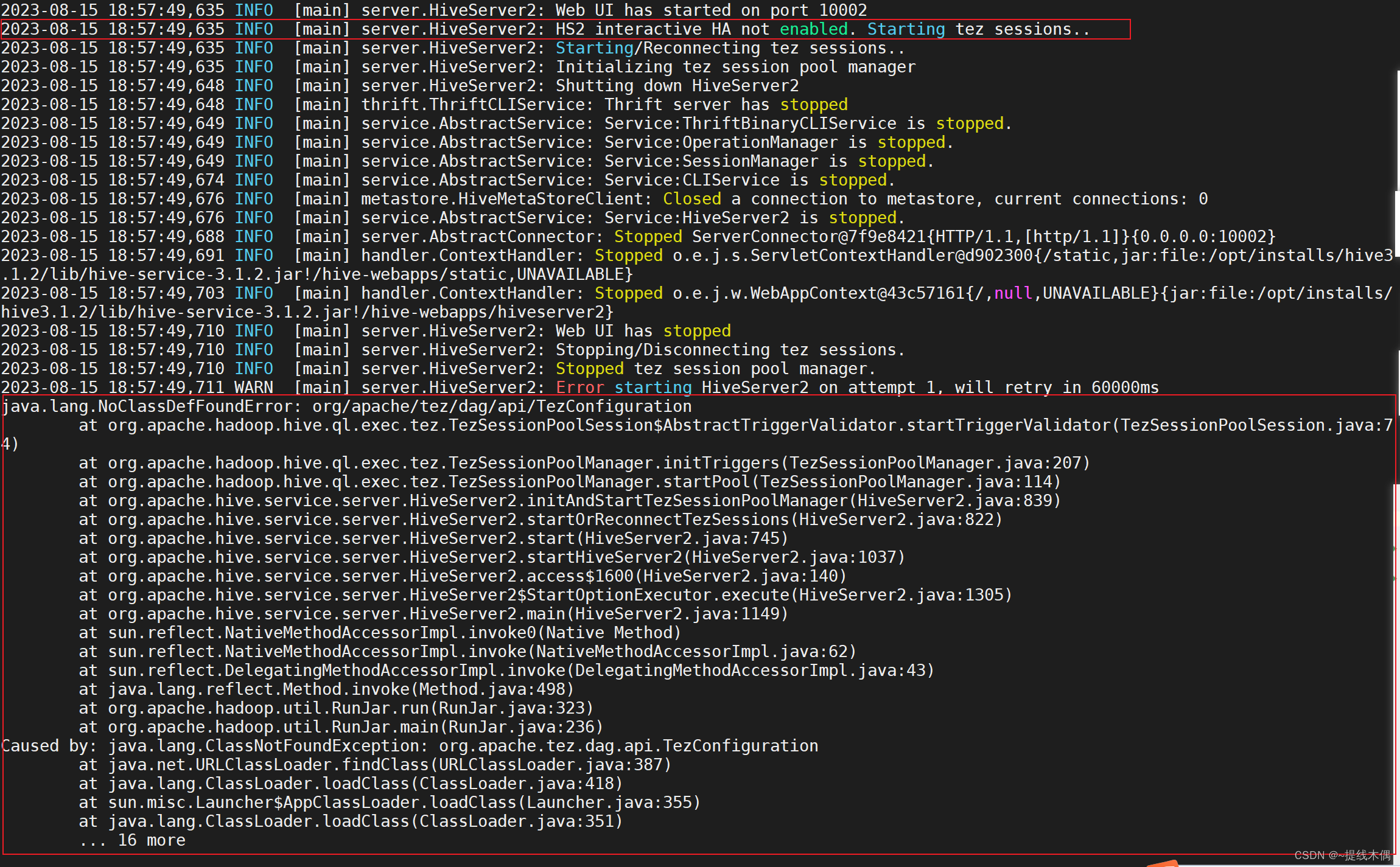
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfiguration
错误:
java.lang.NoClassDefFoundError: org/apache/tez/dag/api/TezConfigurationat org.apache.hadoop.hive.ql.exec.tez.TezSessionPoolSession$AbstractTriggerValidator.startTriggerValidator(TezSessionPoolSession.java:74)at org.apache.hadoop.hive.ql.e…
Hive的窗口函数与行列转换函数及JSON解析函数
1. 系统内置函数
查看系统内置函数:show functions ; 显示内置函数的用法: desc function lag; – lag为函数名 显示详细的内置函数用法: desc function extended lag;
1.1 行转列
行转列是指多行数据转换为一个列的字段。
Hive行转列用到的函数 con…
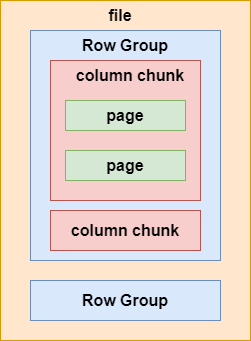
Hive底层数据存储格式
前言
在大数据领域,Hive是一种常用的数据仓库工具,用于管理和处理大规模数据集。Hive底层支持多种数据存储格式,这些格式对于数据存储、查询性能和压缩效率等方面有不同的优缺点。本文将介绍Hive底层的三种主要数据存储格式:文本文件格式、Parquet格式和ORC格式。
一、三…
【hive】hive修复分区或修复表 以及msck命令的使用
【hive】hive修复分区或修复表 以及msck命令的使用 文章目录 【hive】hive修复分区或修复表 以及msck命令的使用问题原因:解决方法:msck命令解析:例子: 问题原因:
之前hive里有数据,后面存储元数据信息的MySQL数据库坏…

hive local mr转
在hive中运行的sql有很多是比较小的sql,数据量小,计算量小.这些比较小的sql如果也采用分布式的方式来执行,那么是得不偿失的.因为sql真正执行的时间可能只有10秒,但是分布式任务的生成得其他过程的执行可能要1分钟.这样的小任务更适合采用lcoal mr的方式来执行.就是在本地来执行…

Spark、Hive、Hbase比较
1.spark
spark是一个数据分析、计算引擎,本身不负责存储;可以对接多种数据源,包括:结构化、半结构化、非结构化的数据;其分析处理数据的方式有多种发,包括:sql、Java、Scala、python、R等&…
hadoop 排序优化
转:http://blog.csdn.net/wf1982/article/details/7369324 hive 全排序优化 全排序 Hive的排序关键字是SORT BY,它有意区别于传统数据库的ORDER BY也是为了强调两者的区别–SORT BY只能在单机范围内排序。考虑以下表定义: CREATE TABLE if no…
HIVE 第八章 schema
schema设计 hive pattern && hive anti-pattern 1.Table by day 按照天分割数据,在relation中,这个参数不推荐,在hive中使用 create table supply(id int,part string,quantity int) partitioned by (int day) alter table supply ad…

Hive 之SQL优化技巧与实践
一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,Reduce,Spill,Shuffle,Sort等多个阶段,所以针对Hive查询的优化可以大致分为针对MR中单个步骤的优化(其中又会有细分)…
HIVE 第六章 视图
第七章 试图 view1 create view shorter_join as select * from people join cart on(cart.people_idpeople.id) where firstnamedirk select lastname from shorter_join where id3 view2 create view if not exists shipments(time,part) comment time and parts for shipmen…

Hive第一章--基本概念
1.1什么是hive
hive是基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 本质是将HQL转化为MapReduce程序。本质是将HQL转化为MapReduce程序。本质是将HQL转化为MapReduce程序。
为什么说hive是基于Hadoop的工具呢&…
hive中如何将存在分隔符号的一列进行拆分,成为多行(可参考之前行转列,列转行笔记第三部分)
hive中如何将存在分隔符号的一列进行拆分,成为多行(可参考之前行转列,列转行笔记第三部分)
三、行转列 split()︰将一个字符串按照指定字符分割,结果为一个array explode():将一列复杂的array或者map拆分为多行,它的参…
IMPALA跟HIVE实践中的小绝招
# impala提升查询速度
compute stats tableName;
# 查看分区情况
show partitions tableName;
# 建分区表
create table tableName (字段) partitioned by (labs_etl_dt string);
# 向分区表里插数据
insert overwrite table tableName partition(labs_etl_dt)
# 将一列中多个元…

hivesql--窗口函数
hivesql–窗口函数 xmind获取地址:https://pan.baidu.com/s/15hegE_7LpWfKLrOVDBIs1w 提取码:skux
补充:
一、分组排序后
first_value(colname) over(partition by … order by …):分组排序后第一行last_value(colname) over(partition b…
最系统的大数据技术盘点,学会一半就是数据大牛
说起大数据,很多人都能聊上一会,但要是问大数据核心技术有哪些,估计很多人就说不上一二来了。
从机器学习到数据可视化,大数据发展至今已经拥有了一套相当成熟的技术树,不同的技术层面有着不同的技术架构,…
Sqoop(二):Hive导出数据到Oracle
把Hive中的数据导入Oracle数据库。
1. 解释一下各行代码:
sqoop export
# 指定要从Hive中导出的表
--table TABLE_NAME
# host_ip:导入oracle库所在的ip:导入的数据库
--connect jdbc:oracle:thin:HOST_IP:DATABASE_NAME # oracle用户账号
--username USERNAM…
Hive SQL常用命令总结,大数据开发学习者按需收藏
Hive是基于Hadoop生态的一个重要组件,是对数据仓库进行管理和分析数据的工具。她提供了SQL查询方式来分析存储在HDFS分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。
这种SQL就是Hive SQL&…
Hive 终于等来了 Flink
等疫情过去了,我们一起看春暖花开。 Apache Spark 什么时候开始支持集成 Hive 功能?
笔者相信只要使用过 Spark 的读者,应该都会说这是很久以前的事情了。
那 Apache Flink 什么时候支持与 Hive 的集成呢?
读者可能有些疑惑&am…

通过JavaAPI访问HBase
先开始创建表
create emp001,member_id,address,info放入数据
put emp001,Rain,id,31
put emp001, Rain, info:birthday, 1990-05-01
put emp001, Rain, info:industry, architect
put emp001, Rain, info:city, ShenZhen
put emp001, Rain, info:country, China
get emp001,…
程序猿专享| 如何运用百度MapReduce分析网站日志
每天访问网站的用户都在关注什么?在网站上有哪些用户行为在不断发生?如何根据用户行为来提升网站的商业价值?网站日志包含用户日常的访问信息,通过日志分析可以了解网站的访问量、网页访问次数、网页访问人数、频繁访问时段等等&a…
利用Docker快速部署hadoop、hive和spark
文章目录一、配置文件yml1.docker-compose.yml二、执行脚本1.启动脚本run.sh2.关闭脚本stop.sh一、配置文件yml
1.docker-compose.yml
version: 3.4
services:namenode:image: test/hadoop-namenode:1.1.0-hadoop2.8-java8container_name: namenodevolumes:- ./data/namenod…

数据库优化之数据备份
文章目录写在前面一、数据备份1、mysqdump1.备份单个数据库2.备份多个数据库3.备份所有数据库4.数据恢复2、文件备份1.数据输出2.文件输入3、binlog日志1.查看binlog日志2.开始binlog日志3.查看binlog日志写在前面
最近有个学弟问我这样的问题,他的hive在mysql中映…

SparkSql 2.2.x 中 Broadcast Join的陷阱(hint不生效)
问题描述
在spark 2.2.0 的sparksql 中使用hint指定广播表,却无法进行指定广播;
前期准备
hive> select * from test.tmp_demo_small;
OK
tmp_demo_small.pas_phone tmp_demo_small.age
156 20
157 22
158 15hive> analyze table test.tmp_demo…
解决:MacOS下配置Hadoop及Hive单机遇到的问题(们)
MacOS Sierra 10.12.1 Hadoop 2.7.3 Hive 1.2.1 前言 本来安逸搞个local 的spark算了,但是过几天我还要搞个网易云音乐的大新闻,没有hive不得劲,遂装,期间遇到的问题,一一记录 安装 基础安装,先照这个来吧…
Hive的in和exists改写,半连接和反连接
Hive的In和exists效率低,可以改写成连接的方式来实现
IN、EXISTS改写为半连接或者内连接,NOT IN、NOT EXISTS改为反连接或外连接 半连接: 为了方便说明半连接的含义,这里我们用"t1.x semi= t2.y"来表示表T1和表T2做半连接,且T1是驱动表,T2是被驱动表,半连接条…

Hive数据倾斜YT
什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点 stage里面有一个task结束时间特别长,99%的时间都在这个task
分为了Mapr Reduce和Join三个阶段 如 事实表 关联 每日抽取的维表拉链表,维表中有很多重复的org_code(开链闭链)和事实表中数据关联…
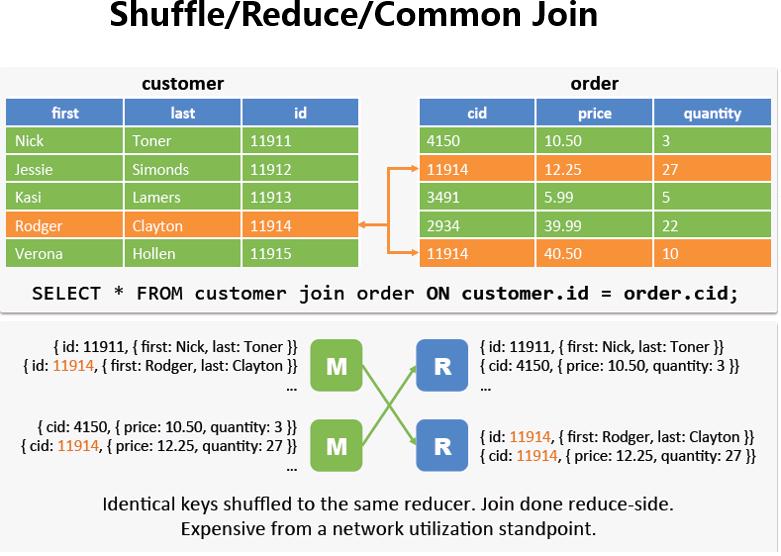
Hive的ReduceJoin/MapJoin/SMBJoin
Hive中就是把Map,Reduce的Join拿过来,通过SQL来表示。 参考链接:LanguageManual Joins - Apache Hive - Apache Software Foundation 1.Reduce /Common/Shuffle Join Reduce Join在Hive中也叫Common Join或Shuffle Join 它会进行把相同key的value合在一起,正好符合我…

Hive的partition问题
查看分区 show partitions td.pt_pmart_kk_SHIPMENT_SETL_ACCOUNT_BILL
hdfs文件按日拉过来了,但是没有数据 (可能是分区没维护要add partition,可能原数据没维护好要analyze,可能表和文件编码不一致)
将数据按partition加载进入这个表
alter table dim.fin_exp_dmn_o…
Hive(一)数据类型、文件格式和数据定义
1、基本数据类型 Hive支持多种不同长度的整型和浮点型数据类型,支持布尔类型,也支持无长度限制的字符串类型,后续的Hive增加了时间戳数据类型和二进制数组数据类型。
和其他的SQL语言一样,这些都是保留字。需要注意的是所有…
hive SQL 中的正则表达式
正则的通配符简介
^ 表示开头
$ 表示结尾
. 表示任意字符
* 表示任意多个
/ 做为转意,即通常在"/"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后//b/,转意为匹配一个单词的边界。 -或-…
(十六)大数据实战——安装使用mysql版的hive服务
前言
hive默认使用的是内嵌据库derby,Derby 是一个嵌入式数据库,可以轻松地以库的形式集成到应用程序中。它不需要独立的服务器进程,所有的数据存储在应用程序所在的文件系统中。为了支持hive服务更方便的使用,我们使用mysql数据…
CDH6.3.2搭建HIVE ON TEZ
参考 https://blog.csdn.net/ly8951677/article/details/124152987
----配置hive运行引擎 在/etc/hive/conf/hive-site.xml中修改如下: hive.execution.engine mr–>tez
hive.execution.engine 设为tez或者运行代码的时候:
set hive.execution.eng…
hive lag() 和lead()函数
LAG 和 LEAD函数简介
Hive 中的 LAG 和 LEAD 函数时,通常用于在结果集中获取同一列在前一行(LAG)或后一行(LEAD)的值。这在分析时间序列数据、计算变化率或查找趋势时非常有用。以下是这两个函数的用法示例࿱…
Servlet+JDBC实战开发书店项目讲解第11讲:管理员用户权限功能
ServletJDBC实战开发书店项目讲解第11讲:管理员用户权限功能
在这一讲中,我们将详细讲解如何实现书店项目中的管理员用户权限功能。下面是每个步骤的详细说明:
步骤一:创建管理员用户表
首先,我们需要在数据库中创建…

hive表的全关联full join用法
背景:实际开发中需要用到全关联的用法,之前没遇到过,现在记录一下。需求是找到两张表的并集。
全关联的解释如下; 下面建两张表进行测试
test_a表的数据如下 test_b表的数据如下;
写第一个full join 的SQL进行查询…
【Hive】HQL Map 『CRUD | 相关函数』
文章目录 1. Map 增删改查1.1 声明 Map 数据类型1.2 增1.3 删1.4 改1.5 查 2. Map 相关函数2.1 单个Map 3. Map 与 String3.1 Map 转 string3.2 string 转 Map 1. Map 增删改查
1.1 声明 Map 数据类型
语法:map<基本数据类型, 基本数据类型> 注意是<>…
Hive 导入csv文件,数据中包含逗号的问题
问题
今天 Hive 导入 csv 文件时,开始时建表语句如下:
CREATE TABLE IF NOT EXISTS test.student (name STRING COMMENT 姓名,age STRING COMMENT 年龄,gender STRING COMMENT 性别,other_info STRING COMMENT 其他信息
)
COMMENT 学生信息表
ROW FORM…

大数据集群需定期清理的文件(节省空间)
大数据集群需定期清理的文件(节省空间)
1.由于HDFS有回收站,如何设置不合理的话,它会长时间占用集群资源,因此我们首先清理HDFS回收站。 在平时删除HDFS文件时,可以使用命令:hdfs dfs -rm -ski…
启动metastore服务报错
启动Metastore的时候报错:
简略的报错信息: MetaException(message:Error creating transactional connection factory)Caused by: MetaException(message:Error creating transactional connection factory)Caused by: javax.jdo.JDOFatalInternalExce…
41、Flink之Hive 方言介绍及详细示例
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

说说构建流批一体准实时数仓
分析&回答
基于 Hive 的离线数仓往往是企业大数据生产系统中不可缺少的一环。Hive 数仓有很高的成熟度和稳定性,但由于它是离线的,延时很大。在一些对延时要求比较高的场景,需要另外搭建基于 Flink 的实时数仓,将链路延时降低…

4.Hive基础—DDL 数据定义—创建、查询、修改、删除数据库、创建表(重要)、修改表、删除表
本文目录如下:第4章 DDL 数据定义4.1 创建数据库4.2 查询数据库4.2.1 显示数据库4.2.2 查看数据库详情4.2.3 切换当前数据库4.3 修改数据库4.4 删除数据库4.5 创建表(重点)4.5.1 建表语法4.5.2 管理表(内部表 )4.5.2.1…

3.Hive基础—Hive 常用交互命令、其他命令操作、Hive 常见属性配置(日志、库与表信息)、Hive 数据类型
本文目录如下:2.8 Hive 常用交互命令2.8.1 “-e”不进入 hive 的交互窗口执行 sql 语句2.8.2 “-f”执行脚本中 sql 语句2.9 Hive 其他命令操作2.9.1 退出 hive 窗口2.9.2 在 hive cli 命令窗口中如何查看 hdfs 文件系统2.9.3 查看在 hive 中输入的所有历史命令2.10…

1.Hive基础—Hive简介、Linux环境下安装Hive环境、启动并使用Hive、安装MySQL、启动 与 登录 MySQL
本文目录如下:第1章 Hive 基本概念1.1 Hive 简介1.2 Hive 架构原理1.2.1 用户接口:Client1.2.2 元数据:Metastore1.2.3 Hadoop1.2.4 驱动器:Driver1.3 Hive 运行机制第2章 Hive 安装、使用、集成环境2.1 虚拟机环境准备2.2 Linux环…
win10下使用hive时遇到的错误集锦
背景
老子不知道hive在win10下怎么就这么多错.....不想用虚拟机,想换成mac,但是mac上没有实况19...真的是,我去年买了个表。 hive建表报错Column length too big for column PARAM_VALUE (max 21845); use BLOB or TEXT instead 解决方法&a…

【大数据实训】基于Hive的北京市天气系统分析报告(二)
博主介绍:✌全网粉丝6W,csdn特邀作者、博客专家、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于大数据技术领域和毕业项目实战✌ 🍅文末获取项目联系🍅 目录
1. 引言
1.1 项目背景 1
1.2 项目意义 1
2.…

0401hive入门-hadoop-大数据学习.md
文章目录 1 Hive概述2 Hive部署2.1 规划2.2 安装软件 3 Hive体验4 Hive客户端4.1 HiveServer2 服务4.2 DataGrip 5 问题集5.1 Could not open client transport with JDBC Uri 结语 1 Hive概述
Apache Hive是一个开源的数据仓库查询和分析工具,最初由Facebook开发&…
【Hive-小文件合并】Hive外部分区表利用Insert overwrite的暴力方式进行小文件合并
这里我们直接用实例来讲解,Hive外部分区表有单分区多分区的不同情况,这里我们针对不同情况进行不同的方式处理。
利用overwrite合并单独日期的小文件
1、单分区
# 开启此表达式:(sample_date)?.
set hive.support.quoted.identifiersnon…
Reactive Spring实战 -- WebFlux使用教程
ebFlux是Spring 5提供的响应式Web应用框架。 它是完全非阻塞的,可以在Netty,Undertow和Servlet 3.1等非阻塞服务器上运行。 本文主要介绍WebFlux的使用。
FluxWeb vs noFluxWeb
WebFlux是完全非阻塞的。 在FluxWeb前,我们可以使用DeferredR…
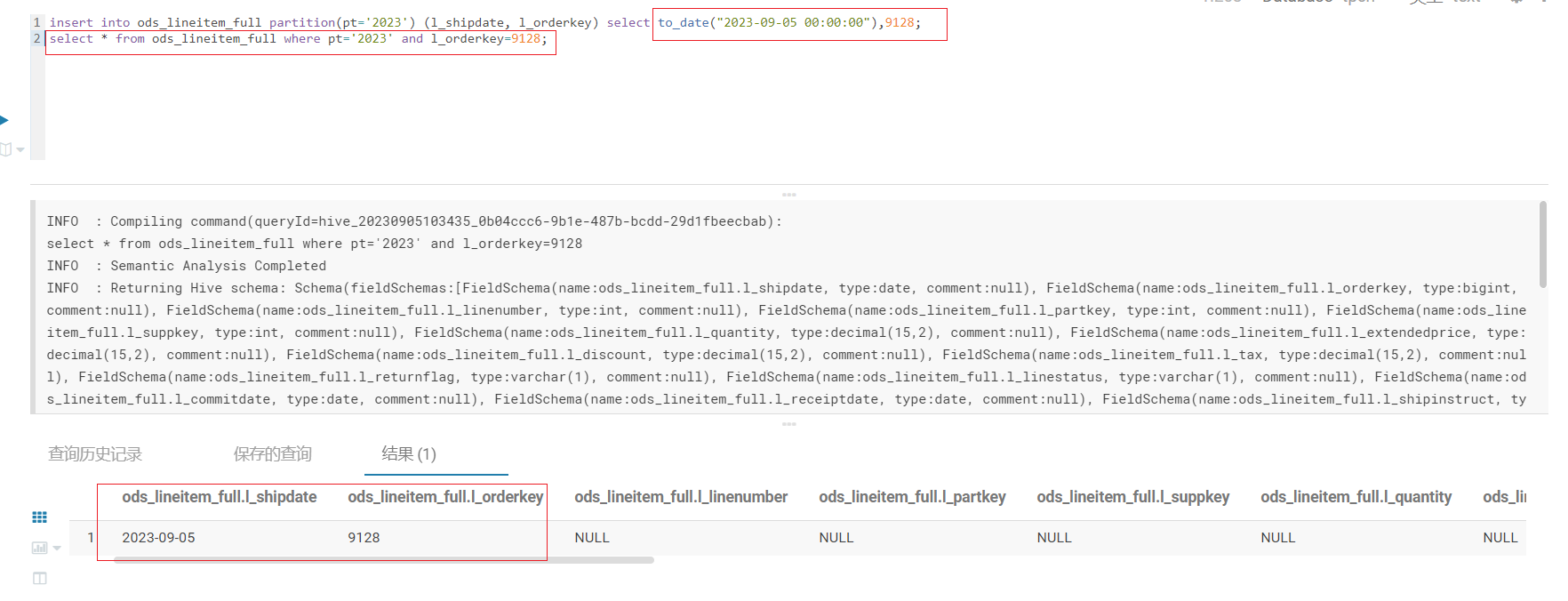
hive指定字段插入数据,包含了分区表和非分区表
1、建表
语句如下:
CREATE EXTERNAL TABLE ods_lineitem_full
(l_shipdate date,l_orderkey bigint,l_linenumber int,l_partkey int,l_suppkey int,l_quantity decimal(15, 2),l_extendedprice decimal(15, 2),l_discount de…
hadoop3.1.3 + hive3.1.2 + mysql5.7.24 + zeppelin0.8.0环境搭建
hadoop3.1.3 hive3.1.2 mysql5.7.24 zeppelin0.8.0环境搭建PRE:Hadoop部署Hive部署zeppelin部署和配置hive interpreterhive创建表导入数据PRE:
首先要有JDK环境,java1.8,配置环境变量。linux系统一般有自带openjdk࿰…
Mybatis-Plus(连接Hive)
序号类型地址1MySQLMySQL操作之概念、SQL约束(一)2MySQLMySQL操作之数据定义语言(DDL)(二)3MySQLMySQL操作之数据操作语言(DML)(三)4MySQLMySQL操作之数据查询语言:(DQL)…
二次开发seatunnel/waterdrop实现在filter中正则替换所有列
1.背景
我在使用seatunnel实现从mysql导入到hive的时候,遇到mysql中存在回车换行符“\n\r”时,到hive中会出现在换行符处切分,导致换行前的一条记录后面的列都是空,而换行后的一条记录的前面的列都是空,严重干扰了结果的准确性,所以需要解决这个问题。
本身seatunnel的…
Presto:Unable to create input format com.hadoop.mapred.DeprecatedLzoTextInputFormat错误解析
我的hive中的ods层表是这样存储的:
drop table if exists ods_ipqc_online_tmp;
create external table ods_ipqc_online_tmp
(MACH_ID string COMMENT 机台id,MACH_IP decimal(16, 2) COMMENT 机台ip,IPQC_ONLINEID string COMMENT IPQC在线ID,CREATE…
hive自定义udf
package com.gxzq.app;/*** author jinhong.liu* date 2023年01月31日 14:48*/import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeExce…
大数据之数据采集项目总结——hadoop,hive,openresty,frcp,nginx,flume
1、前期准备 2、数据收集
1、开启openresty,nginx和frcp内网穿透 2、编辑并启动定时器 3、查看是否收集到了数据 数据收集阶段结束,进入下一个阶段
2、将收集到的切分好的数据上传到hdfs
使用的工具:flume flume像一个管道一样,…
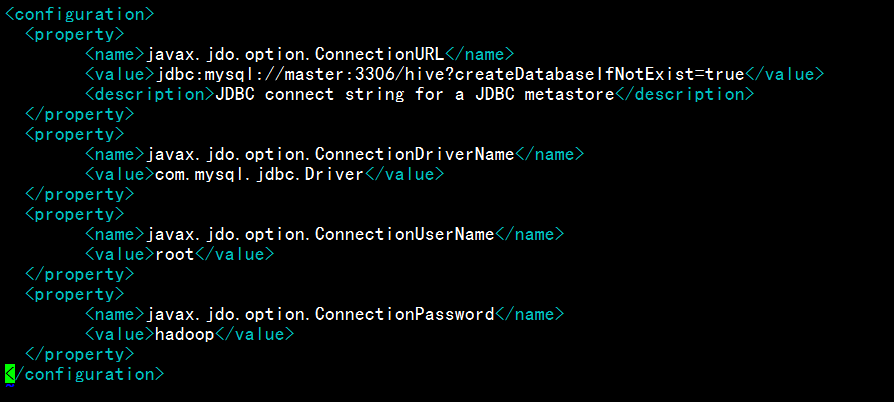
Hadoop+Hive部署安装配置
最近结合具体的项目,搭建了HadoopHive,在运行Hive之前要首先搭建好Hadoop,关于Hadoop的搭建有三种模式,在以下的介绍中,我主要的采用的是Hadoop的伪分布安装模式。写下来给各位分享。 准备工作: 以上所…
Hive中Join优化的几种算法
文章目录 1. Common Join2. Map Join3. Bucket Map Join4. Sort Merge Bucket Map Join ( SMB Map Join ) 1. Common Join
Common Join 是最稳定且默认的Join算法,通过 MR Job 完成 Join 。
需要注意的是,在三个表的 Join 关联中…
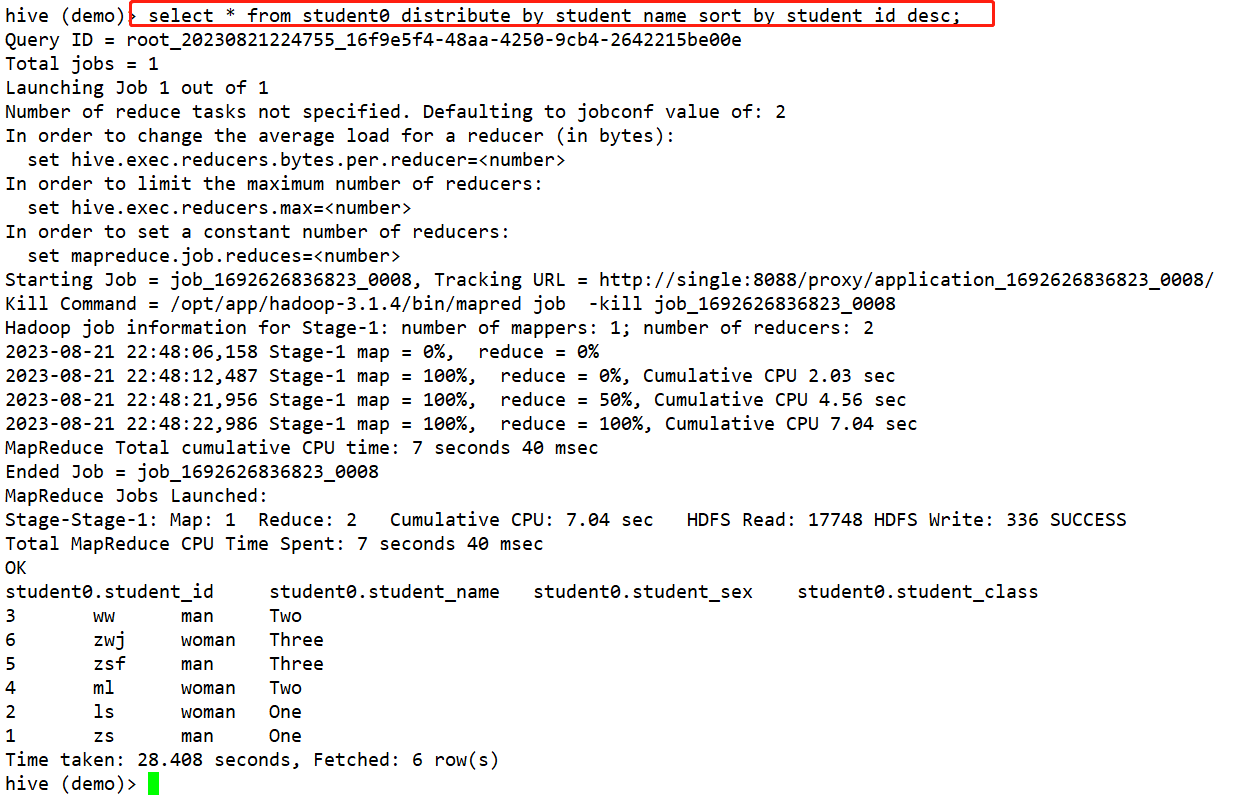
Hadoop生态圈中的Hive数据仓库技术
Hadoop生态圈中的Hive数据仓库技术 一、Hive数据仓库的基本概念二、Hive的架构组成三、Hive和数据库的区别四、Hive的安装部署五、Hive的基本使用六、Hive的元数据库的配置问题七、Hive的相关配置项八、Hive的基本使用方式1、Hive的命令行客户端的使用2、使用hiveserver2方法操…
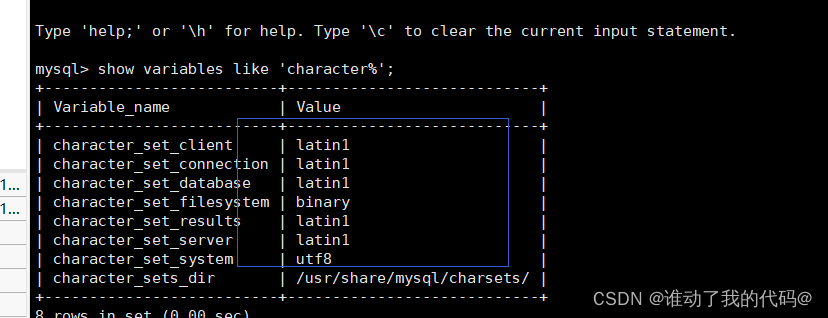
实现MySQL-->HDFS;MySQL-->Hive;Hive-->HDFS;HDFS-->MySQL的数据迁移
实现MySQL-->HDFS;MySQL-->Hive;Hive-->HDFS;HDFS-->MySQL的数据迁移一. Apache Sqoop介绍二.Sqoop安装2.1安装Sqoop2.2解压Sqoop2.3配置Sqoop2.4.加入mysql的jdbc驱动包2.5. 设置ACCUMULO_HOME环境变量2.5. 验证启动,显示版本号2.6.显示MySQL中的数据库…
49. 视频热度问题
文章目录 实现一题目来源 谨以此笔记献给浪费掉的两个小时。
此题存在多处疑点和表达错误的地方,如果你看到了这篇文章,劝你跳过该题。
该题对提升HSQL编写能力以及思维逻辑能力毫无帮助。
实现一
with info as (-- 将数据与 video_info 关联&#x…
数据接口工程对接BI可视化大屏(五)数据接口发布
文章目录 第5章 数据接口发布5.1 编写Service5.2 从MySQL中返回数据5.2.*1 封装Bean5.2.*2 编写Mapper5.2.3 编写ServiceImpl5.2.4 编写Controller5.2.5 测试 5.3 从Redis中返回数据5.3.1 封装Bean5.3.2 编写Mapper5.3.3 编写ServiceImpl5.3.4 编写Controller5.3.5 测试 5.4 从…

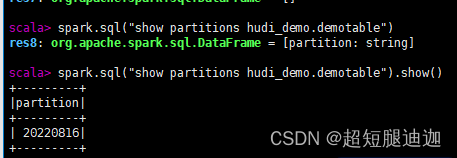
Mysql->Hudi->Hive
一 准备
1.启动集群 /hive/mysql
start-all.sh2.启动spark-shell
spark-shell \--master yarn \
//--packages org.apache.hudi:hudi-spark3.1-bundle_2.12:0.12.2 \--jars /opt/software/hudi-spark3.1-bundle_2.12-0.12.0.jar \--conf spark.serializerorg.apache.spark.…
【hive】行转列—explode()/posexplode()/lateral view 函数使用场景
文章目录 一、lateral view函数二、explode()函数三、posexplode()函数四、行转列使用单列转多行多列转多行 一、lateral view函数 功能: 用于和UDTF函数(explode,split)结合使用,把某一行数据拆分成多行数据,再将多行结果组合成一…
hive电子商务消费行为分析
hive电子商务消费行为分析 1. 掌握Zeppelin的使用 2. 了解数据结构 3.数据清洗 4. 基于Hive的数据分析 1.物料准备 (1)Customer表 customer_details details customer_id Int, 1 - 500 first_name string last_name string email s…
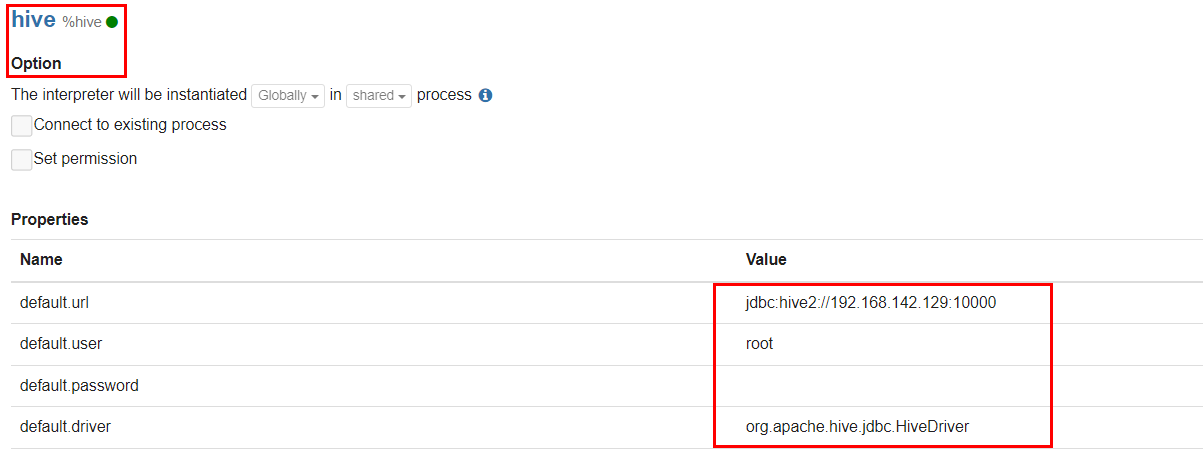
hive工具-zeppelin部署
zeppelin部署 解压安装包至/opt/soft 并改名 /etc/proofile中配置环境变量并source生效 #ZEPPELIN export ZEPPELIN_HOME/opt/soft/zeppelin010 export PATH$ZEPPELIN_HOME/bin:$PATH (1)conf目录下拷贝一份初始配置文件 [rootkb129 conf]# pwd /opt/s…
hive 中正则表表达式使用
一 概念
概念:正则表达式(Regular Expression),又称规则表达式,是记录文本规则的代码。通常被用来检索、替换那些符合某个模式(规则)的文本。
特性:最初是由Unix中的工具软件(例如sed和grep&a…
flink1.13.2版本的对应的hive的Hcatalog的使用记录
依赖版本要求<hive.version>3.1.2</hive.version><flink.version>1.13.2</flink.version><hadoop.version>3.3.2</hadoop.version><scala.binary.version
![Hive行转列[一行拆分成多行/一列拆分成多列]](https://img-blog.csdnimg.cn/a329dd8afa55418db34b9d1b641bbd22.png)
Hive行转列[一行拆分成多行/一列拆分成多列]
场景:
hive有张表armmttxn_tmp,其中有一个字段lot_number,该字段以逗号分隔开多个值,每个值又以冒号来分割料号和数量,如:A3220089:-40,A3220090:-40,A3220091:-40,A3220083:-40,A3220087:-40,A3220086:-4…
修炼离线:(五)hbase映射表插入hive
一:创建hive表。
sql
--drop table if exists ods.odsyyy;
create table if not exists ods.odsfff(row_id string comment 行记录唯一ID,对应ROW_KEY,aaa string comment aaa,bbb string comment bbb,ccc strin…

hive3.X的HiveServer2 内存泄漏问题定位与优化方案(bug)
参考文档: https://juejin.cn/post/7141331245627080735?searchId20230920140418F85636A0735C03971F71
官网社区: https://issues.apache.org/jira/browse/HIVE-22275
In the case that multiple statements are run by a single Session before bein…
Hive-启动与操作(2)
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…

hive表向es集群同步数据20230830
背景:实际开发中遇到一个需求,就是需要将hive表中的数据同步到es集群中,之前没有做过,查看一些帖子,发现有一种方案挺不错的,记录一下。
我的电脑环境如下
软件名称版本Hadoop3.3.0hive3.1.3jdk1.8Elasti…
一百八十一、Hive——海豚调度HiveSQL任务时当Hive的计算引擎是mr或spark时脚本的区别(踩坑,附截图)
一、目的
当Hive的计算引擎是spark或mr时,发现海豚调度HQL任务的脚本并不同,mr更简洁
二、Hive的计算引擎是Spark时
(一)海豚调度脚本
#! /bin/bash source /etc/profile
nowdatedate --date0 days ago "%Y%m%d" y…
![[hive]搭建hive3.1.2hiveserver2高可用可hive metastore高可用](https://img-blog.csdnimg.cn/b36e0643ebb545ff875c8a963c960f3e.png)
[hive]搭建hive3.1.2hiveserver2高可用可hive metastore高可用
参考:
Apache hive 3.1.2从单机到高可用部署 HiveServer2高可用 Metastore高可用 hive on spark hiveserver2 web UI 高可用集群启动脚本_薛定谔的猫不吃猫粮的博客-CSDN博客
没用里头的hive on spark,测试后发现版本冲突
一、Hive 集群规划(蓝色部分)
ck1ck2ck3Secondary…

hive with tez:无法从链中的任何提供者加载aws凭据
环境信息
hadoop 3.1.0
hive-3.1.3
tez 0.9.1 问题描述
可以从hadoop命令行正确地访问s3a uri。我可以创建外部表和如下命令:
create external table mytable(a string, b string) location s3a://mybucket/myfolder/;
select * from mytable limit 20;
执行正…
JDBC MySQL任意文件读取分析
JDBC MySQL任意文件读取分析
文章首发于知识星球-赛博回忆录。给主管打个广告,嘿嘿。 在渗透测试中,有些发起mysql测试流程(或者说mysql探针)的地方,可能会存在漏洞。在连接测试的时候通过添加allowLoadLocalInfileInPath,allowLoadLocalInf…
CentOS6.5 安装Hive
本文介绍在CentOS6.5上安装Hive,安装Hive前系统中已经部署完成了hadoop分布式文件系统,如果你需要安装hadoop请参考这篇文章。
安装Hive是需要mysql数据库服务的支持,因此需要先安装mysql,参考了许多博客教程,最靠谱的…
大数据从入门到精通(超详细版)之Hive的案例实战,ETL数据清洗!!!
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小…
spark读取数据写入hive数据表
目录
一个模板 概述:
create_tabel建表函数,定义日期分区
删除原有分区drop_partition函数
generate_data 数据处理函数,将相关数据写入定义的表中
添加分区函数add_partition 一个模板 概述:
table_name name # 要写入…
Hive 之 DML 数据操作
1. 数据导入
1.1 向表中 load 数据
load 可以从本地服务器、hdfs 文件系统加载数据到数据表中:
load data [local] inpath /opt/module/datas/student.txt [overwrite] into table student [partition (partcol1val1,…)];// 加载到 default 库 student 表
load …
EMR集群运行TPC-DS在云盘和OSS中的对比
1.简介 TPC-DS是大数据领域最为知名的Benchmark标准。本文介绍使用阿里云EMR集群运行TPC-DS在云盘和OSS中的表现对比。
2.环境准备
1.创建EEMR-5.10.1集群 1个master,2个core,3台机器都s是4c16g。
2.安装Git和Maven
sudo yum install -y git maven3.下载TPC-DS Benchmark工…
Hive数据清洗中常见的几个函数
Hive数据清洗中常见的几个字符串处理函数 1.空格处理 trim()2.字符串分割 split()3.无用符处理 regexp_replace()4.字符串拼接concat()concat_ws() 在Hive中,数据清洗是一个重要的任务之一,通常涉及到对数据进行过滤、修改和转换等操作,以使其…
Hive on Spark调优(大数据技术1)
第1章 集群环境概述
1.1 集群配置概述
所用集群由5台节点构成,其中2台为master节点,用于部署HDFS的NameNode,Yarn的ResourceManager等角色,另外3台为worker节点,用于部署HDFS的DataNode、Yarn的NodeManager等角色。 …
记录常见问题-2023
记录:426
场景:在开发、测试中,经常碰到各类问题,记录一下常见问题。
1.在Nacos的namespace使用默认的public时,无需写public
Nacos版本:Nacos 2.0.3
1.1问题
在application.yml文件如下配置,在微服务…

Hive文件存储格式
列式存储和行式存储上图左边为逻辑表,右边第一个为行式存储,第二个为列式存储。行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值&#x…


Hive 之 压缩和存储
欢迎大家扫码关注我的微信公众号: Hive 之 压缩和存储一、 压缩1.1 MR 支持的压缩编码1.2 压缩参数配置1.3 开启 Map 输出阶段压缩1.4 开启 Reduce 输出阶段压缩二、 存储2.1 行存储和列存储2.1.1 行存储的特点2.1.2 列存储的特点2.2 TextFile 格式2.3 Orc 格式2.4…

Hive 之 函数 02-常用查询函数(二)
欢迎大家扫码关注我的微信公众号: Hive 之 函数 02-常用查询函数(二)六、 窗口函数6.1 函数说明6.2 需求6.3 实现6.3.1 查询在 2017 年 4 月份购买过的顾客及总人数6.3.2 查询顾客的购买明细及购买总额6.3.3 上述的场景, 要将 cost 按照日期…
Hive 使用总结HiveQL
一、基本操作
hive #进入使用HiveQL操作
show databases; #展示所有数据库
show databases like *x*; #展示包含x字段的数据库,不同于sql模糊查询 % _ 不适用
create database dbname; #创…

彷徨 | Hive的SQL--DDL详细操作
Hive的简介与安装见另一篇文章 : https://blog.csdn.net/weixin_35353187/article/details/82154151 Hive的三种使用方式 :
方式一 : bin/hive 交互式查询
方式二 : 启动Hive的网络服务 , 然后通过客户端beeline去连接服务进行查询 : 启动服务 : bin/hiveserver2 启动客户端…
hive分区表的元数据信息numRows显示为0
创建分区表
CREATE TABLE `dept_partition`(`deptno` int, `dname` string, `loc` string)
PARTITIONED BY (
使用 Databend 加速 Hive 查询
作者:尚卓燃(PsiACE) 澳门科技大学在读硕士,Databend 研发工程师实习生 Apache OpenDAL(Incubating) Committer PsiACE (Chojan Shang) GitHub 随着架构的不断迭代和更新,大数据系统的查询目标也从大吞吐量查询逐步转…
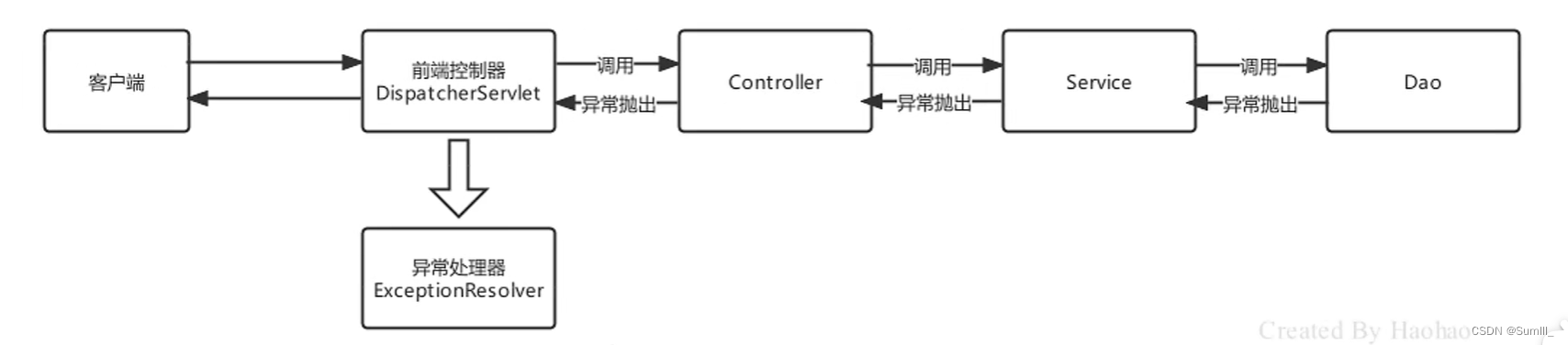
SpringMVC学习笔记——2
SpringMVC学习笔记——2 一、SpringMVC的拦截器1.1、拦截器Interceptor简介1.2、拦截器快速入门1.3、拦截器执行顺序1.4、拦截器执行原理 二、SpringMVC的全注解开发2.1、spring-mvc.xml中组件转化为注解形式2.1.1、消除spring-mvc.xml2.1.2、消除web.xml 三、SpringMVC的组件原…
hive数据库操作,hive函数,FineBI可视化操作
1、数据库操作
1.1、创建数据库
create database if not exists myhive;use myhive;1.2、查看数据库详细信息
desc database myhive;数据库本质上就是在HDFS之上的文件夹。 默认数据库的存放路径是HDFS的:/user/hive/warehouse内
1.3、创建数据库并指定hdfs存…

Hive_Hive统计指令analyze table和 describe table
之前在公司内部经常会看到表的元信息的一些统计信息,当时非常好奇是如何做实现的。
现在发现这些信息主要是基于 analyze table 去做统计的,分享给大家
实现的效果某一个表中每个列的空值数量,重复值数量等,平均长度
具体的指令…
【Hive】drop table需注意外部表
什么是内部表,外部表?
比较专业的定义: 外部表需要转为内部表,执行删除操作才能真的删表结构删表数据。否则drop table仅是删除了表数据,表结构还是存在的。
alter table tb_name set TBLPROPERTIES(EXTERNALfalse);…
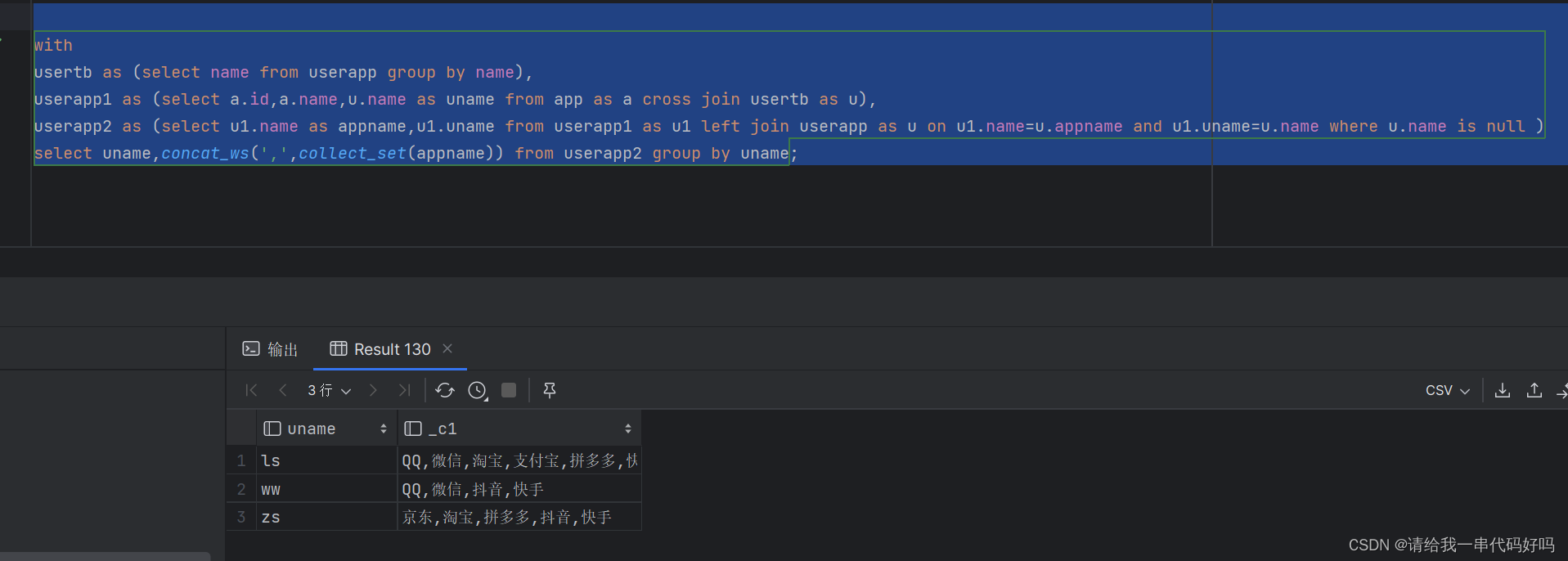
Hadoop Hive入门
0目录 1.linux 安装hive 2.hive入门 3.hive高级语法1 1.linux 安装hive 先确保linux虚拟机中已经安装jdk;mysql和hadoop 并可以成功启动hadoop和mysql 下载hive对应版本到opt/install目录下并解压到opt/soft目录下 重命名 hive312 配置profile 文件ÿ…

44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例--网上有些说法好像是错误的
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…

【Hive SQL 每日一题】统计用户连续下单的日期区间
文章目录 测试数据需求说明需求实现 测试数据
create table test(user_id string,order_date string);INSERT INTO test(user_id, order_date) VALUES(101, 2021-09-21),(101, 2021-09-22),(101, 2021-09-23),(101, 2021-09-27),(101, 2021-09-28),(101, 2021-09-29),(101, 20…
尚硅谷大数据项目《在线教育之离线数仓》笔记007
视频地址:尚硅谷大数据项目《在线教育之离线数仓》_哔哩哔哩_bilibili 目录
第12章 报表数据导出
P112
01、创建数据表
02、修改datax的jar包
03、ads_traffic_stats_by_source.json文件
P113
P114
P115
P116
P117
P118
P119
P120
P121
P122【122_在…
数据接口工程对接BI可视化大屏(二)创建BI空间
第2章 创建BI空间
2.1 SugarBI介绍
网站地址:https://cloud.baidu.com/product/sugar.html
SugarBI是百度推出的自助BI报表分析和制作可视化数据大屏的强大工具。
基于百度Echarts提供丰富的图表组件,开箱即用、零代码操作、无需SQL,5分钟即可完成数…
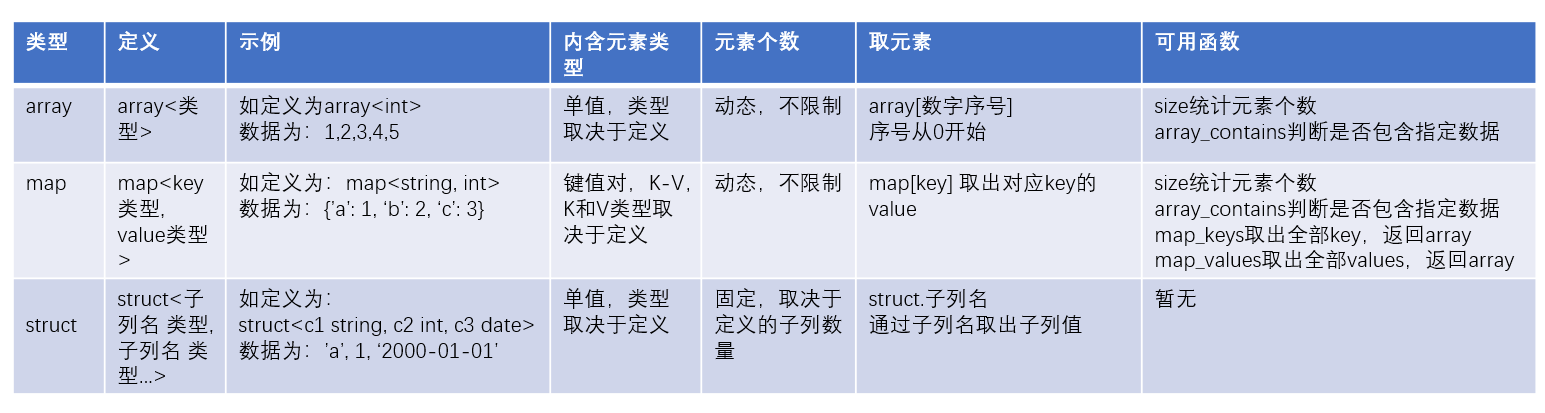
探索Apache Hive:融合专业性、趣味性和吸引力的数据库操作奇幻之旅
文章目录 版权声明一 数据库操作二 Hive数据表操作2.1 表操作语法和数据类型2.2 Hive表分类2.3 内部表Vs外部表2.4 内部表操作2.4.1 创建内部表2.4.2 其他创建内部表的形式2.4.3 数据分隔符2.4.4 自定义分隔符2.4.5 删除内部表 2.5 外部表操作2.5.1 创建外部表2.5.2 操作演示2.…

爬取微博热榜并将其存储为csv文件
🙌秋名山码民的主页 😂oi退役选手,Java、大数据、单片机、IoT均有所涉猎,热爱技术,技术无罪 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 获取源码,添加WX 目录 前言1.…

Sqoop的安装和使用
目录
一.安装
二.导入
1.全量导入
一.MySQL导入HDFS 二.MySQL导入Hive 2.增量导入
一.过滤导入hdfs/hive
二.导出 一.安装
1.下载地址:sqoop下载地址 2.解压
tar -zxvf ./sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C ../module/
3.改名和配置归属权限
#改名…
Hive实战(03)-深入了解Hive JDBC:在大数据世界中实现数据交互
在大数据领域,Hive作为一种数据仓库解决方案,为用户提供了一种SQL接口来查询和分析存储在Hadoop集群中的数据。为了更灵活地与Hive进行交互,我们可以使用Hive JDBC(Java Database Connectivity)驱动程序。本文将深入探…
hive变更数据过程
创建测试表
-- 測試數據集use default;
drop table if exists test3;
CREATE TABLE if not exists test3(id string,name string,create_date string,last_modified_date string,amount double,is_delete int
)partitioned by (dt string)
row format delimited fields term…
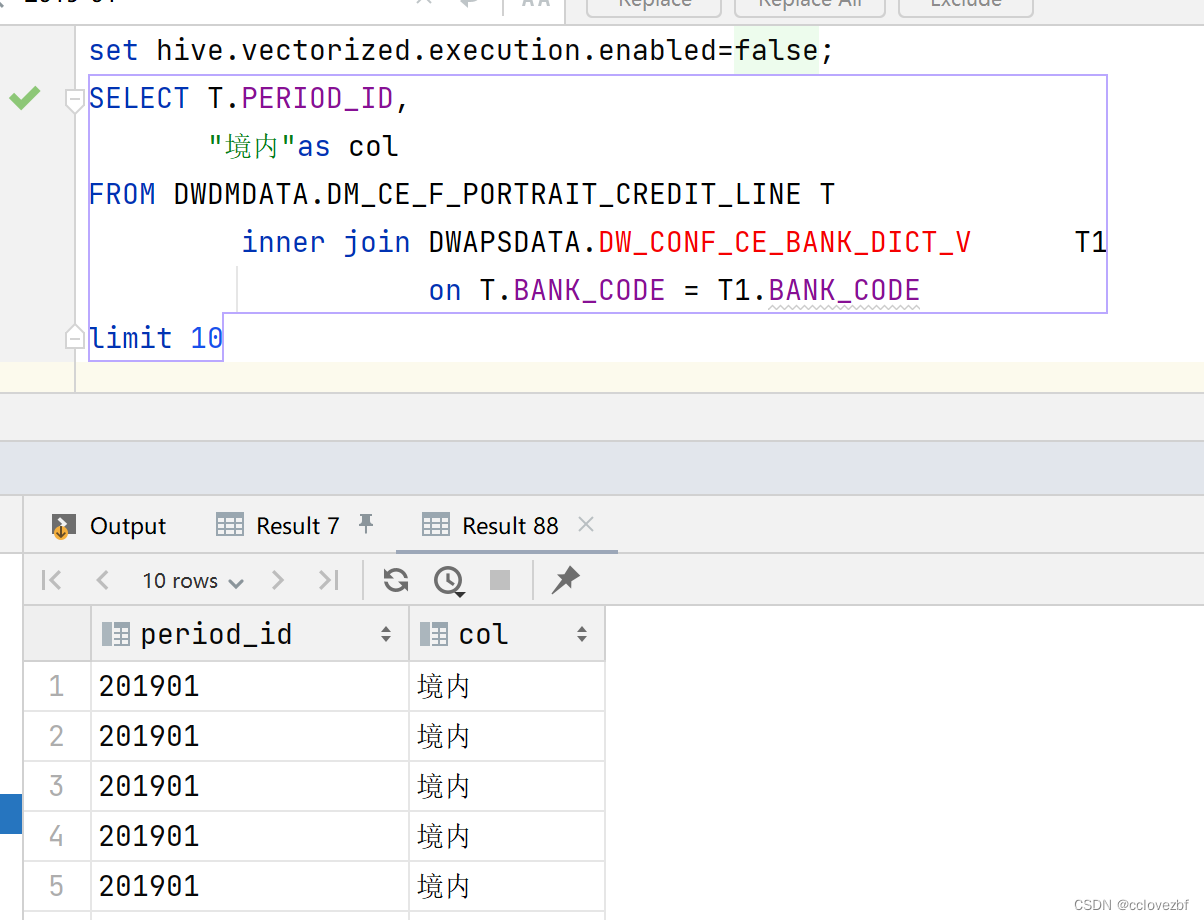
hive 之select 中文乱码
此处的中文乱码和mysql的库表 编码 latin utf 无关。
直接上案例。
有时候我们需要自定义一列,有时是汉字有时是字母,结果遇到这种情况了。 说实话看到这真是糟心。这谁受得了。
单独select 没有任何问题。 这是怎么回事呢? 经过一番检查&…
大数据学习(5)-hive文件格式
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
大数据学习(8)-hive压缩
压缩
在Hive表中和计算过程中,保持数据的压缩,对磁盘空间的有效利用和提高查询性能都是十分有益的。 Hive表数据进行压缩
在Hive中,不同文件类型的表,声明数据压缩的方式是不同的。
1)TextFile
若一张表的文件类型…

数据仓库Hive(林子雨课程慕课)
文章目录 9.数据仓库Hive9.1 数据仓库的概念9.2 Hive简介9.3 SQL语句转换为MapReduce作业的基本原理9.4 Impla9.4.1 Impala简介9.4.2 Impala系统架构9.4.3 Impala查询执行过程9.4.4 Impala与Hive的比较 9.5 Hive的安装和基本操作9.5.1 Hive安装9.5.2 Hive基本操作 9.数据仓库Hi…
关于一篇什么是JWT的原理与实际应用
目录 一.介绍
1.1.什么是JWT
二.结构
三.Jwt的工具类的使用
3.1. 依赖
3.2.工具类
3.3.过滤器
3.4.控制器
3.5.配置
3.6. 测试类
用于生成JWT
解析Jwt
复制jwt,并延时30分钟
测试JWT的有效时间 测试过期JWT的解析
四.应用 今天就到这了,希…
大数据学习(9)-hadoop集群计算速度影响因素
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件 版本号步骤hadoopcore-site.xmlhdfs-site.xmlmapred-site.xmlslavesworkersyarn-site.xml hivehive-site.xmlspark-defaults.conf sparkhdfs-site.xmlhive-site.xmlslavesyarn-site.xmlspark-env.sh 版本号
apache-hive-3.1.3-…
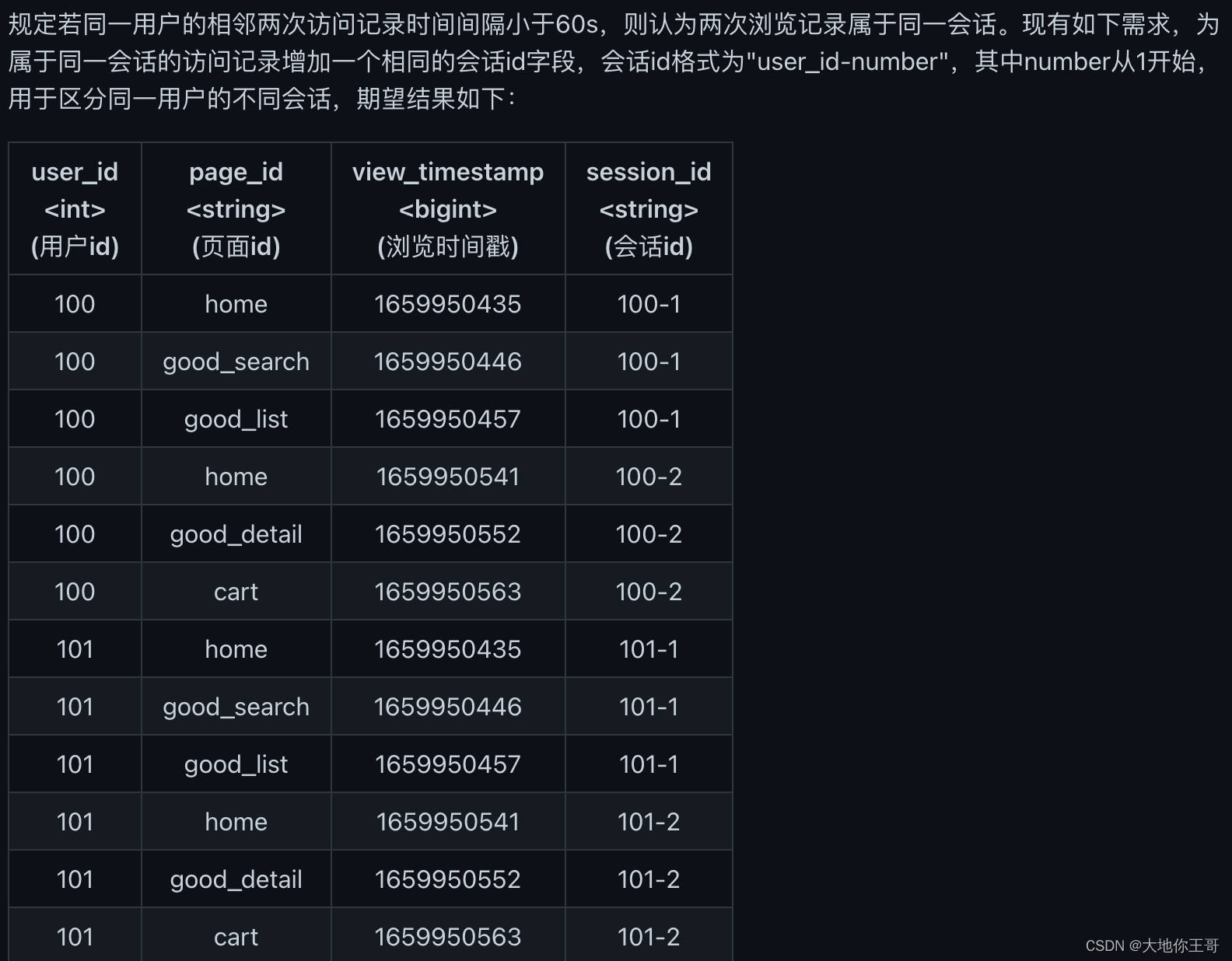
42.会话划分问题求解(打标)
思路分析: (1)为每一次浏览找到他的上一次浏览时间 lag(view_timestamp, 1, 0) over(partition by user_id order by view_timestamp) as last_view_timestamp (2)为>60s的设置一个初始会话的标签flagif(vi…
Hudi第四章:集成Hive
系列文章目录
Hudi第一章:编译安装 Hudi第二章:集成Spark Hudi第二章:集成Spark(二) Hudi第三章:集成Flink Hudi第四章:集成Hive 文章目录 系列文章目录前言一、环境准备1.拷贝jar包 二、Flink集成hive1.配置模版2.案…
Hive跨集群数据迁移过程
文章目录 环境数据迁移需求迁移过程记录 环境
Hive集群AHive集群B跳转机一台
数据迁移需求
本次迁移数据100G,15亿条,数据流转方向从集群A经过跳转机到集群B,通过HDFS拉取和重新建表导入的方式完成数据库迁移。
迁移过程记录
- 当前操作…
Hive篇面试题+详解
Hive篇面试题 1.什么是Hive?它的主要功能是什么?
Hive是一个基于Hadoop的数据仓库工具,它提供了一个类SQL的查询语言(HiveQL)来查询和分析存储在Hadoop集群中的大规模数据。Hive的主要功能是将结构化数据映射到Hadoop…
[Hive] if返回null和0的区别
count(if(pv>1000000,1,0))count(if(pv>1000000,1,null))
区别
count(if(pv>1000000,1,0)) 和 count(if(pv>1000000,1,null)) 之间的区别在于对于不满足条件的情况下的处理方式。 count(if(pv>1000000,1,0)):这个表达式中,如果 pv 的值…
Hadoop面试题(2)
1.什么是数据倾斜?如何处理数据倾斜?
数据倾斜指的是在分布式计算中,数据在某些节点上不均匀地分布,导致某些节点的负载过重,影响整体计算性能。
处理数据倾斜的方法主要包括以下几种:
增加分区数量&…

数据湖Iceberg介绍和使用(集成Hive、SparkSQL、FlinkSQL)
文章目录 简介概述作用特性数据存储、计算引擎插件化实时流批一体数据表演化(Table Evolution)模式演化(Schema Evolution)分区演化(Partition Evolution)列顺序演化(Sort Order Evolution&…
Hive SQL 函数高阶应用场景
HIVE作为数据仓库处理常用工具,如同RDBMS关系型数据库中标准SQL语法一样,Hive SQL也内置了不少系统函数,满足于用户在不同场景下的数据分析需求,以提高开发SQL数据分析的效率。 我们可以使用show functions查看当下版本支持的函数…
Hive 建表客户端报错 missing EOF at “/“
在创建表时,我使用的是idea客户端,报了如下错误
org.apache.hadoop.hive.ql.parse.ParseException:line 6:48 missing EOF at ‘/’ near ‘)’
原本sql如下:
create table t_usa_covid19_p(county string,fips int,cases int,deaths int)…
HIVE-17824,删除hdfs分区信息,清理metastore元数据
当手动删除HDFS 分区数据时,但是并没有清理 Hive 中的分区元数据,删除操作无法自动更新hive分区表元数据。也就是从hdfs中删除大量分区数据,并没有执行如下命令: alter table drop partition commad 从hive 3.0.0开始可以使用MSCK的方法发现新分区或删除丢失的分区; MSCK [REPA…
hive字段关键字问题处理
最近在xxl_job部署shell调度任务时,发现在编写Hql时,对一些使用关键字命名的字段无法解析,按开发规范,字段命名不应该有关键字,但是数据来源是第三方,无法修改,需要通过flume对从kafka的数据到hdfs上,数据是json格式,所以需要对关…
CDH6.3.2 的pyspark读取excel表格数据写入hive中的问题汇总
需求:内网通过Excel文件将数据同步到外网的CDH服务器中,将CDH中的文件数据写入hive中。
CDH版本为:6.3.2 spark版本为:2.4 python版本:2.7.5 操作系统:CentOS Linux 7 集群方式:yarn-cluster
…
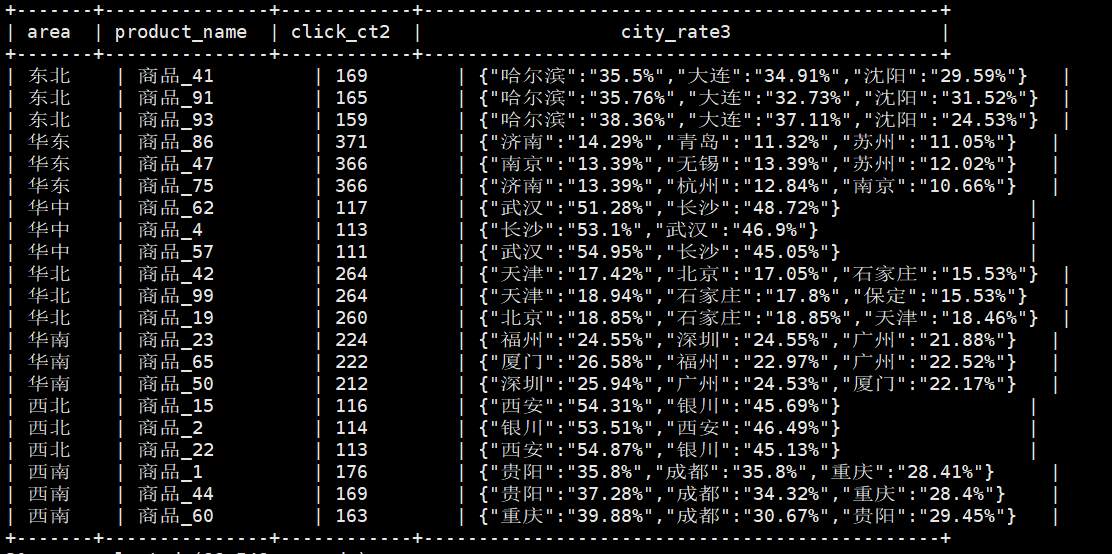
求各区域热门商品Top3 - HiveSQL
背景:这是尚硅谷SparkSQL练习题,本文用HiveSQL进行了实现。 数据集:用户点击表,商品表,城市表 题目: ① 求每个地区点击量前三的商品; ② 在①的基础上,求出每个地区点击量前三的商品后&a…
Hive-命令行CDH访问开启kerberos的hive
1.通过hive用户访问
切换用户为hive
[rootslave conf]# su - hive
上一次登录:五 4月 12 13:59:19 CST 2019pts/1 上
[hiveslave ~]$命令行直接输入hive就可以进入hive
[hiveslave ~]$ hive
log4j:WARN No such property [maxFileSize] in org.apache.log4j.Dail…
hive数据load到redis
使用shell脚本来实现,脚本如下:
#!/bin/bash# 定义变量
pwd/root
day$(date %Y%m%d)
before_day$(date -d -1day %Y%m%d)
log_file$pwd/load_redis_$day.log# 创建目录
mkdir -p $pwd/$day && echo "$(date %Y-%m-%d %H:%M:%S)----$pwd/$d…
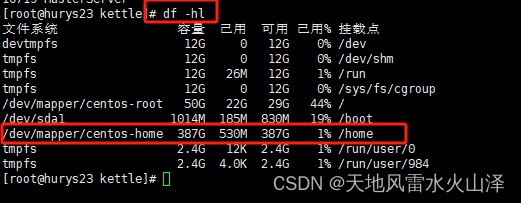
一百八十三、大数据离线数仓完整流程——步骤二、在Hive的ODS层建外部表并加载HDFS中的数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(二)步骤二、在Hive的…
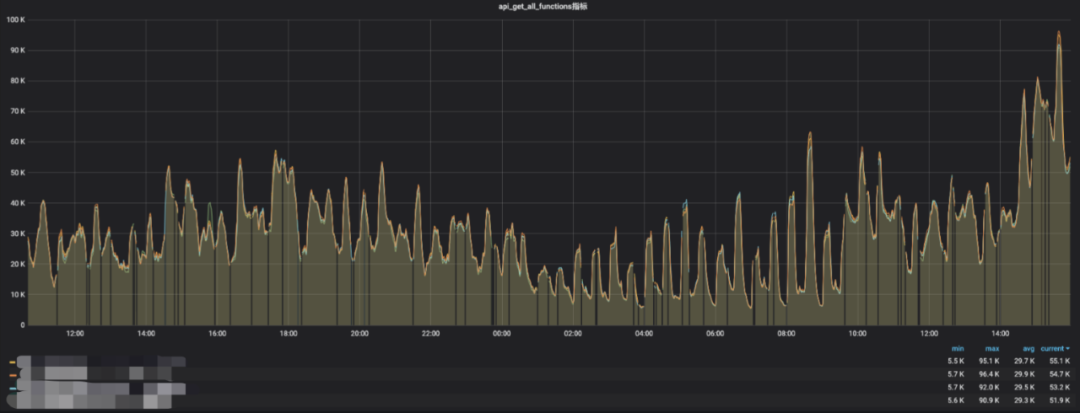
MySQL到TiDB:Hive Metastore横向扩展之路
作者:vivo 互联网大数据团队 - Wang Zhiwen 本文介绍了vivo在大数据元数据服务横向扩展道路上的探索历程,由实际面临的问题出发,对当前主流的横向扩展方案进行了调研及对比测试,通过多方面对比数据择优选择TiDB方案。其次分享了整…
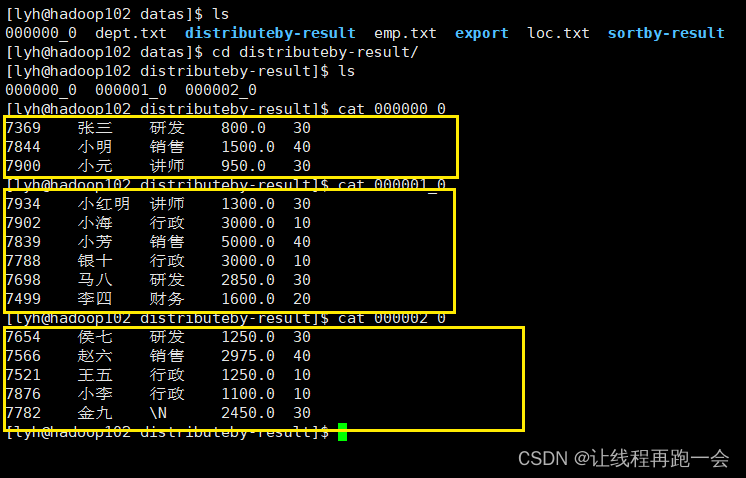
Hive【Hive(三)查询语句】
前言 今天是中秋节,早上七点就醒了,干啥呢,大一开学后空教室紧缺,还不趁着假期来学校等啥呢。顺便偷偷许个愿吧,希望在明年的这个时候,秋招不知道赶不赶得上,我希望拿几个国奖,蓝桥杯…
Hive【Hive(四)函数-单行函数】
函数
函数简介
方便完成我们一些复杂的操作,就好像我们 Spark 中的 UDF 函数,避免用户反复写逻辑。
Hive 提供了大量的内置函数,主要可以分为以下几类:
单行函数聚合函数炸裂函数窗口函数
下面的命令可以查看内置函数的相关…
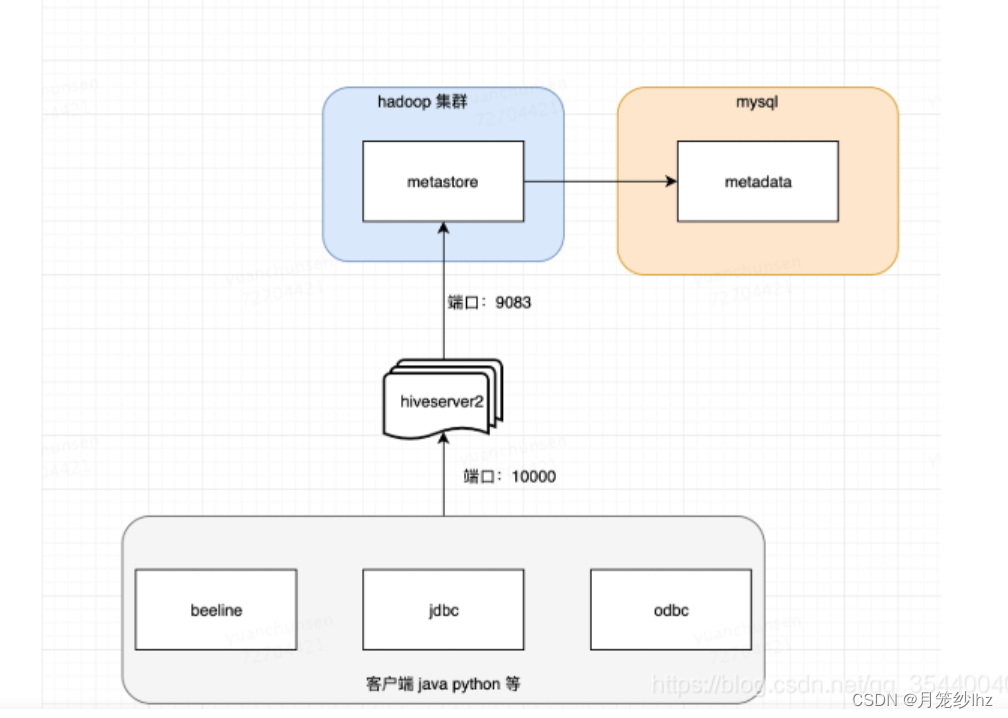
hive add columns 后查询不到新字段数据的问题
分区表add columns 查询不到新增字段数据的问题; 5.1元数据管理 (1)基本架构 Hive的2个重要组件:hiveService2 和metastore,一个负责转成MR进行执行,一个负责元数据服务管理 beeline-->hiveService2/spar…
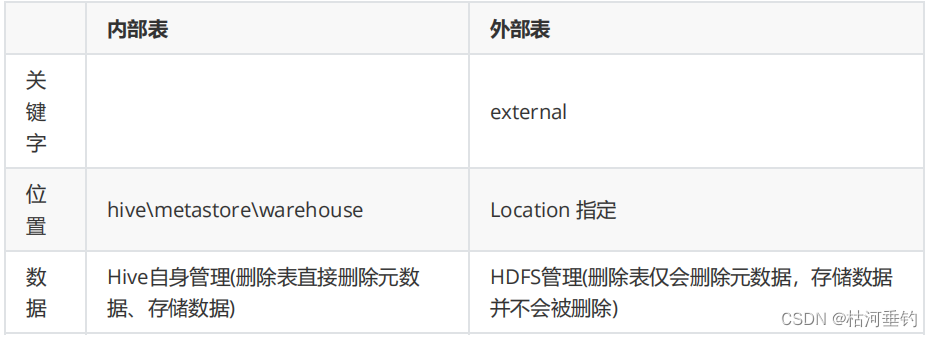
[hive]中的字段的数据类型有哪些
Hive中提供了多种数据类型用于定义表的字段。以下是Hive中常见的数据类型:
布尔类型(Boolean):用于表示true或false。
字符串类型(String):用于表示文本字符串。
整数类型(Intege…

Hive 解析 JSON 字符串数据的实现方式
文章目录 通过方法解析现实示例 通过序列化实现示例 通过方法解析现实
在 Hive 中提供了直接解析 JSON 字符串数据的方法 get_json_object(json_txt, path),该方法参数解析如下: json_txt:顾名思义,就是 JSON 字符串;…
【Python 千题 —— 基础篇】地板除计算
题目描述
题目描述
编写一个程序,接受用户输入的两个数字,然后计算这两个数字的地板除(整除)结果,并输出结果。
输入描述
输入两个数字,用回车隔开两个数字。
输出描述
程序将计算这两个数字的地板除…
【Hive】分区表和分桶表相关知识点介绍
Hive中的分区表和分桶表是两种用于优化数据查询和管理的技术。它们可以提高查询性能、减少数据扫描量并提供更精细的数据组织方式。
分区表(Partitioned Table)
Hive的分区表将数据按照一个或多个列的值进行逻辑分区。每个分区都是一个独立的子目录,其中包含符合该分区条件…
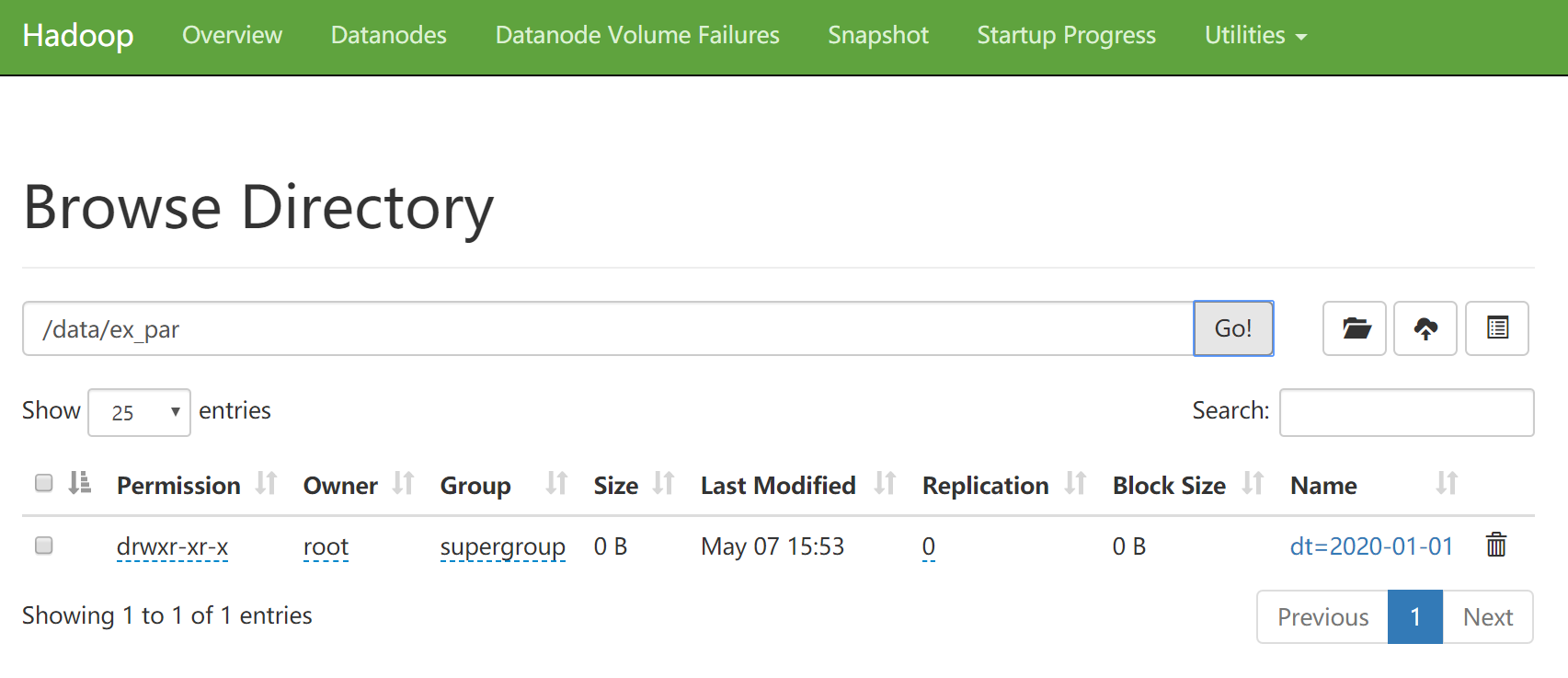
Hive从入门到大牛【Hive 学习笔记】
文章目录 什么是HiveHive的数据存储Hive的系统架构MetastoreHive VS Mysql数据库 VS 数据仓库 Hive安装部署Hive的使用方式命令行方式JDBC方式 Set命令的使用Hive的日志配置Hive中数据库的操作Hive中表的操作 Hive中的数据类型基本数据类型复合数据类型ArrayMapStructStruct和M…

大数据毕业设计选题推荐-超级英雄运营数据监控平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…
Hive3 on Spark3配置
1、软件环境
1.1 大数据组件环境
大数据组件版本Hive3.1.2Sparkspark-3.0.0-bin-hadoop3.2
1.2 操作系统环境
OS版本MacOSMonterey 12.1Linux - CentOS7.6
2、大数据组件搭建
2.1 Hive环境搭建
1)Hive on Spark说明 Hive引擎包括:默认 mr、spark、…
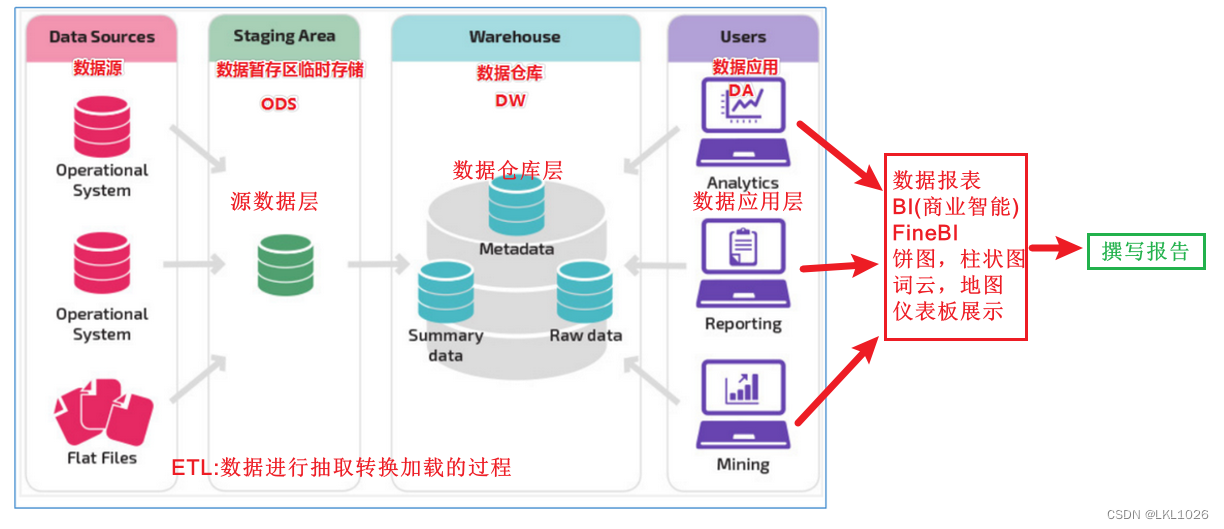
【Python大数据笔记_day05_Hive基础操作】
一.SQL,Hive和MapReduce的关系 用户在hive上编写sql语句,hive把sql语句转化为MapReduce程序去执行 二.Hive架构映射流程 用户接口: 包括CLI、JDBC/ODBC、WebGUI,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端…
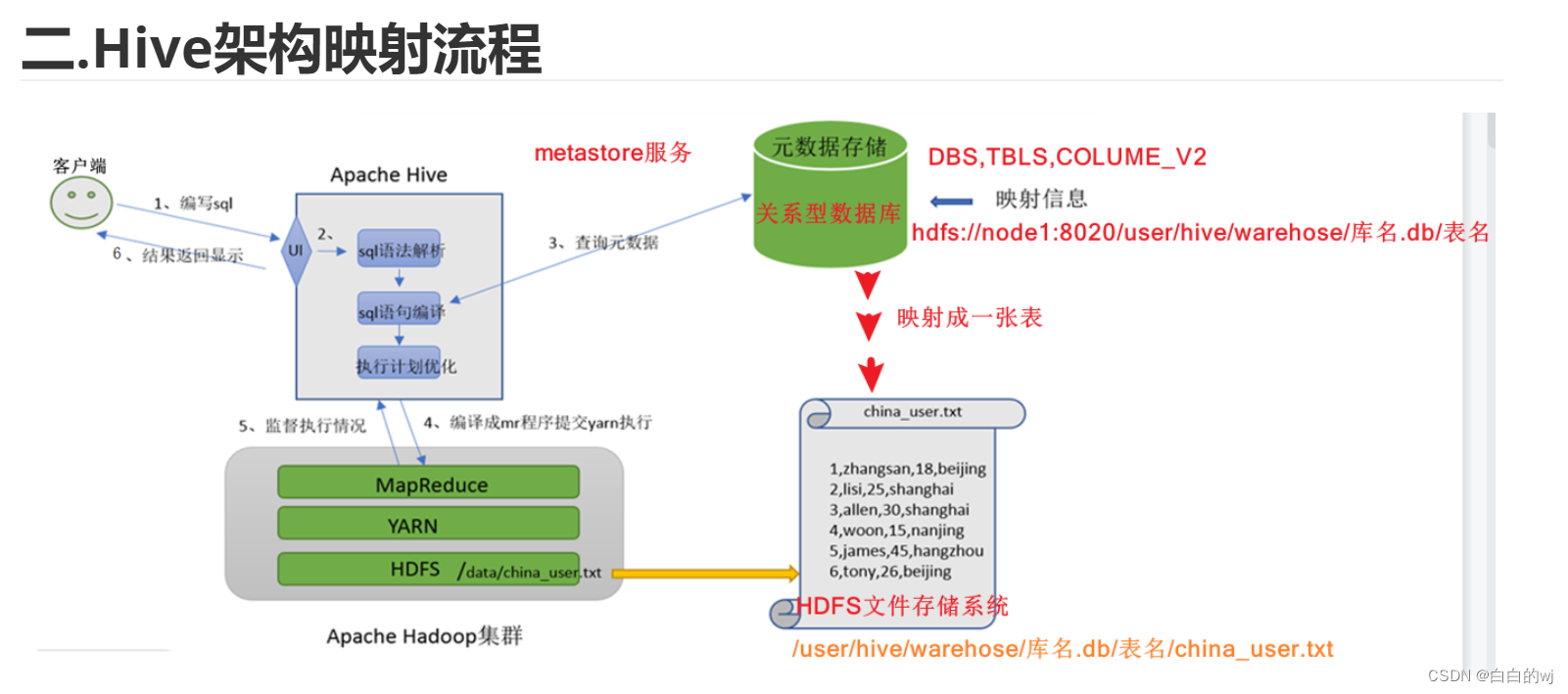
2023.11-9 hive数据仓库,概念,架构
目录
一.HDFS、HBase、Hive的区别
二.大数据相关软件
三. Hive 的优缺点
1)优点
2)缺点
四. Hive 和数据库比较
1)查询语言
2)数据更新
3)执行延迟
4)数据规模
五.hive架构流程
六.MetaStore元…
Hive 知识点八股文记录 ——(二)优化
函数
UDF:用户定义函数
UDAF:用户定义聚集函数
UDTF:用户定义表生成函数
建表优化
分区建桶
创建表时指定分区字段 PARTITIONED BY (date string)指定分桶字段和数量 CLUSTERED BY (id) INTO 10 BUCKETS插入数据按分区、分桶字段插入
…
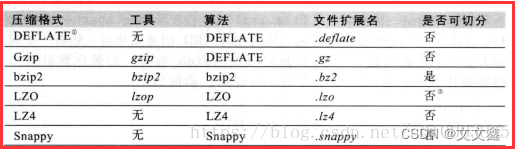
Hive 常用存储、压缩格式
1. Hive常用的存储格式
TEXTFI textfile为默认存储格式 存储方式:行存储 磁盘开销大 数据解析开销大 压缩的text文件 hive 无法进行合拆分
SEQUENCEFILE sequencefile二进制文件,以<key,value>的形式序列到文件中 存储方式:行存储 可…
Spark---Spark on Hive
1、Spark On Hive的配置
1)、在Spark客户端配置Hive On Spark
在Spark客户端安装包下spark-2.3.1/conf中创建文件hive-site.xml:
配置hive的metastore路径
<configuration><property><name>hive.metastore.uris</name><v…
Hdoop学习笔记(HDP)-Part.15 安装HIVE
十五、安装HIVE
1.配置MetaStore
利用ambari创建的MySQL作为MetaStore,创建用户hive及数据库hive
mysql -uroot -p
CREATE DATABASE hive;
CREATE USER hive% IDENTIFIED BY lnydLNsy115;
GRANT ALL ON hive.* TO hive%;
FLUSH PRIVILEGES;2.安装
在服务中添加H…
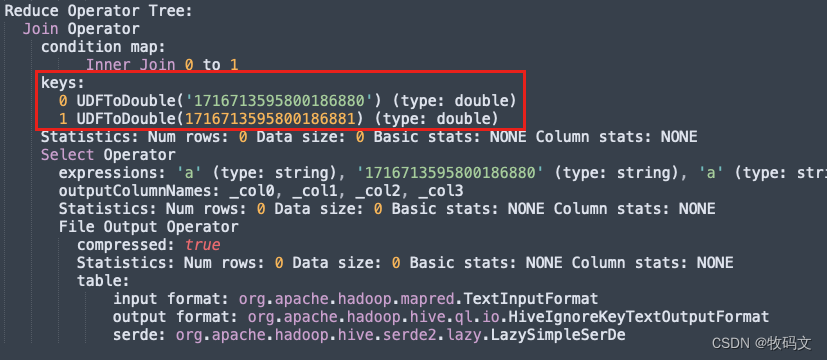
Hive数据倾斜之:数据类型不一致导致的笛卡尔积
Hive数据倾斜之:数据类型不一致导致的笛卡尔积 目录 Hive数据倾斜之:数据类型不一致导致的笛卡尔积一、问题描述二、原因分析三、精度损失四、问题解决 一、问题描述
如果两张表的jion,关联键分布较均匀,没有明显的热点问题&…
使用 Kettle 完成数据 ETL
文章目录 使用 Kettle 完成数据 ETL数据清洗数据处理 使用 Kettle 完成数据 ETL
现在我们有一份网站的日志数据集,准备使用Kettle进行数据ETL。先将数据集加载到Hadoop集群中,然后对数据进行清洗,最后加载到Hive中。
在本地新建一个数据集文…
2023.12.3 hive-sql日期函数小练习
目录 时间函数练习
时间戳 周,季度等计算 获取日期相关
获取当前时间 时间函数练习 --日期函数练习 ,sub是英文subtraction减法的简写, add是英文addition加法的简写
--获取今天是本周的第几天
select dayofweek(2023-12-3); --周日为一周的第一天
select current_timest…
头歌—Hive的安装与配置
第1关:Hive的安装与配置
在修改 conf 下面的hive-site.xml文件这里,题目给的信息是错误的,正确的内容如下:
<?xml version"1.0" encoding"UTF-8" standalone"no"?>
<?xml-stylesheet…

hql面试题之上海某资深数仓开发工程师面试题-求不连续月份的月平均值
1.题目
A,B两组产品的月平均值,月平均值是当月的前三个月值的一个平均值,注意月份是不连续的,如果当月的前面的月份不存在,则为0。如A组2023-04的月平均值为2023年1月的数据加2023-02月的数据的平均值,因为没有其他月…

大数据毕业设计选题推荐-生产大数据平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
hive sqlspark 优化
在数据抽取中常用到从其他数据库抽取数据后数据灌入到hive数据库的情况。
大体逻辑是,连接源数据库,抽取数据,缓存转换,数据插入到hive数据库(或者直接覆盖db文件)。
中间源数据库的效率和代码质量、抽取…
【Python大数据笔记_day06_Hive】
hive内外表操作
建表语法 create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... ) [partitioned by (分区字段名 分区字段类型)] # 分区表固定格式 [clustered by (分桶字段名) into 桶个数 buckets] # 分桶表固定格式 注意: 可以排序[so…
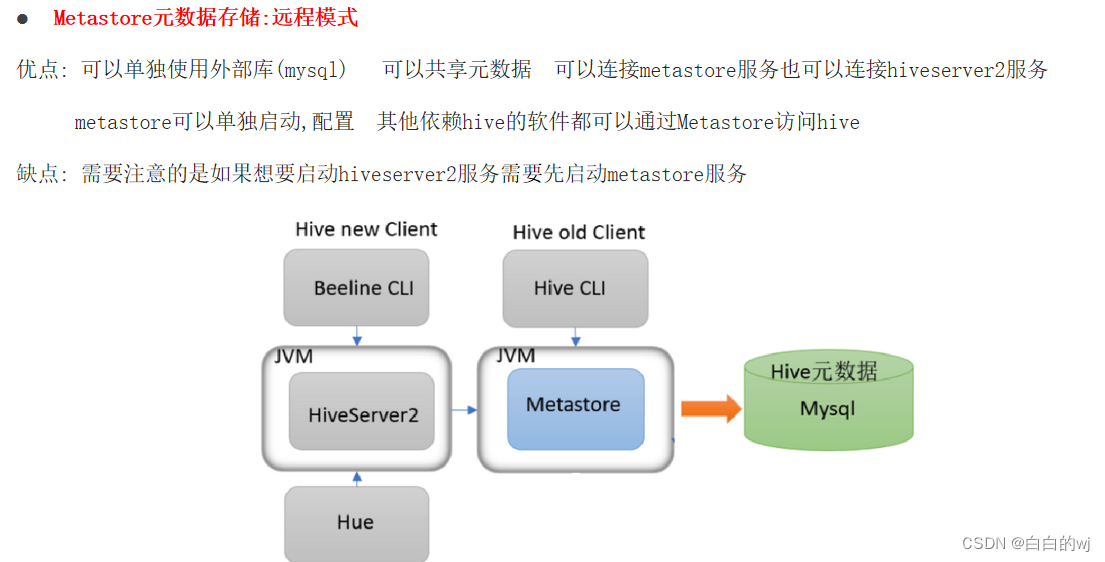
2023.11-9 hive数据仓库,概念,架构,元数据管理模式
目录 0.数据仓库和数据库
数据仓库和数据库的区别 数据仓库基础三层架构
一.HDFS、HBase、Hive的区别
二.大数据相关软件
三. Hive 的优缺点
1)优点
2)缺点
四. Hive 和数据库比较
1)查询语言
2)数据更新
3)…
【Java 进阶篇】Java 中 JQuery 对象和 JS 对象:区别与转换
在前端开发中,经常会涉及到 JavaScript(JS)和 jQuery 的使用。这两者都是前端开发中非常重要的工具,但它们之间存在一些区别。本文将详细介绍 Java 中的 JQuery 对象和 JS 对象的区别,并讨论它们之间的转换方法。
1. …
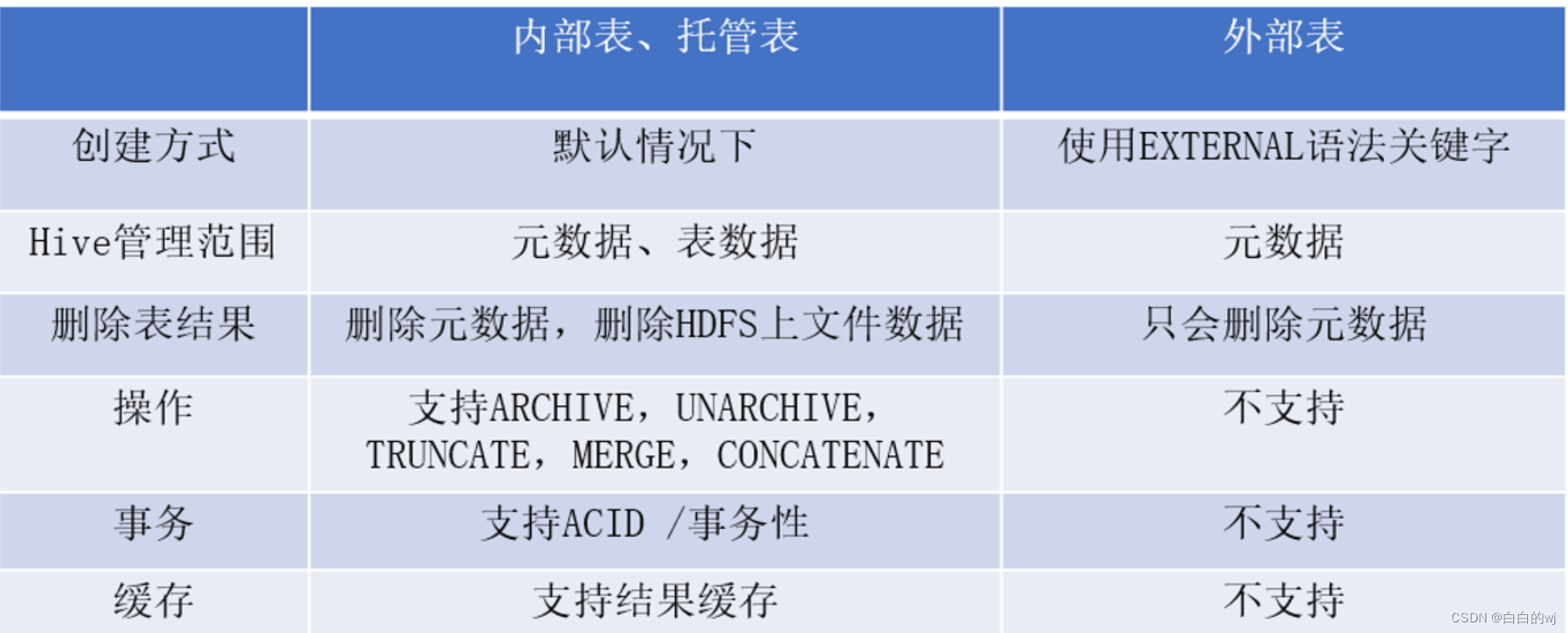
2023.11.11 hive中的内外部表的区别
一.内部表操作
------------------------------1内部----------------------------
--建库
create database hive2;
--用库
use hive2;
--删表
drop table t1;
--建表
create table if not exists t1(id int,name string,gender string
);
--复制内部表
--复制表结构:CREATE T…

2023.11.13 hive数据仓库之分区表与分桶表操作,与复杂类型的运用
目录 0.hadoop hive的文档
1.一级分区表
2.一级分区表练习2 3.创建多级分区表
4.分区表操作
5.分桶表
6. 分桶表进行排序
7.分桶的原理 8.hive的复杂类型
9.array类型: 又叫数组类型,存储同类型的单数据的集合 10.struct类型: 又叫结构类型,可以存储不同类型单数据的集合…

hive和spark-sql中 日期和时间相关函数 测试对比
测试版本:
hive 2.3.4 spark 3.1.1 hadoop 2.7.7
1、增加月份
add_months(timestamp date, int months)add_months(timestamp date, bigint months)Return type: timestampusage:add_months(now(),1) 2、增加日期
adddate(timestamp startdate, int days)…
hivesql连续日期统计最大逾期/未逾期案例
1、虚表(测试表和数据) create test_table as
select a.cust_no, a.r_date, a.yqts from (
select 123 as cust_no, 20231101 as r_date, 0 as yqts
union all
select 123 as cust_no, 20231102 as r_date, 1 as yqts
union all
select 123 as cust_no, 20231103 as r_d…
【Python大数据笔记_day07_hive查询】
hive查询
语法结构: SELECT [ALL | DISTINCT] 字段名, 字段名, ...
FROM 表名 [inner | left outer | right outer | full outer | left semi JOIN 表名 ON 关联条件 ]
[WHERE 非聚合条件]
[GROUP BY 分组字段名]
[HAVING 聚合条件]
[ORDER BY 排序字段名 asc | desc]
[CLUSTE…
Hive使用max case when over partition by 实现单个窗口取两个窗口的值(单个开窗函数,实际取两个窗口)
一、Hive开窗函数根据特定条件取上一条最接近时间的数据(单个开窗函数,实际取两个窗口)
针对于就诊业务,一次就诊,多个处方,处方结算时间可能不一致,然后会有多个AI助手推荐用药,会…
【hive遇到的坑】—使用 is null / is not null 对string类型字段进行null值过滤无效
项目场景:
查看测试表test_1,发现表字段classes里面有null值,过滤null值。
--查看
> select * from test_1;
-----------------------------
| test_1.id | test_1.classes |
-----------------------------
| Mary | class 1 …
Java EE-servlet API 三种主要的类
上述的代码如下:
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.i…
hive使用中的参数优化与问题排查
1.使用hive的虚拟列排查错误案例
set hive.exec.rowoffsettrue;
SELECT –输入文件名 INPUT__FILE__NAME, –文件中的块内偏移量 BLOCK__OFFSET__INSIDE__FILE, –文件行偏移量 ROW__OFFSET__INSIDE__BLOCK, * from hdp_lbg_zhaopin_defaultdb.zzdetail where dt‘20201117’…
[Hive] 常见函数
文章目录 字符串函数数值函数随机函数日期和时间函数字符串转时间 聚合函数数组函数结构体函数数组函数映射函数 map正则处理JSON 字符串函数
CONCAT(string1, string2, …):将多个字符串连接成一个字符串。
LENGTH(string):返回字符串的长度。
LOWER…
Hive客户端和Beeline命令行的基本使用
本专栏案例数据集链接: https://download.csdn.net/download/shangjg03/88478038 1.Hive CLI 1.1 命令帮助Help 使用 `hive -H` 或者 `hive --help` 命令可以查看所有命令的帮助,显示如下: usage: hive-d,--define <key=value> Variable subsitution to ap…
Hive特殊函数的使用
Hive特殊函数的使用 with ascastget_json_objectunix_timestampfrom_unixtime with as
在Hive中,WITH AS是一种子查询的用法,用于在查询的开头定义一个临时表达式。它的语法结构如下:
WITH [表达式名称] AS (子查询表达式
)在这个结构中,[表…
Hive创建分区表并插入数据
业务中经常会遇到这种需求:数据每天全量更新,但是要求月底将数据单独保存一份以供后期查询某月节点的信息。这时就要考虑用到Hive的分区表实现,即按照月份创建分区表,相当于新的月份数据保存在新表,进而实现保存了历史…
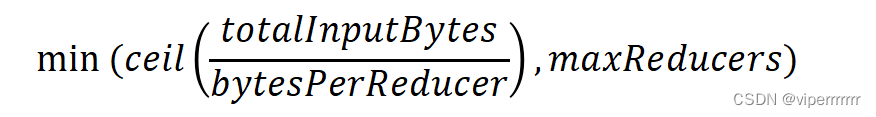
大数据学习(18)-任务并行度优化
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…

JavaEE-cookie和session
本部分内容包括 cookie基本概念,sendcookies和getcookies代码; session基本概念,session实现登陆界面; 上述过程中涉及的代码如下: 1
import javax.servlet.ServletException;
import javax.servlet.annotation.WebSe…

Hive On Spark 概述、安装配置、计算引擎更换、应用、异常解决
文章目录 Hadoop 安装Hive 安装Hive On Spark 与 Spark On Hive 区别Hive On SparkSpark On Hive 部署 Hive On Spark查询 Hive 对应的 Spark 版本号下载 Spark解压 Spark配置环境变量指定 Hadoop 路径在 Hive 配置 Spark 参数上传 Jar 包并更换引擎 测试 Hive On Spark解决依赖…
[shell,hive] 在shell脚本中将hiveSQL分离出去
将Hive SQL语句写在单独的.hql文件中,
然后在shell脚本中调用这些文件来执行Hive查询。
这样可以将SQL语句与shell脚本分离,使代码更加清晰和易于维护。
基本用法
以下是一个示例,展示如何在shell脚本中使用.hql文件执行Hive查询…
Sqoop安装与配置-shell脚本一键安装配置
文章目录 前言一、使用shell脚本一键安装1. 复制脚本2. 增加执行权限3. 执行脚本4. 加载用户环境变量5. 查看是否安装成功 总结 前言
本文介绍了如何使用Shell脚本一键安装Sqoop。Sqoop是一个用于在Apache Hadoop和结构化数据存储(如关系数据库)之间传输…
HiveSQL高级进阶技巧
目录 1.删除2.更新:3.行转列:4.列转行:5.分析函数:6.多维分析7.数据倾斜groupby:join: 掌握下面的技巧,你的SQL水平将有一个质的提升! 1.删除
正常hive删除操作基本都是覆盖原数据&…

大数据毕业设计选题推荐-自媒体舆情分析平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
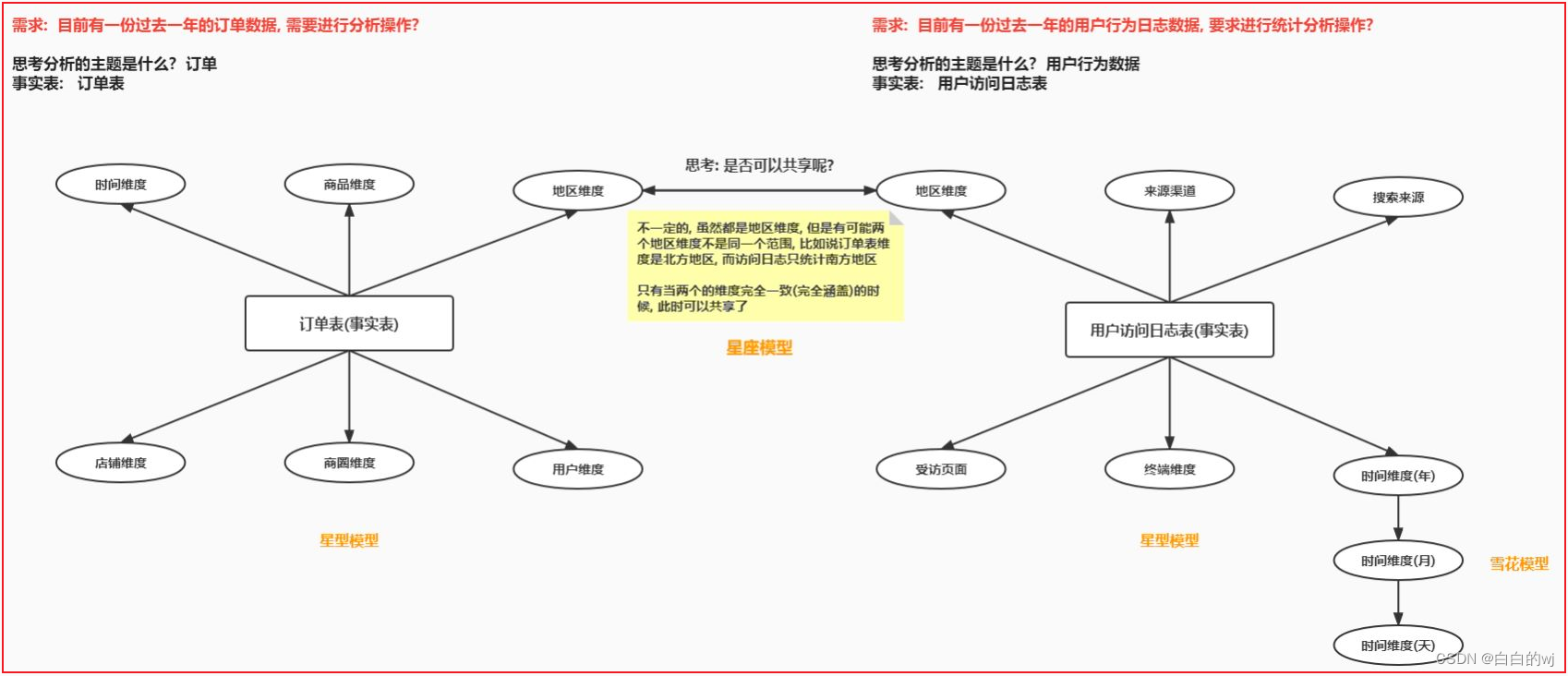
2023.11.22 数据仓库2-维度建模
目录 1.数仓建设方案
2.数仓结构图,项目架构图
2.1项目架构图 2.2数仓结构图 3.建模设计
4.维度建模 什么是事实表: 什么是维度表: 数据发展模式y以及对应的模型
5.数仓建设规范
数据库划分规范
表命名规范
表字段类型规范 1.数仓建设方案 ODS: 源数据层(临时存储层) 贴…
HIVE SQL时间函数
目录 current_timestamp()获取当前时间unix_timestamp()获取当前时区的UNIX时间戳from_unixtime()时间戳转日期函数unix_timestamp(string date)日期转时间戳函数提取日期中的年月日时分秒weekofyear (string date)日期转周函数日期比较函数datediff(string enddate, string st…
hive 报错return code 40000 from org.apache.hadoop.hive.ql.exec.MoveTask解决思路
参考学习 https://github.com/apache/hive/blob/2b57dd27ad61e552f93817ac69313066af6562d9/ql/src/java/org/apache/hadoop/hive/ql/ErrorMsg.java#L47
为啥学习error code 开发过程中遇到以下错误,大家觉得应该怎么办?从哪方面入手呢? 1.百…
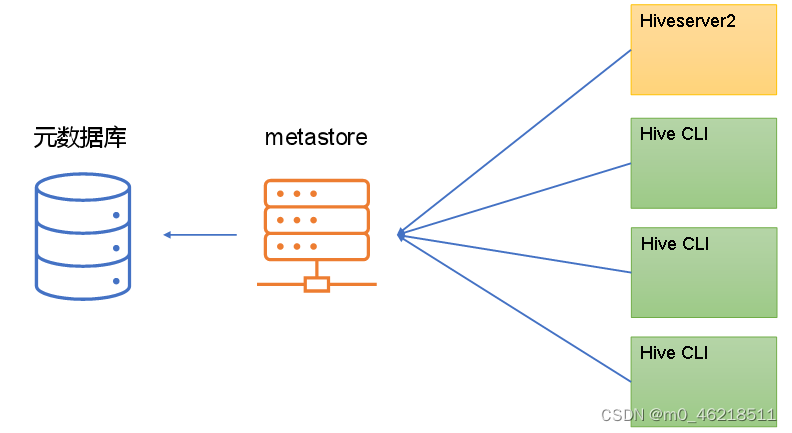
大数据基础设施搭建 - Hive
文章目录 一、上传压缩包二、解压压缩包三、配置环境变量四、初始化元数据库4.1 配置MySQL地址4.2 拷贝MySQL驱动4.3 初始化元数据库4.3.1 创建数据库4.3.2 初始化元数据库 五、启动元数据服务metastore5.1 修改配置文件5.2 启动/关闭metastore服务 六、启动hiveserver2服务6.1…
Hive删除符合条件的记录
Hive在使用中不支持update和delete操作,那么如果想删除部分条件的记录需要怎么操作?本文记录下解决方法。 思路:使用selectwhere选出想要保留的数据,使用insert overwrite向原表覆盖插入数据.
insert overwrite table dbname.tab…
hive两张表实现like模糊匹配关联
testa表(字段a)aaabbacccddddddaaatestb表(字段b)ab1. 使用likeconcat模糊配对
selecta.a
from testa a ,testb b
where a like concat(%,b.b,%)
group by a.a2. 使用locate函数
selecta.a
from testa a ,testb b
where locate(b.b,a.a)>0
group by a.a3. 使用instr函数
sel…
Hive_last_value()
在SQL中,LAST_VALUE()函数是一个窗口函数,用于返回窗口内的最后一个值。窗口函数允许你在一组行上执行计算,这组行与当前行有某种关系。可以将它们想象为与当前行相关的“窗口”。
LAST_VALUE()函数通常与OVER()子句一起使用,后者…

hql面试题之字符串使用split分割,并选择其中的一部分字段的问题
版本:20231109
1.题目:
有两张表,a表有id和abstringr两个字段,b表也有id和bstr两个字段,具体如下 A表:
1abc,bcd,cdf2123,456,789
B表:
1acddef2123456
在a表的abstring字段中用‘,’分割,并取出前两…

hive创建ES外部表过程中的问题
一、缺少jar包:httpclient 报错:
“HiveServer2-Handler-Pool: Thread-696” java.lang.NoClassDefFoundError: org/apache/commons/httpclient/protocol/ProtocolSocketFactory
需要加载commons-httpclient-3.1.jar
二、缺少jar包:eshado…

2023.11.30 -hzmx电商平台建设项目05 - member会员主题建模开发
1.需求说明
1.11各类数据信息说明
说明:公司为了对不同会员进行不同的营销策略,对各类会员的数量都非常敏感,比如注册会员、消费会员、复购会员、活跃会员、沉睡会员。不仅需要看新增数量还要看累积数量。
9个指标:新增注册会员数,累计注册会员数(上一…

root用户启动beeline时报错User: root is not allowed to impers....
原报错信息:
bin/beeline -u jdbc:hive2://hadoop05:10000 -n root
Connecting to jdbc:hive2://hadoop05:10000
23/07/14 08:15:00 [main]: WARN jdbc.HiveConnection: Failed to connect to hadoop05:10000
Could not open connection to the HS2 server. Please…
2023.11.14 hivesql的容器,数组与映射
目录
https://blog.csdn.net/m0_49956154/article/details/134365327?spm1001.2014.3001.5501https://blog.csdn.net/m0_49956154/article/details/134365327?spm1001.2014.3001.5501
8.hive的复杂类型
9.array类型: 又叫数组类型,存储同类型的单数据的集合 10.struct类型…
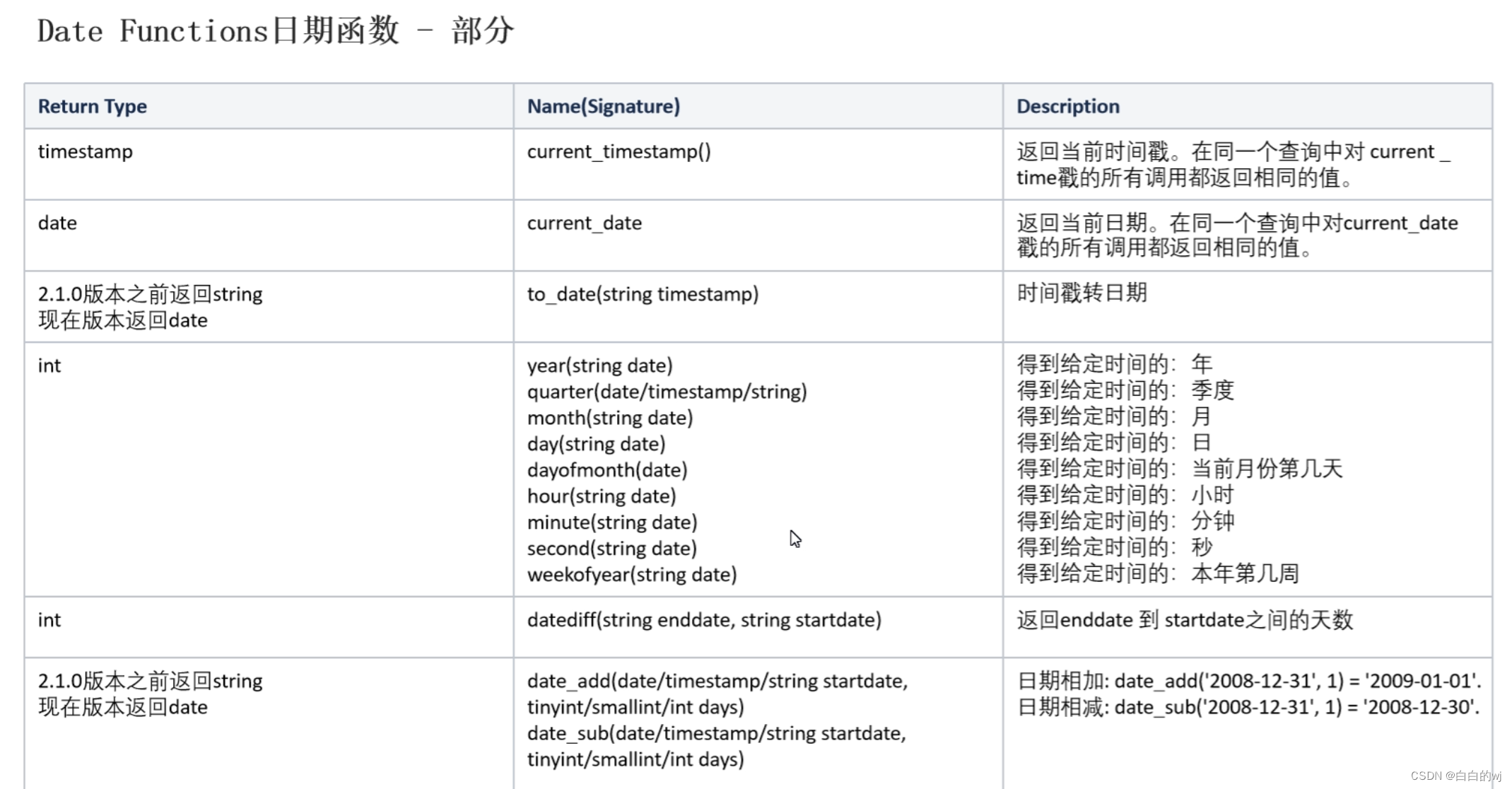
2023.11.15 hive sql之函数标准,字符串,日期,数学函数
目录 一.函数分类标准
二.查看官方函数,与简单演示
三.3种类型函数演示
四.字符串函数
1.常见字符串函数
2.索引函数 解析函数
五.日期函数 1.获取当前时间 2.获取日期相关 3.周,季度等计算
4.时间戳
六.数学函数 一.函数分类标准
目前hive三大标准 UDF:(…
Hive开窗函数根据特定条件取上一条最接近时间的数据(根据条件取窗口函数的值)
一、Hive开窗函数根据特定条件取上一条最接近时间的数据(单个开窗函数,实际取两个窗口)
针对于就诊业务,一次就诊,多个处方,处方结算时间可能不一致,然后会有多个AI助手推荐用药,会…

2023.11.17 hadoop之HDFS进阶
目录
HDFS的机制
edits和fsimage文件
HDFS的存储原理
写入数据原理:
读取数据原理:
元数据简介
元数据存储流程
HDFS安全机制
HDFS归档机制
HDFS垃圾桶机制 接着此前的内容
https://blog.csdn.net/m0_49956154/article/details/134298109?spm1001.2014.3001.5501
…

三十分钟学会Hive
Hive的概念与运用
Hive 是一个构建在Hadoop 之上的数据分析工具(Hive 没有存储数据的能力,只有使用数据的能力),底层由 HDFS 来提供数据存储,可以将结构化的数据文件映射为一张数据库表,并且提供类似 SQL …
Hive效率优化记录
Hive是工作中常用的数据仓库工具,提供存储在HDFS文件系统,将结构化数据映射为一张张表以及提供查询和分析功能。 Hive可以存储大规模数据,但是在运行效率上不如传统数据库,这时需要懂得常见场景下提升存储或查询效率的方法&#x…
Apache Hive源码阅读环境搭建
前置软件: JDK 1.8 Maven 3.3.9
1 下载源码
# 下载源码
git clone https://github.com/apache/hive.gitcd hive# 查看标签
git tag# 切换到要阅读的指定版本的tag
git checkout rel/release-2.1.02 编译源码
mvn clean install -DskipTests执行报错
日志如下
E…
Hive语法,函数--学习笔记
1,排序处理
1.1cluster by排序
,在Hive中使用order by排序时是全表扫描,且仅使用一个Reduce完成。 在海量数据待排序查询处理时,可以采用【先分桶再排序】的策略提升效率。此时, 就可以使用cluster by语法。 cluster…

2023.11.19 hadoop之MapReduce
目录
1.简介
2.分布式计算框架-Map Reduce
3.mapreduce的步骤
4.MapReduce底层原理
map阶段
shuffle阶段
reduce阶段 1.简介
Mapreduce是一个分布式运算程序的编程框架,是用户开发“基于hadoop的数据分析应用”的核心框架;
Mapreduce核心功能是…

Hive 定义变量 变量赋值 引用变量
Hive 定义变量 变量赋值 引用变量
变量
hive 中变量和属性命名空间
命名空间权限描述hivevar读写用户自定义变量hiveconf读写hive相关配置属性system读写java定义额配置属性env只读shell环境定义的环境变量
语法 Java对这个除env命名空间内容具有可读可写权利; …
JavaWeb——第五章 Servlet
第五章 Servlet 一 Servlet简介1.1 动态资源和静态资源1.2 Servlet简介 二 Servlet开发流程2.1 目标2.2 开发过程 三 Servlet注解方式配置3.1 WebServlet注解源码3.2 WebServlet注解使用 四 Servlet生命周期4.1 生命周期简介4.2 生命周期测试4.3 生命周期总结 五 Servlet继承结…

hive企业级调优策略之Join优化
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
Join算法概述
Hive拥有多种join算法,包括Common Join,Map …
使用 PySpark 进行数据清洗与 JSON 格式转换的实践详解(保姆级编码教程)
在大数据处理中,PySpark 提供了强大的工具来处理海量数据,特别是在数据清洗和转换方面。本文将介绍如何使用 PySpark 进行数据清洗,并将数据格式转换为 JSON 格式的实践。
简介
PySpark 是 Apache Spark 的 Python API,可用于处…
hive企业级调优策略之如何用Explain查看执行计划
Explain执行计划概述
Explain呈现的执行计划,由一系列Stage组成,这一系列Stage具有依赖关系,每个Stage对应一个MapReduce Job,或者一个文件系统操作等。 若某个Stage对应的一个MapReduce Job,其Map端和Reduce端的计算…
【Hive-Sql】Hive 处理 13 位时间戳得到年月日时分秒(北京时间)
【Hive-Sql】Hive 处理 13 位时间戳得到年月日时分秒(北京时间) 1)需求2)实现 1)需求
使用 Hive 自带函数 将 13位 时间戳转成年月日时分秒(北京时间),格式样例:‘2023-…
Hive的四种排序方法
Hive的四种排序方法
hive排序方法,hive的排序方式 hive有四种排序方法: ORDER BY 、SORT BY 、DISTRIBUTE BY 、CLUSTER BY
0. 测试数据准备
--数据准备
WITH t_emp_info AS (
SELECT * FROM (VALUES (1001, 研发部, 16000 ), (1002, 市场部, 17000 ), (1003, 销售部, 1100…
Servlet技术之HttpServletRequest和HttpServletResponse
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 Servlet技术j详解1 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、Servlet简介二、S…
8-Hive原理与技术
单选题 题目1:按粒度大小的顺序,Hive数据被分为:数据库、数据表、桶和什么 选项: A 元祖 B 栏 C 分区 D 行 答案:C ------------------------------ 题目2:以下选项中,哪种类型间的转换是被Hive查询语言…
JeecgBoot 框架升级 Spring Boot 3.1.5
Spring Boot
从 2.7.10升级到3.1.5有以下几个点需要注意。
JDK版本支持从JDK 17-19版本javax.servlet切换到jakarta.servletspring.redis配置切换为spring.data.redisSpring Cloud 2022.0.4Spring Cloud Alibaba 2022.0.0.0
除以上三点外,其它都是平滑升级&#…

二百一十一、Flume——Flume实时采集Linux中的Hive日志写入到HDFS中(亲测、附截图)
一、目的
为了实现用Flume实时采集Hive的操作日志到HDFS中,于是进行了一场实验
二、前期准备
(一)安装好Hadoop、Hive、Flume等工具 (二)查看Hive的日志在Linux系统中的文件路径
[roothurys23 conf]# find / -name…
WIN10下解决HIVE 初始化MYSQL表报错:Unknown version specified for initialization
今天本地WINDOWS装HIVE,走到最后一步初始化数据库死活不通过:
D:\hive\hive-rel-release-3.1.3\bin\ext>hive --service schematool -dbType mysql -initSchema --verbose
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found bind…

kyuubi整合flink yarn session mode
目录 概述配置flink 配置kyuubi 配置kyuubi-defaults.confkyuubi-env.shhive 验证启动kyuubibeeline 连接使用hive catlogsql测试 结束 概述
flink 版本 1.17.1、kyuubi 1.8.0、hive 3.1.3、paimon 0.5
整合过程中,需要注意对应的版本。
注意以上版本
配置
ky…

hive-3.1.2环境安装实验
1.修改hadoop相关参数
1-修改core-site.xml
[bigdata@master hive]$ vim /opt/module/hadoop/etc/hadoop/core-site.xml
<!-- 配置该bigdata(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.bigdata.hosts</name><va…
Hive HWI 配置
前言
1、下载安装好hive后,发现hive有hwi界面功能,研究下是否可以运行,于是使用hive –service hwi命令启动hwi界面报错。 启动hwi功能 2、访问192.168.126.110:9999/hwi,发现访问错误 一、HWI介绍
HWI(Hive Web Int…
Hive中parquet压缩格式分区表的跨集群迁移记录
文章目录 环境与需求集群环境需求描述 操作步骤STEP 1STEP 2STEP 3STEP 4STEP 5STEP 6 环境与需求
集群环境
华为FushionInsight A
华为FushionInsight B
华为集群管理机 local
Hive 3.1.0
HDFS 3.3.1
需求描述
从华为A集群中将我们的数据迁移到华为B集群,其…
Hive的metastore服务的两种运行模式
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口
1.metastore运行模式
metastore有两种运行模式,分别为嵌入式模式和独立服务模式。下面分别对两种模式进行说明:
(1)嵌入式模式 (2&#x…

彷徨 | Hive的介绍 , 安装 , 配置以及启动
1 什么是Hive
首先 , Hive是一个 sql 工具;它能接收用户输入的sql语句,然后把它翻译成mapreduce程序对HDFS上的数据进行查询、运算,并返回结果,或将结果存入HDFS;Hive是基于Hadoop的一个数据仓库工具(离线)࿰…
Hive2.1.0集成Tez
Tez是什么? Tez是Hontonworks开源的支持DAG作业的计算框架,它可以将多个有依赖的作业转换为一个作业从而大幅提升MapReduce作业的性能。Tez并不直接面向最终用户——事实上它允许开发者为最终用户构建性能更快、扩展性更好的应用程序 如何编译 Tez最新的…
Hue+Hive临时目录权限不够解决方案
[sizemedium]安装[urlhttp://qindongliang.iteye.com/blog/2212619]Hue[/url]后,可能会分配多个账户给一些业务部门操作hive,虽然可以正常写SQL提交任务,但是由于不同账户在生成MR任务时写入的临时文件,导致临时目录权限改变&…
hive自定义udf实现md5功能
Hive自定义UDF实现md5算法Hive发展至今,自身已经非常成熟了,但是为了灵活性,还是提供了各种各样的 插件的方式,只有你想不到的,没有做不到的,主流的开源框架都有类似的机制,包括Hadoop,Solr,Hba…
Hive使用注意事项
1)注意表中的数据是存储在hdfs中的,但是表的名称、字段信息是存储在metastore中的 2)中文乱码问题:
中文乱码的原因是因为hive数据库里面的表都是latin1编码的,中文本来就会显示乱码,但是又不能修改整个数据库里面所有…
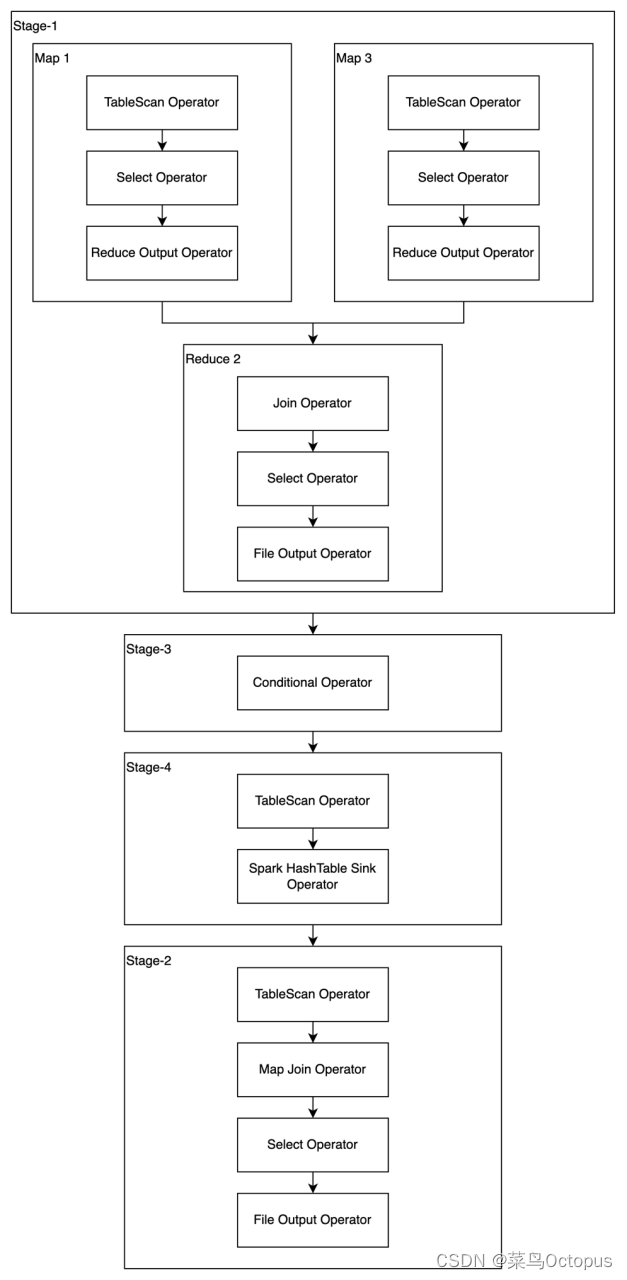
Hive on Spark调优(大数据技术7)
第7章 数据倾斜优化
7.1 数据倾斜说明 数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往一个Reduce,进而导致该Reduce所需的时间远…

阿里云异构数据源离线同步工具之DataX
阿里云异构数据源离线同步工具之DataXDataXDataX概述框架设计插件体系核心架构更多介绍安装DataX系统要求下载与安装DataX基本使用1.官方演示案例2.从stream读取数据并打印到控制台查看配置模板创建作业配置文件启动DataX3.从MySQL抽取数据到HDFS获取配置模板创建作业配置文件启…
【Trino实战】CentOS 部署Trino 集成Hive Elasticsearch
CentOS 部署Trino 集成Hive Elasticsearch
[TOC]
前提条件 64位CentOS操作系统 调整用户的文件描述符的大小。官网推荐以下限制,通常可以在/etc/security/limits.conf中设置: trino soft nofile 131072
trino hard nofile 13107264位JDK17.0.3 建议在…

初学hadoop——Hive Java API的使用
以词频统计算法为例,来介绍怎么在具体应用中使用Hive
一、 创建input目录,output目录会自动生成
其中input为输入目录,output目录为输出目录。
命令:
cd /usr/local/hadoop
mkdir input 二、 在input文件夹中创建两个测试文件…

hive复合类型:array、map、struct
一 基本概念
类型描述语法举例array一组相同类型数据的集合ARRAY<data_type>如果数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用map一组键-值对数据的集合,使用key可以访问值MAP<primitive_type, data_type>如果某列…

Hive 运行环境搭建
文章目录Hive 运行环境搭建一、Hive 安装部署1、安装hive2、MySQL 安装3、Hive 元数据配置到 Mysql1) 拷贝驱动2) 配置Metastore 到 MySQL3) 再次启动Hive4) 使用元数据服务的方式访问Hive二、使用Dbaver连接HiveHive 运行环境搭建
HIve 下载地址:http://archive.a…
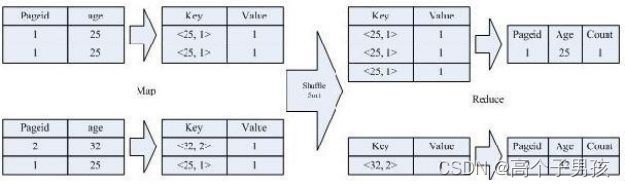
Hive面试题-HQL转换MapReduce底层核心逻辑剖析
视频可查看:https://www.bilibili.com/video/BV1RV41147Tb/?spm_id_from333.999.0.0&vd_source3ba3c3ba31427f60d734ede7a948de4a 原文地址:Hive学习之路 (二十)Hive 执行过程实例分析 - 扎心了,老铁 - 博客园 (c…
spark链接hive时踩的坑
使用spark操作hive,使用metastore连接hive,获取hive的数据库时,当我们在spark中创建数据库的时候,创建成功。 同时hive中也可以看到这个数据库,建表插入数据也没有问题,但是当我们去查询数据库中的数据时&a…
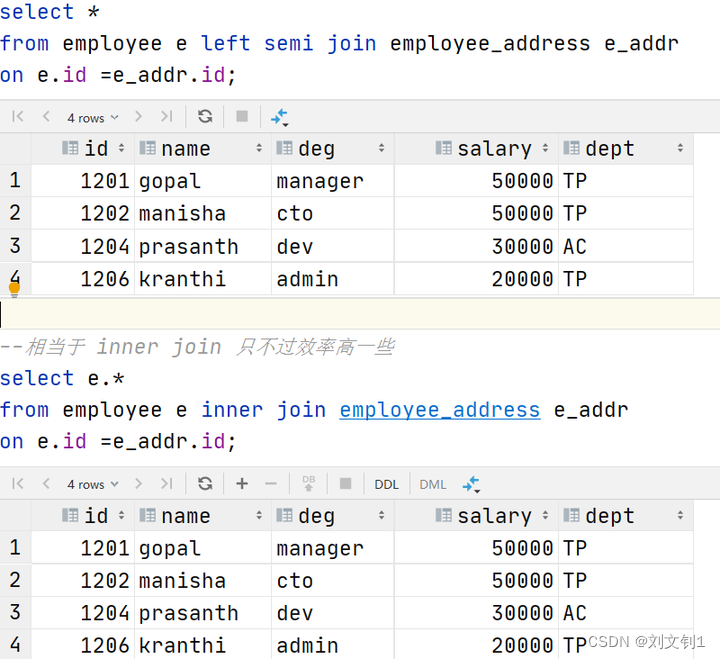
Hive SQL的各种join总结
说明
Hive join语法有6中连接
inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左半开连接)、cr…

数据仓库工具Hive
1. 请解释Hive是什么,它的主要用途是什么?
Hive是一个基于Hadoop的数据仓库工具,主要用于处理和分析大规模结构化数据。它可以将结构化的数据文件映射为一张数据库表,并提供类似SQL的查询功能,将SQL语句转换为MapRedu…

二百一十五、Flume——Flume拓扑结构之复制和多路复用的开发案例(亲测,附截图)
一、目的
对于Flume的复制和多路复用拓扑结构,进行一个小的开发测试
二、复制和多路复用拓扑结构 (一)结构含义
Flume 支持将事件流向一个或者多个目的地。
(二)结构特征
这种模式可以将相同数据复制到多个channe…

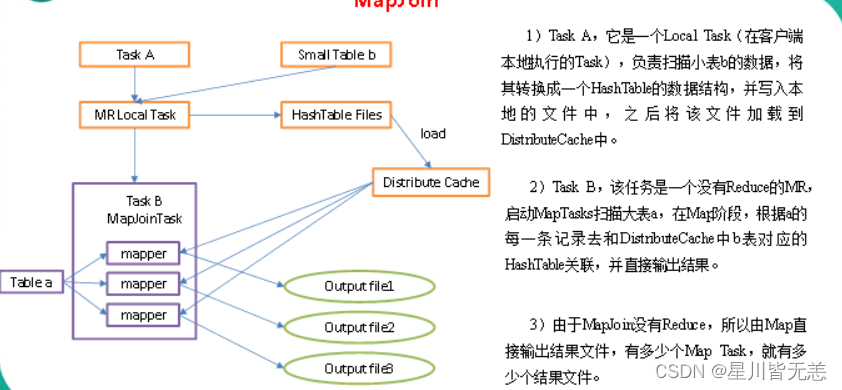
大数据技术之Hive(超级详细)
第1章 Hive入门
1.1 什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL转化成MapReduce程序 …

Sqoop安全性:确保安全的数据传输
确保数据传输的安全性在大数据处理中至关重要。Sqoop作为一个用于数据传输的工具,也提供了多种安全性措施,以确保数据在传输过程中的机密性和完整性。本文将深入探讨Sqoop的安全性特性,提供详细的示例代码和全面的内容,以帮助大家…
【Hive】——DDL(CREATE TABLE)
1 CREATE TABLE 建表语法 2 Hive 数据类型 2.1 原生数据类型 2.2 复杂数据类型 2.3 Hive 隐式转换 2.4 Hive 显式转换 2.5 注意 3 SerDe机制 3.1 读写文件机制 3.2 SerDe相关语法 3.2.1 指定序列化类(ROW FORMAT SERDE ‘’) 3.2.2 指定分隔符࿰…
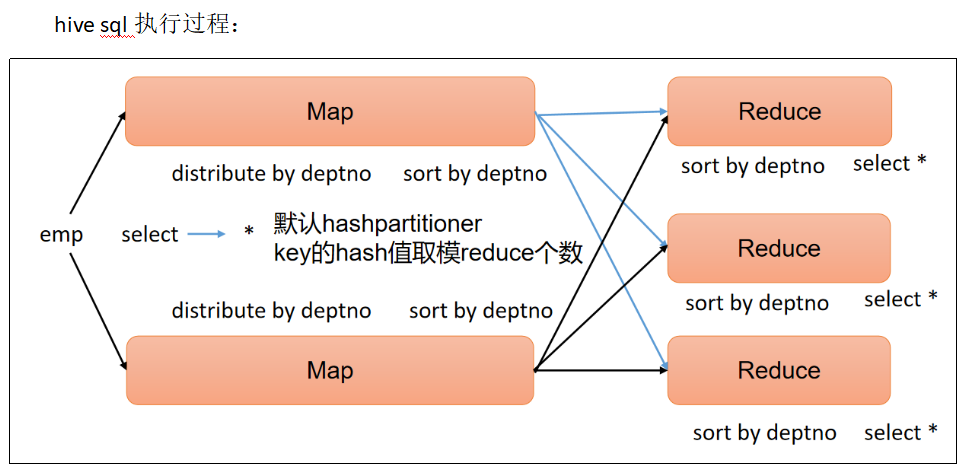
hive聚合函数之排序
1 全局排序(Order By)
Order By:全局排序,只有一个Reduce。 (1).使用Order By子句排序 asc(ascend):升序(默认) desc(descend)&#…

大数据技术12:Hive简介及核心概念
前言:2007年,编写Pig虽然比MapReduce编程简单,但是还是要学习。于是Facebook发布了Hive,支持使用SQL语法进行大数据计算,写个Select语句进行数据查询,Hive会将SQL语句转化成MapReduce计算程序。这样&#x…

Sqoop故障排除指南:处理错误和问题
故障排除是每位数据工程师和分析师在使用Sqoop进行数据传输时都可能遇到的关键任务。Sqoop是一个功能强大的工具,但在实际使用中可能会出现各种错误和问题。本文将提供一个详尽的Sqoop故障排除指南,涵盖常见错误、问题和解决方法,并提供丰富的…

【Hive】——DDL(PARTITION)
1 增加分区
1.1 添加一个分区 ALTER TABLE t_user_province ADD PARTITION (provinceBJ) location/user/hive/warehouse/test.db/t_user_province/provinceBJ;必须自己把数据加载到增加的分区中 hive不会帮你添加
1.2 一次添加多个分区 ALTER TABLE table_name ADD PARTITION…
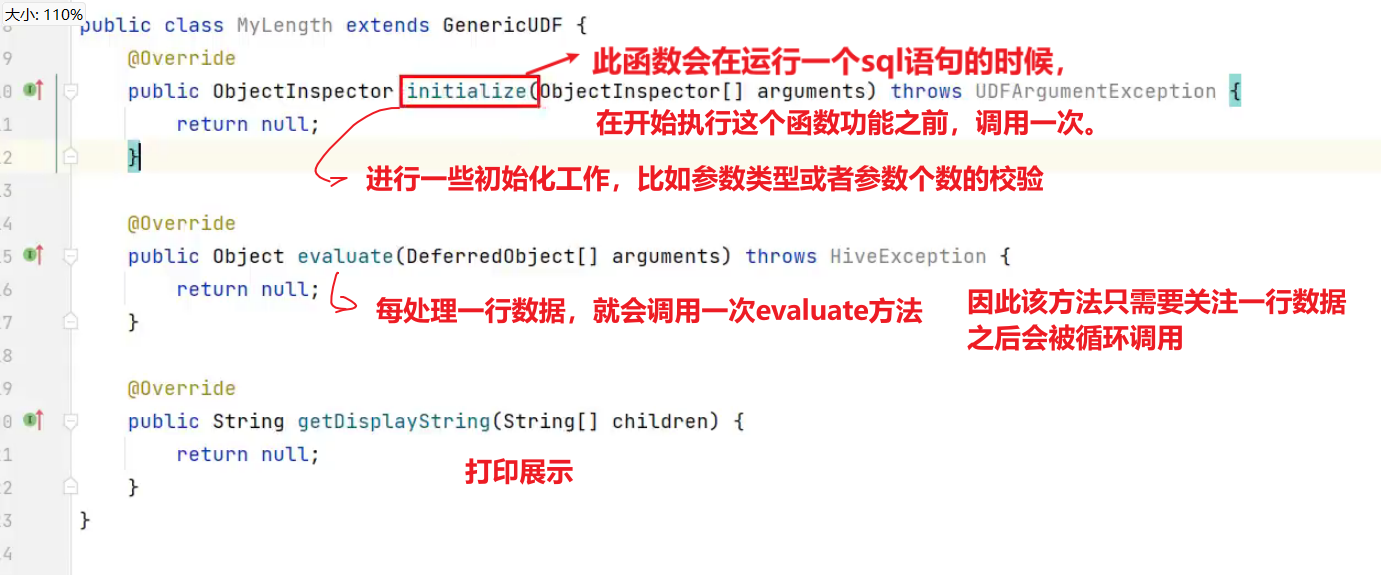
【Hive_03】单行函数、聚合函数、窗口函数、自定义函数、炸裂函数
1、函数简介2、单行函数2.1 算术运算函数2.2 数值函数2.3 字符串函数(1)substring 截取字符串(2)replace 替换(3)regexp_replace 正则替换(4)regexp 正则匹配(5ÿ…

Sqoop数据导入到Hive表的最佳实践
将数据从关系型数据库导入到Hive表是大数据领域中的常见任务之一,Sqoop是一个强大的工具,可以帮助实现这一目标。本文将提供Sqoop数据导入到Hive表的最佳实践,包括详细的步骤、示例代码和最佳建议,以确保数据导入过程的高效性和可…
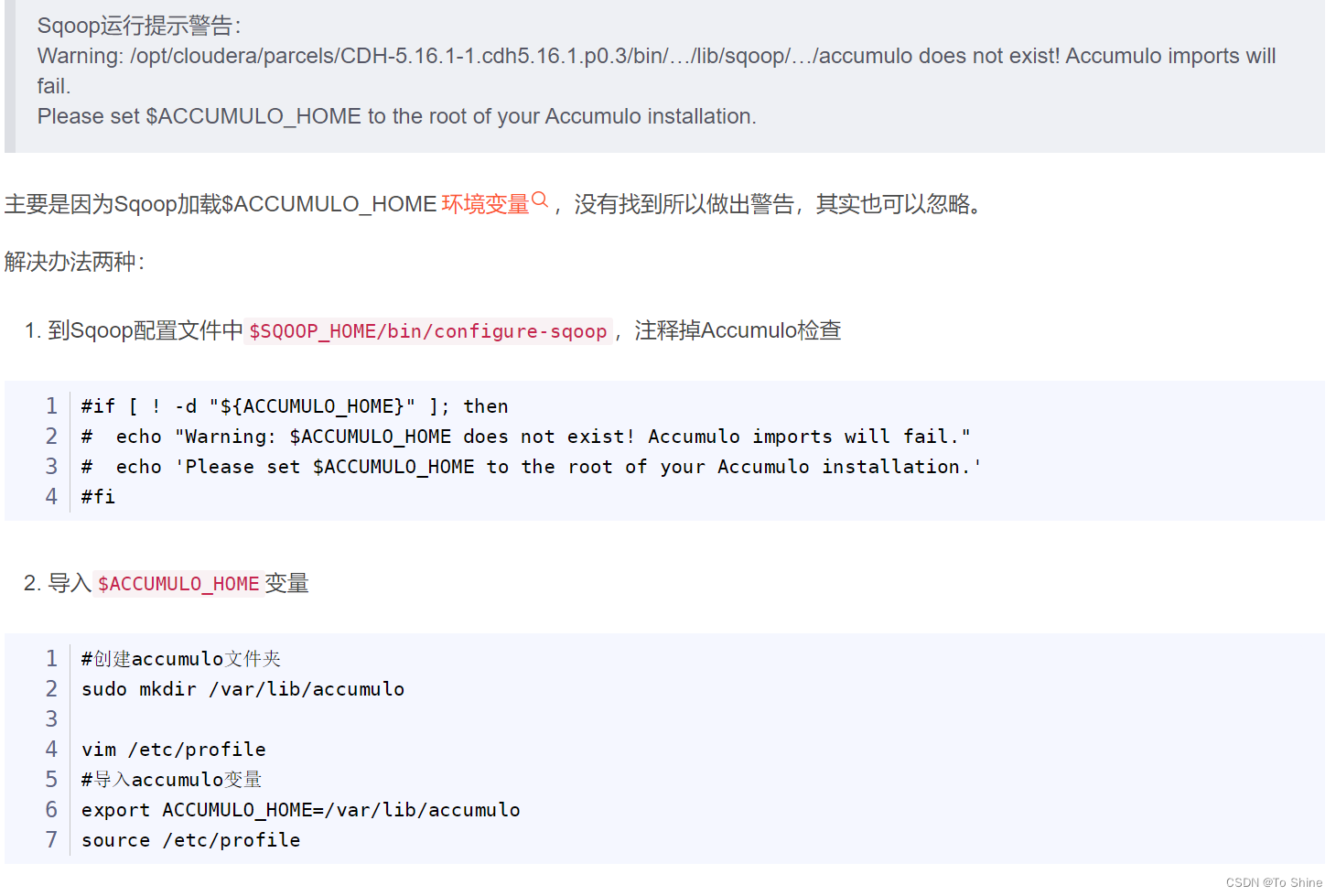
用户行为分析遇到的问题-ubantu16,hadoop3.1.3
用户行为分析传送门 我的版本 ubantu16 hadoop 3.1.3 habse 2.2.2 hive3.1.3 zookeeper3.8.3 sqoop 1.46/1.47 我sqoop把MySQL数据往hbase导数据时候有问题 重磅:大数据课程实验案例:网站用户行为分析(免费共享)
用户行为分析-小…

Hive06_基础查询
HIVE 查询语句
1 查询语句语法:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMI…

Hive详解、配置、数据结构、Hive CLI
一、Hive 认识
1. Hive 应用
问题:公司的经营状况?
主题一:财务现金流指标1.1:净现金流入/流出量指标1.2:现金转换周期预算执行状况指标2.1:预算内成本控制指标2.2:预算与实际支出的差异
主题…


HttpSession的使用
1 HttpSession 概述
在 Java Servlet API 中引入 session 机制来跟踪客户的状态。session 指的是在一段时间内,单个客户与 Web 服务器的一连串相关的交互过程。在一个 session 中,客户可能会多次请求访问同一个网页,也有可能请求访问各种不同…
Hive实战:实现数据去重
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、基于HDFS数据文件创建Hive外部表4、利用Hive SQL实…
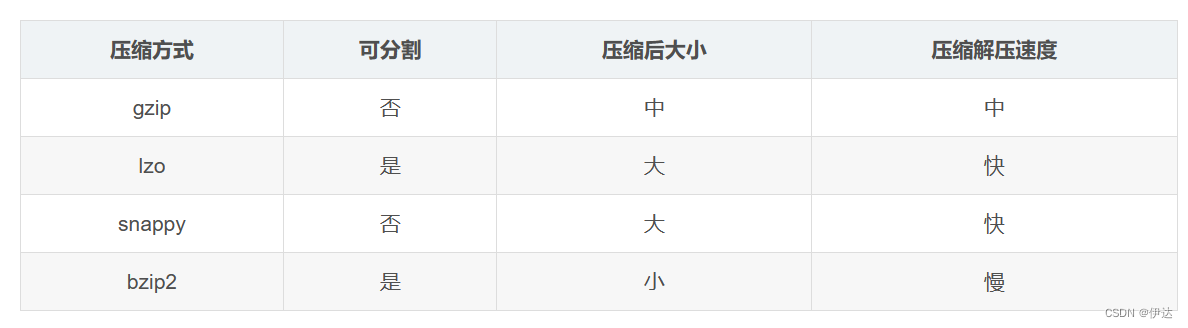
【大数据进阶第三阶段之Hive学习笔记】Hive查询、函数、性能优化
【大数据进阶第三阶段之Hive学习笔记】Hive安装-CSDN博客
【大数据进阶第三阶段之Hive学习笔记】Hive常用命令和属性配置-CSDN博客
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门-CSDN博客
【大数据进阶第三阶段之Hive学习笔记】Hive查询、函数、性能优化-CSDN博客 ——…
【Hive】——函数案例
1 Hive 多字节分隔符处理
1.1 默认规则
Hive默认序列化类是LazySimpleSerDe,其只支持使用单字节分隔符(char)来加载文本数据,例如逗号、制表符、空格等等,默认的分隔符为”\001”。根据不同文件的不同分隔符…
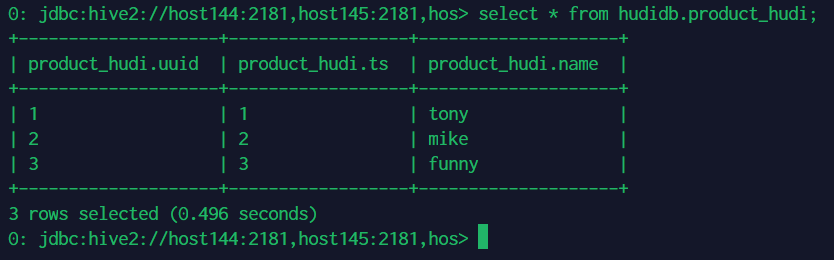
【大数据】Hudi HMS Catalog 完全使用指南
Hudi HMS Catalog 完全使用指南 1.Hudi HMS Catalog 基本介绍2.在 Flink 中写入数据3.在 Flink SQL 中查看数据4.在 Spark 中查看数据5.在 Hive 中查看数据 1.Hudi HMS Catalog 基本介绍
功能亮点:当 Flink 和 Spark 同时接入 Hive Metastore(HMS&#…

Hive02_基本使用,常用命令
一、Hive基本概念
1 什么是 Hive
1)hive 简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
2&#…
大数据-Hive练习-环比增长率、同比增长率、复合增长率
目录
🥙12.1 环比增长率
1. 概述
2. 公式
3. 示例
4.练习-需求:计算各类商品的月环比增长率
🥙12.2 同比增长率
1. 概述
2. 公式
3. 示例
4. 练习-需求:计算各类商品的月同比增长率
🥙12.3 复合增长率
1. 概述
2. 公式
3. 示例…

Hive实战:词频统计
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据文件1、在虚拟机上创建文本文件2、将文本文件上传到HDFS指定目录 (二)实现步骤1、启动Hive Metastore服务2、启动Hive客户端3、基于HDFS文件创建外部表4、利用Hive SQL…
Cookie的详解使用(创建,获取,销毁)
文章目录 Cookie的详解使用(创建,获取,销毁)1、Cookie是什么2、cookie的常用方法3、cookie的构造和获取代码演示SetCookieServlet.javaGetCookieServlet.javaweb.xml运行结果如下 4、Cookie的销毁DestoryCookieServletweb.xml运行…
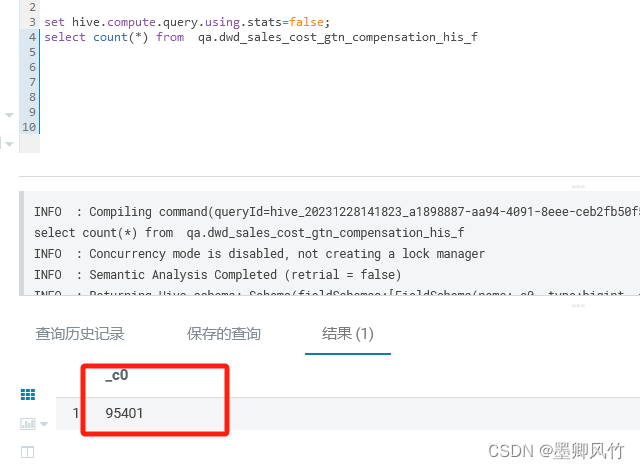
hive在执行elect count(*) 没有数据显示为0(实际有数据)
set hive.compute.query.using.statsfalse; 是 Hive 的一个配置选项。它的含义是禁用 Hive 在执行查询时使用统计信息。
在 Hive 中,统计信息用于优化查询计划和执行。当该选项设置为 false 时,Hive 将不会使用任何统计信息来帮助决定查询的执行计划。这…

Hive集群出现报错信息解决办法
一、报错信息:hive> show databases;FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient 解决办法:1.删除mysql中的元数据库(metastore࿰…
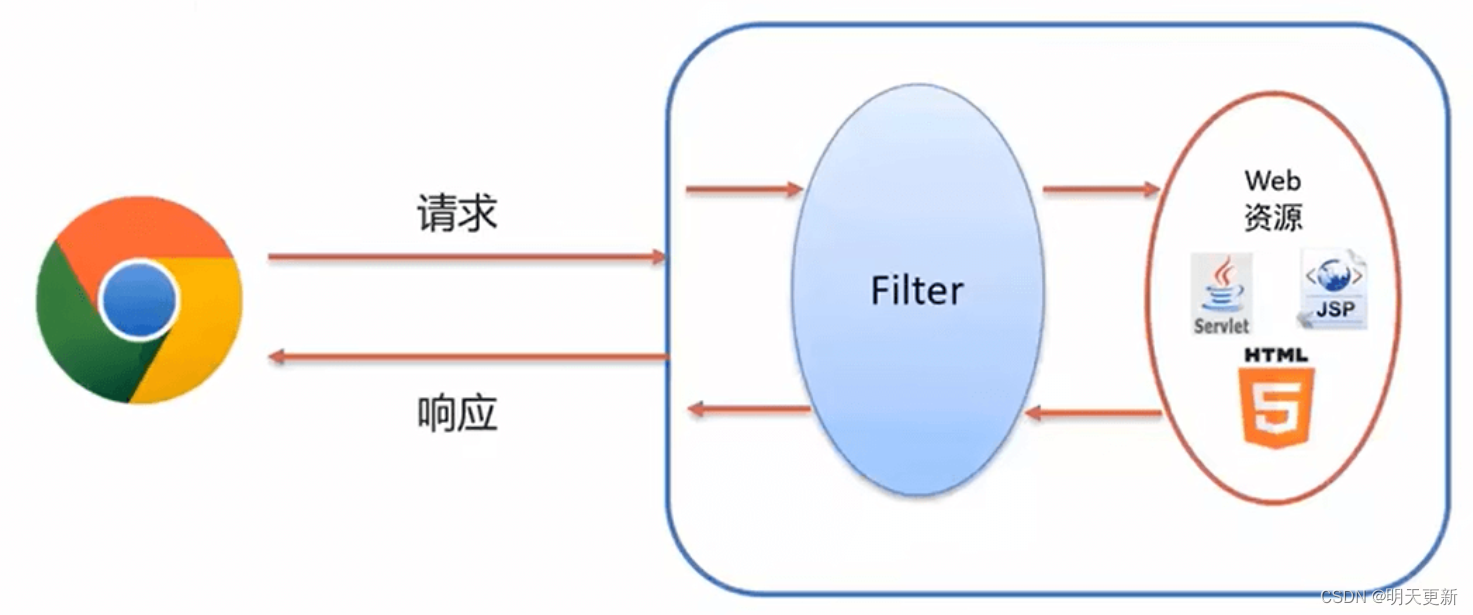
Filter过滤器的使用!!!
什么是过滤器
当浏览器向服务器发送请求的时候,过滤器可以将请求拦截下来,完成一些特殊的功能,比如:编码设置、权限校验、日志记录等。 过滤器执行流程 过滤器的使用:
/** Copyright (c) 2020, 2023, All rights …
接收Kafka数据并消费至Hive表
1 Hive客户端方案
将Kafka中的数据消费到Hive可以通过以下简单而稳定的步骤来实现。这里假设的数据是以字符串格式存储在Kafka中的。
步骤: 创建Hive表: 使用Hive的DDL语句创建一个表,该表的结构应该与Kafka中的数据格式相匹配。例如&#…

删除和清空Hive外部表数据
外部表和内部表区别
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table); 区别: 内部表数据由Hive自身管理,外部表数据由HDFS管理; …

使用REQUESTDISPATCHER对象调用错误页面
使用REQUESTDISPATCHER对象调用错误页面 问题陈述
InfoSuper公司已经创建了一个动态网站。发生错误时,浏览器中显示的堆栈跟踪很难理解。公司的系统分析师David Wong让公司的软件程序员Don Allen创建自定义错误页面。servlet引发异常时,应使用RequestDisapatcher对象向自定义…
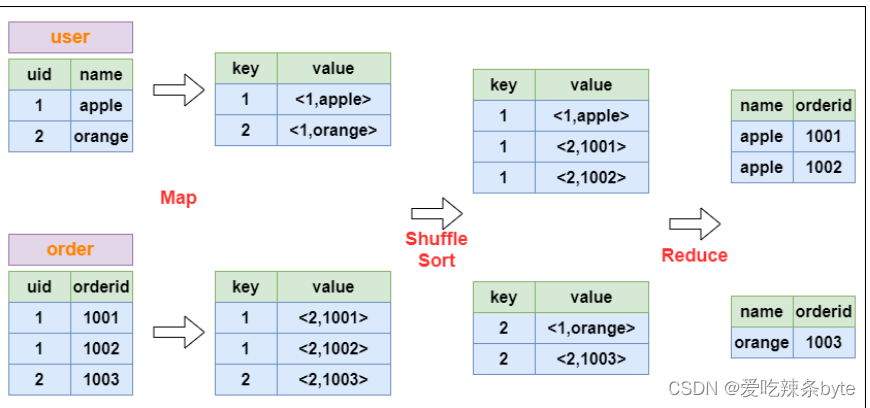
Hive SQL编译成MapReduce任务的过程
一、 Hive 底层执行架构
1.1 Hive底层架构 1 )用户接口: Client CLI ( command-line interface )、 JDBC/ODBC(jdbc 访问 hive) 、 WEBUI (浏览器访问 hive ) 2 )元数据: Metas…
Hive的排序——order by 、sort by、distribute by 、cluster by
Hive中的排序通常涉及到order by 、sort by、distribute by 、cluster by
一、语法 selectcolumn1,column2, ...
from table
[where 条件]
[group by column]
[order by column]
[cluster by column| [distribute by column] [sort by column]
[limit [offset,] rows];
…
Hive调优——count distinct去重优化
离线数仓开发过程中经常会对数据去重后聚合统计,而对于大数据量来说,count(distinct ) 操作消耗资源且查询性能很慢,以下是调优的方式。
解决方案一:group by 替代
原sql 如下:
#7日、14日的app点击的用户数&#x…
(03)Hive的相关概念——分区表、分桶表
目录
一、Hive分区表
1.1 分区表的概念
1.2 分区表的创建
1.3 分区表数据加载及查询
1.3.1 静态分区
1.3.2 动态分区
1.4 分区表的本质及使用
1.5 分区表的注意事项
1.6 多重分区表
二、Hive分桶表
2.1 分桶表的概念
2.2 分桶表的创建
2.3 分桶表的数据加载
2.4 …
(01)Hive的相关概念——架构、数据存储、读写文件机制
目录
一、架构及组件介绍
1.1 Hive整体架构
1.2 Hive组件
1.3 Hive数据模型(Data Model)
1.3.1 Databases
1.3.2 Tables
1.3.3 Partitions
1.3.4 Buckets
二、Hive读写文件机制
2.1 SerDe 作用
2.2 Hive读写文件流程
2.2.1 读取文件的过程
…
(09)Hive——CTE 公共表达式
目录
1.语法 2. 使用场景
select语句
chaining CTEs 链式
union语句
insert into 语句
create table as 语句
前言 Common Table Expressions(CTE):公共表达式是一个临时的结果集,该结果集是从with子句中指定的查询派生而来…
Hive自定义函数详解
1.hive函数各种命令
查看系统自带的函数
hive> show functions;
-- 显示自带的函数的用法
hive> desc function upper;
-- 详细显示自带的函数的用法
hive> desc function extended upper;
-- 添加jar包到hive中
add jar /data/xx.jar;
-- 创建自定义函数
create fu…
Hive拉链表设计、实现、总结
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 环境介绍实现1. 初始化拉链表2. 后续拉链表数据的更新 总结彩蛋 - 想清空表的数据:转成内部表,清空数据后,再转成外部表,将分区目录删掉&am…
Hive使用双重GroupBy解决数据倾斜问题
文章目录 1.数据准备2.双重group by实现 解决数据倾斜2.1 第一层加盐group by2.2 第二层去盐group by 1.数据准备
create table wordcount(a string) row format delimited fields terminated by ‘,’;
load data local inpath ‘opt/2.txt’ into table wordcount;
hive (…
Hive表加工为知识图谱实体关系表标准化流程
文章目录 1 对源数据静态文件的加工1.1 分隔符的处理情况1.2 无法通过分隔符以及包围符区分字段1.3 数据中存在回车换行符 2 CSV文件导入Hive的建表2.1 包围符作用和功能2.2 Hive的建表导入2.3 数据文件导入 3 对Hive表中数据的清洗3.1 数据质量检查3.2 标准导图表的构建3.3 随…
安装Hadoop:Hadoop的单机模式、伪分布式模式——备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项
前言
Hadoop包括三种安装模式:
单机模式:只在一台机器上运行,存储是采用本地文件系统,没有采用分布式文件系统HDFS;伪分布式模式:存储采用分布式文件系统HDFS,但是,HDFS的名称节点…
Hive07_多表查询
HIVE多表查询
1 Join 语句
1) 等值 Join
Hive 支持通常的 SQL JOIN 语句。
1)案例实操 (1)根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
hive (default)> select e.empno, e.ename,…
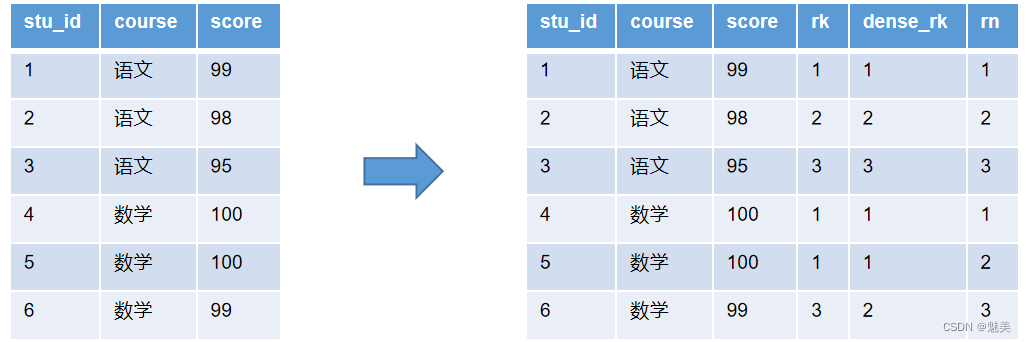
Hive3.1.3基础
参考B站尚硅谷 目录 什么是HiveHive架构原理 Hive安装Hive安装地址Hive安装部署安装Hive启动并使用Hive MySQL安装安装MySQL配置MySQL 配置Hive元数据存储到MySQL配置元数据到MySQL Hive服务部署hiveserver2服务metastore服务编写Hive服务启动脚本(了解)…
Hive之set参数大全-16
配置 HiveServer2 中 Tez Workload Manager (WM) Application Master (AM) 注册的超时时间
在 Hive 中,hive.server2.tez.wm.am.registry.timeout 是一个参数,用于配置 HiveServer2 中 Tez Workload Manager (WM) Application Master (AM) 注册的超时时…

ServletResponse接口
ServletResponse接口
ServletContext接口向servlet提供关于其运行环境的信息。上下文也称为Servlet上下文或Web上下文,由Web容器创建,用作ServletContext接口的对象。此对象表示Web应用程序在其执行的上下文。Web容器为所部署的每个Web应用程序创建一个ServletContext对象。…
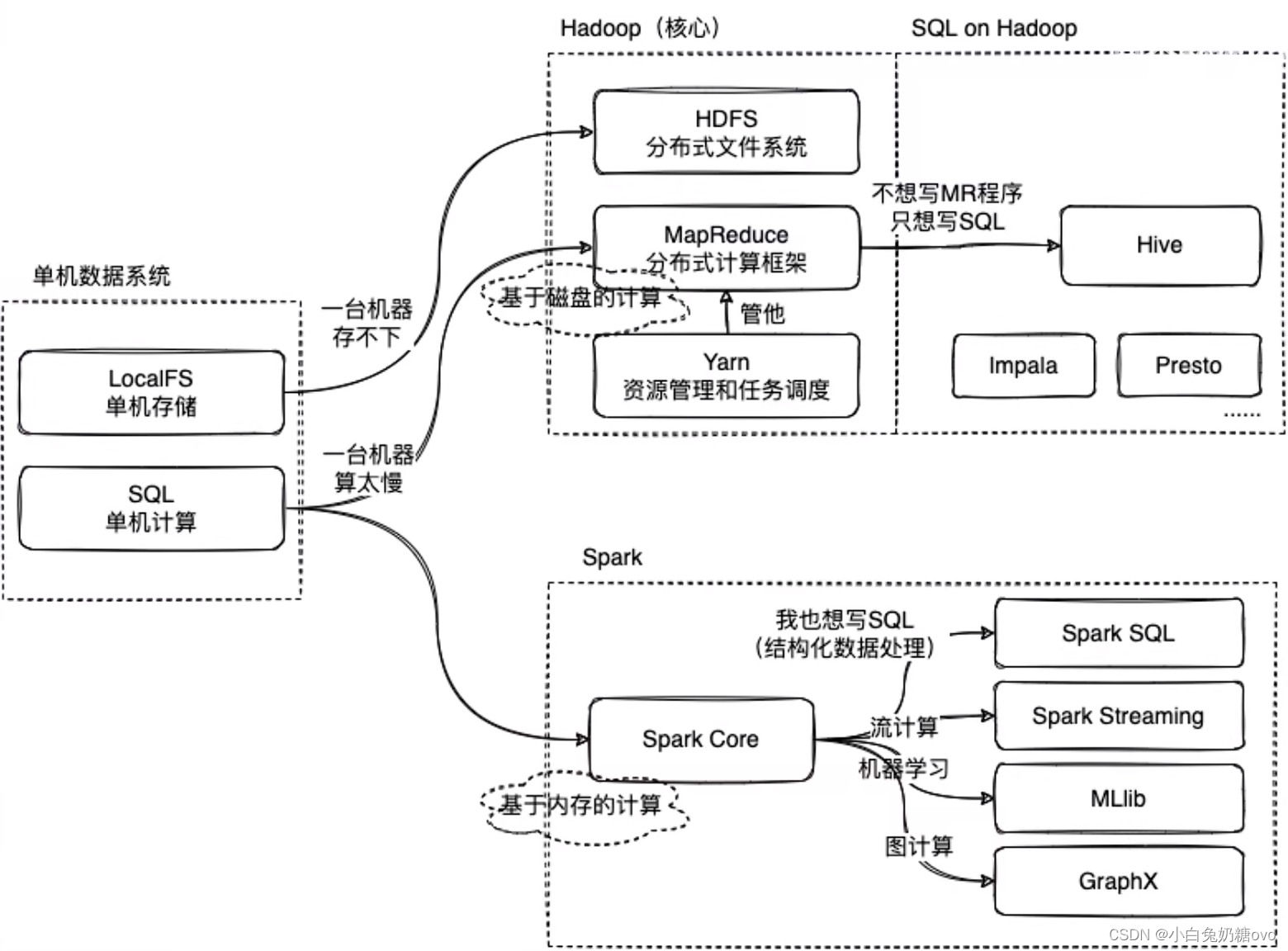
Hadoop, HIve, Spark关系简述
大数据∈数据管理系统的范畴
数据管理系统: 数据怎么存?数据怎么算? 单机数据管理时代下,
数据处理的任务:IO密集型; 数据存不下? HDFS用于存放多机器的数据并提供相关Api接口。 HDFS中引入了…
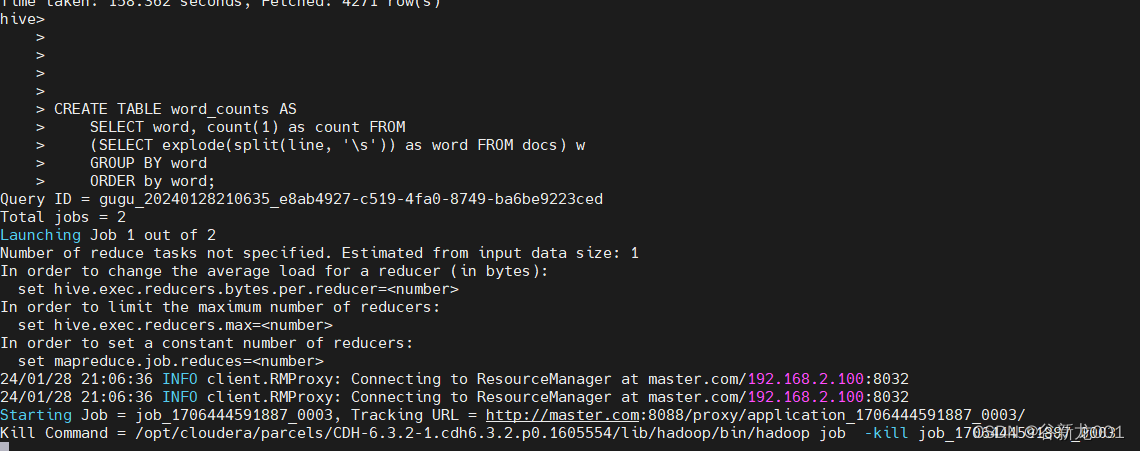
【cdh】hive执行SQL提示缺少3.0.0-cdh6.3.2-mr-framework.tar.gz文件
问题:执行SQL报错提示缺少文件 异常信息如下 在hdfs上查看的时候连文件夹都没有,所以这个异常会抛出,但是我是基于CDH搭建的,可以直接基于下面操作 执行完成之后查看HDFS文件 重新执行SQL发现可以正常执行了
Hive(15)中使用sum() over()实现累积求和和滑动求和
目的:
三个常用的排序函数row_number(),rank()和dense_rank()。这三个函数需要配合开窗函数over()来实现排序功能。但over()的用法远不止于此,本文咱们来介绍如何实现累计求和和滑动求和。
1、数据介绍
三列数据,分别是员工的姓名、月份和…
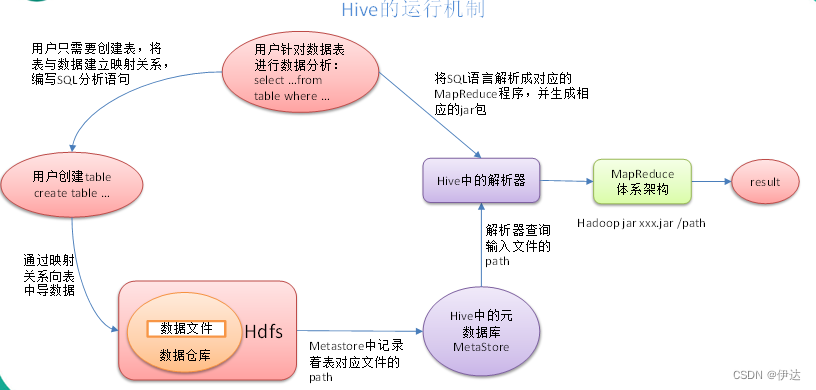
【大数据进阶第三阶段之Hive学习笔记】Hive基础入门
目录
1、什么是Hive
2、Hive的优缺点
2.1、 优点
2.2、 缺点
2.2.1、Hive的HQL表达能力有限
2.2.2、Hive的效率比较低
3、Hive架构原理
3.1、用户接口:Client
3.2、元数据:Metastore
3.3、Hadoop
3.4、驱动器:Driver
Hive运行机制…
数仓工具—Hive进阶之StorageHandler(23)
Storage Handler
引入Storage Handler,Hive用户使用SQL的方式读写外部数据源, 例如ElasticSearch、 Kafka、HBase等数据源的查询对非专业开发是有一定门槛的,借助Storage Handler,他们有了一种方便快捷的手段查询数据,Storage Handler作为Hive的存储插件,我们需要的时候直…
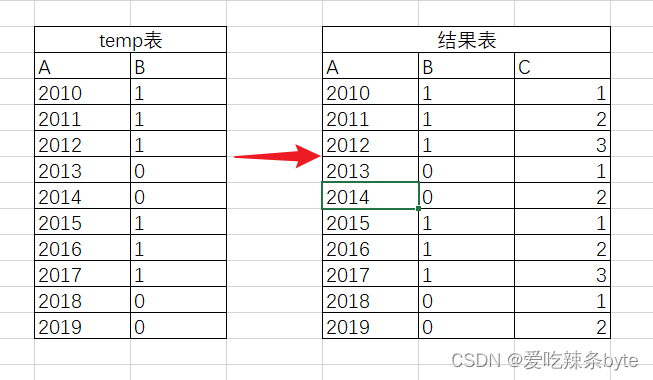
HiveSQL题——窗口函数(lag/lead)
目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
1.4 前后函数:lag/lead
二、实际案例
2.1 股票的波峰波谷
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 前后列转换(面试题)
0 问题描述
1 数据准备 …
HiveSQL题——排序函数(row_number/rank/dense_rank)
一、窗口函数的知识点
1.1 窗户函数的定义 窗口函数可以拆分为【窗口函数】。窗口函数官网指路:
LanguageManual WindowingAndAnalytics - Apache Hive - Apache Software Foundationhttps://cwiki.apache.org/confluence/display/Hive/LanguageManual%20Windowin…
Hive SQL / SQL
1. 建表 & 拉取表2. 插入数据 insert select3. 查询3.1 查询语句语法/顺序3.2 关系操作符3.3 聚合函数3.4 where3.5 分组聚合3.6 having 筛选分组后结果3.7 显式类型转换 & select产生指定值的列 4. join 横向拼接4.1 等值连接 & 不等值连接4.2 两表连接4.2.1 内连…
创建第一个SpringMVC项目,入手必看!
文章目录 创建第一个SpringMVC项目,入手必看!1、新建一个maven空项目,在pom.xml中设置打包为war之前,右击项目添加web框架2、如果点击右键没有添加框架或者右击进去后没有web框架,点击左上角file然后进入项目结构在模块…
Hive学习(14)json解析get_json_object()函数
一、语法
目的:在一个标准JSON字符串中,按照指定方式抽取指定的字符串。
string get_json_object(string <json>, string <path>)
参数说明 json:必填。STRING类型。标准的JSON格式对象,格式为{Key:Value, Key:Val…
Hive中的四种排序
1.order by
全局排序,只有一个Reducer(多个reducer无法保证全局有序),会导致当输入规模较大时,消耗较长的计算时间
hive.mapred.mode strict 模式下 必须指定 limit 否则执行会报错。 2.sort by
不是全局排序&…
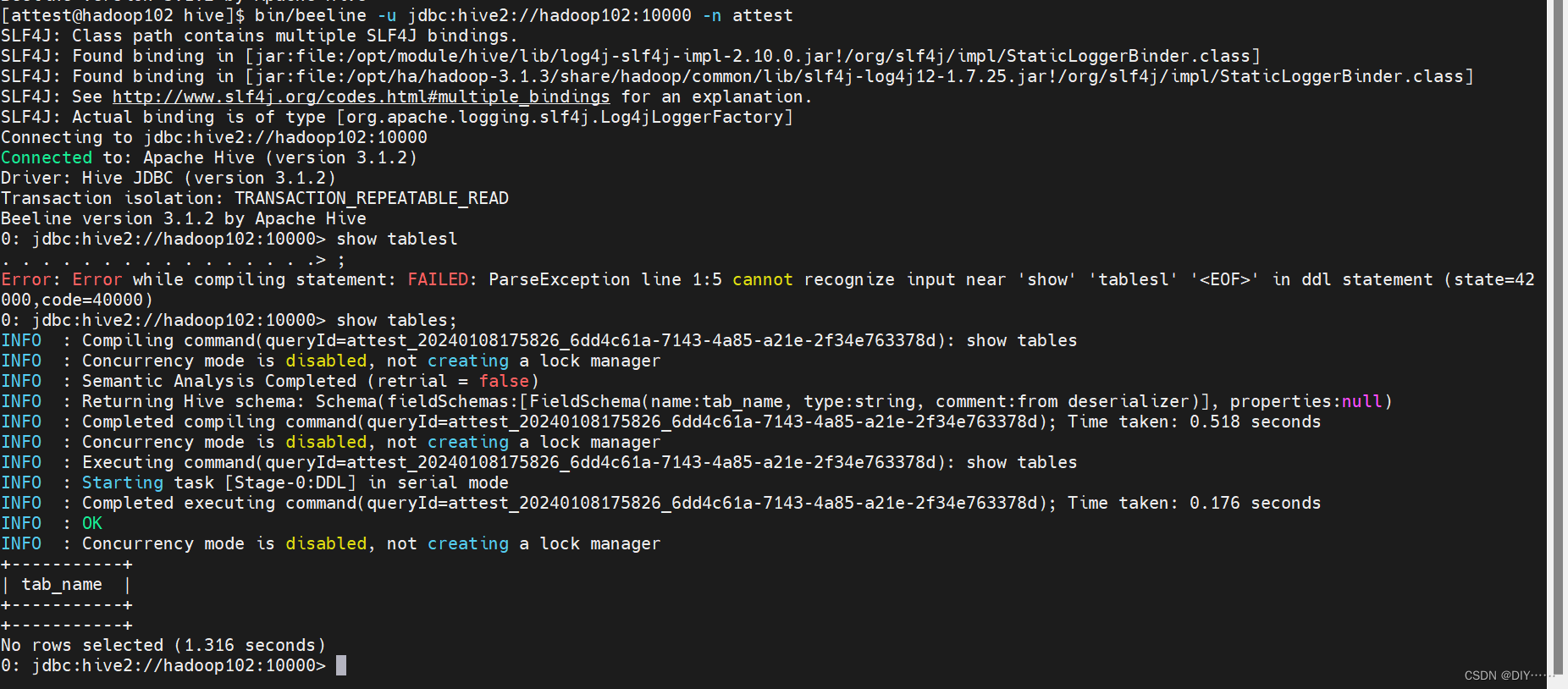
数据治理实践 | 网易某业务线的计算资源治理
写在前面
感谢关注,更多资料可以关注公众号语数,也可关注B站同名:语兴呀,一起学习数仓建设。
前言
本文从计算资源治理实践出发,带大家清楚认识计算资源治理到底该如何进行,并如何应用到其他项目中。
由…
Hive 日期处理函数汇总
Hive 日期处理函数汇总
最近项目处理日期操作比较繁杂,使用Hive的日期函数也较频繁
1. 加减日期 date_add(‘日期字符串’,int值) :把一个字符串日期格式加n天,n为int值 select date_add(‘2023-12-31’,7); 结果: 2024-01-07 date_sub(‘日期字符串’,int值) :把一个字符串…
Hive之set参数大全-2
C
指定是否启用表达式缓存的评估
hive.cache.expr.evaluation 是 Hive 中的一个配置属性,用于指定是否启用表达式缓存的评估。表达式缓存是一项优化技术,它可以在执行查询时缓存表达式的评估结果,以减少计算开销。
在 Hive 配置中…
Hive之set参数大全-3
D
是否启用本地任务调试模式
hive.debug.localtask 是 Apache Hive 中的一个配置参数,用于控制是否启用本地任务调试模式。在调试模式下,Hive 将尝试在本地模式下运行一些任务,以便更容易调试和分析问题。
具体来说,当 hive.de…
Hive之set参数大全-5
I
限制外部表数据插入
set hive.insert.into.external.tablestrue;在Apache Hive中,通过INSERT INTO语句向外部表(External Table)插入数据时,有一些注意事项和限制。外部表是Hive中的一种特殊表,它与Hive管理的存储…
Hive事务表转换为非事务表
环境:hive3.1.0
由于建表时默认会建为非事务表 CREATE TABLE bucket_text_table2(column1 string,column2 string,column3 int) CLUSTERED BY (column3) into 5 BUCKETS STORED AS TEXTFILE; 执行完成后,查看默认建表语句:
---------------…
Hive数据库:嵌入、本地、远程全攻略(下)
先介绍一下本地模式和远程模式:
当使用本地模式时,Hive将其元数据存储在本地数据库(例如MySQL)中,使其成为一个独立的数据处理系统。在本地模式中,Hive的配置文件(hive-site.xml)中…

【DolphinScheduler】datax读取hive分区表时,空分区、分区无数据任务报错问题解决
问题背景:
最近在使用海豚调度DolphinScheduler的Datax组件时,遇到这么一个问题:之前给客户使用海豚做的离线数仓的分层搭建,一直都运行好好的,过了个元旦,这几天突然在数仓做任务时报错,具体报…
Hive基础知识(十四):Hive的八种Join使用方式与优缺点
1. 等值 Join
Hive 支持通常的 SQL JOIN 语句。 1)案例实操 (1)根据员工表和部门表中的部门编号相等,查询员工编号、员工名称和部门名称;
select e.ename,e.empno,d.dname from emp e join dept d on e.deptno d.de…
【数据开发】大型离线数仓OLAP数据开发指南(目录)
文章目录 1、什么离线数仓OLAP2、OLAP数仓建设3、OLAP数仓开发指南 1、什么离线数仓OLAP
离线数仓OLAP(Online Analytical Processing)是一种数据分析技术,它通过对离线数据仓库中的数据进行分析,为企业提供决策支持的数据分析服…
HiveSQL题——数据炸裂和数据合并
目录
一、数据炸裂
0 问题描述
1 数据准备
2 数据分析
3 小结
二、数据合并
0 问题描述
1 数据准备
2 数据分析
3 小结
一、数据炸裂
0 问题描述 如何将字符串1-5,16,11-13,9" 扩展成 "1,2,3,4,5,16,11,12,13,9" 且顺序不变。
1 数据准备
with da…
Hive基础知识(九):Hive对数据库表的增删改查操作
1. 创建表 1)建表语法 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name #EXTERNAL:外部的
[(col_name data_type [COMMENT col_comment],...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment],...)]#PARTITIO…
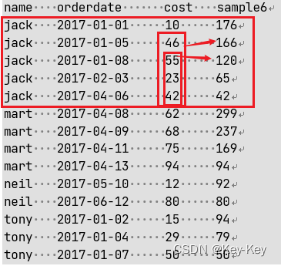
大数据开发之Hive(查询、分区表和分桶表、函数)
第 6 章:查询
6.1 基本语法及执行顺序
1、查询语句语法
select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]]
[LIMIT n…
大数据开发之Hive(统计影音视频网站的常规指标)
第 11 章:Hive实战
11.1 数据结构
1、视频表
字段备注详细描述videoId视频唯一id(String)11位字符串uploader视频上传者(String)上传视频的用户名Stringage视频年龄(int)视频在平台上的整天数category视频类别(Array)上传视频指定的视频分类length视频长度(Int)整…
Hive数据导出的四种方法
hive数据仓库有多种数据导出方法,我在本篇文章中介绍下面的四种方法供大家参考:Insert语句导出、Hadoop命令导出、Hive shell命令导出、Export语句导出。
一、Insert语句导出
语法格式
Hive支持将select查询的结果导出成文件存放在文件系统中。语法格…

Hive添加第三方Jar包方式总结
一、在 Hive Shell中加入—add jar
hdfs dfs -put HelloUDF-1.0.jar /tmp
beeline -u "jdbc:hive2://test.bigdata.com:10000" -n "song" -p ""
add jar hdfs:///tmp/HelloUDF-1.0.jar;
create function HelloUDF as org.example.HelloUDF USIN…
hql(hive sql)中的join及踩过的坑
1 几种join方式 join join对应于inner join 内连接。 当多张表进行join的时候,所有表中与on条件中匹配的数据才会显示。 hql(即hive sql)的on子句中只支持and,不支持 or,也不支持null的对比。
left outer join 左外连…

HIVE中关联键类型不同导致数据重复,以及数据倾斜
比如左表关联键是string类型,右表关联键是bigint类型,关联后会出现多条的情况
解决方案: 关联键先统一转成string类型再进行关联
原因:
根据HIVE版本不同,数据位数上限不同,
低版本的超过16位会出现这种…

Hive实战 —— 电商数据分析(全流程详解 真实数据)
目录 前言需求概述数据清洗数据分析一、前期准备二、项目1. 数据准备和了解2.确定数据粒度和有效列3.HDFS创建用于上传数据的目录4.建库数仓分层 5.建表5.1近源层建表5.2. 明细层建表为什么要构建时间维度表?如何构建时间维度表? 5.3 轻聚层建表6. 指标数…
Hive 窗口函数札记
窗口函数的理解是hive函数里的一个高阶内容,把一些容易混淆的做个记录,以方便随时查看。
1:ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING 含义:
这个定义表示窗口范围从当前行的前任意多行开始(包括最早的行&a…

【Flink】FlinkSQL读取hive数据(批量)
一、简介:
Hive在整个数仓中扮演了非常重要的一环,我们可以使用FlinkSQL实现对hive数据的读取,方便后续的操作,本次例子为Flink1.13.6版本
二、依赖jar包准备:
官网地址如下:
Overview | Apache Flink
1、我们需要准备相关的jar包到Flink安装目录的lib目录下,我们需…
【Flink】FlinkSQL实现数据从Hive到MySQL
简介 未来Flink通用化,代码可能就会转换为sql进行执行,大数据开发工程师研发Flink会基于各个公司的大数据平台或者通用的大数据平台,去提交FlinkSQL实现任务,学习FlinkSQL势在必行。 本博客在sql-client(Flink自带的sql执行器)中模拟大数据平台的sql编辑器执行FlinkSQL,使…
【dbeaver】win环境的kerberos认证和Clouders/cdh集群中Kerberos认证使用Dbeaver连接Hive、Impala和Phoenix
一、配置Mit kerberos
1.1 下载安装MIT KERBEROS客户端
MIT KERBEROS 下载较新的版本即可。 下载之后一路默认安装即可。注意:不要修改软件安装位置。 修改系统环境变量中的Path。将刚刚的安装路径置顶。(不置顶,也要比%JAVA_HOME%\bin和a…
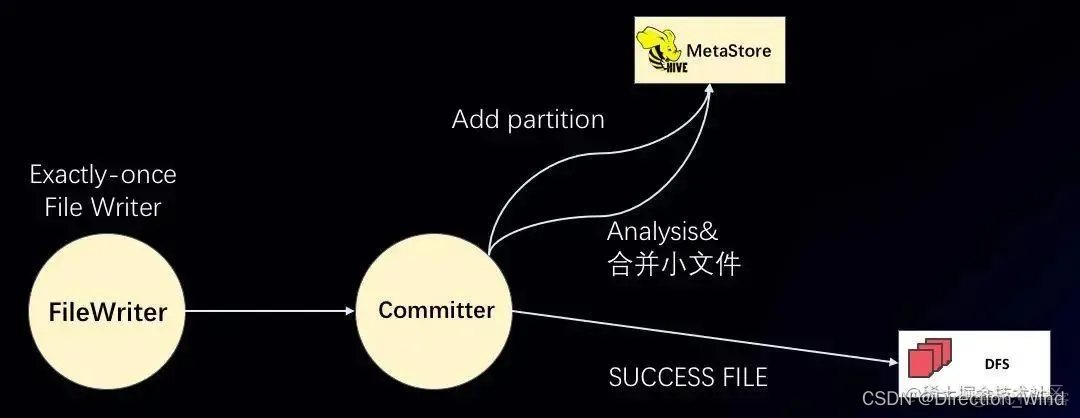
flink sql 实战实例 及延伸问题:聚合/数据倾斜/DAU/Hive流批一体 等
flink sql 实战实例 及延伸问题 Flink SQL 计算用户分布Flink SQL 计算 DAU多topic 数据更新mysql topic接入mysql引入 upsert-kafka-connector 以1.14.4版本为例 数据倾斜问题:让你使用用户心跳日志(20s 上报一次)计算同时在线用户、DAU 指标…
數據集成平台:datax將MySQL數據以query方式同步到hive
數據集成平台:datax將MySQL數據以query方式同步到hive
1.py腳本
# codingutf-8
import json
import getopt
import os
import sys
import MySQLdb
import re# MySQL相关配置,需根据实际情况作出修改
mysql_host "xx"
mysql_port "330…

Hive的UDF开发之向量化表达式(VectorizedExpressions)
1. 背景
笔者的大数据平台XSailboat的SailWorks模块包含离线分析功能。离线分析的后台实现,包含调度引擎、执行引擎、计算引擎和存储引擎。计算和存储引擎由Hive提供,调度引擎和执行引擎由我们自己实现。调度引擎根据DAG图和调度计划,安排执…
【超详细】HIVE 日期函数(当前日期、时间戳转换、前一天日期等)
文章目录 相关文献常量:当前日期、时间戳前一天日期、后一天日期获取日期中的年、季度、月、周、日、小时、分、秒等时间戳转换时间戳 to 日期日期 to 时间戳 日期之间月、天数差 作者:小猪快跑 基础数学&计算数学,从事优化领域5年&#…
hive表中导入数据 多种方法详细说明
文章中对hive表中导入数据 方法目录 方式一:通过load方式加载数据 方式二:直接向分区表中插入数据 方式三:查询语句中创建表并加载数据(as select) 方式四:创建表时通过location指定加载数据路径 1. 创建表…
在Linux操作系统的ECS实例上安装Hive
目录 1. 完成hadoop安装配置2. 安装配置MySql安装配置 3. 安装Hive4. 配置元数据到MySQL5. hiveserver2服务配置文件测试 1. 完成hadoop安装配置
在Linux操作系统的ECS实例上安装hadoop
以上已安装并配置完jdk、hadoop也搭建了伪分布集群
2. 安装配置MySql
安装
下下一步…
Hive 严格模式设置
Hive 在早期使用参数 hive.mapred.mode 来决定是否执行严格模式, 其值为 strict 或者 nostrict. 当其值为 strict 时,执行严格模式,如从分区表查询时,过滤条件必须有分区字段。
在 Hive 3.1.3 中,因为 hive.mapred.mode 比较粗暴…
Hive--删除数据库
一、删除数据库
注意:Hive 与 MySQL 再删除数据库时是有一点不一样的。 Hive再删除数据库操作时,要保证该库下没有任何数据表!
删除一个空数据库,如果数据库下面有数据表,那么就会报错 drop database…

【002hive基础】hive的库、表与hdfs的组织逻辑
文章目录 一. 数据的组织形式1. hive数据库2. hive表2.1. 内部表和外部表2.2. 分区表与分桶表 3. 视图 二. 底层储存 一. 数据的组织形式
1. hive数据库
hive将不同功能模块的数据,存储在不同的数据库中,在hdfs中以文件夹的形式显示。 2. hive表
2.1.…

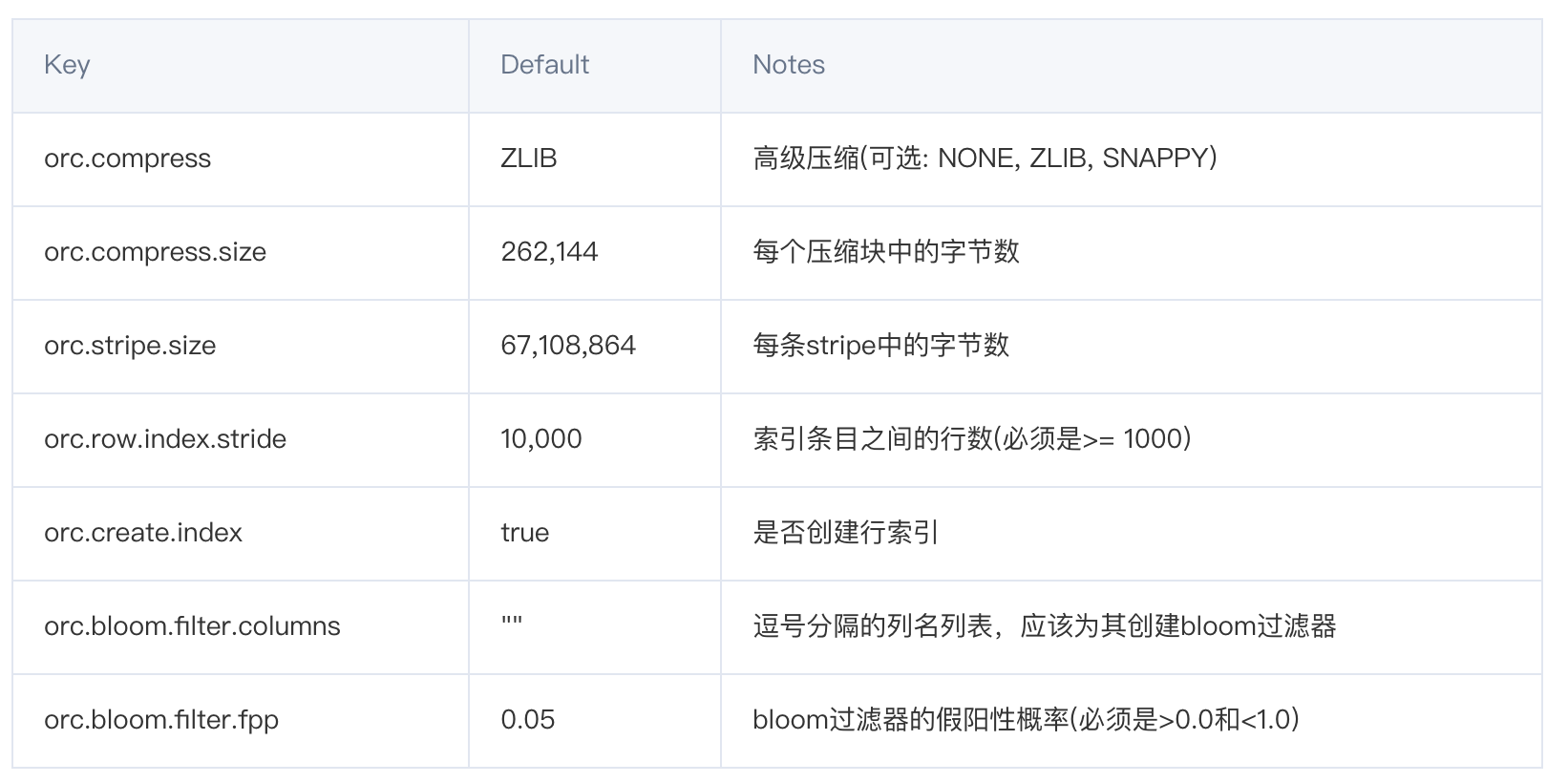
【004hive基础】hive的文件存储格式与压缩
文章目录 一.hive的行式存储与列式存储二. 存储格式1. TEXTFILE2. ORC格式3. PARQUET格式 ing 三. Hive压缩格式1. mr支持的压缩格式:2. hive配置压缩的方式:2.1. 开启map端的压缩方式:2.2.开启reduce端的压缩方式: 四. hive中存储格式和压缩相结合五. hive主流存储格式性能对比…
用idea操作hbase数据库,并映射到hive
依赖条件:需要有Hadoop,hive,zookeeper,hbase环境映射:每一个在 Hive 表中的域都存在于 HBase 中,而在 Hive 表中不需要包含所有HBase 中的列。HBase 中的 RowKey 对应到 Hive 中为选择一个域使用 :key 来对…
Hive 压缩配置详解
压缩
1 MR支持的压缩编码
压缩格式工具算法文件扩展名是否可切分DEFAULT无DEFAULT.deflate否GzipgzipDEFAULT.gz否bzip2bzip2bzip2.bz2是LZOlzopLZO.lzo否LZ4无LZ4.lz4否Snappy无Snappy.snappy否
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,…
大数据课程-学习十九周总结
4.2.8.修改表
4.2.8.1.表重命名 基本语法: alter table old_table_name rename to new_table_name;
– 把表score3修改成score4 alter table score3 rename to score4;
4.2.8.2.增加/修改列信息 – 1:查询表结构 desc score4; – 2:添加列 alter table score4 ad…
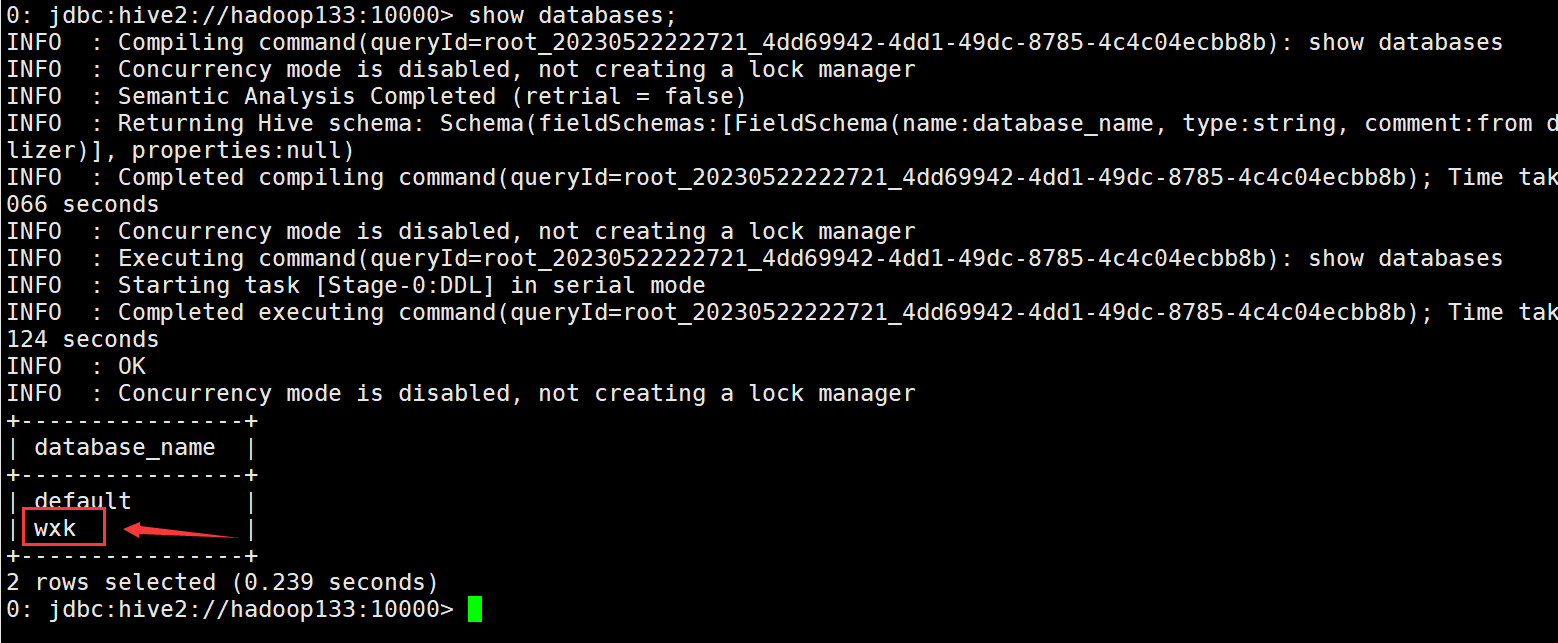
12. 查询指定日期的全部商品价格
文章目录 题目需求实现一题目来源 题目需求
查询所有商品(sku_info表)截至到2021年10月01号的最新商品价格(需要结合价格修改表进行分析)。
期望结果如下:
sku_id (商品id)price <decimal…
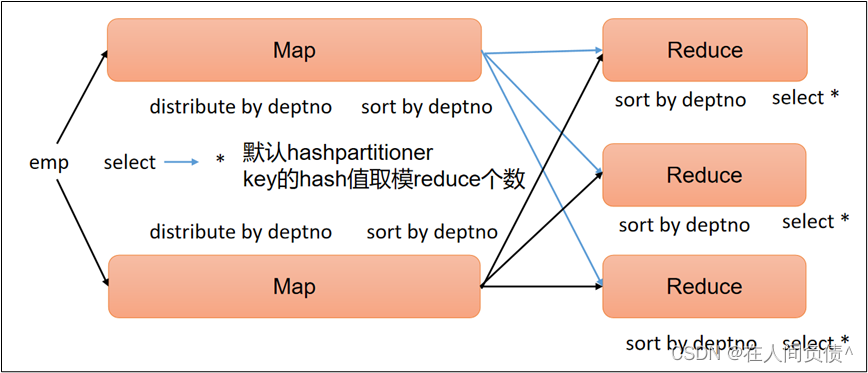
Hive ---- 查询
Hive ---- 查询 1. 基础语法2. 基本查询(Select…From)1. 数据准备2. 全表和特定列查询3. 列别名4. Limit语句5. Where语句6. 关系运算函数7. 逻辑运算函数8. 聚合函数 3. 分组1. Group By语句2. Having语句 4. Join语句1. 等值Join2. 表的别名3. 内连接…
各大数据组件数据倾斜的原因和解决办法
1 背景
在处理大规模数据时,数据倾斜是一个常见的问题。数据倾斜指的是在分布式环境中处理数据时,某些节点上的任务会比其他节点更加繁重,这可能导致性能下降、资源浪费等问题。数据倾斜可能会出现在不同层次的数据处理过程中,例…
【学习记录】大数据课程-学习十一周总结
Hive的安装
Hive的安装方式
hive的安装一共有三种方式:内嵌模式、本地模式、远程模式
元数据服务(metastore)作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端…

集群搭建--安装apache-hive-2.3.4
本文安装的是 apache-hive-2.3.4-bin.tar.gz 其下载地址为:
路径 https://pan.baidu.com/s/1ZPJxbGdpjW0fPpKUa7RX6Q 提取码: i58e
解压 apache-hive-2.3.4-bin.tar.gz(hadoop用户)
tar -zxvf apache-hive-2.3.4-bin.tar.gz -C /usr/local/modules/
将 apa…

Hive内部表和外部表(一)
文章目录Hive内部表和外部表1. 内部表加载数据删除表测试web界面查看,源数据已经被删除2. 外部表加载数据删除表测试web查看,源数据仍然存在Hive内部表和外部表
删除内部表的时候,表中的数据(HDFS上的文件)会被同表的…

使用DataX实现mysql与hive数据互相导入
文章目录1.安装DataX1.1上传datax压缩包1.2解压至/usr目录下2. 使用DataX实现mysql中student表导数据到student2表。2.1在mysql中创建数据库2.2导入student.sql文件2.3创建student2表2.3 datax.py mysql2mysql.json2.4查看student2数据3. 使用DataX实现mysql的student表导入hiv…
Hive源码阅读环境准备
源码地址
hive源码地址在github或gitee均可以下载,如果没有vpn工具,使用gitee网速更快点。 github地址为:
https://github.com:edingbrugh/hive.gitgitee地址如下:
https://gitee.com/apache/hive.git环境要求
本地或远程已经安装hivejdk 8maven 3.6…

Hive和Hadoop关系
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以查询和分析存储在Hadoop中的大规模数据的机制。Hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成Ma…

Mapreduce案例之---统计手机号耗费的总上行流量、下行流量、总流量
1.需求:
统计每一个手机号耗费的总上行流量、下行流量、总流量
2.数据准备:
2.1 输入数据格式:
时间戳、电话号码、基站的物理地址、访问网址的ip、网站域名、数据包、接包数、上行/传流量、下行/载流量、响应码 2.2 最终输出的数据格式&…

小米基于 Flink 的实时数仓建设实践
摘要:本文整理自小米软件开发工程师周超,在 Flink Forward Asia 2022 平台建设专场的分享。本篇内容主要分为四个部分: 1. 小米数仓架构演变 2. FlinkIceberg 架构升级实践 3. 流批一体实时数仓探索 4. 未来展望 Tips:点击「阅读原…
hive中如何计算字符串中表达式
比如 select 1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 col ,1(2-3)(-4.1-3.1)-(4-3)-(-3.34.3)-1 result \
现在的需求式 给你一个字符串如上述col 你要算出result。
前提式 只有和-的运算,而且只有嵌套一次 -(4-3)没有 -(-4(3-(31)))嵌套多次。
第一步我们需要将运…
CDH 之 hive 升级至 hive-3.1.3 完美踩坑过程
一、准备工作
1.1 前言 这是博主在升级过程中遇到的问题记录,大家不一定遇到过,如果不是 CDH 平台的话,单是 hive 服务升级应该是不会有这些问题的,且升级前博主也参考过几篇相关 CDH 升级 hive 服务的博文,前面的升级…

HiveSQL初级题目
文章目录 Hive SQL题库(初级)第一章 环境准备1.1 建表语句1.2 数据准备1.3 插入数据 第二章 简单查询2.1 查找特定条件2.1.1 查询姓名中带“冰”的学生名单2.1.2 查询姓“王”老师的个数2.1.3 检索课程编号为“04”且分数小于60的学生的课程信息,结果按分数降序排列…
大数据面试题:Hive的cluster by 、sort by、distribute by 、order by 区别?
面试题来源:
《大数据面试题 V4.0》
大数据面试题V3.0,523道题,679页,46w字
参考答案:
可回答:1)Hive的排序函数;2)Hive的排序,以及各自的区别࿱…
hive中的order by ,sort by ,distribute by,cluster by的用法与区别
一、order by
order by后面不跟limit的话,order by会强制将reduce number设置成1,不加limit,会将所有数据sink到reduce端来做全局排序。多个reducer无法保证全局有序,但是因为只有一个reducer,就导致当输入数据规模较大时&#…

Hive ---- DDL(Data Definition Language)数据定义
Hive ---- DDL(Data Definition Language)数据定义 1. 数据库(database)1. 创建数据库2. 查询数据库3. 修改数据库4. 删除数据库5. 切换当前数据库 2. 表(table)1. 创建表2. 查看表3. 修改表4. 删除表5. 清…
【Hive】join时的小技巧
有时候join或者where两表时会报错: FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to strict…

Hive 安装部署MySQL 安装Hive 元数据配置到 MySQL
目录
1.安装 Hive
2.启动并使用 Hive
3.MySQL 安装
4.Hive 元数据配置到 MySQL 1.安装 Hive 1)把 apache-hive-3.1.2-bin.tar.gz 上传到 linux 的/opt/software 目录下2)解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面[atguiguhadoop102…
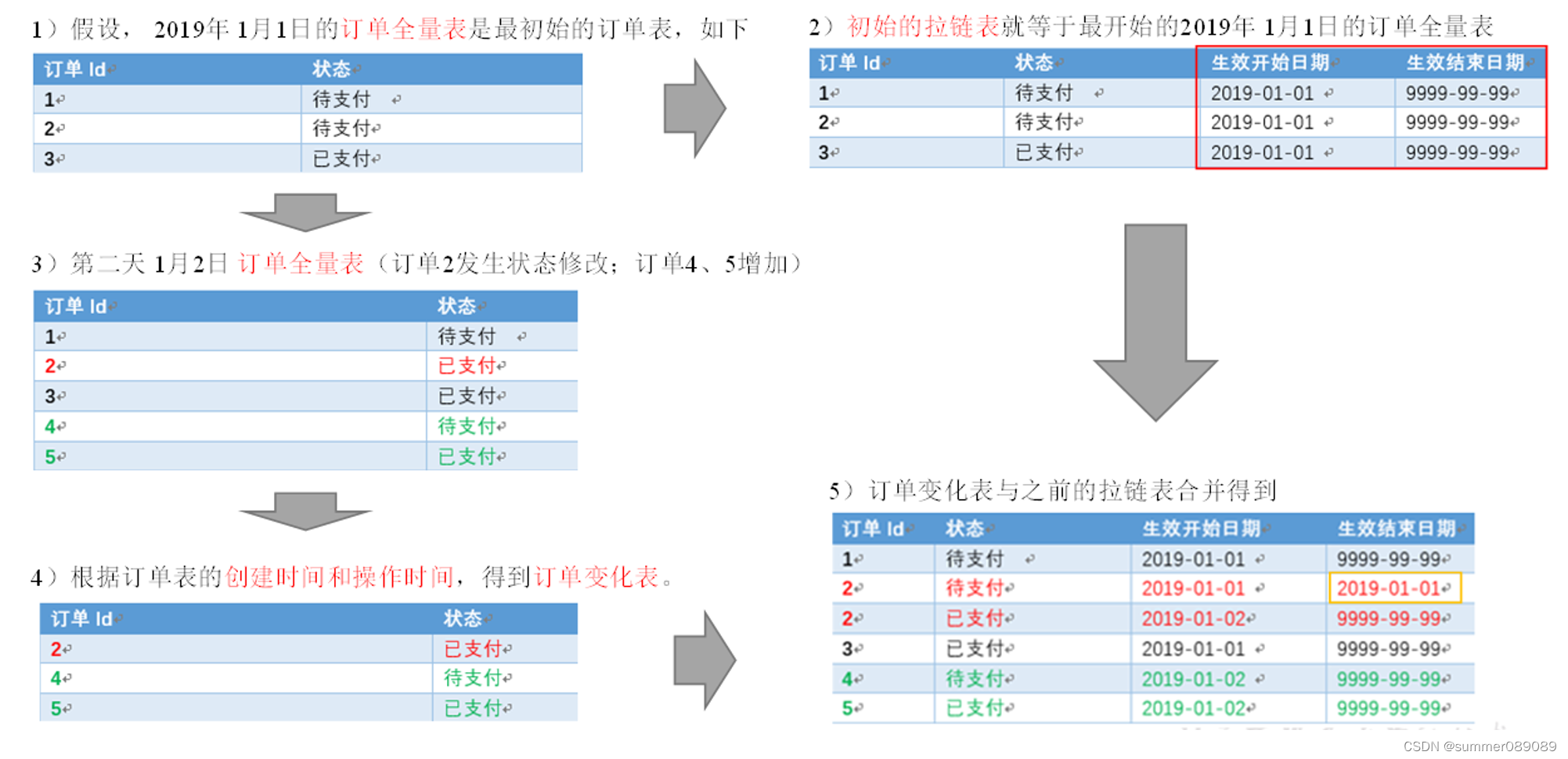
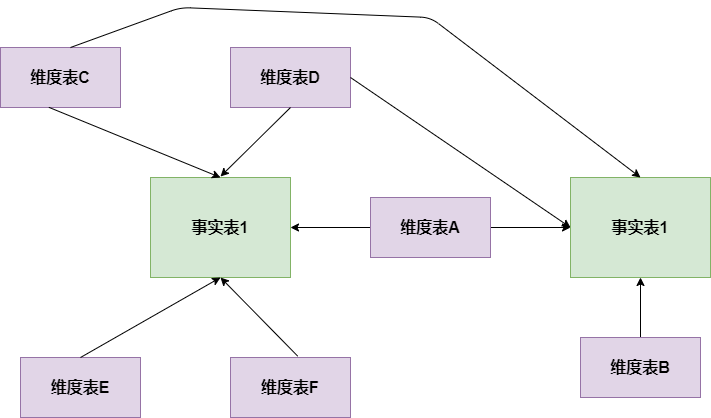
2023-Hive必备详细教程
Hive涉及的知识点如下图所示,本文将逐一讲解: 一. Hive概览
1.1 hive的简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
其本质是将SQL转换为MapReduce/Spark的任务…
黑马在线教育数仓实战8
学生出勤主题看板
2.1 需求分析
回顾: 涉及维度, 指标, 涉及表, 字段, 以及需要清洗的内容, 需要转换的内容, 如果有多个表, 表与表关联条件 需求一: 统计指定时间段内,不同班级的出勤人数。打卡时间在上课前40分钟(否则认为无效)~上课时间点之内,且未…

从‘discover.partitions‘=‘true‘分析Hive的TBLPROPERTIES
从’discover.partitions’true’分析Hive的TBLPROPERTIES
前言
Hive3.1.2先建表:
show databases ;use db_lzy;show tables ;create external table if not exists test_external_20230502(id int,comment1 string,comment2 string
)
stored as parquet
;creat…
hive 保留四位小数
1. cast(value as decimal()) 推荐使用
select cast(100.200150001 as decimal(20,4));
100.2002
2.round() 有时会有特殊问题
select round(11.000000111,4);
11.0
3.regexp_extract() 正则字符串截取(不会四舍五入)
select regexp_ex…
拿捏SQL:以“统计连续登录天数超过3天的用户“为例拿捏同类型SQL需求
文章目录 [TOC](文章目录) 一、介绍案例:以"统计连续登录天数超过3天的用户"为需求。数据准备方案1:常规思路针对对数据user_id分组,根据用户的活动日期排序用登录日期与rn求date_sub,得到的差值日期如果是相等的&#…
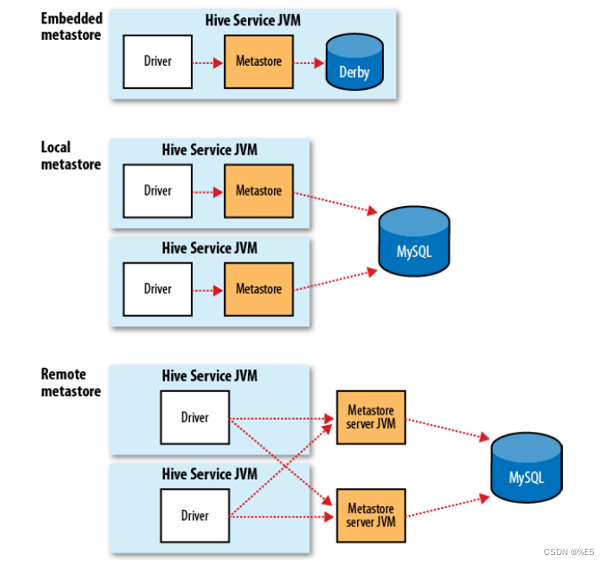
大数据|Hive和数据仓库
前文回顾:HBase基本工作原理 目录
📚数据仓库和OLAP
🐇数据仓库
🥕面向主题
🥕集成的
🥕时变的
🥕非易失的
🐇OLTP(联机事务处理)vs OLAP(…
Hudi的precombine.field释疑
从不同资料,可看到四个让人迷惑的 precombine.field 配置项: precombine.field write.precombine.field hoodie.table.precombine.field hoodie.datasource.write.precombine.field
它们是完全相同,还是有什么关系了?
hoodi…
hive on spark安装的一些问题
自己安装的可用环境: linux: CentOS-7hadoop : hadoop-2.8.1spark: spark-1.6.3-bin-hadoop2.4-without-hivehive : apache-hive-2.1.1-binscala: scala-2.12.3sql: MariaDB安装问题:
原本是想安装新版本的spark 2.0以后版本,发现各种问…
一百一十、Hive时间转换——from_unixtime踩坑(不要用from_unixtime,而是用from_utc_timestamp)
1.详情
从kettle转换任务得到时间戳为13位,1683701579457。想看看这个时间戳与createTime字段的关系,于是一开始使用了from_unixtime,结果踩坑了 2.运行问题(晚8个小时)
hive> select from_unixtime(cast(1683701…
一百一十一、Hive——从HDFS到Hive的数据导入(静态分区、动态分区)
一、分区的定义 分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹, Hive 中的分区就是分目录 ,把一个大的数据集根据业务需要分割成小的数据集。 在查询时通过 where 子句中的表达式选择查询所需要的指定的分区,这样的查询效率 会…
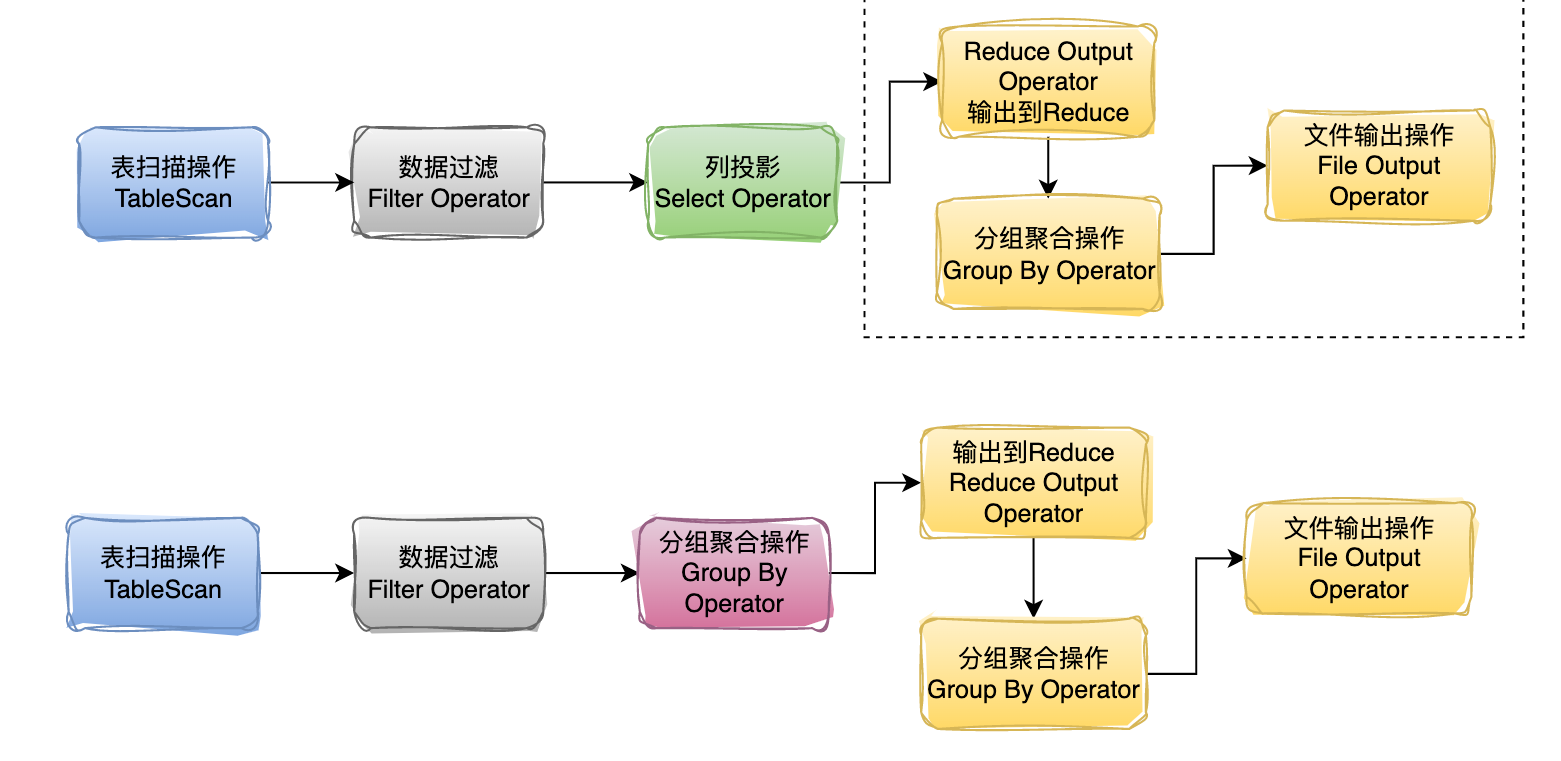
HiveSQL在使用聚合类函数的时候性能分析和优化详解
文章目录 概述1.仅在Reduce阶段聚合的SQL执行逻辑2.在map和reduce阶段聚合的SQL逻辑 概述
前文我们写过简单SQL的性能分析和解读,简单SQL被归类为select-from-where型SQL语句,其主要特点是只有map阶段的数据处理,相当于直接从hive中取数出来…
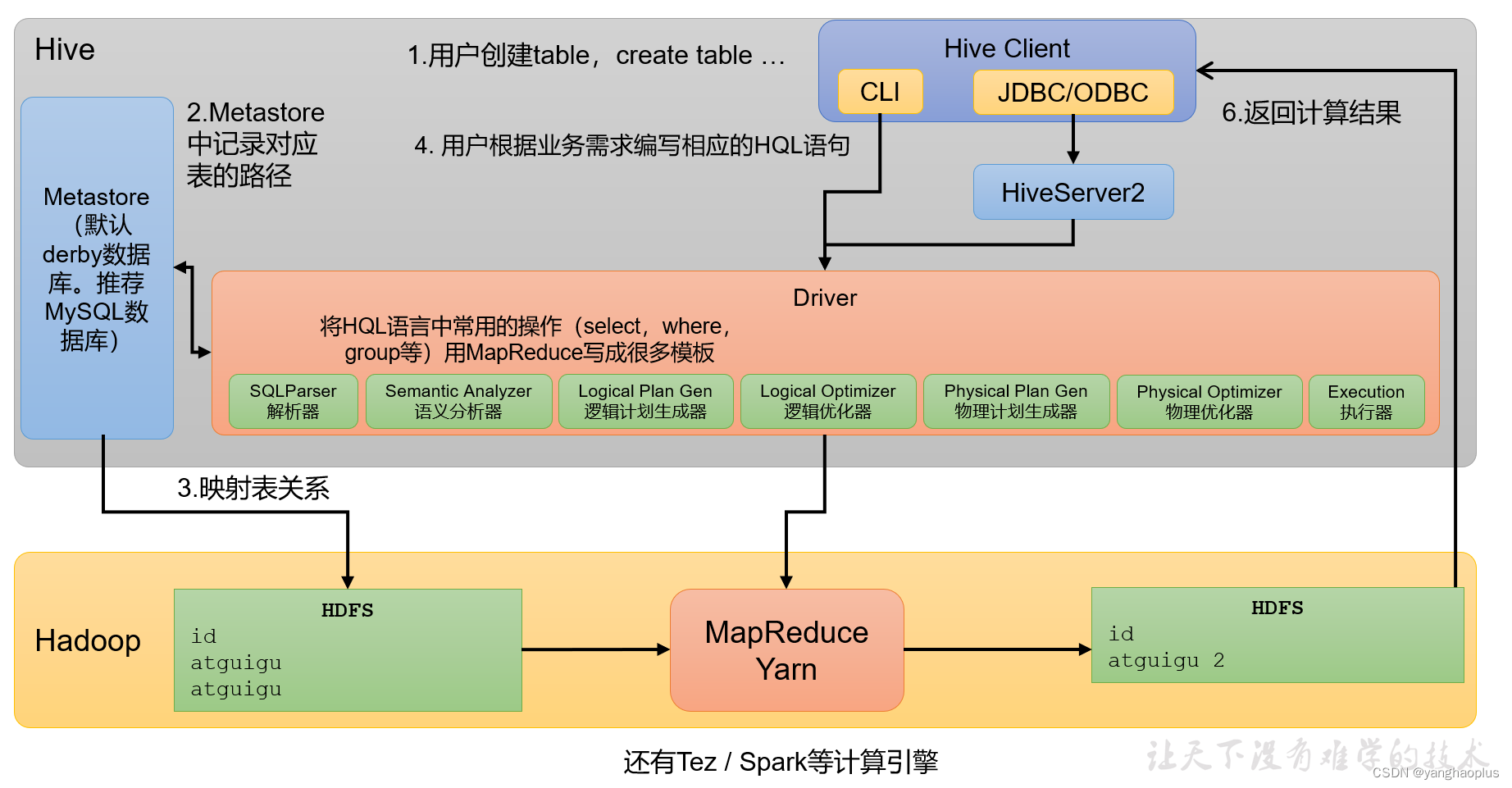
数仓工具Hive 概述
Hive Hive简介Hive架构HiveSQL语法不同之处建表语句查询语句 Hive查看执行计划Hive文件格式 Hive简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。 通过Hive可以将mapred…
大数据应用技术测试习题
1. Impala是哪种处理的查询分析?
A. 实时 B. 内存计算 C. 海量处理 D. 批处理 答案:A 解析:Impala是由Cloudera开发的一个开源并行处理查询工具,它能够在Apache Hadoop上进行实时查询分析。使用Impala,用户可以执行低…
Hive(12):View视图
1 View的概念
Hive中的视图(view)是一种虚拟表,只保存定义,不实际存储数据。通常从真实的物理表查询中创建生成视图,也可以从已经存在的视图上创建新视图。
创建视图时,将冻结视图的架构,如果删除或更改基础表,则视图将失败,并且视图不能存储数据,操作数据,只能查…
Hive Server 清理本地临时文件
HiveServer2 scratchdir 在本地存储一些临时文件。如果使用 kill -9 停止 HiveServer2 时,来不及清理本地的 scratchdir。再次启动时,默认是不清理本地的 scratchdir 的。那么多次重启 HiveServer2 后,有可能在本地有大量垃圾文件,…

「数据仓库」怎么选择现代数据仓库?
构建自己的数据仓库时要考虑的基本因素我们用过很多数据仓库。当我们的客户问我们,对于他们成长中的公司来说,最好的数据仓库是什么时,我们会根据他们的具体需求来考虑答案。通常,他们需要几乎实时的数据,价格低廉&…

Hive基础之:hive的查询注意事项以及优化总结(hive sql优化)
hive的查询注意事项以及优化总结一、基本原则:二、其他注意事项Hive是将符合SQL语法的字符串解析生成可以在Hadoop上执行的MapReduce的工具。使用Hive尽量按照分布式计算的一些特点来设计sql,和传统关系型数据库有区别, 所以需要去掉原有关系…

Hive基础之:图文详解hive分区、分桶
什么是分区、分桶
下面我用一组图和一个情景先简单的介绍一下什么是分区、分桶: 小黄人要去医院打疫苗,于是格鲁把它们分成了几组让他们去不同的医院,用来分散医院的压力。如图所示,格鲁根据身高把它们分成了三组。 来到医院后&a…

JDBC getColumnLabel和getColumnName区别及自动解析查询字段
背景
最近在负责的一款数据产品,其功能之一为数据推送,即把数据从源头数据源同步到目标数据源。 功能大致如下,SQL语句块需要支持多段SQL,以英文逗号;分隔:
问题
自测时发现一个问题。对于select 11 as userid或s…
Hive SQLException: Method not supported问题
概述
项目使用到 impala/hive 查询引擎,ELK记录每天都要抛出差不多一两条报错信息:java.net.SocketTimeoutException: Read timed out。原因应该是SQL比较复杂,查询超时。故而可以考虑设置超时时间。
参考SocketTimeoutException: Read tim…

Hive元数据的解析
Hive体系结构的元数据(Metastore)是一个重要的组件,保存了Hive有关库、表、存储、分区等信息。元数据主要包括两个方面:一方面是元数据库,最常见的是采用MySQL;另一方面是元数据服务,与其他查询…
大数据平台开发架构讲解
大数据背景
对于业务数据数据量的暴增,用户智能化需求提升。在这个DT的时代,大数据的开发也就应运而生了,大数据开发必须解决两个问题,大数据量如何统一存储,大数据量如何统一计算。针对这些问题产生了很多大数据方面…

关于Hive的授权研究
关于Hive的授权研究 因为最近在学习hive的相关知识,就把最近看的一些资料总结了一下,使用的hive是3.1.2版本,应该是比较新的,所以如果文章有不对的地方,希望大佬指正。
Hive的权限控制
简介:
Hive的真实…
Docker安装Hive与Windows安装Hive
Docker安装Hive与Windows安装HiveDocker安装Hive下载复制到容器内部进入容器解压及重命名修改hive-env.sh创建hive-site.xml添加驱动包创建数据库启动HiveWindows安装Hive下载Hive配置hive-env.sh配置hive-default.xml添加驱动包创建数据库启动HiveDocker安装Hive
由于使用Doc…

大数据 安装指南-----利用docker
为了避免繁琐的大数据环境安装 mysql 安装
docker 安装mysql_诸葛子房_的博客-CSDN博客
kafka 安装
docker 安装kafka_诸葛子房_的博客-CSDN博客
hive 安装
使用docker快速搭建hive环境_upupfeng的博客-CSDN博客_docker部署hive
Hbase 安装
HBase实践 | 使用 Docker 快速…

MapReduce Shuffle 参数调优【转载】
MapReduce Shuffle性能调优
MapReduce shuffle过程剖析及调优
MapReduce的shuffle过程详解 Map阶段 -- 环形缓冲区大小,默认100
set mapreduce.task.io.sort.mb 200;-- 环形缓冲区溢写阈值,默认0.8
set mapreduce.map.sort.spill.percent 0.9;-- 并行…
Hive优化笔记(2 - 数据倾斜)
一 基本概念
简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少。默认情况下, Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时,就发生倾斜了
数据倾斜一般有两种情况…

Centos7安装MySQL续2
接 Centos7安装MySQL遇到libaio问题
一、安装MySql服务器
1.安装mysql服务端
[roothadoop01 mysql-libs]# rpm -ivh MySQL-server-5.6.24-1.el6.x86_64.rpm 有问题见文章 Centos7安装MySQL遇到libaio问题
2、查看产生的随机密码
[roothadoop102 mysql-libs]# c…

SQL习题集_详细注释版答案
目录
一、准备工作
二、MySQL语句执行顺序
三、题目
四、附录 一、准备工作
1 环境 MySQL 5.7.28 Ubuntu18.04.4 2 登录MySQL
-- Terminal下输入
mysql -uroot -p
3 数据库操作
-- 创建数据库 practice
-- character set 用来指定编码格式,方便之后插入中文…

Hive多行转多列,多列转多行
hive中的行列转换包含单行、多行、单列、多列,所以一共有四种组和转换结果。
一、多行转多列
原始数据表 目标结果表 分析:目标表中的a和b是用分组形成,所以groupby字段选用原始表中col1,c、d、e是原始表中的行值,…
Hive中的grouping set,cube,roll up
GROUPING SETS GROUPING SETS作为GROUP BY的子句,允许开发人员在GROUP BY语句后面指定多个统计选项,可以简单理解为多条group by语句通过union all把查询结果聚合起来结合起来,下面是几个实例可以帮助我们了解,
以acorn_3g.test…
hive udf 判断四边形是否为矩形
hive udf中经常要做判断四边形是否为矩形,所以写了这个udf如下: public class RectangularIsNot extends UDF {private static final int LNG_LAT_LENGTH = 2;private static final String SEPARATOR_POINT = "|";private
Hive(14):Database|schema(数据库) DDL操作
1 Create database
Hive中DATABASE的概念和RDBMS中类似,我们称之为数据库。在Hive中, DATABASE和SCHEMA是可互换的,使用DATABASE或SCHEMA都可以。
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROP…
hive-视图与物化视图
一、视图
1、一句话解释
一张虚表,不存数据,对外暴露真实表的一部分数据,增强数据保密性,查询的时候,底层会转换成对真实表的查询,走MapReduce。
2、参考资料
hive的视图_hive 视图_kcy000的博客-CSDN博…
hive基于新浪微博的日志数据分析——项目及源码
有需要本项目的全套资源资源以及部署服务可以私信博主!!! 本系统旨在对新浪微博日志进行大数据分析,探究用户行为、内容传播、移动设备等多个方面的特征和趋势,为企业和个人的营销策略、产品设计、用户服务等提供有益的…

关于Hive程序的全排序
使用Hive可以高效而又快速地编写复杂的MapReduce查询逻辑。但是某些情况下,因为不熟悉数据特性,或没有遵循Hive的优化约定,Hive计算任务会变得非常低效,甚至无法得到结果。一个”好”的Hive程序仍然需要对Hive运行机制有深入的了解…
Hive ---- 分区表和分桶表
Hive ---- 分区表和分桶表 1. 分区表1. 分区表基本语法2. 二级分区表3. 动态分区 2. 分桶表1. 分桶表基本语法2. 分桶排序表 1. 分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的存储到多个目录,每个目录就称为该表的一个分区。在查询时通过where子句中…
HIVE 第四章 数据操作
数据操作篇 加载数据(会生成partition,如果不存在的话;local字段表示为是本机目录,如果不加,则表示为hdfs上的目录;overwrite关键字表示删除目标目录,当没有则保留,但会覆盖同名旧目…
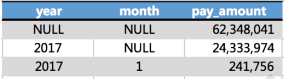
hivesql常用优化技巧
一、列裁剪与分区裁剪
1.列裁剪(只查询需要的字段,千万不要直接写 select * from)
列裁剪就是在查询时只读取需要的列。当列很多或者数据量很大时,如果select所有的列或者不指定分区,导致的全列扫描和全表扫描效率都很…
列转行,行转列(hivesql)
一、笛卡尔积
笛卡尔积即交叉连接,返回结果的行数等于两个表行数的乘积。 笛卡尔积会出现的可能情况: 1.省略连接条件 2.连接条件无效 3.所有表中的所有数据互相连接
二、列转行
concat_ws(): concat_ws (separator,字符串A/字段名A,字符串B/字段名B……

hive数据仓库和mysql的区别
hive和mysql的区别
什么是hive
Hive是建立在Hadoop之上的数据仓库基础构架、是为了减少MapReduce编写工作的批处理系统,Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce。Hive可以理解为一个客户端工具,将我们的sql操作转换为相应的…
java面试题(14):Oracle中truncate和delete的区别
(1)Truncate 是DDL 语句,DELETE 是DML语句。
(2)Truncate 的速度远快于DELETE。当执行DELETE操作时所有表数据先被COPY到回滚表空间,数据量不同花费时间长短不一。而TRUNCATE 是直接删除数据,不…
DataGrip连接Hive、Impala数据源
概述
最近在负责一款数据产品,因调试需要,得经常执行impala查询SQL。公司内部维护有一个Hive/Impala查询平台,本来可以使用多账户登录此查询平台:一个是自己的域账户,当然权限非常有限,很多表不可查询&…
成为卓越数据科学家必备的 13 项技能
一周前,我在 LinkedIn 上问了一个问题:优秀的数据科学家与卓越的数据科学家之间的区别是什么? 令人惊讶的是,我得到了来自各行各业的许多顶尖数据科学家的积极反馈。 我发现这非常实用和有趣。为了进一步了解二者间的区别,我一直…

hive与mysql的安装与配置
hive与mysql的安装与配置
hive是基于hadoop的数据仓库工具,将一定格式的文件映射为一张张表,因此hive版本和hadoop版本有对应关系,一定要检查自己安装的hadoop和hive版本是否兼容;
hadoop版本:2.9.1,hive…
大数据平台架构设计探究
近年来,随着IT技术与大数据、机器学习、算法方向的不断发展,越来越多的企业都意识到了数据存在的价值,将数据作为自身宝贵的资产进行管理,利用大数据和机器学习能力去挖掘、识别、利用数据资产。如果缺乏有效的数据整体架构设计或…
Hive group by 数据倾斜问题处理
一、背景
发现一个10.19号的任务下午还没跑完,正常情况下,一般一个小时就已经跑完,而今天已经超过3小时了,因此去观察实际的任务,发现9个map 其中8个已经完成,就一个还在run,说明有明显的数据倾…

Chapter6 数据仓库Hive
6.1数据仓库概念
6.1.1什么是数据仓库
数据仓库:数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。
数据仓库的目的:支持企业内部的商业分析和决策,让企业可以基于数据仓库的分析结果…

阿语python4-2 美多商城v5.0用户中心-用户基本信息之第5.1.1节用户基本信息逻辑分析...
用户基本信息逻辑分析1. 用户基本信息逻辑分析以下是要实现的后端逻辑用户模型补充email_active字段查询并渲染用户基本信息添加邮箱发送邮箱验证邮件验证邮箱提示:用户添加邮箱时,界面的局部刷新,我们选择使用Vue.js来实现。
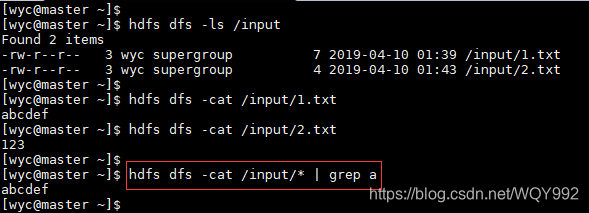
HDFS dfs常用命令大全
根据官方文档的提示我们能够知道可以通过shell的方式访问hdfs中的数据,对数据进行操作。那么首先让我们看一下hdfs的版本,使用命令hdfs version。 -mkdir
创建目录 Usage:hdfs dfs -mkdir [-p] < paths> 选项:-p 很像Unix m…
Hive SQL 优化
1.案例一
原sql:
select count(case when a.id in (select id from b) then 1 esle 0) from a;结果总共数据:727 耗时:
2020-12-28 17:38:31 INFO Cost time is: 568.197s
改造后:
select count(case when b.id is not null then 1 els…
【Hive学习笔记】Hive与传统关系型数据库的区别
1、查询语言 Hive用的是HQL。 关系型数据库用的是SQL。
2、数据存储位置 Hive把数据存储在HDFS中。 关系型数据库将数据存在块设备或本地文件系统中。
3、数据格式 Hive没有定义专门的数据格式,可由用户可以自定义,在自定义的时候…
TSDB的数据如何利用Hadoop/spark集群做数据分析?
物联网场景已经成为各行业巨头和各互联网公司的兵家必争之地,百度云天工TSDB对物联网场景下时序数据表现除了优秀的存储和查询能力,已经成为物联网应用的标配,支撑着智能制造、工业能源、智能车联网、智能家居、智慧城市等多个行业应用。TSDB…

hive 中最常用日期处理函数
hive 常用日期处理函数
在工作中,日期函数是提取数据计算数据必须要用到的环节。哪怕是提取某个时间段下的明细数据也得用到日期函数。今天和大家分享一下常用的日期函数。为什么说常用呢?其实这些函数在数据运营同学手上是几乎每天都在使用的。
技术交…
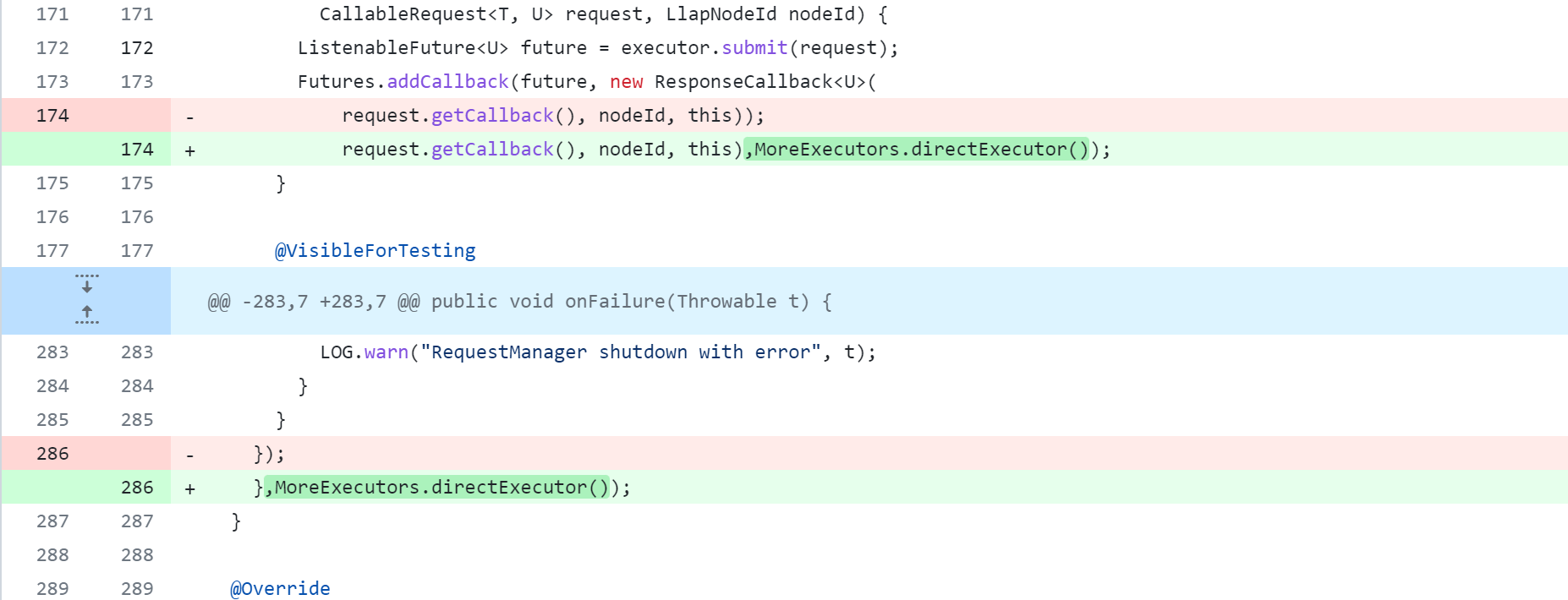
从源代码编译构建Hive3.1.3
从源代码编译构建Hive3.1.3 编译说明编译Hive3.1.3更改Maven配置下载源码修改项目pom.xml修改hive源码修改说明修改standalone-metastore模块修改ql模块修改spark-client模块修改druid-handler模块修改llap-server模块修改llap-tez模块修改llap-common模块 编译打包异常集合异常…
基于MapReduce的Hive数据倾斜场景以及解决方案
文章目录 1 Hive数据倾斜的现象1.1 Hive数据倾斜的场景1.2 解决数据倾斜问题的排查思路 2 解决Hive数据倾斜问题的方法2.1 开启负载均衡2.2 引入随机性2.3 使用MapJoin或Broadcast Join2.4 调整数据存储格式2.5 分桶表、分区表2.6 使用抽样数据进行优化2.7 过滤倾斜join单独进行…
二、编写第一个 Spring MVC 程序
文章目录 一、编写第一个 Spring MVC 程序 一、编写第一个 Spring MVC 程序 代码示例 创建 maven 项目,以此项目为父项目,在父项目的 pom.xml 中导入相关依赖 <dependencies><dependency><groupId>junit</groupId><artifactI…

hive高频使用的拼接函数及“避坑”
hive高频使用的拼接函数及“避坑”
说到拼接函数应用场景和使用频次还是非常高,比如一个员工在公司充当多个角色,我们在底层存数的时候往往是多行,但是应用的时候我们通常会只需要一行,角色字段进行拼接,这样join其他…
Hive on Spark的小文件设置参数
Hive on Spark的小文件设置参数
参数调优 了解完了Spark作业运行的基本原理之后,对资源相关的参数就容易理解了。所谓的Spark资源参数调优,其实主要就是对Spark运行过程中各个使用资源的地方,通过调节各种参数,来优化资源使用的效…
sqoop 整库导入数据
文章目录需求整库导入常用参数通用参数导入控制参数输出格式参数输入分析参数Hive参数代码生成参数需求
最近在迁移老数据的时候需要把mysql的整个库全部迁移到hive,由于mysql的表和库比较多,建表麻烦,所以只有祭出神器–sqoop的整库导入。 …
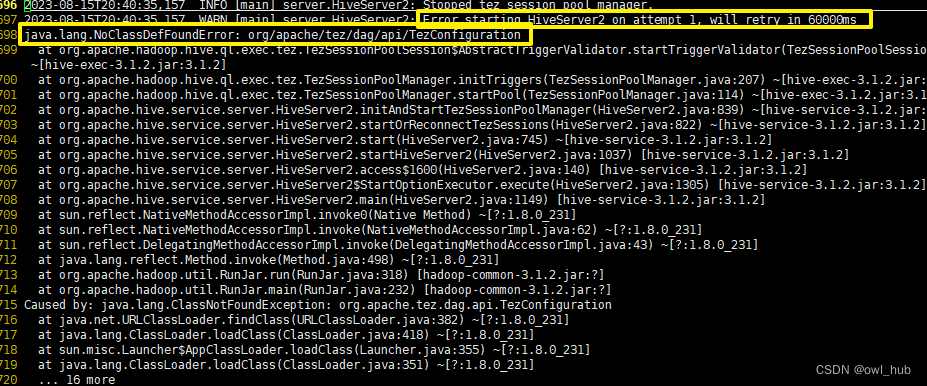
hive-无法启动hiveserver2
启动hiveserver2没有反应,客户端也无法连接( beeline -u jdbc:hive2://node01:10000 -n root)
报错如下
查看hive的Log日志,发现如下报错
如何解决
在hive的hive_site.xml中添加如下代码
<property><name>hive.server2.active.passive…
Hive无法启动的解决方案
关掉虚拟机后,重新启动后,按照Hadoop和Hive的流程重新启动,发现无法启动成功,特别是元数据服务无法启动,出现以下错误: Exception in thread “main” java.lang.RuntimeException: java.net.ConnectException: Call F…
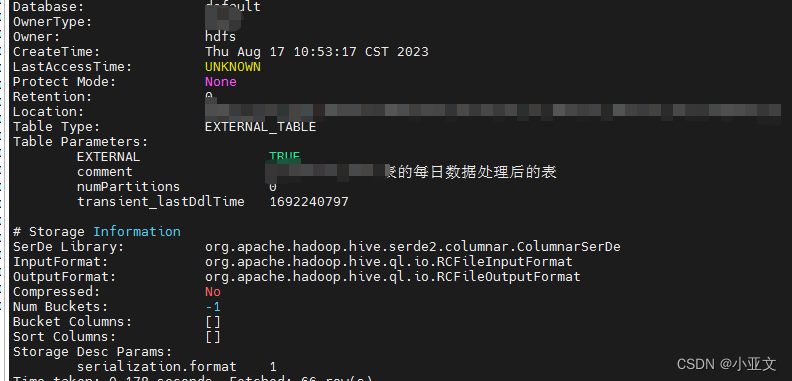
hive--给表名和字段加注释
1.建表添加注释
CREATE EXTERNAL TABLE test(loc_province string comment 省份,loc_city string comment 城市,loc_district string comment 区,loc_street string comment 街道,)COMMENT 每日数据处理后的表
PARTITIONED BY (par_dt string)
ROW FORMAT SERDEorg.apache.had…
beeline连接HIVE默认登入使用anonymous用户权限不够
在用beeline连接hive查询表数据时,出现错误权限不够
ERROR : Job Submission failed with exception org.apache.hadoop.security.AccessControlException
(Permission denied: useranonymous, accessWRITE, inode"/user":hdfs:supergroup:drwxr-xr-xat …

Python 3 使用Hive 总结
启动HiveServer2 服务 HiveServer2 是一种可选的 Hive 内置服务,可以允许远程客户端使用不同编程语言向 Hive 提交请求并返回结果。
Thrift服务配置
假设我们已经成功安装了 Hive,如果没有安装,请参考:Hive 一文读懂 。在启动 H…
Hive 获取数组最后一个元素
引言:
通过split分割当前字段获取数组,并得到最后一个索引的元素,通过hive怎么实现,下面通过不同方法一一验证可行性。
字段样式 shopList : productA,productB,productC
表名 shopTable : shopListTable 一.split size 获取 - 失败 h…
Hive count,sum 使用与扩展
一.引言
有一批市场的用户购买数据,希望进行相关分析:
Table: user_action_in_market
字段:user 、gender、shop_list、buy、cost、dt
字段分别代表购买用户,用户性别(f,m),用户购买商品列表(逗号分割 A,B,C...)&a…
Hive 踩坑之 GC overhead limit exceeded
一.引言
使用Hive执行 select count(*) from table 这种基础语法竟然爆出 GC overhead limit exceeded,于是开始了新的踩坑之旅 二.hive语句与报错
hive -e "select count(*) from $table where day between 20201101 and 20201130;"
统计一下总数结果…

hive执行sql语句报错“Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
hive执行sql语句报错“Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
在安装了hive的节点上用如下命令启动 metastore 服务:
# 后台启动 metastore 服务器端,默认使用 9083 端口
nohup hive --service metast…

Spark实现数据生产到parquet及hive表
1. spark-shell 执行脚本
spark-shell 中相当于定义了一个Object并提供main(),且代码都是在其中执行,不需额外定义Object。
test.scala
//import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSe…
hive 如何使用grouping sets
hive 中 grouping sets,cube,rollup使用说明: grouping sets: 根据不同维度的字段组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL。 cube: 根据group by维度的所有组合进行聚合。 rollup: 为cube的子集࿰…

hive调用方式及数据导出
1. hive命令的3种调用方式
1. 直接使用hive交互式模式(sql的语法)
hive #启动hive
hive>quit;或exit; #退出hive
2. hive -e sql语句(适合短语句)
-- 静音模式:不会显示mapreduce的操作过程
hive -S…
常用Hive函数及自定义UDF函数创建
参考: Hive常用函数总结
1. 字符串相关
1.1 字符串替换
select regexp_replace(\n123\n,\n,);
select translate("MOBIN","BIN","M");
-- MOM
1.2 查找子串位置
1. 集合查找函数: find_in_set 返回以逗号分隔的字符串中str第一次出现…
使用pyspark读写hive数据表
spark 版本 2.1.0
1、读Hive表数据
pyspark提供了操作hive的接口,可以直接使用SQL语句从hive里面查询需要的数据,代码如下:
# -*- coding: utf-8 -*-import sys
from pyspark.sql import SparkSession, HiveContextreload(sys)
sys.setdefaultencoding("utf-8"…

SQL求用户的最大连续登陆天数
建表插入数据
create table tmp_continous
(id STRING ,time DATETIME
);INSERT OVERWRITE TABLE tmp_continous
Select 201, 2017-01-01 00:00:00 union all
Select 201,2017-01-02 00:00:00 union all
Select 202,2017-01-02 00:00:00 union all
Select 202,2017-01-03 0…
Spark3.1.2高可用部署
Spark3.1.2高可用部署文档 解压、改名
tar -zxvf spark-3.1.2-bin-hadoop2.7.tgz -C /opt/
cd /opt/
mv spark-3.1.2-bin-hadoop2.7/ spark
cd spark/conf添加Hadoop配置文件的软链接
ln -s /opt/hadoop/etc/hadoop/core-site.xml
ln -s /opt/hadoop/etc/hadoop/hdfs-site.xm…

大数据开发写sql写烦了,要不要转?
如果说大数据是每天写sql还不太精准(精准的是用各种方式写SQL)当你不创造东西时,你只会根据自己的感觉而不是能力去看待问题。会不会转别的,看个人兴趣,大数据方向还有那么多。 瞅瞅方向:如数据分析师、大数…
hive详解(分区分桶)
分区&分桶
分区
为什么有分区?
随着系统运行时间增长,表的数据量越来越大,而hive查询时通常是是全表扫描,这样将导致大量的不必要的数据扫描,从而大大减低查询效率。
从而引进分区技术,使用分区技术…

Spark基础之:Spark SQL介绍
Spark基础之:Spark SQL介绍一.Spark SQL的概述1、Spark SQL来源2、从代码看Spark SQL的特点3、从代码运行速度看来看Spark SQL二.Spark SQL数据抽象DataFrame1)DataFrame的组成2)DataFrame的代码构建<1>基于rdd的方式1<2>基于rdd…
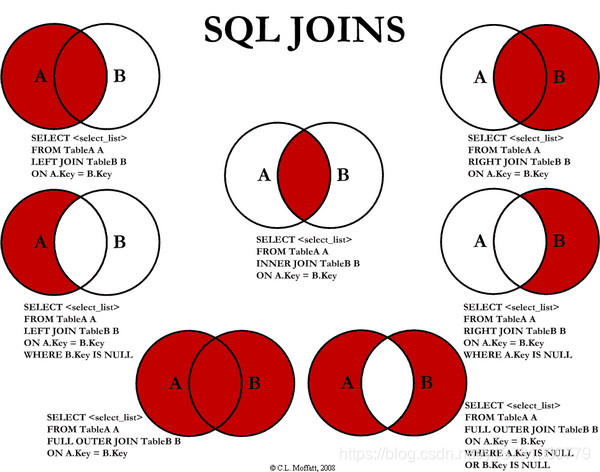
MySQL------DQL查询数据(Data Query LANGUAGE)
1.DQL
(Data Query LANGUAGE : 数据查询语言)
所有的查询操作都用它 Select简单的查询,复杂的查询它都能做~数据库中最核心的语言,最重要的语句使用频率最高的语句
2.查询指定字段
语法: SELECT 字段,... FROM 表
-- 查询全部的学生
…

Kudu用法详尽剖析
最近在招聘要求下突然看到了Apache kudu 于是花了几天时间研究了下,下面简单的给大家介绍下 记得收藏。
一、Kudu 介绍
1.1、背景介绍 在KUDU之前,大数据主要以两种方式存储;
【1】:静态数据 以 HDFS 引擎作为存储引擎…

CentOS7下Hive的安装使用
目录
背景
安装配置运行
命令
插入数据
表分桶
正则serde存储格式
排序和聚集
子查询
视图
自定义函数
写UDF
写UDAF聚集函数
表生成函数UDTF通用版
表分区
删除列
动态分区
导出表到文件系统
查询复合结构中的元素
内置函数
case...when...then.else语句 …
javaweb监听器和juery技术
监听servlet创建
package com.hspedu.listener;import javax.servlet.ServletContext;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;/*** 老韩解读* 1. 当一个类实现了 ServletContextListener* 2. 该类就是一个监听器* 3. 该类可…

hive on tez资源控制
sql insert overwrite table dwintdata.dw_f_da_enterprise2 select * from dwintdata.dw_f_da_enterprise; hdfs文件大小数量展示 注意这里文件数有17个 共计321M 最后是划分为了21个task
为什么会有21个task?不是128M 64M 或者说我这里小于128 每个文件一个map…
尚硅谷大数据项目《在线教育之采集系统》笔记005
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili 目录
P057
P058
P059
P060
P061
P062
P063
P064
P065
P066
P067
P068
P069
P070
P071
P072
P073 P057
#!/bin/bashMAXWELL_HOME/opt/module/maxwell/maxwell-1.29.2status_ma…
Hive加密,PostgreSQL解密还原
当前公司数据平台使用的处理架构,由Hive进行大数据处理,然后将应用数据同步到PostgreSQL中做各类外围应用。由于部分数据涉及敏感信息,必须在Hive进行加密,然后在PG使用时再进行单个数据解密,并监控应用的数据调用事情…
成功解决DataX从Hive导出Oracle的数据乱码问题!
前言
大数据与 RDBMS 之间的数据导入和导出都是企业日常数据处理中常见的一环,该环节一般称为 e-t-l 即 extract-transform-load。市面上可用的 etl 工具和框架很多,如来自于传统数仓和 BI 圈的 kettle/informatica/datastage, 来自于 hadoop 生态圈的 sqoop/datax,抑或使用…

总结:Hive,Hive on Spark和SparkSQL区别
Hive on Mapreduce Hive的原理大家可以参考这篇大数据时代的技术hive:hive介绍,实际的一些操作可以看这篇笔记:新手的Hive指南,至于还有兴趣看Hive优化方法可以看看我总结的这篇Hive性能优化上的一些总结 Hive on Mapreduce执行流…
拾肆:Spark with Hive和Hive on Spark
在 Hive 与 Spark 这对“万金油”组合中,Hive 擅长元数据管理,而 Spark 的专长是高效的分布式计算,二者的结合可谓是“强强联合”。今天这一讲,我们就来聊一聊 Spark 与 Hive 集成的两类方式,一类是从 Spark 的视角出发,我们称之为 Spark with Hive;而另一类,则是从 Hi…
hive 的map数和reduce如何确定
一、 控制hive任务中的map数: 1. 通常情况下,作业会通过input的目录产生一个或者多个map任务。 主要的决定因素有: input的文件总个数,input的文件大小,集群设置的文件块大小(目前为128M, 可在hive中通过set dfs.block.si…
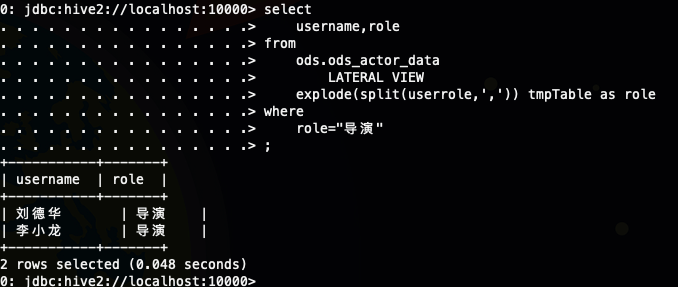
hive 列转行 和 行转列
案例分析一:
列转行
测试数据的格式如下:
hive> select * from col_lie limit 10;
OK
col_lie.user_id col_lie.order_id
104399 1715131
104399 2105395
104399 1758844
104399 981085
104399 …
Spark连接Hive,进行Hive数据表的读写操作
基础环境
Hadoop安装-1,hadoop安装-2spark安装Hive安装
配置
将Hive的conf目录下的hive-site-xml文件拷贝到spark的conf目录下;将Hive中的mysql驱动包(mysql-connector-java-8.0.22.jar,根据自己mysql的版本进行选择࿰…

Hive安装教程(避坑)
下载&解压
第一步,Hive官网下载apache-hive-3.1.2-bin.tar.gz,其中3.1.2是我下载的版本,你要根据自己的hadoop版本进行适配 然后,进行解压。
配置
进入conf目录,将hive-default.xml.template进行拷贝ÿ…
HIVE 第七章 索引
索引 创建索引 create index employees_index on table employees(country) as bitmap #使用bitmap函数建立索引 with deferred rebuild idxproperties(creatordirk,created_atsome_time) in table employees_index_table partitioned by (country,name) co…

一百五十二、Kettle——Kettle9.3.0本地连接Hive3.1.2(踩坑,亲测有效)
一、目的
由于先前使用的kettle8.2版本在Linux上安装后,创建共享资源库点击connect时页面为空,后来采用如下方法,在/opt/install/data-integration/ui/menubar.xul文件里添加如下代码
<menuitem id"file-openZiyuanku" label&…
HIVE 第六章 查询二
不同类型比较 不同类型的数字float double做比较,要注意0.2float大于0.2double 可以cat(0.2 as float) order by and sort by hive的order by是全部数据的排序,在一个reduce中处理排序,默认升序。效率比较低,通常跟limit一起用 可…
8.Hive基础—函数—系统内置函数、常用内置函数、自定义函数、自定义UDF函数、自定义UDTF函数
本文目录如下:第8章 函数8.1 系统内置函数8.2 常用内置函数8.2.1 空字段赋值8.2.2 CASE WHEN THEN ELSE END8.2.3 行转列8.2.4 列转行8.2.5 窗口函数(开窗函数)8.2.6 Rank8.2.7 其他常用函数8.3 自定义函数8.4 自定义 UDF 函数8.5 自定义 UDT…

7.Hive基础—分区表(基本操作、二级分区、动态分区调整)、分桶表(创建、注意事项、Insert导入数据)、抽样查询
本文目录如下:第7章 分区表和分桶表7.1 分区表7.1.1 分区表基本操作7.1.1.1 引入分区表7.1.1.2 创建分区表语法7.1.1.3 加载数据到分区表中7.1.2 二级分区7.1.2.1 创建二级分区表7.1.2.2 正常的加载数据7.1.2.3 把数据直接上传到分区目录上7.1.3 动态分区调整7.1.3.…

【hive】简单介绍hive的几种join
文章目录 前言1. Common Join2. Map Join介绍:使用方法:限制: 3. Bucket Map Join介绍:好处:使用条件:使用方法: 4. Sort Merge Bucket Map Join介绍:如何使用: 5. Skew …

在Hive/Spark上执行TPC-DS基准测试 (PARQUET格式)
在上一篇文章:《在Hive/Spark上运行执行TPC-DS基准测试 (ORC和TEXT格式)》中,我们介绍了如何使用 hive-testbench 在Hive/Spark上执行TPC-DS基准测试,同时也指出了该项目不支持parquet格式。
如果我们想要生成parquet格式的测试数据,就需要使用其他工具了。本文选择使用另…
hive sql 拆解字段
在Hive SQL中,拆解字段通常涉及到字符串操作,如将一个包含多个部分的字符串拆解成多个独立的字段。可以使用内置的字符串函数来实现这个目标。以下是一些常见的用于拆解字段的字符串函数和示例: 1.SUBSTRING(str, start, length):…
Hive练习之蚂蚁森林
背景说明:
以下表记录了用户每天的蚂蚁森林低碳生活领取的记录流水。
user_low_carbon
user_id data_dt low_carbon
用户 日期 减少碳排放
u_001 2017/1/1 10
u_001 2017/1/2 150
u_001 2017/1/2 110
u_001 2017/1/2 10
u_001 2017/1/4 50
u_001 2017/1/4 10…
maven/web app/hive JDBC/IDEA配置-正确配置依赖
1.maven 创建普通Java项目(jdk如果配置好无需调整,直接next) 生成普通java项目如下结构
2.部署为webapp 3.配置Tomcat(和网络上的各教程一致,详细的下载和配置略) Name处可自定义名称,如…
mapJoin与reduceJoin
mapreduce中可以实现map端的join以及reduce端的join,我们看下有什么区别。 mapJoin与reduceJoin数据准备reduce joinmap joinhive的map join测试数据准备
有一张订单表(order):
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6三列对应的…


Hadoop教程_Hive环境搭建(伪分布式/MySQL/Ubuntu)
1.安装MySQL
在Ubuntu下安装MySQL十分简单,只需要运行几行命令即可。
sudo apt-get install mysql-server #需要输入root用户的密码
sudo apt-get isntall mysql-client
sudo apt-get install libmysqlclient-dev
sudo netstat -tap | grep mysql #查看MySQL进程是…
Java Map 到 前台json串
Java Map 到 前台json串 JSONArray j new JSONArray();Set<String> setparams.keySet();if(null!set&&!set.isEmpty()){Map<String, String> jsonMap new HashMap<String, String>();for (Iterator<String> iterator set.iterator(); itera…
6.Hive基础—查询—基本查询(函数、Limit、Where等)、分组(Group By、Having)、Join语句(连接)、排序
本文目录如下:第6章 查询6.1 基本查询(Select…From)6.1.1 全表和特定列查询6.1.1.1 数据准备6.1.1.2 全表查询6.1.1.3 选择特定列查询6.1.2 列别名6.1.3 算术运算符6.1.4 常用函数6.1.5 Limit 语句6.1.6 Where 语句6.1.7 比较运算符…
5.Hive基础—DML 数据操作—数据导入(Load、通过查询语句)、数据导出(Insert、使用Hadoop命令导出)
本文目录如下:第5章 DML 数据操作5.1 数据导入5.1.1 向表中装载数据(Load)5.1.1.1 语法5.1.1.2 实操案例5.1.2 通过查询语句向表中插入数据(Insert)5.1.3 查询语句中创建表并加载数据(As Select)…
网络学生用品商店系统设计与实现(论文+源码)_kaic
摘 要 随着互联网的发展,人们的生活发生了巨大的变化,给人们的生活、工作等方面带来了相当大的提高,电子化成为了节约成本、调高效率的代名词。电子商务是利用微电脑技术和网络通讯技术进行的商务活动,买卖双方通过网络所进行各…
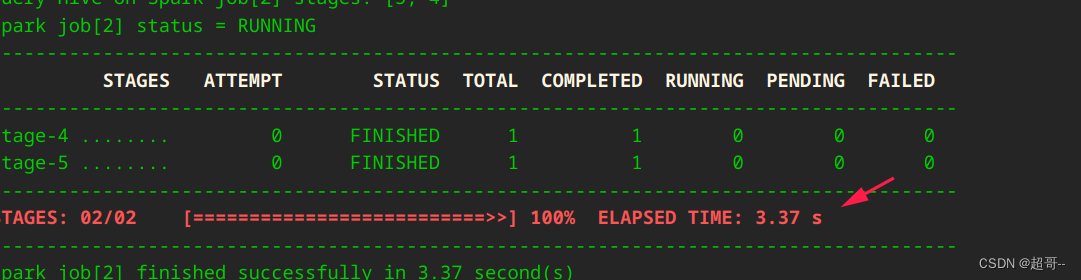
Hive3第六章:更换引擎
系列文章目录
Hive3第一章:环境安装 Hive3第二章:简单交互 Hive3第三章:DML数据操作 Hive3第三章:DML数据操作(二) Hive3第四章:分区表和分桶表 Hive3第五章:函数 Hive3第六章:更换引擎 文章目…
大数据学习:Hive企业级调优
Hive企业级调优
1. Hive表的数据压缩
1.1数据的压缩说明 压缩模式评价 可使用以下三种标准对压缩方式进行评价 1、压缩比:压缩比越高,压缩后文件越小,所以压缩比越高越好2、压缩时间:越快越好3、已经压缩的格式文件是否可以再分…
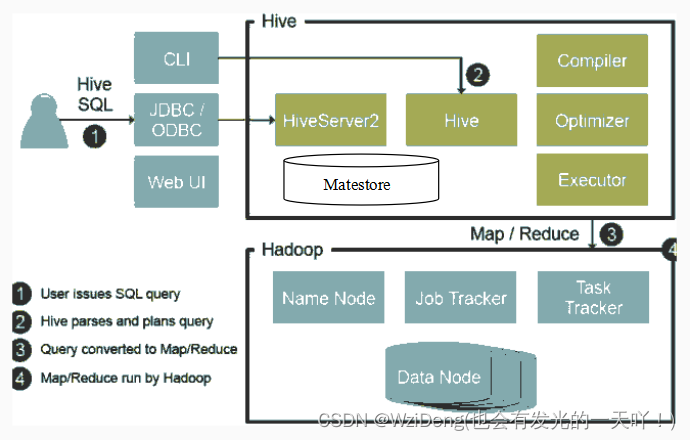

hive中get_json_object函数不支持解析json中文key
问题
今天在 Hive 中 get_json_object 函数解析 json 串的时候,发现函数不支持解析 json 中文 key。 例如:
select get_json_object({ "姓名":"张三" , "年龄":"18" }, $.姓名);我们希望的结果是得到姓名对应…
【大数据】Hive 表中插入多条数据
Hive 表中插入多条数据 在 Hive 中,我们可以使用 INSERT INTO 语句向表中插入数据。当我们需要插入多条数据时,有多种方式可以实现。本文将介绍如何在 Hive 表中插入多条数据,并提供相应的代码示例。
1.使用单个 INSERT INTO 语句插入多条数…
Hive/Spark 整库导出/导入脚本
1. 整库导出为一个SQL文件
database"<your-database-name>"cat << EOF > $database.sql
drop database if exists $database cascade;
create database if not exists $database;
use $database;
EOFfor table in $(beeline -n hadoop -u jdbc:hive2…
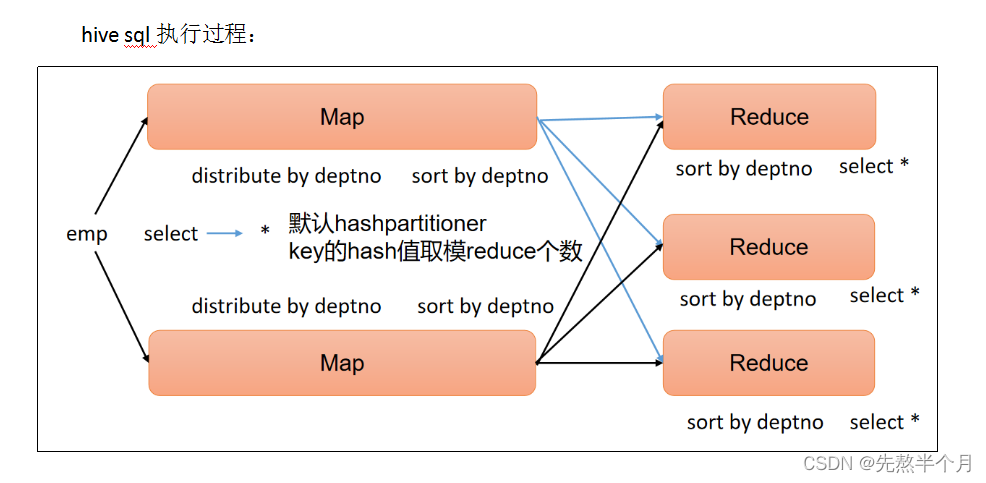
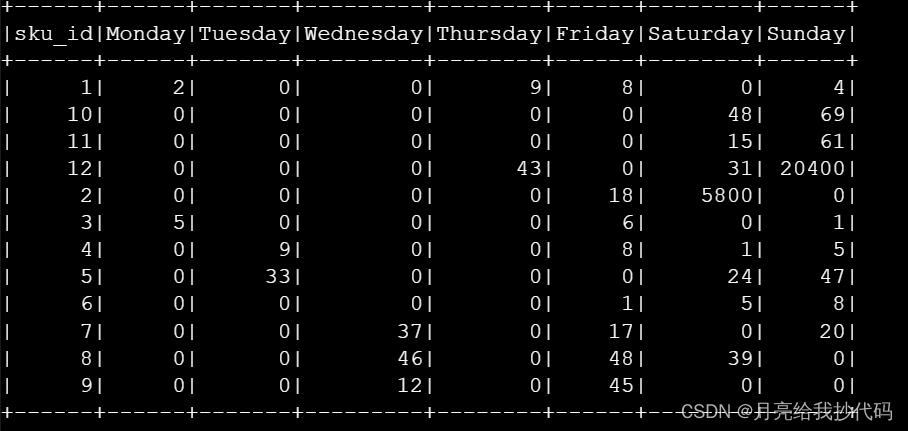
Hive Cli / HiveServer2 中使用 dayofweek 函数引发的BUG!
文章目录 前言dayofweek 函数官方说明BUG 重现Spark SQL 中的使用总结 前言
使用的集群环境为:
hive 3.1.2spark 3.0.2
dayofweek 函数官方说明
dayofweek(date) - Returns the day of the week for date/timestamp (1 Sunday, 2 Monday, …, 7 Saturday).
…
【大数据】Hive 中的批量数据导入
Hive 中的批量数据导入 在博客【大数据】Hive 表中插入多条数据 中,我简单介绍了几种向 Hive 表中插入数据的方法。然而更多的时候,我们并不是一条数据一条数据的插入,而是以批量导入的方式。在本文中,我将较为全面地介绍几种向 H…
修复hive重命名分区后新分区为0的问题
hive分区重命名后,新的分区的分区大小为0 , 例如 alter table entersv.ods_t_test partition(dt2022-11-08) rename to partition(dt2022-11-21) ods_t_test 的2022-11-21分区大小为0。怎样修复 使用 msck repair table 命令来修复表的元数据,让hive重新…
hive 动态分区-动态分区数量太多也会导致效率下降只设置非严格模式也能执行动态分区
hive 动态分区-动态分区数量太多也会导致效率下降&只设置非严格模式也能执行动态分区
结论
在非严格模式下不开启动态分区的功能的参数(配置如下),同样也能进行动态分区数据写入,目测原因是不严格检查SQL中是否指定分区或者…
Hadoop Yarn 配置多队列的容量调度器
文章目录 配置多队列的容量调度器多队列查看 配置多队列的容量调度器
首先,我们进入 Hadoop 的配置文件目录中($HADOOP_HOME/etc/hadoop);
然后通过编辑容量调度器配置文件 capacity-scheduler.xml 来配置多队列的形式。
默认只…
探索数据湖中的巨兽:Apache Hive分布式SQL计算平台浅度剖析!
文章目录 ◆ Apache Hive 概述1.1 分布式SQL计算1.2 Hive的优势 ◆ 模拟实现Hive功能2.1 元数据管理2.2 解析器2.3 基础架构2.4 Hive架构 ◆ Hive基础架构3.1 Hive架构图3.2 Hive组件3.2.1 元数据存储3.2.2 Driver驱动程序3.2.3 用户接口 ◆ Hive部署4.1 VMware虚拟机部署步骤一…
配置开启Hive远程连接
配置开启Hive远程连接 Hive远程连接默认方式远程连接Hive自定义身份验证类远程连接Hive权限问题额外说明 Hive远程连接
要配置Hive远程连接,首先确保HiveServer2已启动并监听指定的端口
hive/bin/hiveserver2检查 HiveServer2是否正在运行
# lsof -i:10000
COMMA…

Servlet的使用(JavaEE初阶系列17)
目录
前言:
1.Servlet API的使用
1.1HttpServlet
1.2HttpServletRequest
1.3HttpServletResponse
2.表白墙的更新
2.1表白墙存在的问题
2.2前后端交互接口
2.3环境准备
2.4代码的编写
2.5数据的持久化
2.5.1引入JDBC依赖
2.5.2创建数据库
2.5.3编写数…

大数据学习:Hive安装部署
Hive的安装部署 注意hive就是一个构建数据仓库的工具,只需要在一台服务器上安装就可以了,不需要在多台服务器上安装。 此处以安装到node03为例;请大家保持统一 使用hadoop普通用户操作 1.1 先决条件
搭建好三节点Hadoop集群;node…

大数据项目实战(安装Hive)
一,搭建大数据集群环境
1.3 安装Hive
1.3.1 Hive的安装
1.安装MySQL服务
1)检查是否安装MySQL,如安装将其卸载。卸载命令 rpm -qa | grep mysql 2)搜索MySQL文件夹,如存在则删除 find / -name mysql rm -rf /etc/s…
Hadoop----Hive的使用
1.数据库的安装,通过网上教程,使用yum进行安装即可,一定删除干净,下载与Hive版本对应的MySQL。
2.Hive的安装,在官网下载.tar.gz包解压至对应目录(/export/server),可以根据网上教程…
大数据之Hive(三)
分区表
概念和常用操作
将一个大表的数据按照业务需要分散存储到多个目录,每个目录称为该表的一个分区。一般来说是按照日期来作为分区的标准。在查询时可以通过where子句来选择查询所需要的分区,这样查询效率会提高很多。
①创建分区表
hive (defau…
Hive 任务限制同时运行的任务数量的配置
Hive任务的并发控制,指同时运行的 container 的数量,防止先提交的任务占用全部的队列资源,导致后来提交的任务无法申请到足够的资源。
Hive 任务的并发控制,和使用的引擎相关。
MapReduce(MR)引擎 Map 任…
Hive学习(12)Hive常用日期函数
1、to_date:日期时间转日期函数
select to_date(2015-04-02 13:34:12);
输出:2015-04-022、from_unixtime:转化unix时间戳到当前时区的时间格式
select from_unixtime(1323308943,’yyyyMMdd’);
输出:201112083、unix_timestam…

Hive 的权限管理
目录
编辑
一、Hive权限简介
1.1 hive中的用户与组
1.1.1 用户
1.1.2 组
1.1.3 角色
1.2 使用场景
1.2.1 hive cli
1.2.2 hiveserver2
1.2.3 hcatalog api
1.3 权限模型
1.3.1 Storage Based Authorization in the Metastore Server
1.3.2 SQL Standards Based …

HDFS文件删除后,HIVE元数据还存在的问题
一.背景 手动在hdfs上删除了一个表的分区数据(inc_day2023-08-30),当查询这个表这个分区的数据时报错文件不存在 二.原因 即HDFS数据删除了,但是hive metastore元数据却没有更新,使用show partitions tablename 发现该分区还存在 三.解决办法…
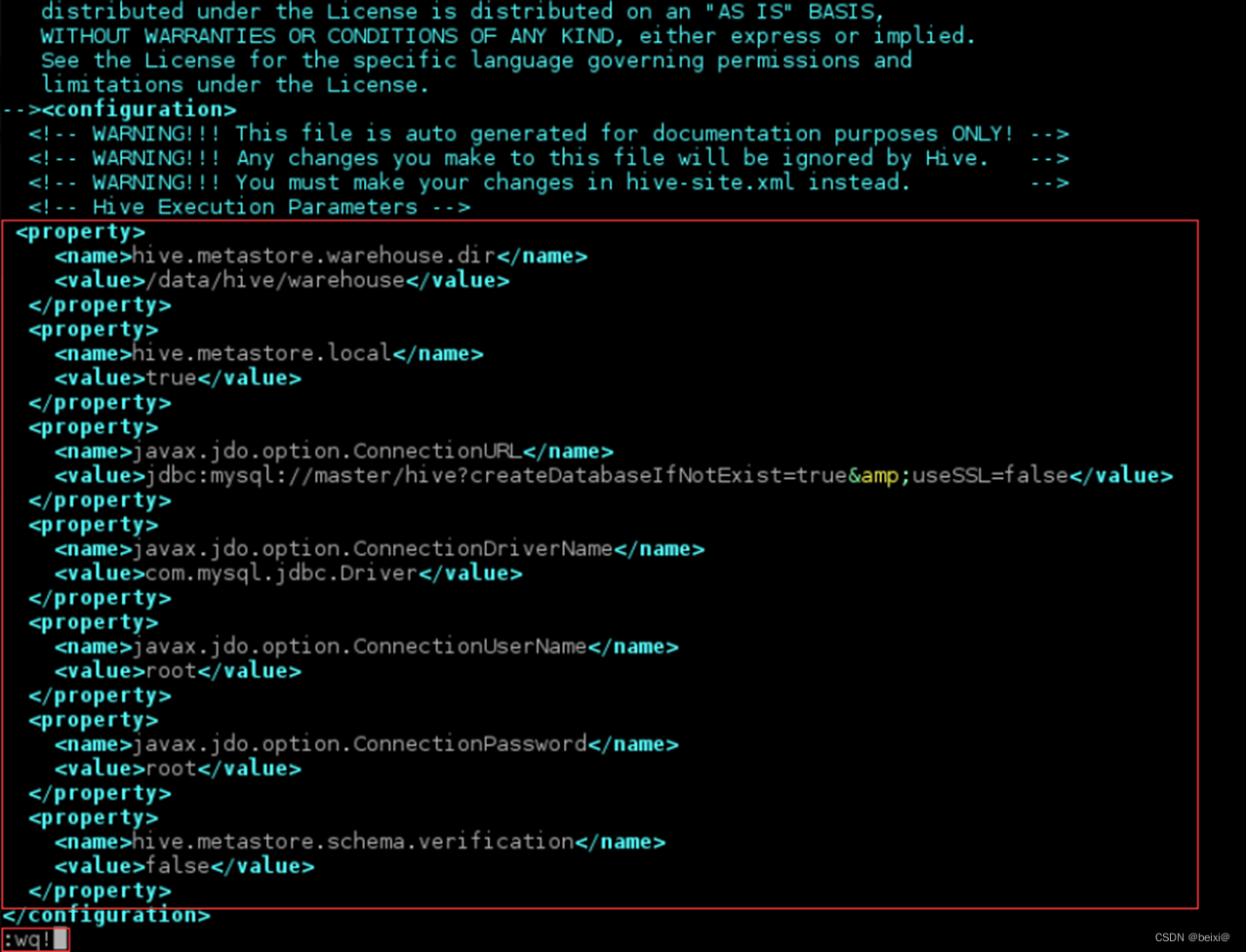
Hive-安装与配置(1)
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…
大数据学习:Hive主流文件存储格式对比
Hive 主流文件存储格式对比
1. hive的SerDe
1.1 hive的SerDe是什么
Serde是 Serializer/Deserializer的简写。hive使用Serde进行行对象的序列与反序列化。最后实现把文件内容映射到 hive 表中的字段数据类型。
为了更好的阐述使用 SerDe 的场景,我们需要了…

Hive SQL 优化大全(参数配置、语法优化)
文章目录 参数配置优化yarn-site.xml 配置文件优化mapred-site.xml 配置文件优化 分组聚合优化 —— Map-Side优化参数解析优化案例 服务器环境说明
机器名称内网IP内存CPU承载服务master192.168.10.1084NodeManager、DataNode、NameNode、JobHistoryServer、Hive、HiveServer…
Hive的静态分区与动态分区
在 Hive 中,分区是一种组织数据的方式,允许你将表数据划分成更小的子集,以便更有效地管理和查询大型数据集。分区可以分为静态分区和动态分区,它们有不同的特点和用途。
1. 静态分区(Static Partitioning):
静态分区是在创建表时显式定义的分区方式。在静态分区中,你…
一百八十二、大数据离线数仓——离线数仓从Kafka采集、最终把结果数据同步到ClickHouse的完整数仓流程(待续)
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、项目背景
项目行业属于交通行业,因此数据具有很…
关于hiveonSpark的错误问题
关于Spark的配置
1.spark
1. spark-env.sh.template
mv命令改名
mv /opt/module/spark/conf/spark-env.sh.template /opt/module/spark/conf/spark-env.sh添加内容
// 有了SPARK_DIST_CLASSPATH配置信息以后,
//Spark就可以把数据存储到Hadoop分布式文件系统HD…
【程序员必知必会3】ClickHouse和Hive究竟哪些区别
ClickHouse和Hive究竟哪些区别
ClickHouse和Hive都是用于大数据处理和分析的分布式存储和计算系统,但它们之间存在一些区别: 架构:ClickHouse采用列式存储和向量化执行引擎,可以实现亚秒级别的数据查询。而Hive采用基于Hadoop的数…

【Hive-SQL】Hive Select 选择语句排除一列或多列
查看除了sample_date以外的所有字段信息
set hive.support.quoted.identifiersnone; select (sample_date)?.
from test.table where sample_date20230713;查看除了sample_date 和 msgtype以外的所有字段信息
set hive.support.quoted.identifiersnone; select (sample_dat…
hive 谓词下推实例分析(on与where的区别)
测试数据
t1 表
select * from t1;
-----------------------------------
| t1.id | t1.name | t1.age | t1.dt |
-----------------------------------
| 1 | aa | 12 | 01 |
| 1 | aa | 12 | 02 |
| 2 | aa | 14 …
【创新项目探索】大数据服务omnidata-hive-connector介绍
omnidata-hive-connector介绍
omnidata-hive-connector是一种将大数据组件Hive的算子下推到存储节点上的服务,从而实现近数据计算,减少网络带宽,提升Hive的查询性能。目前支持Hive on Tez。omnidata-hive-connector已在openEuler社区开源。 …
hivesql执行过程
语法解析
SemanticAnalyzer
SemanticAnalyzer是Hive中的语义分析器,负责检查Hive SQL程序的语义是否正确。SemanticAnalyzer会对Hive SQL程序进行以下检查:
检查过程
语法检查
SemanticAnalyzer会检查Hive SQL程序的语法是否正确,包括关…
大数据课程L4——网站流量项目的Hive离线批处理
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的
⚪ 掌握网站流量项目的 Hive 的占位符与文件的调用;
⚪ 掌握网站流量项目的 Hive 离线批处理过程;
⚪ 掌握网站流量项目的定时任务改造Hive离线处理过程; 一、Hive 的占位符与文件的调用 …

hive葵花宝典:hive函数大全
文章目录 版权声明函数1 函数分类2 查看函数列表3 数学函数取整函数: round指定精度取整函数: round向下取整函数: floor向上取整函数: ceil取随机数函数: rand幂运算函数: pow绝对值函数: abs 4 字符串函数字符串长度函数:length字符串反转函数:reverse…
L2 数据仓库和Hive环境配置
1.数据仓库架构
数据仓库DW主要是一个用于存储,分析,报告的数据系统。数据仓库的目的是面向分析的集成化数据环境,分析结果为企业提供决策支持。-DW不产生和消耗数据 结构数据:数据库中数据,CSV文件 直接导入DW非结构…
Spark 增量抽取 Mysql To Hive
题目要求: 抽取ds_db01库中customer_inf的增量数据进入Hive的ods库中表customer_inf。根据ods.user_info表中modified_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加静态分区,分区字段为etl_date,类型为String,且值为当前日期的前一天日期(分区字段…
Sqoop导入到Hive,Hive使用 HA
Sqoop写入Hive卡在连接Hive的JDBC上不执行
Sqoop访问 启用 HA模式的Hive
找到Hive的安装根目录:$HIVE_HOME/conf 创建一个新的配置文件:beeline-hs2-connection.xml
<?xml version"1.0"?>
<?xml-stylesheet type"text/xsl…
Hive内置函数字典
写在前面:HQL同SQL有很多的类似语法,同学熟悉SQL后一般学习起来非常轻松,写一篇文章列举常用函数,方便查找和学习。
1. 执行模式
1.1 Batch Mode 批处理模式
当使用-e或-f选项运行$ HIVE_HOME / bin / hive时,它将以…
Hive中窗口函数的基本语法和示例
Hive是一个基于Hadoop的数据仓库解决方案,它允许你执行SQL查询和分析大规模数据集。Hive支持窗口函数,用于在查询中执行各种分析操作,例如排名、累积、分组和聚合,以及许多其他分析任务。窗口函数使你能够在查询结果集的特定窗口&…
Hive一行拆分成多行/一列拆分成多列
场景:
hive有张表armmttxn_tmp,其中有一个字段lot_number,该字段以逗号分隔开多个值,每个值又以冒号来分割料号和数量,如:A3220089:-40,A3220090:-40,A3220091:-40,A3220083:-40,A3220087:-40,A3220086:-4…

Hadoop-Hive
1. hive安装部署 2. hive基础 3. hive高级查询 4. Hive函数及性能优化 1.hive安装部署 解压tar -xvf ./apache-hive-3.1.2-bin.tar.gz -C /opt/soft/ 改名mv apache-hive-3.1.2-bin/ hive312 配置环境变量:vim /etc/profile #hive export HIVE_HOME/opt/soft/hive…

hive 静态分区与动态分区(笔记)
目录
前言:
静态分区: 1.创建分区
2.删除分区
3.在分区中插入数据
4.查看分区表数据
动态分区 :
2.查看v表源数据
3.以emp_name为动态字段数据抽取到employee表
总结 前言: Hive中的分区就是把一张大表的数据按照业务需要…
hive执行select count(1)返回0
背景: 做数据质量检核任务的时候,有些数据表有数据,直接查hive执行select count(1) from table返回的值一直是0 问题原因: hive通过select count(1)或者select count(*) 查询的是元数据库里面的rownum,如果数据表数据是通过load、…
Hive UDF 札记
低版本的udf就不说了,太老了,说现在主流的。
1:initialize 方法的进一步理解:
在Apache Hive中,用户自定义函数(UDF)的initialize方法是一个可选的方法,它属于Hive UDF的生命周期…
Hive窗口函数笔试题(面试题)
Hive笔试题实战
短视频
题目一:计算各个视频的平均未完播率
有用户-视频互动表tb_user_video_log: id uid video_id start_time end_time if_follow if_like if_retweet comment_id 1 101 2001 2021-10-01 10:00:00 2021-10-01 10:00:30…
Sqoop【实践 02】Sqoop1最新版 全库导入 + 数据过滤 + 字段类型支持 说明及举例代码(query参数及字段类型强制转换)
Sqoop1最新版举例 1.环境说明2.import-all-tables3.query4.字段类型支持 1.环境说明
还是之前的环境:
# 不必要信息不再贴出
# JDK
[roottcloud ~]# java -version
java version "1.8.0_251"
# MySQL
[roottcloud ~]# mysql -V
mysql Ver 14.14 Distrib…
如何通过Hive/tez与Hadoop的整合快速实现大数据开发
一、Hive的功能
Hive是基于Hadoop的一个外围数据仓库分析组件,可以把Hive理解为一个数据仓库,但这和传统的数据库是有差别的。
传统数据库是面向业务存储,比如 OA、ERP 等系统使用的数据库,而数据仓库是为分析数据而设计的。同时…
Hive on Spark 配置
目录 1 Hive 引擎简介2 Hive on Spark 配置2.1 在 Hive 所在节点部署 Spark2.2 在hive中创建spark配置文件2.3 向 HDFS上传Spark纯净版 jar 包2.4 修改hive-site.xml文件2.5 Hive on Spark测试2.6 报错 1 Hive 引擎简介 Hive引擎包括:MR(默认)…
Servlet Cookie和Session
Cookie和Session
http协议是一个无状态的协议,你每一个跳转到下一个页面的时候都是需要先登录才能使用,这样就很麻烦比如淘宝,没有cookie和session的话,用户在首页已经登录上去了,但是需要再次登录才能选择商品&#…


数据迁移工具 -- Sqoop 安装配置
1、Sqoop概述 Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql等)间进行数据的传递。可以将关系型数据库(MySQL ,Oracle,Postgres等)中的数据导入到HDFS中,也可以将HDFS的数…
任务8:安装大数据统计分析工具Hive
任务描述
知识点:Hive安装应用
重 点:
基于CentOS系统,安装配置Hive创建访问Hive数据库的用户,并授予访问权限
内 容:
安装Hive配置MySQL、设置远程访问权限配置HiveHive服务端、客户端访问
任务指导
1. Hive…
2024.1.30 Spark SQL的高级用法
目录 1、如何快速生成多行的序列
2、如何快速生成表数据
3.开窗函数
排序函数
平分函数
聚合函数 向上向下窗口函数 1、如何快速生成多行的序列
-- 需求: 请生成一列数据, 内容为 1 , 2 , 3 , 4 ,5 仅使用select语句
select explode(split(1,2,3,4,5,,)) as num;-- 需…
(四)hive的搭建2
在(三)hive的搭建1中我们搭建好了hive环境,但是只能本地访问,在本节中配置Hive的访问方式。
1.元数据服务的方式
1.1 编辑hive-site.xml sudo vi hive-site.xml
在文件最后增加以下内容
<!– 指定存储元数据要连接的地址 –…
Flink 集成和使用 Hive Metastore
1. AWS EMR 的 Flink 使用 Hive Metastore 想在 Flink 中使用 Hive Metastore 其实只需要将 Flink Hive Connector 以及 Hive Metastore 有关的 Jar 包部署到 ${FLINK_HOME}/lib 下即可,稍后我们会介绍一下具体做法。但是,如果是 AWS EMR,会有…
Hive的基本SQL操作(DDL篇)
目录
编辑
一、数据库的基本操作
1.1 展示所有数据库
1.2 切换数据库
1.3 创建数据库
1.4 删除数据库
1.5 显示数据库信息
1.5.1 显示数据库信息
1.5.2 显示数据库详情
二、数据库表的基本操作
2.1 创建表的操作
2.1.1 创建普通hive表(不包含行定义格…
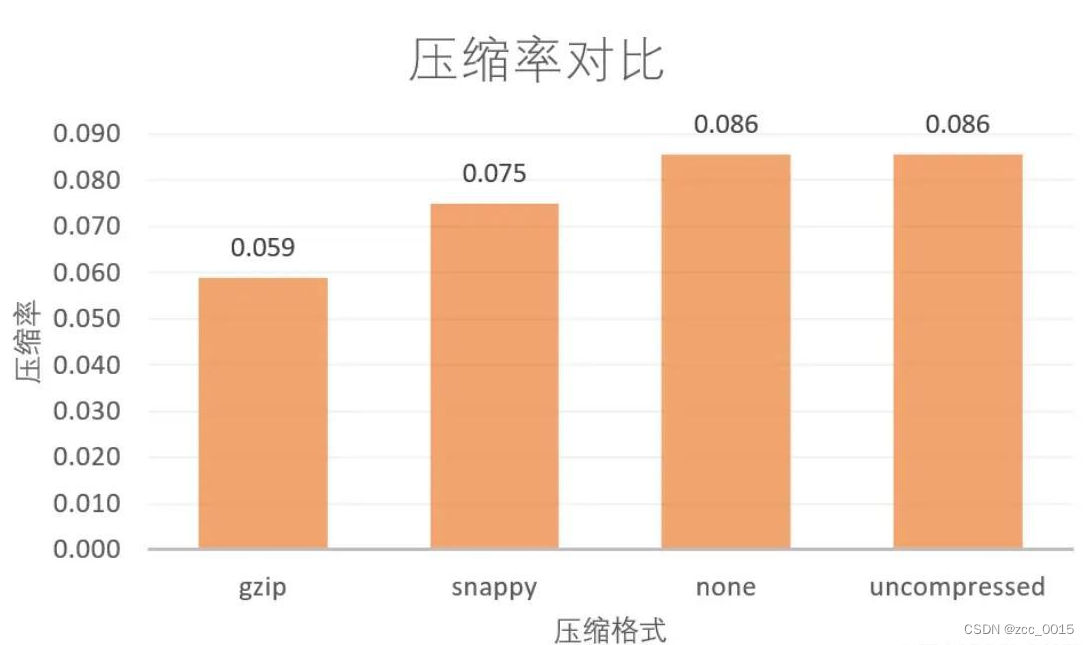
pg数据表同步到hive表数据压缩总结
1、背景 pg库存放了大量的历史数据,pg的存储方式比较耗磁盘空间,pg的备份方式,通过pgdump导出后,进行gzip压缩,压缩比大概1/10,随着数据的积累磁盘空间告警。为了解决pg的压力,尝试采用hive数据…
Apache Hive安装部署详细图文教程
目录
一、Apache Hive 元数据
1.1 Hive Metadata
1.2 Hive Metastore
二、Metastore 三种配置方式
2.1 内嵌模式
2.2 本地模式
2.3 远程模式
三、Hive 部署实战
3.1 安装前准备
3.2 Hadoop 与 Hive 整合
3.3 远程模式安装
3.3.1 安装 MySQL
3.3.2 …
Hive【Hive(二)DML】
启动 hive 命令行:
hive
DML 数据操作
1、数据导入
1.1、向表中装载数据(load)
语法:
hive> load data [local] inpath 数据的path [overwrite] into table student [partition (partcol1val1,…)];(1&#x…
Hive【非交互式使用、三种参数配置方式】
前言 今天开始学习 Hive,因为毕竟但凡做个项目基本就避不开用 Hive ,争取这学期结束前做个小点的项目。 第一篇博客内容还是比较少的,环境的搭建配置太琐碎没有写。
Hive 常用使用技巧
交互式使用
就是我们正常的进入 hive 命令行下的使用…
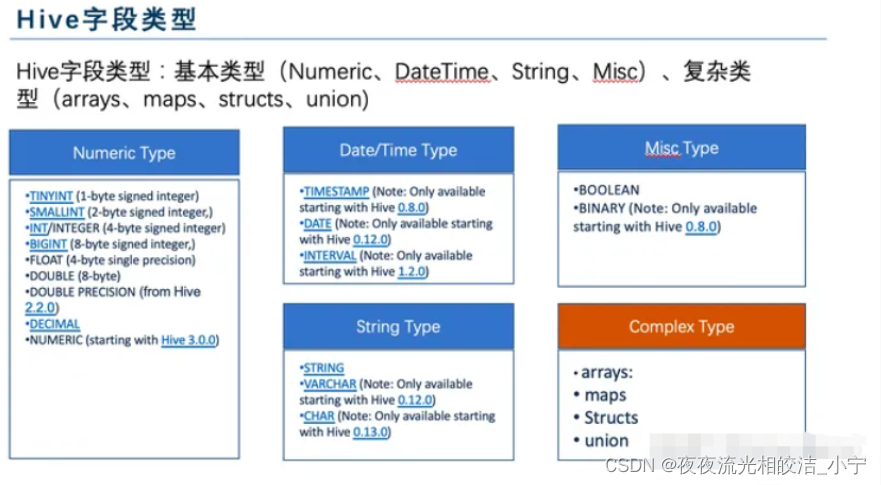
Hive 数据仓库介绍
目录
编辑
一、Hive 概述
1.1 Hive产生的原因
1.2 Hive是什么?
1.3 Hive 特点
1.4 Hive生态链关系
二、Hive架构
2.1 架构图
2.2 架构组件说明
2.2.1 Interface
2.2.1.1 CLI
2.2.1.2 JDBC/ODBC
2.2.1.3 WebUI
2.2.2 MetaData
2.2.3 MetaStore
2.2…
任务长期不释放和占用单节点持续的cpu,导致hivesever2本身内存泄漏造成
任务长期不释放和占用单节点持续的cpu,导致hivesever2本身内存泄漏造成 产生的原因在于:
查询过于复杂或者数据量过大:当有复杂的查询或处理大量数据的请求时,HiveServer2可能会出现高负载。这可能涉及大量的计算、IO操作或涉及大…
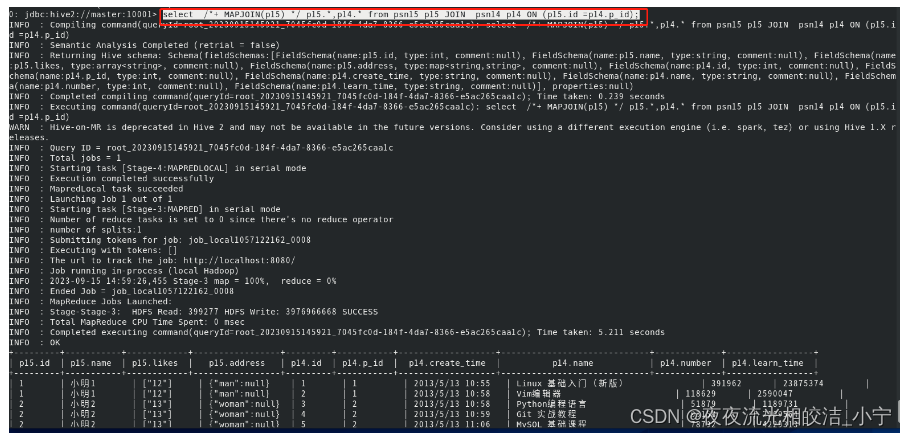
Hive 优化建议与策略
目录
编辑
一、Hive优化总体思想
二、具体优化措施、策略
2.1 分析问题得手段
2.2 Hive的抓取策略
2.2.1 策略设置
2.2.2 策略对比效果
2.3 Hive本地模式
2.3.1 设置开启Hive本地模式
2.3.2 对比效果
2.3.2.1 开启前
2.3.2.2 开启后
2.4 Hive并行模式
2.5 Hive…
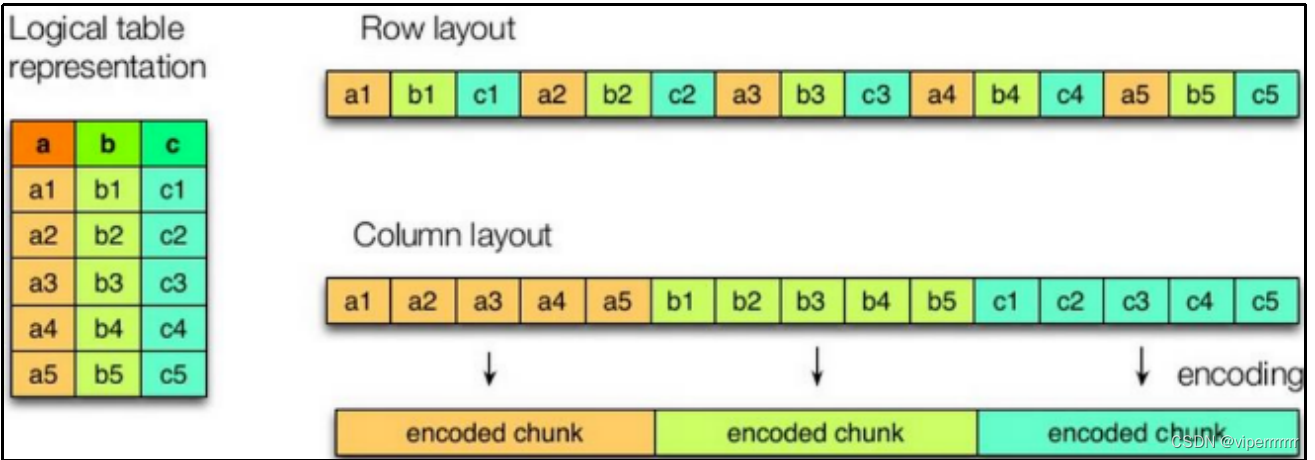
大数据学习(7)-hive文件格式总结
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
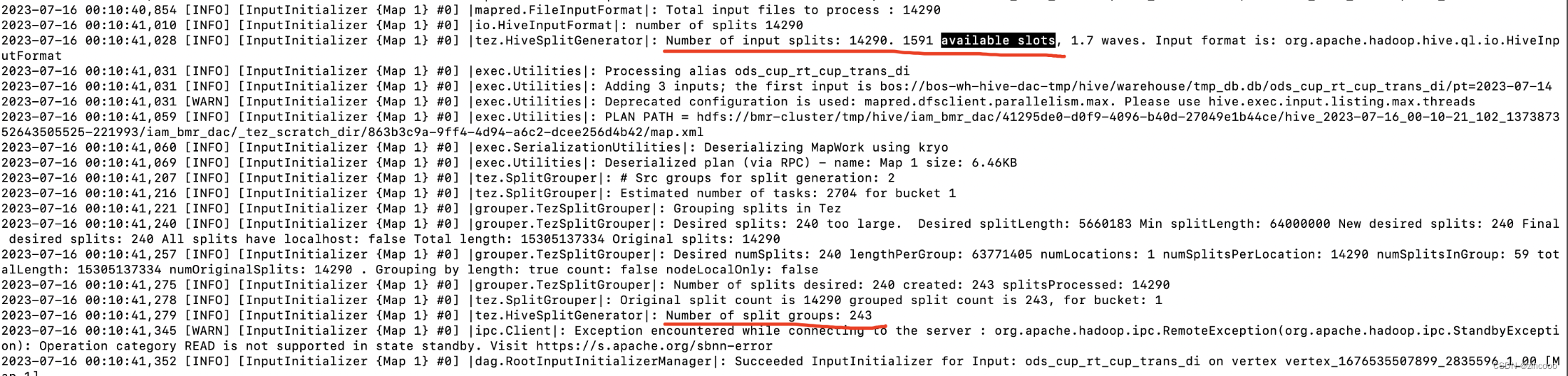
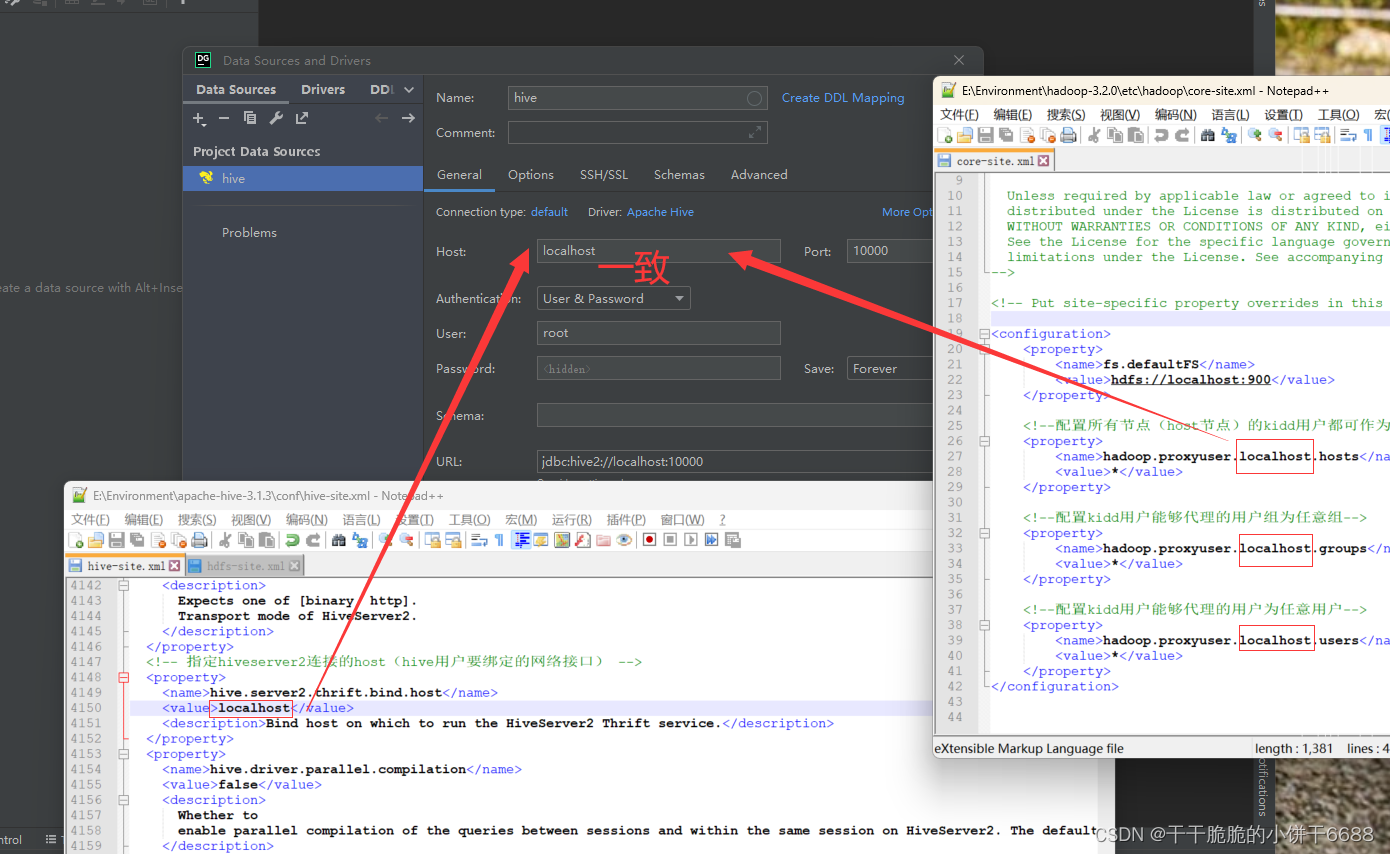
Windows下DataGrip连接Hive
DataGrip连接Hive 1. 启动Hadoop2. 启动hiveserver2服务3. 启动元数据服务4. 启动DG 1. 启动Hadoop 在控制台中输入start-all.cmd后,弹出下图4个终端(注意终端的名字)2. 启动hiveserver2服务
单独开一个窗口启动hiveserver2服务,…
大数据学习(11)-hive on mapreduce详解
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…

【大数据】Hive SQL语言(学习笔记)
一、DDL数据定义语言
1、建库
1)数据库结构 默认的数据库叫做default,存储于HDFS的:/user/hive/warehouse
用户自己创建的数据库存储位置:/user/hive/warehouse/database_name.db
2)创建数据库
create (database|…

4.查询用户的累计消费金额及VIP等级
思路分析: (1)按照user_id及create_date 分组求消费金额total_amount (2)开窗计算同user_id下的累计销售金额sum(total_amount) over(partition by user_id order by create_date ROWS BETWEEN UNBOUNDED PRECEDING AN…
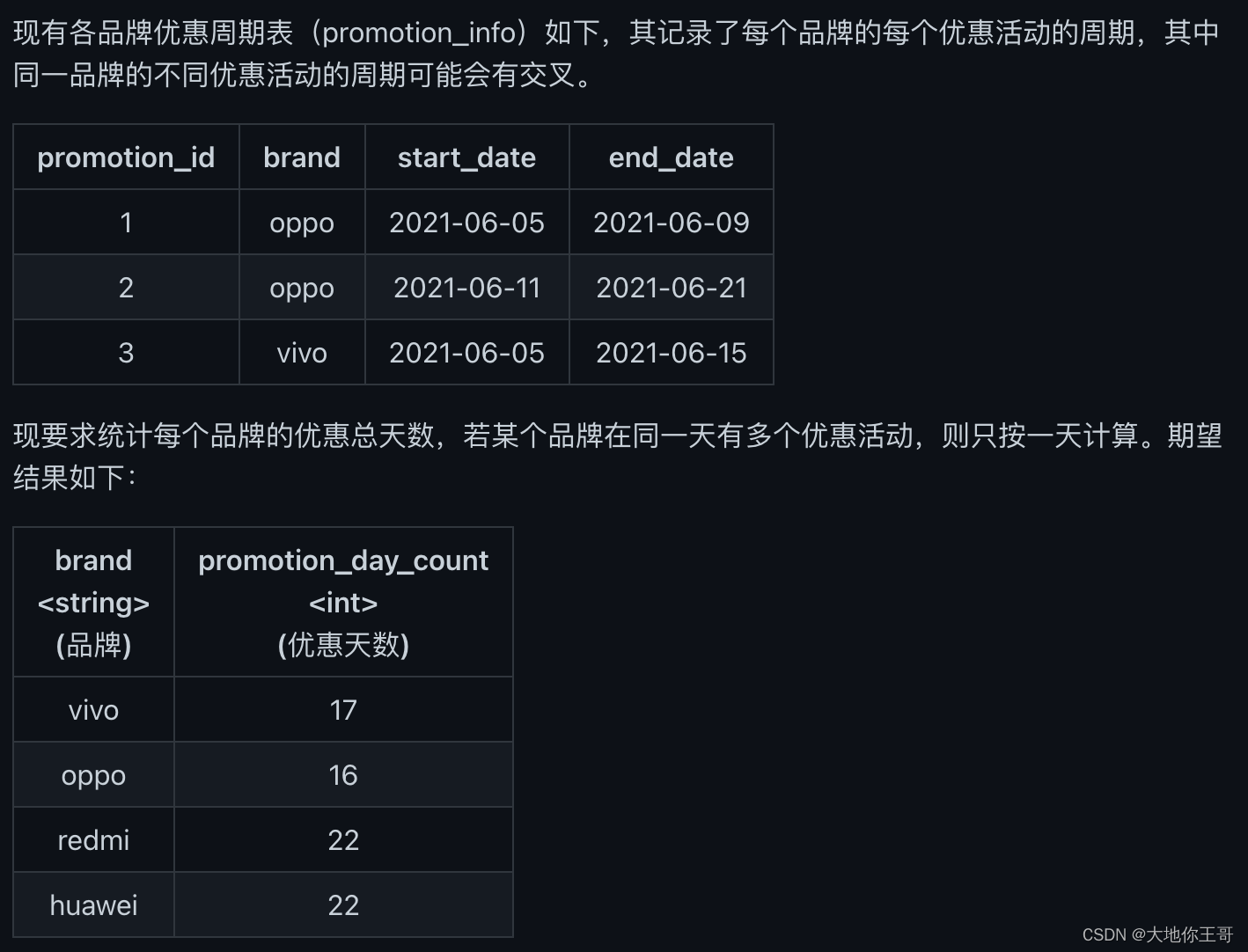
44.日期交叉问题(品牌活动天数计算)
思路分析: (1)计算表中每一条数据所对应的活动天数days (2)使用posexplode函数对days炸裂求其索引值index (3)使用开始日期index补全后面每一个活动日期in_date (4)按品牌…
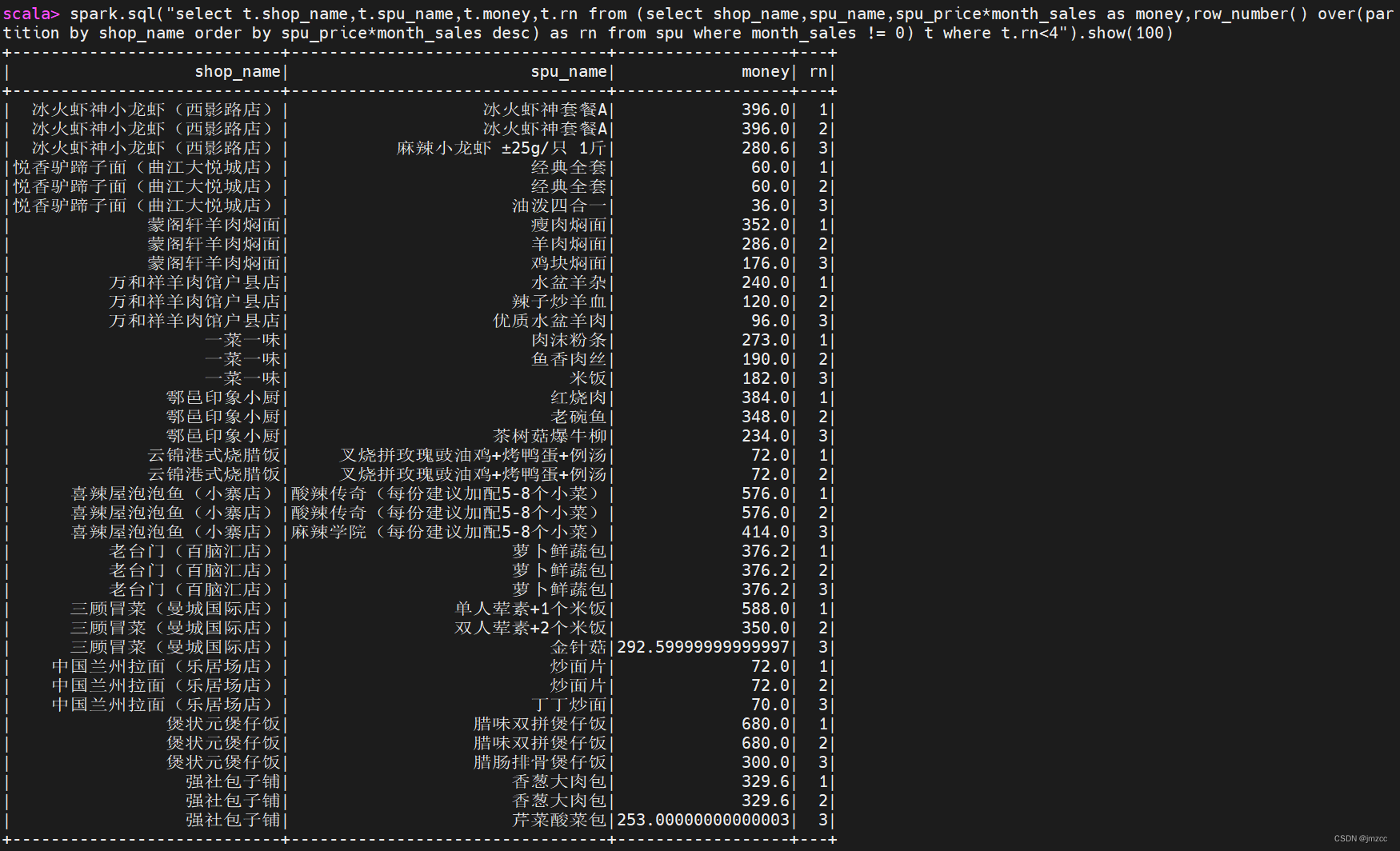
Hive用户中文使用手册系列(一)
Apache Hive
在标题为“Information Platforms and the Rise of the Data Scientist”的文章一文中,Jeff Hammerbacher把“信息平台”描述为“企业摄取(ingest)、处理(process)、生成(generate)信息的行为”与“帮助加速从经验数据中学习”的“中心”。 在Facebook…
世界新冠疫情大数据案例
一、环境要求
HadoopHiveSparkHBase 开发环境。
二、数据描述
countrydata.csv 是世界新冠疫情数,数据中记录了从疫情开始至 7 月 2 日,以国家为单位的每日新冠疫情感染人数的数据统计。字段说明如下: 世界新冠疫情数据 countrydata.cs…
Hive用户中文使用手册系列(二)
命令和 CLI
语言手册命令
命令是 non-SQL statements,例如设置 property 或添加资源。它们可以在 HiveQL 脚本中使用,也可以直接在CLI或Beeline中使用。
命令描述退出使用 quit 或 exit 退出交互式 shell。重启将 configuration 重置为默认值(从 Hive…
[hive] map
在 Hive 中,MAP 是一种复杂数据类型,用于表示键值对的集合。
它类似于其他编程语言中的字典、哈希表或关联数组。
你可以在 Hive 表中使用 MAP 类型的列,也可以在查询过程中创建和操作 MAP。
以下是一些关于在 Hive 中使用 MAP 的常见操作…
API网关与社保模块
API网关与社保模块 理解zuul网关的作用完成zuul网关的搭建 实现社保模块的代码开发 zuul网关 在学习完前面的知识后,微服务架构已经初具雏形。但还有一些问题:不同的微服务一般会有不同的网 络地址,客户端在访问这些微服务时必须记住几十甚至…

使用Sqoop命令从Oracle同步数据到Hive,修复数据乱码 %0A的问题
一、创建一张Hive测试表 create table test_oracle_hive(id_code string,phone_code string,status string,create_time string
) partitioned by(partition_date string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ,;
创建分区字段partition_date,…
hive和presto的求数组长度函数区别及注意事项
1、任务
获取邮箱字符串’后字符串 ,求长度 2、hive & spark-sql 求数组长度的函数 size hive & spark-sql 求数组长度的函数 sizeselect size(split(email, )),split(email, ),split(email, )[0],split(email, )[1]
FROM
(select "jack126.com"…

项目知识点总结-过滤器-MD5注册-邮箱登录
(1)过滤器
使用过滤器验证用户是否登录
/**
* Title: NoLoginFilter.java
* Package com.qfedu.web.filter
* Description: TODO(用一句话描述该文件做什么)
* author Feri
* date 2018年5月28日
* version V1.0
*/
package com.gdsdx…
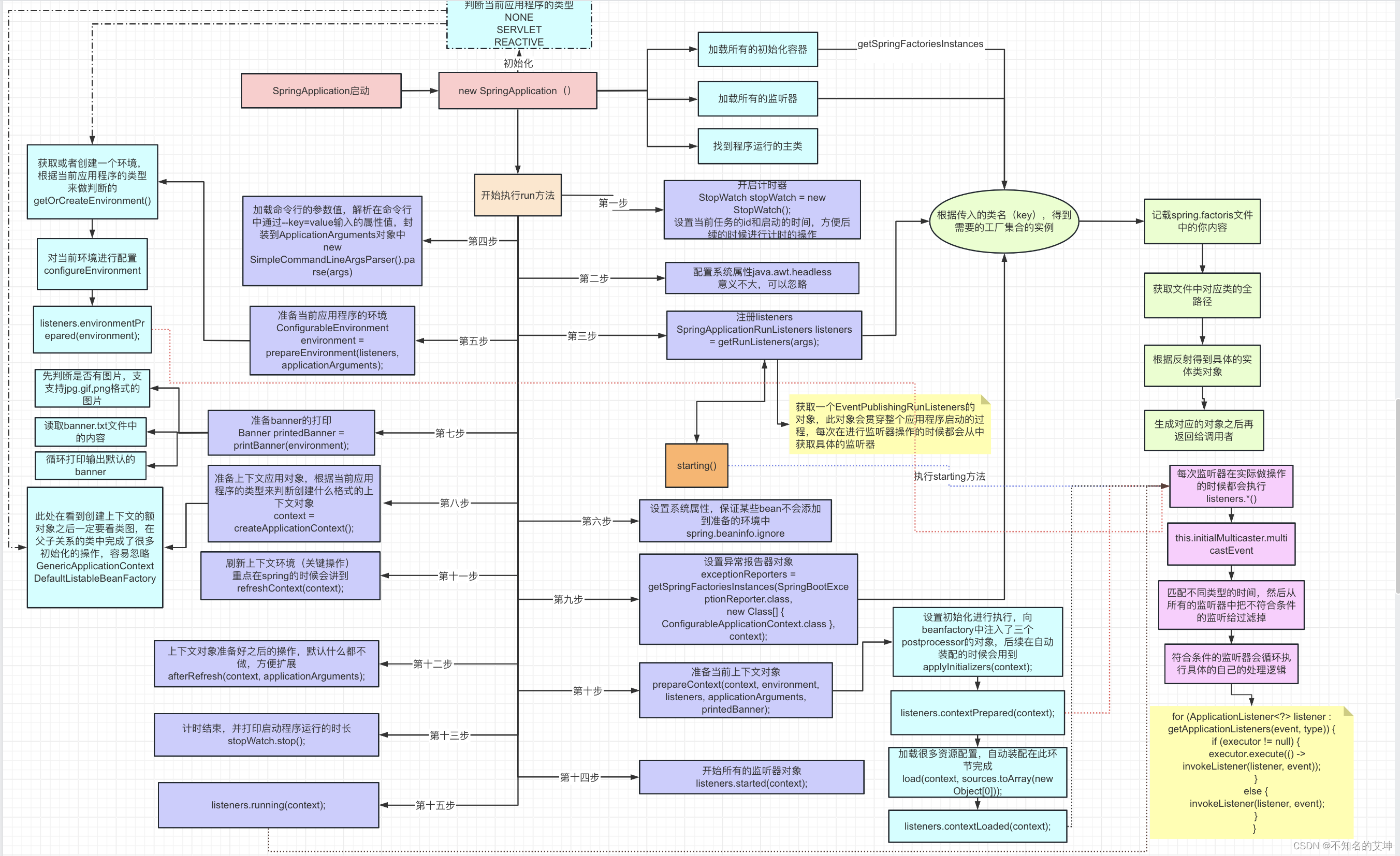
SpringBoot 源码分析(一) 启动过程分析
SpringBoot源码核心内容 SpringBoot的源码主要核心有以下几块; 1、是run()方法 ,做一些准备工作 2、是自动装配原理 3、配置文件加载原理 4、tomcat内嵌原理 一、springboot.run()方法分析 在run方法中主要做的事情如下: SpringBootApplication
public c…
Spark On Hive原理和配置
目录
一、Spark On Hive原理 (1)为什么要让Spark On Hive?
二、MySQL安装配置(root用户) (1)安装MySQL (2)启动MySQL设置开机启动 (3)修改MySQL…
[hive] 窗口函数 ROW_NUMBER()
文章目录 ROW_NUMBER() 示例窗口函数 ROW_NUMBER()
在 Hive SQL 中,ROW_NUMBER()是一个用于生成行号的窗口函数。
它可以为查询结果集中的每一行分配一个唯一的行号。
以下是 ROW_NUMBER() 函数的基本语法:
ROW_NUMBER() OVER (PARTITION BY column…
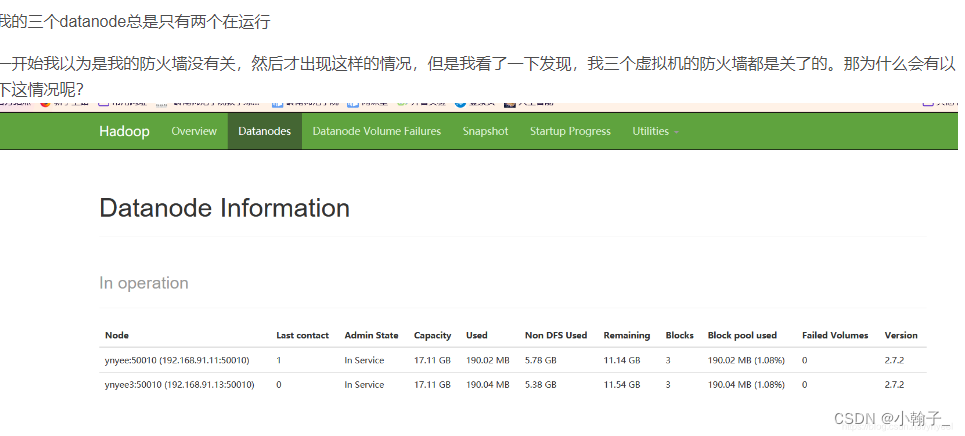
Hadoop、Hive安装
一、 工具
Linux系统:Centos,版本7.0及以上 JDK:jdk1.8 Hadoop:3.1.3 Hive:3.1.2 虚拟机:VMware mysql:5.7.11
工具下载地址: https://pan.baidu.com/s/1JYtUVf2aYl5–i7xO6LOAQ 提取码: xavd…

【Java 进阶篇】在Java Web应用中实现请求数据的共享:域对象详解
在Java Web应用中,处理请求时常常需要在不同的Servlet之间共享数据。为了实现数据的共享和传递,Java提供了域对象的概念,包括请求域(Request域)、会话域(Session域)和应用域(Applica…

apache seatunnel支持hive jdbc
上传hive jdbc包HiveJDBC42.jar到seatunel lib安装目录 原因是cloudera 实现了add batch方法 创建seatunnel任务文件mysql2hivejdbc.conf
env {execution.parallelism = 2job.mode = "BATCH"checkpoint.interval = 10000
}
source {Jdbc {url = "jdbc:mysql:/…

构建 hive 时间维表
众所周知 hive 的时间处理异常繁琐且在一些涉及日期的统计场景中会写较长的 sql,例如:周累计、周环比等;本文将使用维表的形式降低时间处理的复杂度,提前计算好标准时间字符串未来可能需要转换的形式。 一、表设计
结合业务场景常…
Java实现Hive UDF详细步骤 (Hive 3.x版本,IDEA开发)
这里写目录标题 前言1. 新建项目2.配置maven依赖3.编写代码4.打jar包5.上传服务器6.代码中引用 前言
老版本编写UDF时,需要继承 org.apache.hadoop.hive.ql.exec.UDF类,然后直接实现evaluate()方法即可。 由于公司hive版本比较高(3.x&#x…
HiveSQL中last_value函数的应用
一、背景
在以下数据中如何实现对每一个列按照更新时间取最新的非null值?
1 a a null 202301 202301
1 b b null null 202302
1 null c null null 202303
1 d null null null 202304如何实现…
Hive【Hive(八)自定义函数】
自定义函数用的最多的是单行函数,所以这里只介绍自定义单行函数。
Coding
导入依赖
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.3</version></dependency>…
四个BY的区别 HIVE中
在Hive中,有四个BY比较:Order By、Sort By、Distribute By和Cluster By。 Order By是全局排序,只有一个Reducer。它可以按照升序(ASC)或降序(DESC)对结果进行排序。Order By子句通常用在SELECT语…
hiveSQL语法及练习题整理(mysql)
目录 hiveSQL练习题整理:
第一题
第二题
第三题
第四题
第五题
第六题
第七题
第八题
第九题
第十题
第十一题
第十二题
hivesql常用函数:
hiveSQL常用操作语句(mysql) hiveSQL练习题整理: 第一题
我…

【Hive】内部表(Managed Table)和外部表(External Table)相关知识点
在Hive中,有两种类型的表:外部表(External Table)和内部表(Managed Table)。它们在数据存储和管理方式上存在一些重要的区别。 本文就来对这些知识做一个总结。 1、如何在hive中创建内部表和外部表? 2、内部表和外部表的一些区别。 3、怎么查看一个表是内部表还是外部表…
建表时如何合理选择字段类型
前言
我们在建表的时候关于字段类型的选择会有这么几类人:
严谨型 严格调研每个字段可能的大小,然后根据不同字段类型的限制,进行选择,这一类人在创建关系型数据表的时候是没有问题的。图自己省事型 把所有字段都设置为String&a…
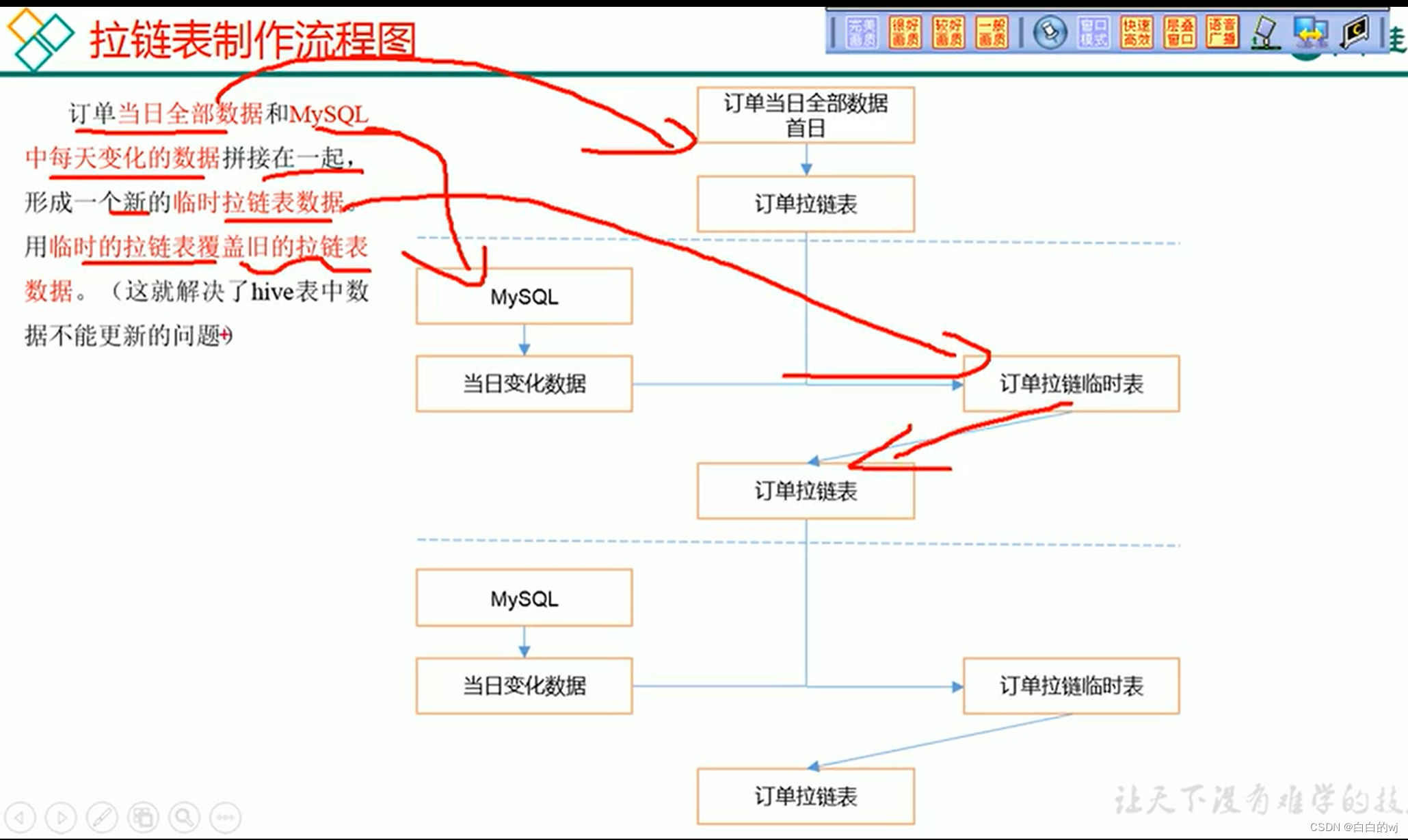
2023.12.1 --数据仓库之 拉链表
目录 什么是拉链表
为什么要做拉链表?
没使用拉链表:
使用了拉链表:
题中订单拉链表的形成过程
实现语句 什么是拉链表 拉链表是缓慢渐变维的一种解决方案.
拉链表,记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始…
Hive的时间操作函数
目录 前言函数使用介绍实际使用判断该天是星期几判断该天对应的周(包含一周开始和结束) 前言
hive 里面的时间函数有很多,今天单讲dayofweek函数,背景:有时候不仅要出日报,还要出周报,需要很多…
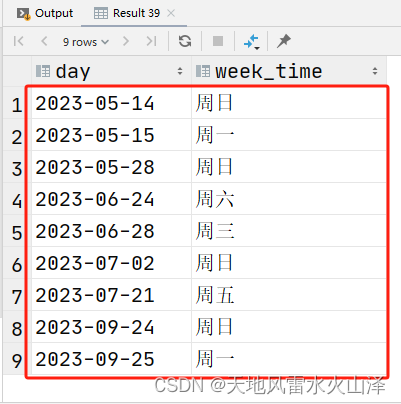
一百八十八、Hive——HiveSQL查询表中的日期是星期几(亲测,附截图)
一、目的
指标需要查询以工作日和周末维度的数据统计,因此需要根据数据的日期判断这一天属于星期几,周一到周五为工作日,周六到周日为周末
二、SQL查询
(一)SQL语句
selectday,case when pmod(datediff(create_tim…
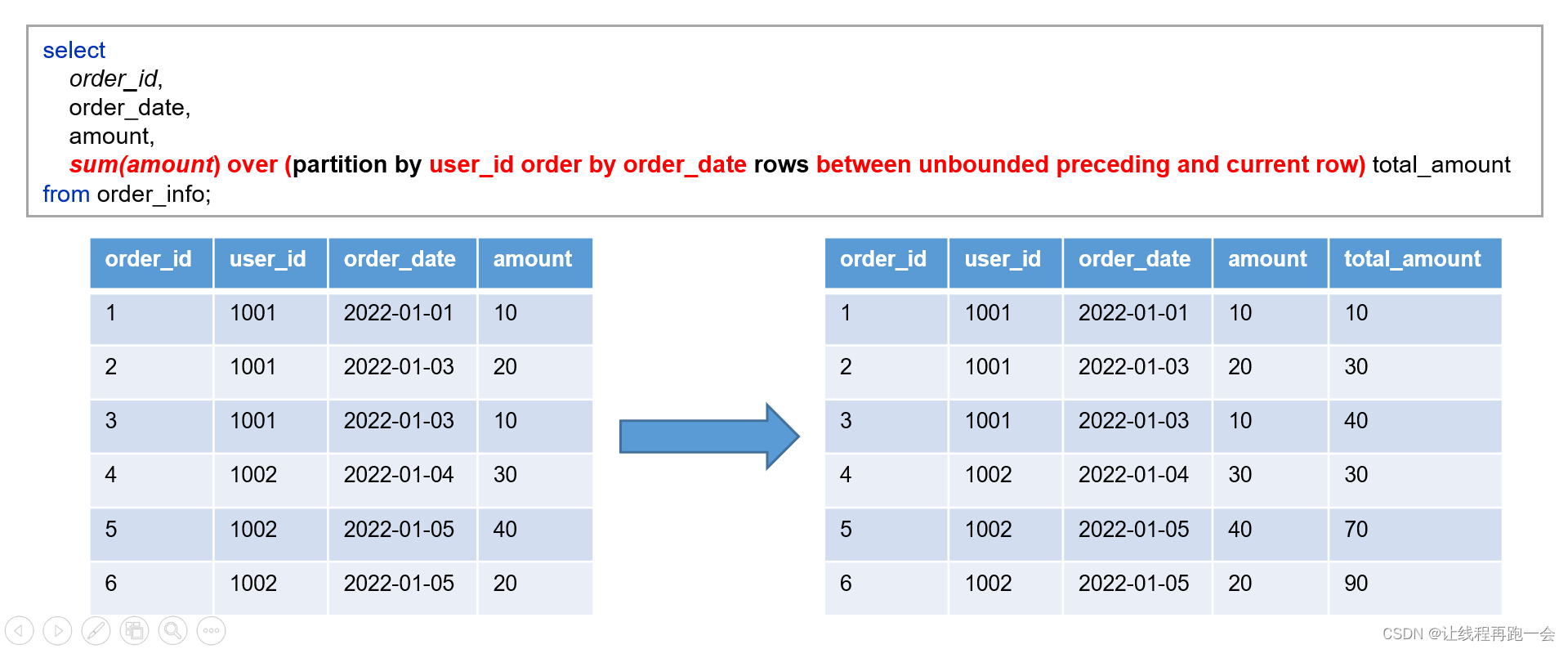
Hive【Hive(六)窗口函数】
窗口函数(window functions)
概述
定义 窗口函数能够为每行数据划分 一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。
语法 窗口函数的语法主要包括 窗口 和 函数 两个部分。其中窗口用于定义计算范围…
基于Kylin的数据统计分析平台架构设计与实现
目录
1 前言
2 关键模块
2.1 数据仓库的搭建
2.2 ETL
2.3 Kylin数据分析系统
2.4 数据可视化系统
2.5 报表模块
3 最终成果
4 遇到问题 1 前言 这是在TP-LINK公司云平台部门做的一个项目,总体包括云上数据统计平台的架构设计和组件开发,在此只做…

SQL进阶 - SQL的编程规范
性能优化是一个很有趣的探索方向,将耗时耗资源的查询优化下来也是一件很有成就感的事情,但既然编程是一种沟通手段,那每一个数据开发者就都有义务保证写出的代码逻辑清晰,具有很好的可读性。
目录
引子
小试牛刀
答案
引言
…
hive统计页面停留时间
1、背景:通过业务埋点数据,统计用户在页面的停留时间
样例数据,样例数据存入表tmp,
有如下字段用户uid、动作时间戳time、页面名称pn、动作名称action
SELECT 12345 AS uid, 1695613731020 AS time, 搜索 AS pn, click AS acti…
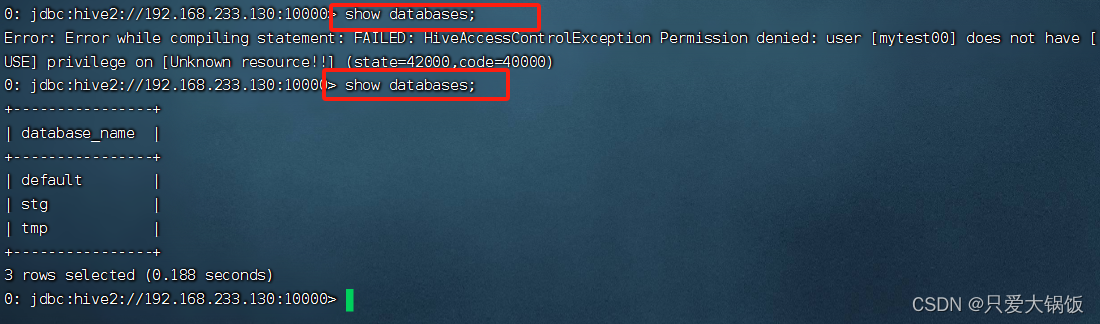
Apache Ranger:(二)对Hive集成简单使用
1.Ranger Hive-plugin安装 进入 Ranger 编译生成的目录下 找到 ranger-2.0.0-hive-plugin.tar.gz 进行解压
tar -zxvf ranger-2.0.0-hive-plugin.tar.gz -C /opt/module/
2.修改配置文件
vim install.properties
#策略管理器的url地址
POLICY_MGR_URLhttp://[ip]:6080#组件…

HiveSQL题——collect_set()/collect_list()聚合函数
一、collect_set() /collect_list()介绍 collect_set()函数与collect_list()函数属于高级聚合函数(行转列),将分组中的某列转换成一个数组返回,常与concat_ws()函数连用实现字段拼接效果。 collect_list:收集并形成lis…
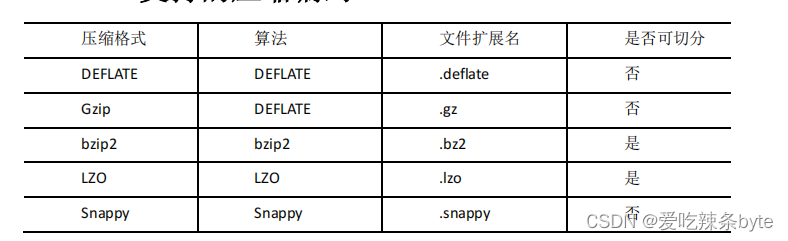
(10)Hive的相关概念——文件格式和数据压缩
目录
一、文件格式
1.1 列式存储和行式存储
1.1.1 行存储的特点
1.1.2 列存储的特点
1.2 TextFile
1.3 SequenceFile
1.4 Parquet
1.5 ORC
二、数据压缩
2.1 数据压缩-概述 2.1.1 压缩的优点 2.1.2 压缩的缺点
2.2 Hive中压缩配置
2.2.1 开启Map输出阶段压缩&…
hive 分桶文件的大小多大最合适
hive 分桶文件的大小多大最合适
Hive 分桶文件大小的最佳选择取决于多个因素,例如数据的大小、查询模式、硬件配置和网络带宽等。一般来说,建议将每个桶的大小控制在128 MB到1 GB之间。
以下是一些关于选择分桶大小的建议:
根据数据大小选…
测试环境搭建整套大数据系统(三:搭建集群zookeeper,hdfs,mapreduce,yarn,hive)
一:搭建zk https://blog.csdn.net/weixin_43446246/article/details/123327143 二:搭建hadoop,yarn,mapreduce。
1. 安装hadoop。
sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt2. 修改java配置路径。
cd /opt/hadoop-3.2.4/etc…
板块一 Servlet编程:第四节 HttpServletResponse对象全解与重定向 来自【汤米尼克的JAVAEE全套教程专栏】
板块一 Servlet编程:第四节 HttpServletResponse对象全解与重定向 一、什么是HttpServletResponse二、响应数据的常用方法三、响应乱码问题字符流乱码字节流乱码 四、重定向:sendRedirect请求转发和重定向的区别 在上一节中,我们系统的学习了…
Flink Catalog 解读与同步 Hudi 表元数据的最佳实践
博主历时三年精心创作的《大数据平台架构与原型实现:数据中台建设实战》一书现已由知名IT图书品牌电子工业出版社博文视点出版发行,点击《重磅推荐:建大数据平台太难了!给我发个工程原型吧!》了解图书详情,…
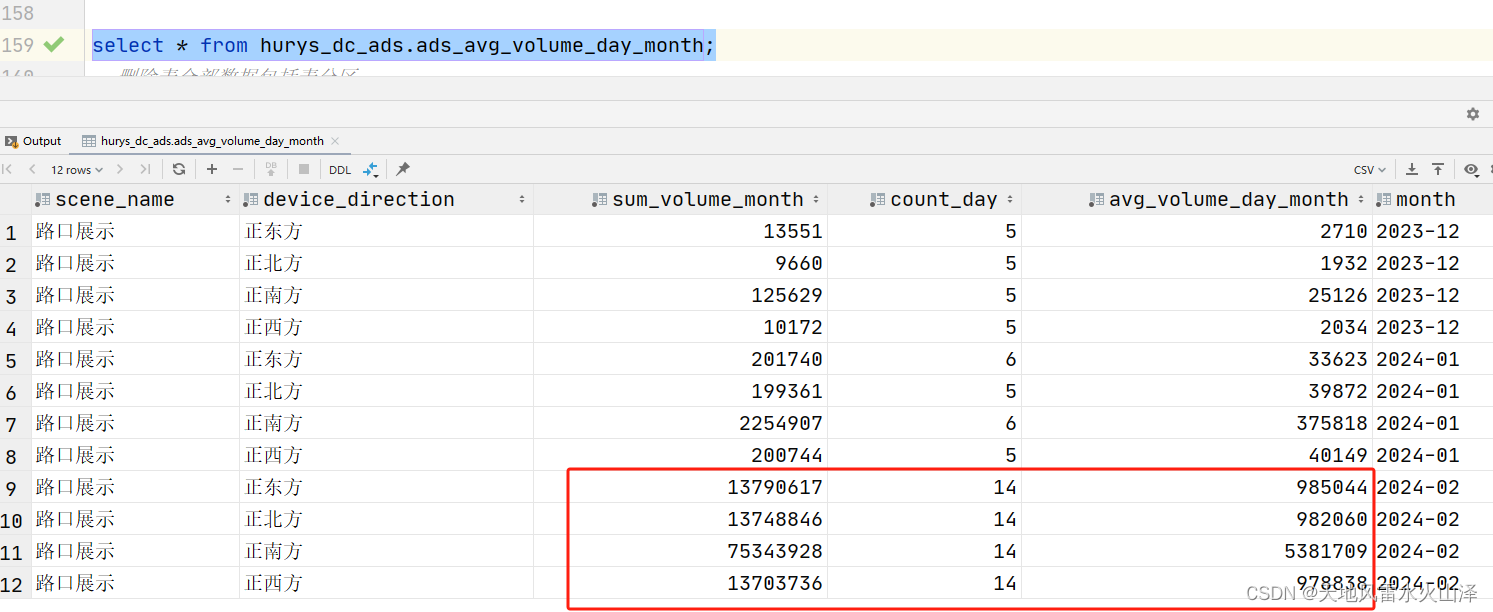
二百二十四、Kettle——曲线实现从Hive插入更新到ClickHouse(分区字段是month或year)
一、目的
对于以month、year为分区字段的数据,不是像day字段分区那样每天增量插入更新即可,而是要以部分字段查询、部分字段更新,但是ClickHouse数据库并不适合更新操作,直接使用Kettle的插入更新控件会导致问题,必须…

hive-批量导出表结构,导入表结构
1、导出hive表结构
datastudio可以连接hive库,通过show databases 语句可以显示hive下建了多少数据库名。
使用use 数据库名,进入某个数据库下,通过show tables可显示该数据库下建了多少张表。
将所有库的表数据整理成库名.表名的形式放入…
Hadoop,Hive 数据预处理CR
记录一次大材小用,我在将.csv电影数据集 电影json数据 导入MySQL时,出现了报错: 很明显,意味着.csv中的数据有非utf8编码的, 尝试使用file查看了下.csv文件的编码格式: 如果不确定原始编码,可以先用file命令尝试检测一下: file -i input.csv该命令会显示文件的MIME类型…

Hive-技术补充-初识ANTLR
一、背景
要清晰的理解一条Hql是如何编译成MapReduce任务的,就必须要学习ANTLR。下面是ANTLR的官方网址,下面让我们一起来跟着官网学习吧,在学习的过程中我参考了《antlr4权威指南》,你也可以读下这本书,一定会对你有…
Hive Sql获取含有特殊字符key的json数据
hive表中json数据的key含有.符号,所以使用get_json_object(str,“$.key_1.key_2”)语法的时候就会获取到null。解法是通过json_to_map方法将json数据变成一个map结果,然后用key下标的方式获取值,代码
json_to_map(str)["key_1.key_2]
[数据湖iceberg]-hive集成数据湖读取数据的正确姿势
1 概述
Iceberg作为一种表格式管理规范,其数据分为元数据和表数据。元数据和表数据独立存储,元数据目前支持存储在本地文件系统、HMS、Hadoop、JDBC数据库、AWS Glue和自定义存储。表数据支持本地文件系统、HDFS、S3、MinIO、OBS、OSS等。元数据存储基于…
數據集成平台:datax將hive數據步到mysql(全部列和指定列)
數據集成平台:datax將hive數據步到mysql(全部列和指定列)
1.py腳本
傳入參數: target_database:數據庫 target_table:表 target_columns:列 target_positions:hive列的下標&#x…
智能柜架构解析与实践探索——打造智能化、高效的物品存储管理系统
在物联网和人工智能技术的快速发展下,智能柜作为智能化物品存储管理系统,正在逐渐走进我们的生活和工作场景。本文将深入探讨智能柜的架构设计原理、核心技术和实践经验,带领读者了解如何构建智能、高效的智能柜系统,提升物品管理…

Hive SQL必刷练习题:留存率问题(*****)
留存率:
首次登录算作当天新增,第二天也登录了算作一日留存。可以理解为,在10月1号登陆了。在10月2号也登陆了,那这个人就可以算是在1号留存
今日留存率 (今日登录且明天也登录的用户数) / 今日登录的总…
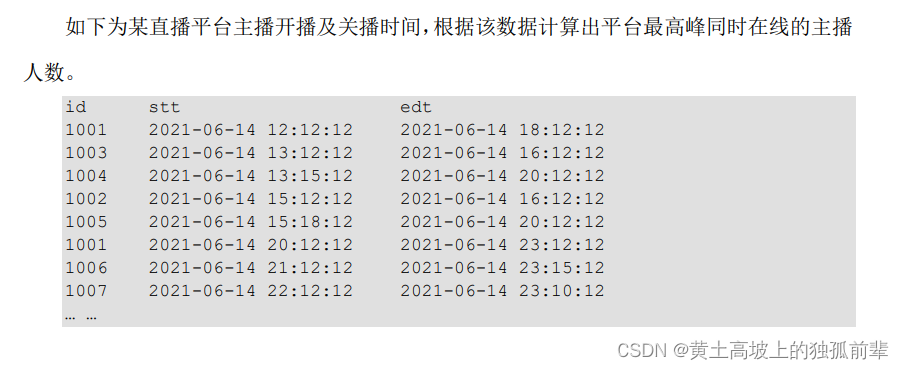
HiveSQL一本通 - 案例实操
文章目录 0.HiveSQL一本通使用说明6.综合案例练习之基础查询6.1 环境准备创建数据表数据准备加载数据 6.2 简单查询练习1.查询姓名中带“山”的学生名单2.查询姓“王”老师的个数3.检索课程编号为“04”且分数小于60的学生的分数信息,结果按分数降序排列4.查询数学成…
Apache Hive的部署与体验
一、Apache Hive概述
什么是分布式SQL计算? 以分布式的形式,执行SQL语句,进行数据统计分析。Apache Hive是做什么的?
很简单,将SQL语句翻译成MapReduce程序,从而提供用户分布式SQL计算的能力。传统MapRed…
搭建hive环境,并解决后启动hive命令报 hive: command not found的问题
一、问题解决
1、问题复现 2、解决问题 查阅资料得知该问题大部分是环境变量配置出了问题,我就输入以下命令进入配置文件检查自己的环境变量配置:
[rootnode03 ~]# vi /etc/profile 检查发现自己的hive配置没有问题 ,于是我就退出…
【八股】2024春招八股复习笔记2(大数据开发,Java)
【八股】2024春招八股复习笔记2(大数据开发) 文章目录 1、大数据存储(Flume、Hive、HBase、HDFS)2、大数据计算(MapReduce,Spark、Flink)3、大数据集群(Yarn、ZooKeeper、kafka&…
hive 、spark 、flink之想一想
hive 、spark 、flink之想一想
hive
1:hive是怎么产生的?
Hive是由Facebook开发的,目的是让拥有SQL知识的分析师能够在Hadoop上进行数据查询。Hive提供了类SQL的查询语言HiveQL,通过将HiveQL查询转换为MapReduce任务来在Hadoop…

开源大数据集群部署(十二)Ranger 集成 hive
作者:櫰木
1、解压安装
在hd1.dtstack.com主机上执行(一般选择hiveserver2节点)
解压ranger-2.3.0-hive-plugin.tar.gz
[roothd1.dtstack.com software]#tar -zxvf ranger-2.3.0-hive-plugin.tar.gz修改install.properties配置
[roothd1…
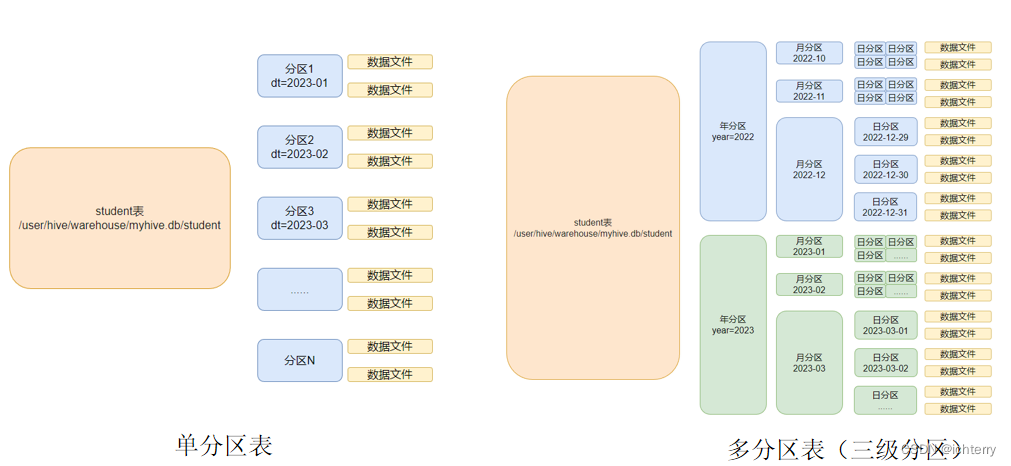
Apache Hive的基本使用语法
一、数据库操作
创建数据库
create database if not exists myhive;查看数据库
use myhive;
desc database myhive;创建数据库并指定hdfs存储
create database myhive2 location /myhive2;删除空数据库(如果有表会报错)
drop database myhive;…
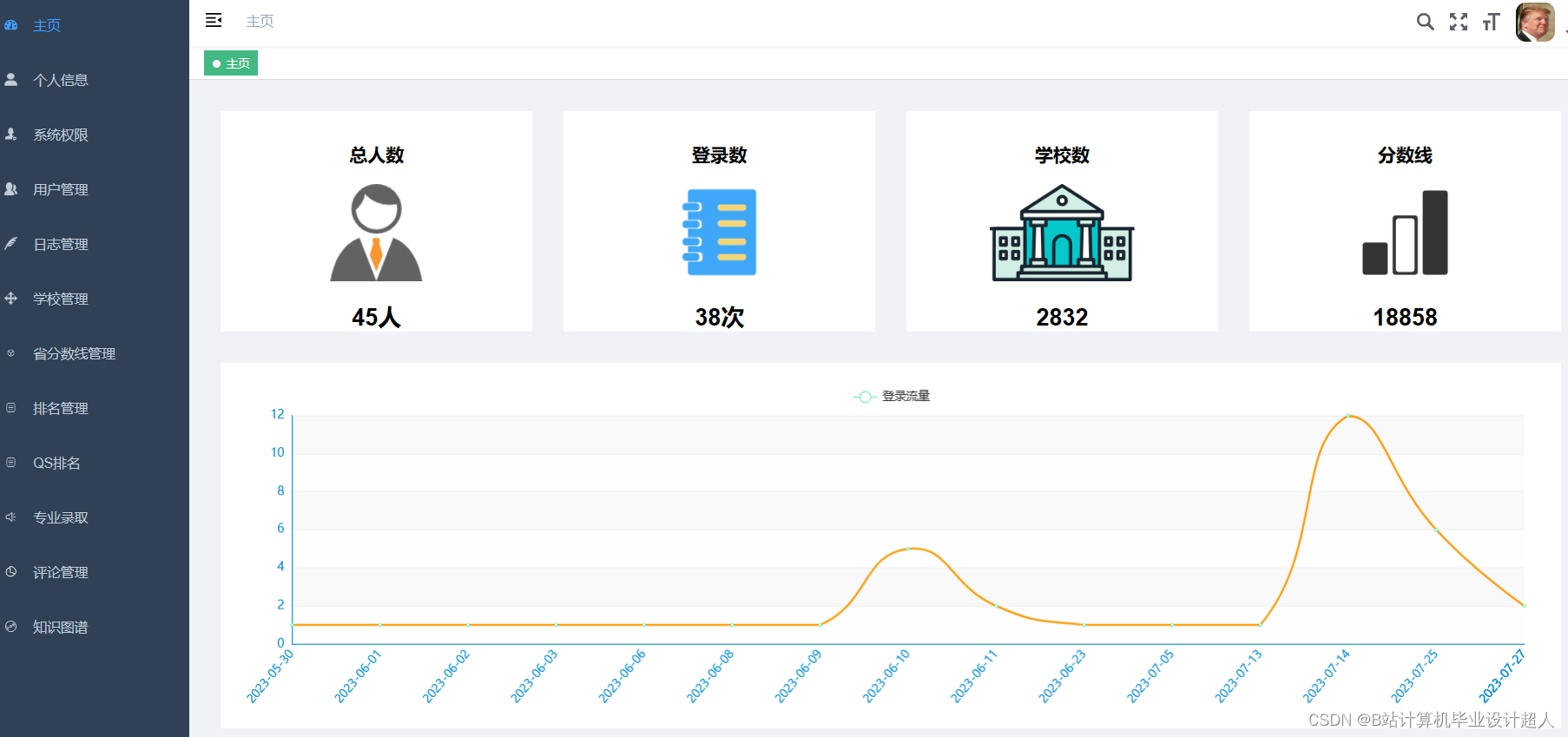
计算机毕业设计Python+Spark知识图谱高考志愿推荐系统 高考数据分析 高考可视化 高考大数据 大数据毕业设计 机器学习 深度学习 人工智能
学院(全称): 专业(全称): 姓名 学号 年级 班级 设计(论文) 题目 基于Spark的高考志愿推荐系统设计与实现 指导教师姓名 职称 拟…
hive--字符串截取函数substr(),substring()
一、字符串截取函数:substr,substring
语法: substr(string A, int start),substring(string A, int start)
返回值: string
说明:返回字符串A从start位置到结尾的字符串
举例: hive> select substr(abcde,3); cde hive…

Presto简介、部署、原理和使用介绍
Presto简介、部署、原理和使用介绍
1. Presto简介
1-1. Presto概念
Presto是由Facebook开发的一款开源的分布式SQL查询引擎,最初于2012年发布,并在2013年成为Apache项目的一部分;Presto 作为现在在企业中流行使用的即席查询框架&#x…
hive,hbase集群拷贝注意事项
注意事项:
1.有足够的带宽,最好能300M/S 磁盘写入速度
2.两个集群的在一个网络,且新集群的主机名可以访问的域名。 CDH的主机名不能轻易更改,若只能换主机名建议重新部署CDH集群。
3.数据拷贝跑后台进程 hive表跨集群备份
注…
HIVE中的常用和不常用的函数总结及hive中的常见问题(自用)
笛卡尔积
假设A和B是两个集合,存在一个集合,它的元素是用A中元素为第一元素,B中元素为第二元素构成的有序二元组,这个集合称为集合A和集合B的笛卡尔积,记为A X B。
eg:假设集合A{a, b},集合B{0, 1, 2}&am…
hive 中少量数据验证函数的方法-stack
可以使用 stack 将少量数据直接写在sql中,然后用于验证是否正确
1、每个省累计销量前1名的城市 t1(pro_name,city_name,sale_num,sale_date) 源数据: ‘河北’,‘石家庄’,‘1’,‘2022-01-01’ ,‘河北’,‘石家庄’,‘2’,‘2022-01-02’ ,‘河北’,‘…

LZO索引文件失效说明
在hive中创建lzo文件和索引时,进行查询时会出现问题.hive的默认输入格式是开启小文件合并的,会把索引也合并进来。所以要关闭hive小文件合并功能!
Apache Hive的基本使用语法(一)
一、数据库操作
创建数据库
create database if not exists myhive;查看数据库
use myhive;
desc database myhive;创建数据库并指定hdfs存储
create database myhive2 location /myhive2;删除空数据库(如果有表会报错)
drop database myhive;…

Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)15-28章
Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)15-28章[Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性能优化)1-14章](https://blog.csdn.net/wt334502157/article/details/127489556)
Hive3入门至精通(基础、部署、理论、SQL、函数、运算以及性…
hive--字符串连接函数concat(),concat_ws()
一、字符串连接函数:concat 功能:将多个字符串连接成一个字符串
语法: concat(string A, string B…)
返回值: string
说明:返回输入字符串连接后的结果,支持任意个输入字符串
举例: hive> select concat(abc, …
Hive2.1.0集成Tez
[img]http://note.youdao.com/yws/public/resource/344cd03f173c19ea03136b36d01a5f91/xmlnote/DA0FB4CF4175453FB7973BC09572A370/25149[/img]#### Tez是什么?Tez是Hontonworks开源的支持DAG作业的计算框架,它可以将多个有依赖的作业转换为一个作业从而…
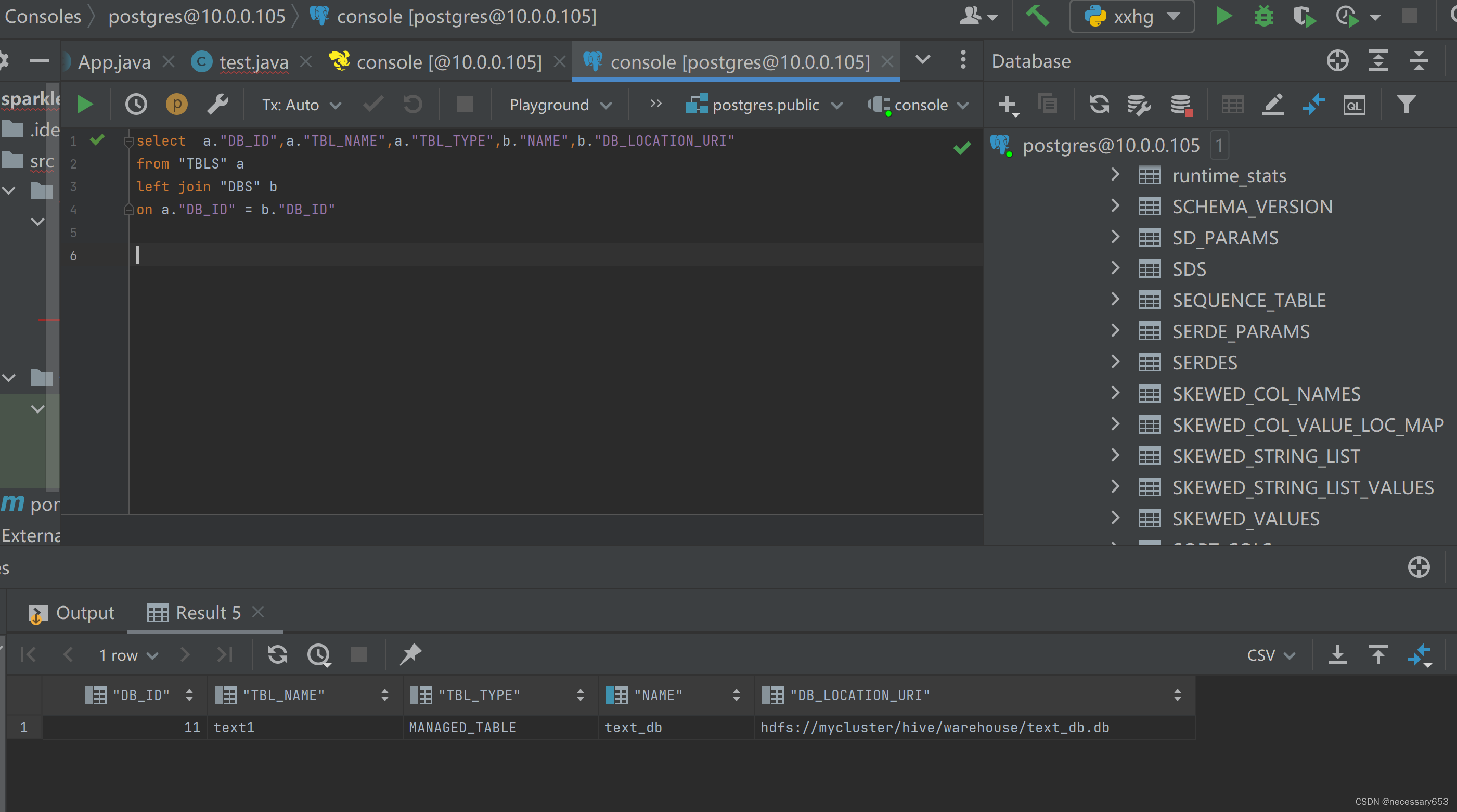
hive中spark SQL做算子引擎,PG作为MetaDatabase
简介
hive架构原理 1.客户端可以采用jdbc的方式访问hive
2.客户端将编写好的HQL语句提交,经过SQL解析器,编译器,优化器,执行器执行任务。hive的存算都依赖于hadoop框架,所依赖的真实数据存放在hdfs中,解析…
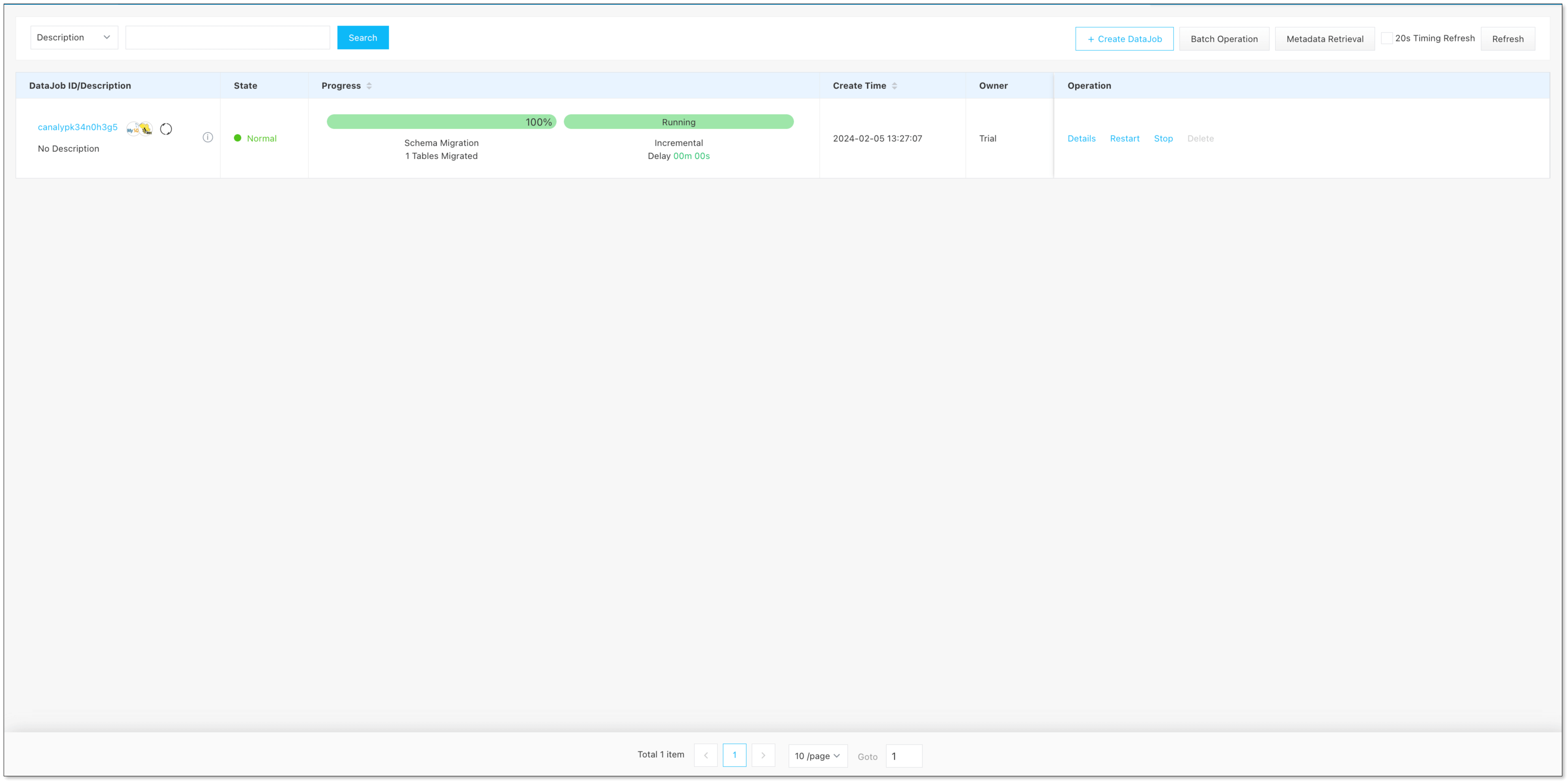
CloudCanal x Hive 构建高效的实时数仓
简述
CloudCanal 最近对于全周期数据流动进行了初步探索,打通了Hive 目标端的实时同步,为实时数仓的构建提供了支持,这篇文章简要做下分享。
基于临时表的增量合并方式基于 HDFS 文件写入方式临时表统一 Schema任务级的临时表
基于临时表的…
Hive SQL 开发指南(三)优化及常见异常
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指…
Hive中如何快速的复制一张分区表(包括数据)
转载网址:http://lxw1234.com/archives/2015/09/484.htm 我自己的实际操作,遇到了一些问题。 事先已经创建好了一张表t421,其表结构为:
hive> desc formatted t451;
OK
# col_name data_type co…

HIVE SQL 编程实操
1.需求
根据一下三张表完成对应的查询需求
表1:hive_sql_test1.t_user 观众表共6000条数据 表2:hive_sql_test1.t_movie 电影表共3000条数据 表3:hive_sql_test1.t_rating 影评表100万条数据 查询1:展示电影ID为2116这部电影…

大数据--数据仓库--数据仓库分层总结
一:数仓分层(标准五层) 电商数仓建设:采用flume,kafka导入日志数据,采用sqoop导入业务数据。接着进行数仓分层建模。
ods层: 保持数据原貌,不做任何修改,起到数据备份作…
Hive窗口函数语法规则、窗口聚合函数、窗口表达式、窗口排序函数 - ROW NUMBER 、口排序函数 - NTILE、窗口分析函数
Hive窗口函数 文章目录Hive窗口函数语法规则窗口聚合函数窗口表达式窗口排序函数 - ROW NUMBER窗口排序函数 - NTILE窗口分析函数窗口函数也叫开窗函数、OLAP函数其最大特点:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。如果函数具有OVER子句&a…
Hive分组排序取topN的sql查询示例
Hive分组排序取topN的sql查询示例 要在Hive中实现分组排序并取每组的前N条记录,可以使用 ROW_NUMBER() 窗口函数结合 PARTITION BY 和 ORDER BY 子句。 以下是一个示例SQL查询,用于选择每个部门中工资最高的前3名员工:
SELECT department, e…
HIVE 第五章 查询
查询语句 查询的一些例子: 1.query hive> SELECT name, subordinates[0] FROM employees; John Doe Mary Smith Mary Smith Bill King Todd Jones NULL 2.expression hive> SELECT upper(name), salary, deductions["Federal Taxes"], round(salary…

2.Hive基础—Hive 元数据配置到 MySQL、使用 (元数据服务) 和 (JDBC) 的方式访问 Hive
本文目录如下:2.5 Hive 元数据配置到 MySQL2.5.1 拷贝 Jar 包2.5.2 配置 Metastore 到 MySQL2.6 使用元数据服务的方式访问 Hive2.7 使用 JDBC 方式访问 Hive2.7.1 修改配置文件: hive-site.xml2.7.2 启动 hiveserver2(需要等待一会)2.7.3 启动 beeline 客户端2.7.4…
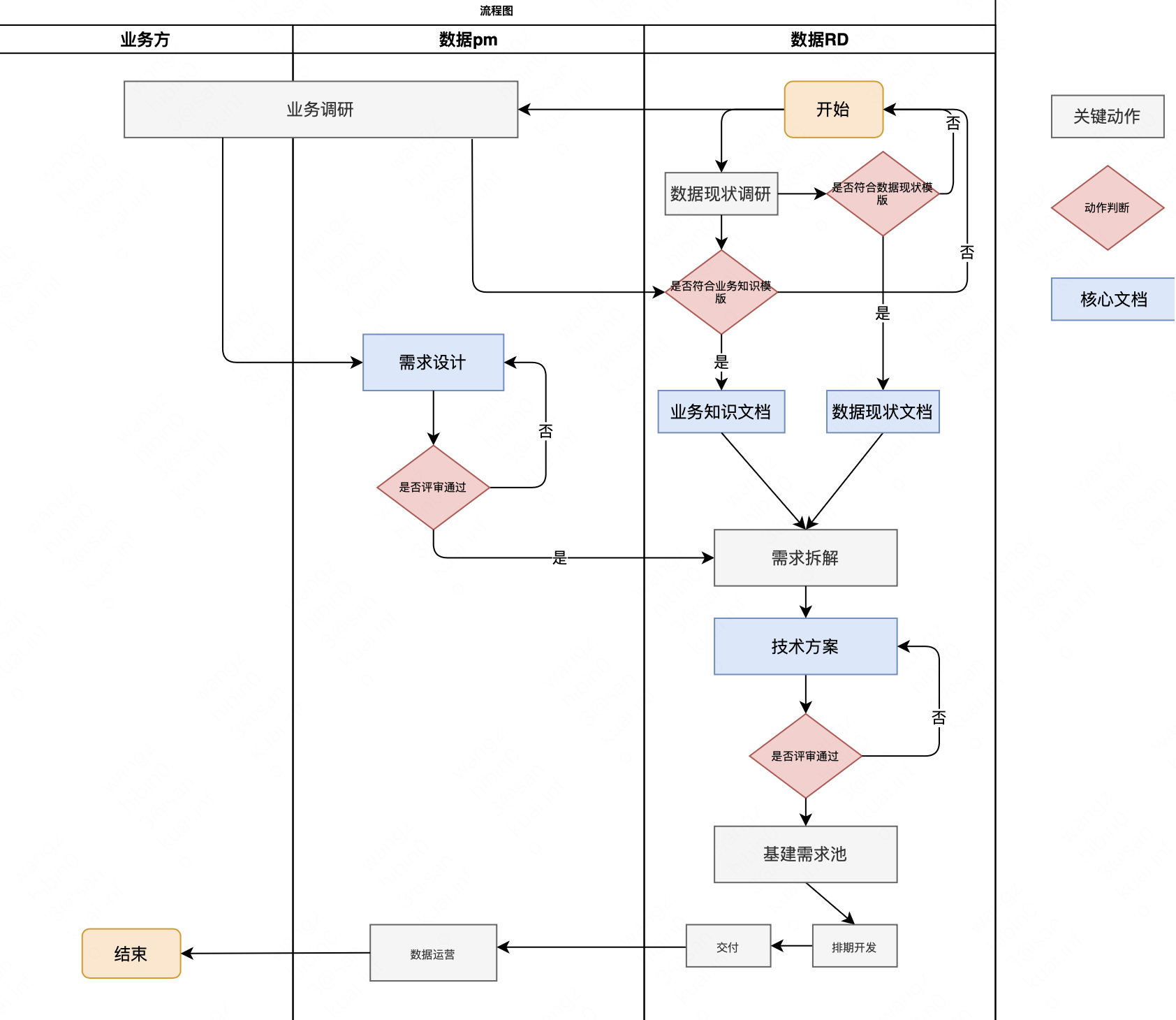
维度建模基本流程总结
一、维度建模基本流程图数据RD进行业务调研和数据现状调研,产出符合相关模版规范的业务知识文档和数据现状文档。数据PM也会调研相关业务产出需求设计文档,三方参与需求评审,评审通过后基建数据RD进行需求拆解,产出技术方案&#…
![[RoarCTF 2019]Easy Java](https://img-blog.csdnimg.cn/direct/eb2d3f64006c4636a5a9ecdd4e329859.png)
[RoarCTF 2019]Easy Java
🍬 博主介绍👨🎓 博主介绍:大家好,我是 hacker-routing ,很高兴认识大家~
✨主攻领域:【渗透领域】【应急响应】 【Java、PHP】 【VulnHub靶场复现】【面试分析】
🎉点赞➕评论➕收…
oracle12C的概念及安装和卸
一. 数据库的引入
以前将数据用变量、数组、对象存在内存,而内存只能短暂存储数据。如果我们想长久存数据用文件将数据存在磁盘上,不方便存取和管理数据,因此可以使用数据库来存数据。
二. 数据库基础概念
2.1 数据库(database,简称DB)
以…

在Hive/Spark上运行执行TPC-DS基准测试 (ORC和TEXT格式)
目前,在Hive/Spark上运行TPC-DS Benchmark主要是通过早期由Hortonworks维护的一个项目:hive-testbench 来完成的。本文我们以该项目为基础介绍一下具体的操作步骤。不过,该项目仅支持生成ORC和TEXT格式的数据,如果需要Parquet格式,请参考此文《在Hive/Spark上执行TPC-DS基…
一百五十二、Kettle——Kettle9.3.0本地连接Hive3.1.2(踩坑,亲测有效,附截图)
一、目的
由于先前使用的kettle8.2版本在Linux上安装后,创建共享资源库点击connect时页面为空,后来采用如下方法,在/opt/install/data-integration/ui/menubar.xul文件里添加如下代码
<menuitem id"file-openZiyuanku" label&…
大数据校招学员实习面试分享
本文实习面试总结来自一位非科班(机械专业)出身的在校生。
作为一个大数据领域的校招实习生,我在这里想分享一下我的经验和教训,希望对大家有所帮助。
1 简历投递准备
在准备简历时,首先需要准确地把握自己的技能和…
大数据bug-sqoop(二:sqoop同步mysql数据到hive进行字段限制。)
一:sqoop脚本解析。
#!/bin/sh
mysqlHost$1
mysqlUserName$2
mysqlUserPass$3
mysqlDbName$4
sql$5
split$6
target$7
hiveDbName$8
hiveTbName$9
partFieldName${10}
inputDate${11}echo ${mysqlHost}
echo ${mysqlUserName}
echo ${mysqlUserPass}
ec…
hive中split函数相关总结
目录 split函数示例实战注意事项 split 函数一直再用,居然发现没有总结,遂补充一下;
split函数
在Hive中,split函数用于将一个字符串根据指定的分隔符进行分割,并返回一个数组。它的语法如下:
split(str…
二百二十八、Hive——HQL报错:删除HDFS中的Hive数据文件导致Xshell连接MySQL异常和HQL查询异常
一、目的
在删除HDFS中Hive目录下的数据文件后,导致HQL查询异常,以及XShell连接MySQL出现异常
二、问题
(一)HQL查询问题
SQL语句在增加group by之后查询无数据,没有group by则查询有数据
而且SQL语句无法动态加载…
[hive面试真题]-基础理论篇
hive的工作流程 hive中分区表,分桶表 工作中hive分区表的应用示例 发现hive分区中的数据不对怎么处理 hive出现code 1 2 3 什么原因 ,怎么处理 工作中hive常见的文件格式 .压缩格式 工作时常用的hive函数 谈谈对窗口函数的理解 hive中如果出现数据倾斜 ,怎么发现 ,怎么…
安装CDH平台的服务器磁盘满了,磁盘清理过程记录
1.使用hdfs命令查看哪个文件占用最大
hdfs dfs -du -h /tmp
2.我的服务器上显示/tmp/hive/hive文件夹下的,一串字符串命名的文件特别大几乎把磁盘占满了
网上查到/tmp文件是临时文件,由于hiveserver2任务运行异常导致缓存未删除,正常情况下…
Hive安装教程-Hadoop集成Hive
文章目录 前言一、安装准备1. 安装条件2. 安装jdk3. 安装MySQL4. 安装Hadoop 二、安装Hive1. 下载并解压Hive2. 设置环境变量3. 修改配置文件3. 创建hive数据库4. 下载MySQL驱动5. 初始化hive数据库6. 进入Hive命令行界面7. 设置允许远程访问 总结 前言
本文将介绍安装和配置H…

前端页面访问后台hiveserver2,阶段性报错
1、运行环境 Windows11下安装VMware,VMware下安装CentOS7 Linux系统,三台虚拟机集群部署hadoop,安装hive; 在Linux下安装Eclipse,创建maven工程,使用hive-jdbc-2.3.2访问hiveserver2
2、在windows11下&…
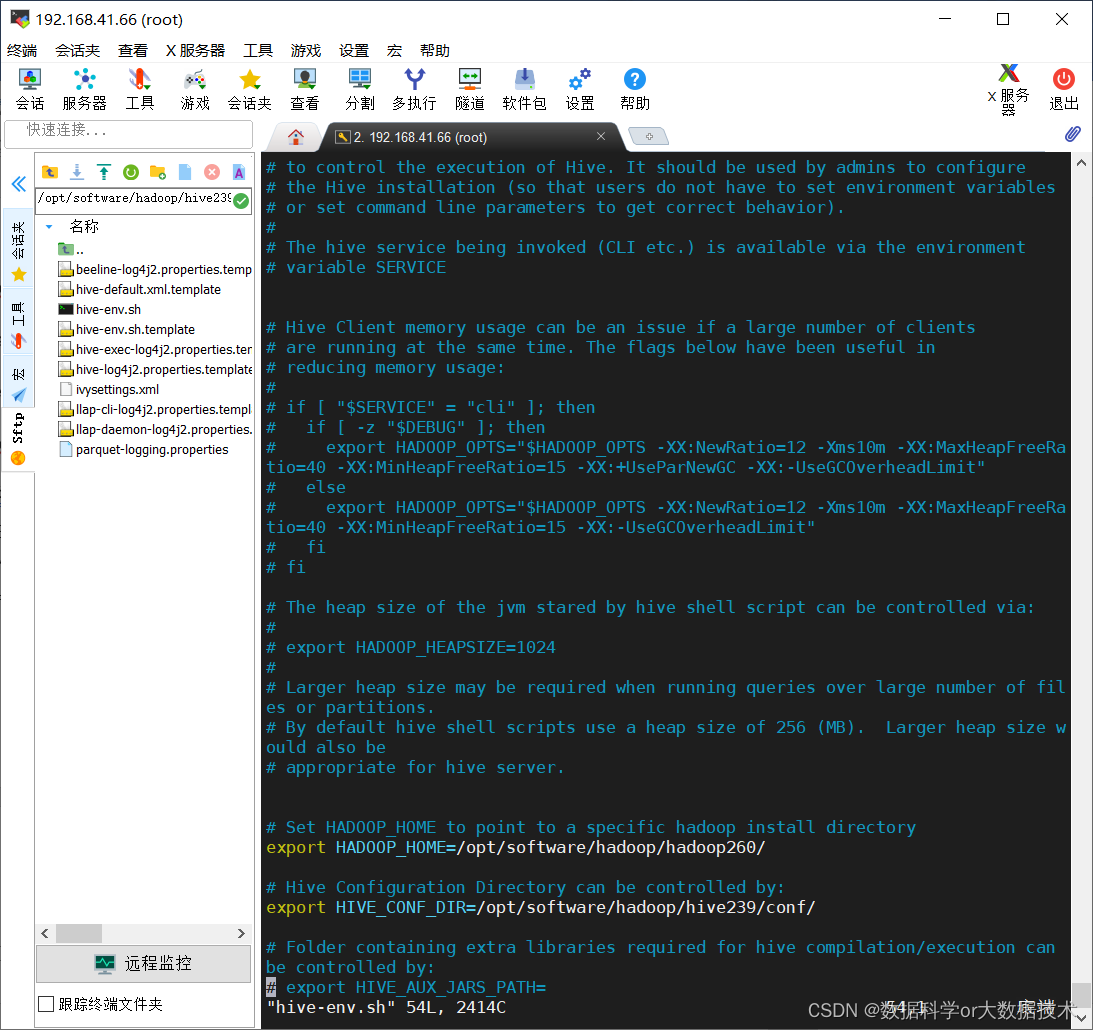
Hadoop 3:YARN
YARN简介
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器。 YARN是一个【通用资源管理系统和调度平台】,可为上层应用提供统一的资源管理和调度。 它的引入为集群在利用率、…
hive集成hbase Bytes.toByte处理字段 隐射为null乱码 加#b为0问题
解决hive集成hbase Bytes.toByte处理字段 隐射为null乱码 为0问题
错误例子(一)
create external table bigdata_student(id string,name string,age int
)stored by org.apache.hadoop.hive.hbase.HBaseStorageHandler
with SERDEPROPERTIES ("h…
leecode 数据库:584. 寻找用户推荐人
数据导入:
Create table If Not Exists Customer (id int, name varchar(25), referee_id int);
Truncate table Customer;
insert into Customer (id, name, referee_id) values (1, Will, None);
insert into Customer (id, name, referee_id) values (2, Jane, …
SQL常用的内置函数
replace() replace(str,‘a’,‘b’) 将字符串str 中的a字符串替换为b。 regexp_replace() regexp_replace(str,‘正则表达式’,b) 将字符串str中正则匹配的地方替换为b。 translate() translate(str,‘str1’,‘str2’) 对str字符串和str1字符串进行比对,字符相同的…

Hive on Spark调优(大数据技术8)
第8章 任务并行度优化 8.1 优化说明 对于一个分布式的计算任务而言,设置一个合适的并行度十分重要。在Hive中,无论其计算引擎是什么,所有的计算任务都可分为Map阶段和Reduce阶段。所以并行度的调整,也可从上述两个方面进行调整。 …
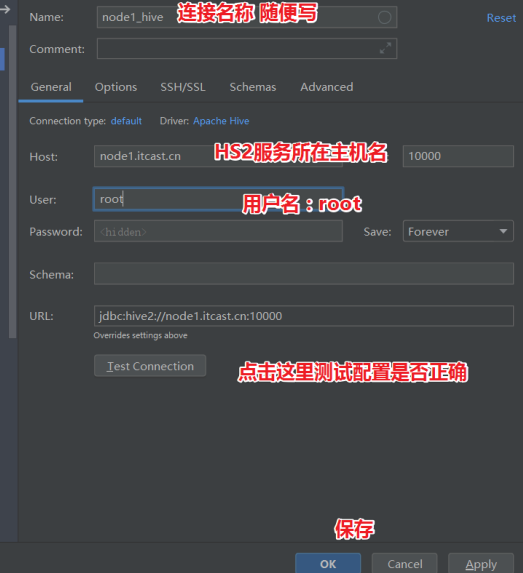
【Hadoop】三、数据仓库基础与Apache Hive入门
文章目录 三、数据仓库基础与Apache Hive入门1、数据仓库基本概念1.1、数据仓库概念1.2、场景案例:数据仓库为何而来1.3、数据仓库主要特征1.4、数据仓库主流开发语言--SQL 2、Apache Hive入门2.1、Apache Hive概述2.2、场景设计:如何模拟实现Hive功能2.…

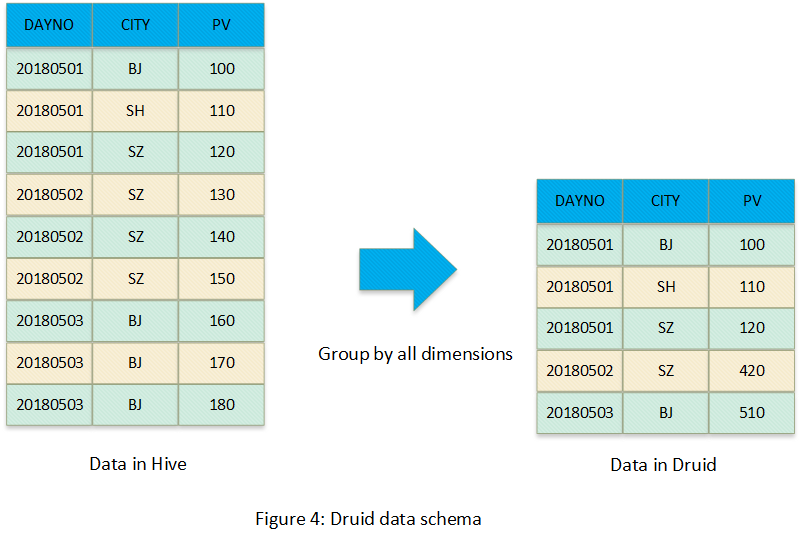
大数据(三)大数据技术栈发展史
-系列目录- 大数据(一)背景和概念 大数据(二)大数据架构发展史 大数据(三)大数据技术栈发展史 前两章,我们分析了大数据相关的概念和发展史,本节我们就讲一讲具体的大数据领域的常见技术栈发展史。对主流技术栈有一个初步的认知。 一、总览 大数据技术栈…
Datax ftp写入hive
这是一个巨大的坑,网上对这块的完整描述真的很少,新手真的会很迷茫!!!
插件
选择插件
reader插件选择:ftpread
write插件选择:hdfswrite
参数配置
reader参数
"parameter": {/…
Hive Spark Flink 调优
Hive(from -> on -> join -> where -> group by -> having -> select -> order by -> limit)Spark(Master,Driver,TaskManager)Flink语法优化 1. 列裁剪(只选择需要的列…
一百二十、Kettle——用kettle把Hive数据同步到ClickHouse
一、目标
用kettle把hive数据同步到clickhouse,简单运行、直接全量导入数据
工具版本:kettle:8.2 Hive:3.1.2 ClickHouse21.9.5.16
二、前提
(一)kettle连上hive (二)kettle连上cli…
Apache Atlas高级搜索语法示例
from hive_table;hive_table from hive_table where name xxx or name yyy from hive_table where name ["xxx", "yyy"] from hive_table where name LIKE *_xxx hive_db where name like "???dm?*" hive_column where table.name …
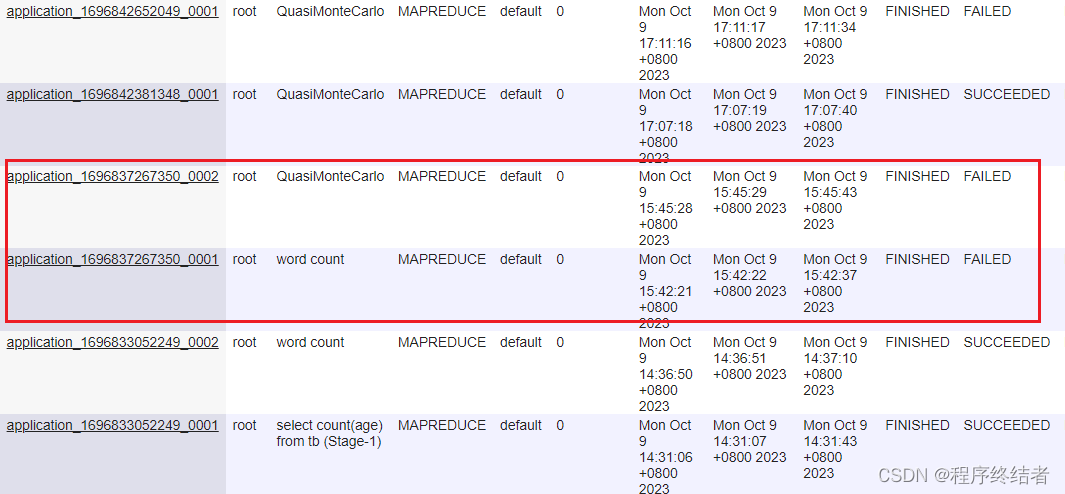
Hadoop-2.5.2平台环境搭建遇到的问题
文章目录 一、集群环境二、MySQL2.1 MySQL初始化失败2.2 MySQL启动报错2.3 启动时报不能打开日志错2.4 mysql启动时pid报错 二、Hive2.1 mr shuffle不存在2.1.2 查看yarn任务:2.1.3 问题描述:2.1.4 参考文档 一、集群环境
java-1.8.0-openjdk-1.8.0.181…
kyuubi的查询遇到的问题NoneType‘ object has no attribute ‘_getitem_‘
对一个空的查询结果进行索引操作:如果你执行了一个查询语句,但是返回的结果为空,那么在尝试对结果进行索引访问时就会触发此错误。在进行索引操作之前,应该先检查查询的结果是否为空,以避免此错误。
还有可能是cpu过高…
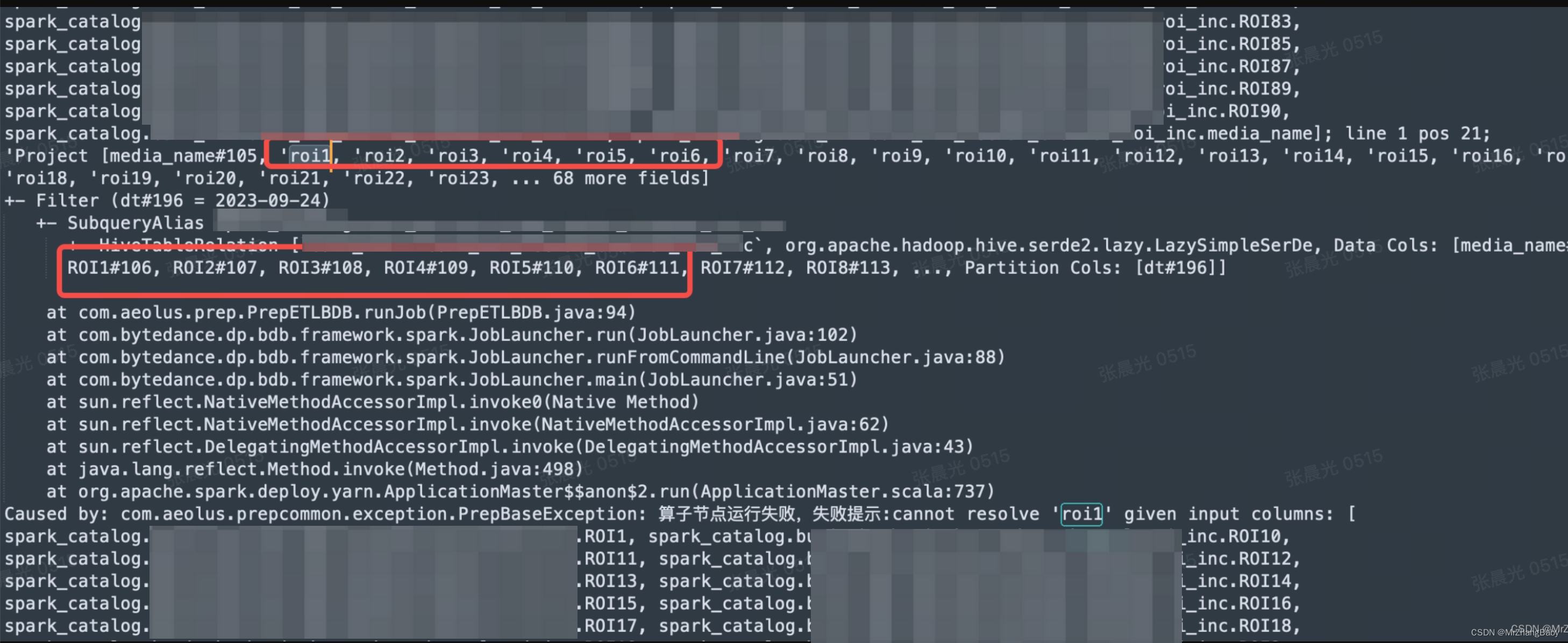
spark读取hive表字段,区分大小写问题
背景
spark任务读取hive表,查询字段为小写,但Hive表字段为大写,无法读取数据
问题错误: 如何解决呢? In version 2.3 and earlier, when reading from a Parquet data source table, Spark always returns null for any column …

大数据毕业设计选题推荐-污水处理大数据平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…
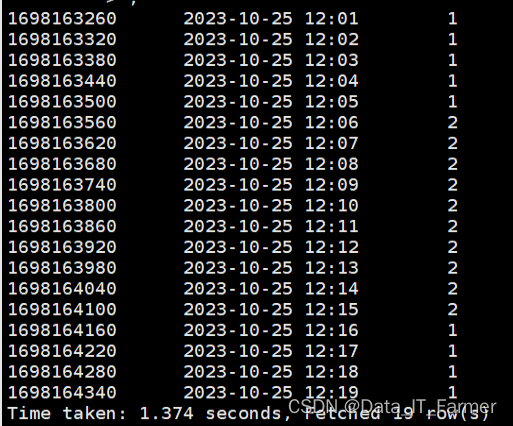
统计分钟级别的视频在线用户数+列炸裂+repeat函数
统计分钟级别的视频在线用户数
1、原始数据如下: uid vid starttime endtime select aa as uid,v00l as vid,2023-10-25 12:00 as starttime,2023-10-2512:15 as endtime union select bb as uid,v002 as vid,2023-10-25 12:05 as starttime,2023-10-25 12:19 …
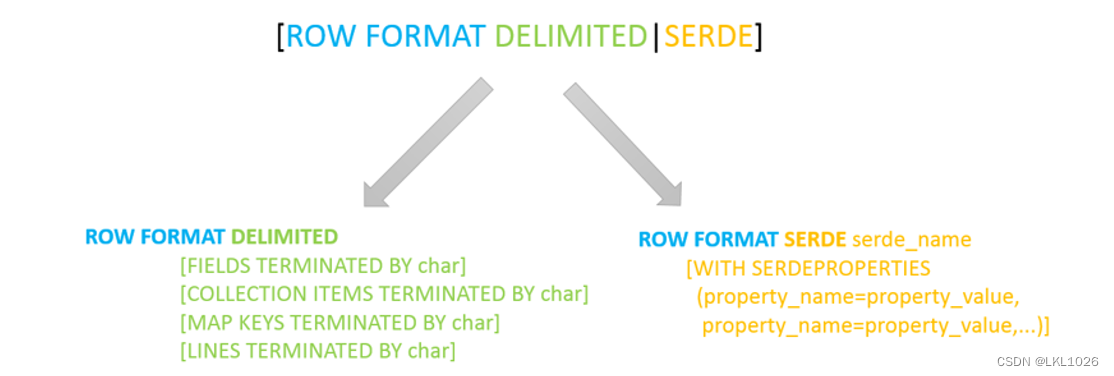
【Python大数据笔记_day07_hive中的分区表、分桶表以及一些特殊类型】
分区表 分区表的特点/好处:需要产生分区目录,查询的时候使用分区字段筛选数据,避免全表扫描从而提升查询效率
效率上注意:如果分区表在查询的时候呀没有使用分区字段去筛选数据,效率不变
分区字段名注意:分区字段名不能和原有的字段名重复,因为分区字段名要作为字段拼接到表后…
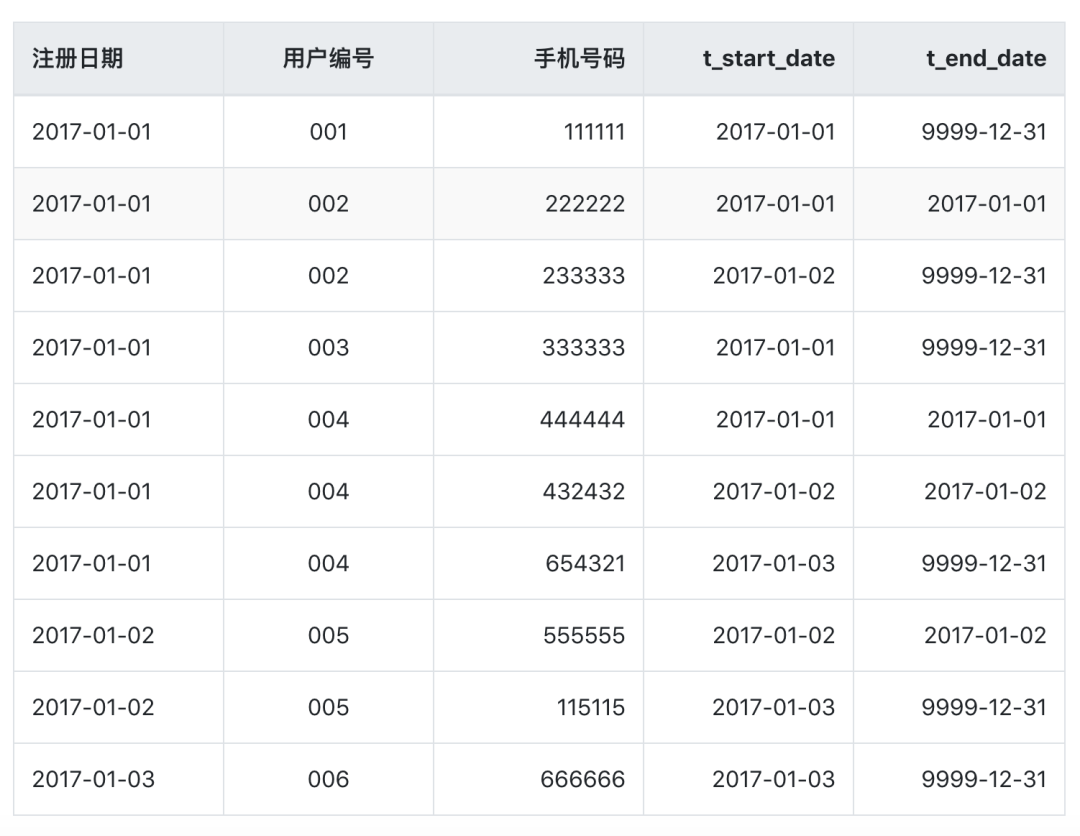
详解数据仓库之拉链表(原理、设计以及在Hive中的实现)
最近发现一本好书,读完感觉讲的非常好,首先安利给大家,国内第一本系统讲解数据血缘的书!点赞!近几天也会安排朋友圈点赞赠书活动(ง•̀_•́)ง 0x00 前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包…

Python-Python高阶技巧:HTTP协议、静态Web服务器程序开发、循环接收客户端的连接请求
版本说明
当前版本号[20231114]。
版本修改说明20231114初版
目录 文章目录 版本说明目录HTTP协议1、网址1.1 网址的概念1.2 URL的组成1.3 知识要点 2、HTTP协议的介绍2.1 HTTP协议的概念及作用2.2 HTTP协议的概念及作用2.3 浏览器访问Web服务器的过程 3、HTTP请求报文3.1 H…
2023.11.16-hive sql高阶函数lateral view,与行转列,列转行
目录 0.lateral view简介
1.行转列 需求1:
需求2:
2.列转行
解题思路: 0.lateral view简介 hive函数 lateral view 主要功能是将原本汇总在一条(行)的数据拆分成多条(行)成虚拟表,再与原表进行笛卡尔积,…
二百零二、Hive——Hive解析JSON字段(单个字段与json数组)
一、目的
用Flume采集Kafka写入到Hive的ODS层在HDFS路径下的JSON数据,需要在DWD层进行解析并清洗
(一)Hive的ODS层建静态分区外部表
create external table if not exists ods_queue(queue_json string
)
comment 静态排队数据表——静…

hive数仓-数据的质量管理
版本20231116 要理解数据的质量管理,应具备hive数据仓库的相关知识 文章目录 1.理解什么是数据的质量管理:2.数据质量管理的规划数据质量标准的分类 3.数据质量管理解决方案1.ods层的数据质量校验1)首先在hive上建立一个仓库,添加…
数据库 Bags 概念和操作
1. 概念
1.1 Set
Set 是一个没有重复数据的集合。Set 操作的参与方和结果里都没有重复元素。
1.2 Bags
Bags 是可以有重复数据的集合。数据库中操作一般是 Bag 操作。
2 Bags 操作
2.1 Select
C1C2C3125346127128
select C1, C2 的结果
C1C212341212
2.2 UNION ALL
…
hive实战使用文档(一)之hive on hbase知多少
hive对库表的常用命令
查看数据库 :
show database;切换数据库:
use database_name;查看所有的表:
show tables;查询表结构:
desc table_name;创建数据库:
create database database_name;删除数据库
drop database if exists database_name;
dro…
Linux虚拟机安装hive-0.13.1-cdh5.3.6
下载
cdh5.3.6 密码:bqgj
【cdh】 链接: https://pan.baidu.com/s/1ASwsAS2eRrV7WpymuQS3-w 密码: bqgj
官方下载地址
配置
在虚拟机的 /opt 下创建 cdh5.3.6 文件夹,并将hive-0.13.1-cdh5.3.6上传到 /opt/cdh5.3.6 下,然后进入 /hive-0.13.1-cdh5.…

Hive 之 函数 01-常用查询函数(一)
欢迎大家扫码关注我的微信公众号: Hive 之 函数 01-常用查询函数(一)一、 空字段赋值二、 时间类2.1 date_format: 格式化时间2.2 date_add: 时间跟天数相加2.3 date_sub: 时间跟天数相减(跟 d…
Hive操作报错总结——不断更新
本文会收集一些作者在操作Hive的时候遇见的一些错误和解决方法,也有一些bug不知道为什么要这么解决,探索中… hive> create table mfd_interest_data(date bigint,interest_rate double,year_date double) row format delimited fields terminated by…

代码思路分享 计算机毕业设计Python+Hadoop+Spark+Hive音乐可视化 音乐数据分析 音乐大数据 音乐推荐系统 音乐数据仓库 大数据毕业设计 大数据毕设
涉及技术
hadoop
hive
azkaban
python爬虫
hue
sqoop
mysql
运行截图

代码思路分享 计算机毕业设计Python+Hadoop+Spark+Hive旅游可视化 旅游数据分析 数据仓库 旅游推荐系统 旅游大数据 大数据毕业设计 大数据毕设
涉及技术
hadoop
hive
azkaban
python爬虫
hue
sqoop
mysql
运行截图

数据仓库项目分享思路 计算机毕业设计Python+Hadoop+Spark+Hive招聘可视化 招聘数据分析 数据仓库 招聘推荐系统 招聘大数据 大数据毕业设计 大数据毕设
涉及技术
hadoop
hive
azkaban
python爬虫
hue
sqoop
mysql
运行截图

数据仓库Hive——函数与Hive调优
文章目录五、函数1.系统自带的函数1.1 查看系统自带的函数1.2 显示某一个自带函数的用法1.3 详细显示自带的函数的用法2.自定义函数3.自定义UDF函数开发实例(toLowerCase())3.1 环境搭建3.2 书写代码,定义一个传入的参数3.3 打包,带入测试环境3.4 创建临…

数据仓库Hive——查询(下)
文章目录四、查询4.Join语句4.1 等值Join4.2 表的别名4.3 内连接4.4 左外连4.5 右外连4.6 满外连5.排序5.1 全局排序(Order By)5.2 按照自定义别名排序5.3 多个列排序5.4 每个MapReduce内部排序(Sort By)5.5 分区排序(Distribute by)5.6 Cluster By6.分桶及抽样查询6.1分桶表数…
7.Hive性能优化及Hive3新特性
1.Hive表设计优化
分区表优化查询速度分桶表优化join速度索引优化(在Hive3后移除,了解即可)
2.Hive表数据优化
2.1 文件格式
概述
Hive数据存储的本质市HDFS,所有数据读写都基于HDFS的文件来实现为了提高对HDFS文件读写的性能…
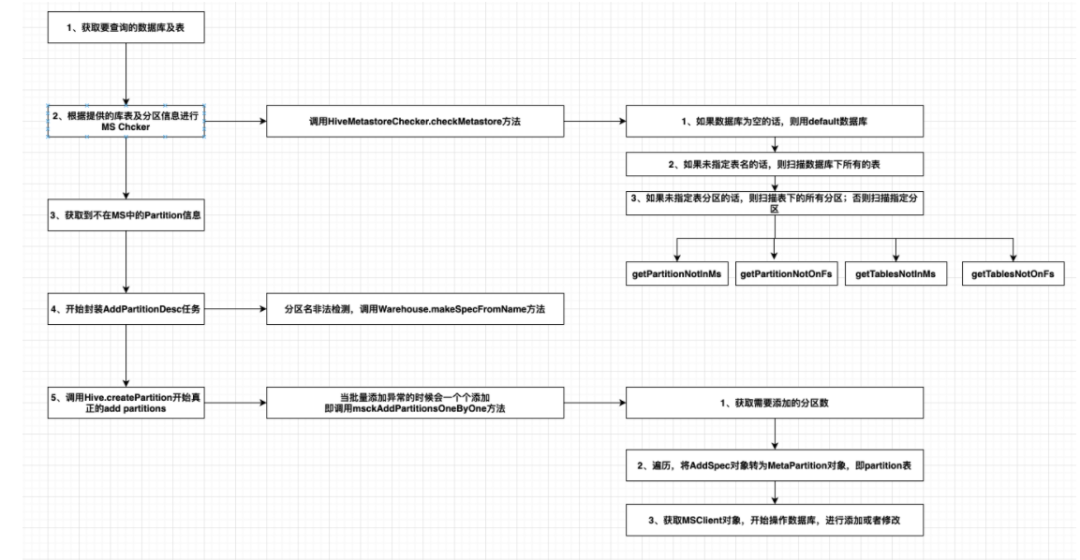
Hive专题-数据修复篇
相信使用过Hive的同学,一定会知道msck repair的用途(元数据修复)。那么不知道大家有没有好奇过Hive底层是怎么实现该机制的呢?这里带大家简单了解一下。
一、基本解释
在HMS(Hive MetaStore)中存储着每个表的分区列表࿰…
【hive基础】hive常见操作速查
文章目录 一. hive变量操作1. 查看当前hive配置信息2. 设置变量3. 修改变量4. 进入hive终端重新加载配置 二. 执行hive sql三. 启动hive 一. hive变量操作
1. 查看当前hive配置信息
# 查看当前所有配置信息
hive > set ;# 查看某一项配置信息
hive >set hive.metastore…
Sqoop基础理论与常用命令详解(超详细)
文章目录 前言一、Sqoop概述1. Sqoop简介2. Sqoop架构(1) Sqoop Client(2) Sqoop Server(3) Connector(4) Metastore(5) Hadoop/HDFS 3. Sqoop特点(1) 简化数据传输(2) 高效处理大数据量(3) 灵活的数据格式支持(4) 丰富的连接器支持(5) 数据压缩和加密(6) 与Hadoop生态系统集成…

2023.11.17-hive调优的常见方式
目录
0.设置hive参数
1.数据压缩
2.hive数据存储格式
3.fetch抓取策略
4.本地模式
5.join优化操作
6.SQL优化(列裁剪,分区裁剪,map端聚合,count(distinct),笛卡尔积)
6.1 列裁剪:
6.2 分区裁剪:
6.3 map端聚合(group by):
6.4 count(distinct):
6.5 笛卡尔积:
7…
【Python大数据笔记_day10_Hive调优及Hadoop进阶】
hive调优 hive官方配置url: Configuration Properties - Apache Hive - Apache Software Foundation hive命令和参数配置 hive参数配置的意义: 开发Hive应用/调优时,不可避免地需要设定Hive的参数。设定Hive的参数可以调优HQL代码的执行效率,或帮助定位问…
2023.11.16 hivesql高阶函数之开窗函数
目录 1.开窗函数的定义
2.数据准备
3.开窗函数之排序 需求:用三种排序方法查询学生的语文成绩排名,并降序显示 4.开窗函数分组
需求:按照科目来分类,使用三种排序方式来排序学生的成绩 5.聚合函数与分组配合使用
6.聚合函数同时和分组以及排序关键字配合使用
--需求1&…
Hive客户端hive与beeline的区别
hive与beeline简介 1、背景2、hive3、beeline4、hive与beeline的关系 1、背景 Hive的hive与beeline命令都可以为客户端提供Hive的控制台连接。两者之间有什么区别或联系吗?
Hive-cli(hive)是Hive连接hiveserver2的命令行工具,从Hive出生就一直存在&…
Hive默认分割符、存储格式与数据压缩
目录 1、Hive默认分割符2、Hive存储格式3、Hive数据压缩 1、Hive默认分割符 Hive创建表时指定的行受限(ROW FORMAT)配置标准HQL为:
...
ROW FORMAT DELIMITED
FIELDS TERMINATED BY \u0001
COLLECTION ITEMS TERMINATED BY ,
MAP KEYS TERMI…
Hive安装配置 - 本地模式
文章目录 一、Hive运行模式二、安装配置本地模式Hive(一)安装配置MySQL1、删除系统自带的MariaDB2、上传MySQL组件到虚拟机3、在主节点上安装MySQL组件4、在主节点上配置MySQL(1)查看MySQL服务状态(2)查看M…
拉链表-spark版本
采用spark实现的拉链表
拉链表初始化
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.lit/*** 拉链表初始化*/
object table_zip_initial {val lastDay "9999-12-31"def main(args: Array[String]): Unit {var table_base &q…
hadoop、hive、DBeaver的环境搭建及使用
本文主要介绍hadoop、hive的结构及使用,具体的操作步骤见最后的附件;
hadoop提供大数据的存储、资源调度、计算,分为三个模块:HDFS、YRAN、MapReduce HDFS提供数据的分布式存储,分为三个节点NameNode,DataNode,Second…
GZ033 大数据应用开发赛题第07套
2023年全国职业院校技能大赛 赛题第07套 赛项名称: 大数据应用开发 英文名称: Big Data Application Development 赛项组别: 高等职业教育组 赛项编号: GZ033 …
[hive] posexplode函数
在Hive SQL中,posexplode是一个用于将数组(array)拆分为多行的函数。
它返回数组中的每个元素以及其在数组中的位置(索引)作为两列输出。
这是posexplode函数的语法:
posexplode(array)其中,…

记录一次因内存不足而导致hiveserver2和namenode进程宕机的排查
背景
最近发现集群主节点总有进程宕机,定位了大半天才找到原因,分享一下
排查过程
查询hiveserver2和namenode日志,都是正常的,突然日志就不记录了,直到我重启之后又恢复工作了。 排查各种日志都是正常的࿰…

数据开发必经之路-数据倾斜
前言 数据倾斜是数据开发中最常见的问题,同时也是面试中必问的一道题。那么何为数据倾斜?什么时候会出现数据倾斜?以及如何解决呢? 何为数据倾斜:数据倾斜其本质就是数据分配不均匀,部分任务处理大量的数据…
化繁为简|中信建投基于StarRocks构建统一查询服务平台
近年来,在证券服务逐渐互联网化,以及券商牌照红利逐渐消退的行业背景下,中信建投不断加大对数字化的投入,尤其重视数据基础设施的建设,期望在客户服务、经营管理等多方面由经验依赖向数据驱动转变,从而提高…
Hive学习——单机版Hive的安装
目录
一、基本概念
(一)什么是Hive
(二)优势和特点
(三)Hive元数据管理
二、Hive环境搭建
1.自动安装脚本
2./opt/soft/hive312/conf目录下创建hive配置文件hive-site.xml
3.拷贝一个jar包到hive下面的lib目录下
4.删除hive的guava,拷贝hadoop下的guava
5…
大数据项目实战之数据仓库:用户行为采集平台——第2章 项目需求及架构设计
第2章 项目需求及架构设计
2.1 项目需求分析
1)采集平台
(1)用户行为数据采集平台搭建
(2)业务数据采集平台搭建
2)离线需求
3)实时需求
4)思考题
1、项目技术如何选型&…

Hive介绍及DDL
1.OLTP和OLAP
OLTP: 联机事务处理系统。在前台接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。关系型数据库是OLTP典型应用,如MySQL
OLTP环境开展数据分析是否可行?
为了更好的开展数据分析&#x…
探讨Hive是否转为MapReduce程序
目录 前提条件
数据准备
探讨HQL是否转为MapReduce程序执行
1.设置hive.fetch.task.conversionnone
2.设置hive.fetch.task.conversionminimal
3.设置hive.fetch.task.conversionmore 前提条件
Linux环境下安装好Hive,这里测试使用版本为:Hive2.3.…
使用 Spark 抽取 MySQL 数据到 Hive 时某列字段值出现异常(字段错位)
文章目录 源数据描述问题复现问题解析问题解决 源数据描述
在 MySQL 中建立了表 order_info ,其字段信息如下所示:
-------------------------------------------------------------------------------------------------
| Field | Type…
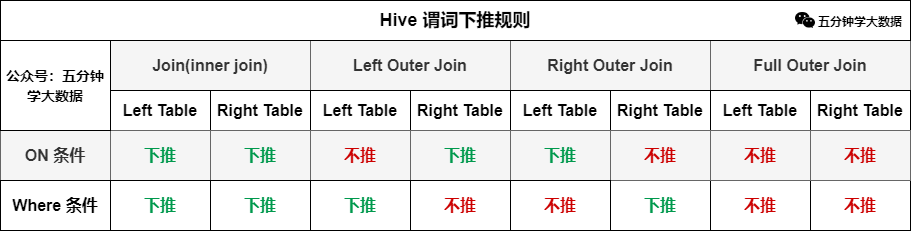
Hive参数与性能调优-V2.0
Hive作为大数据平台举足轻重的框架,以其稳定性和简单易用性也成为当前构建企业级数据仓库时使用最多的框架之一。
但是如果我们只局限于会使用Hive,而不考虑性能问题,就难搭建出一个完美的数仓,所以Hive性能调优是我们大数据从业…
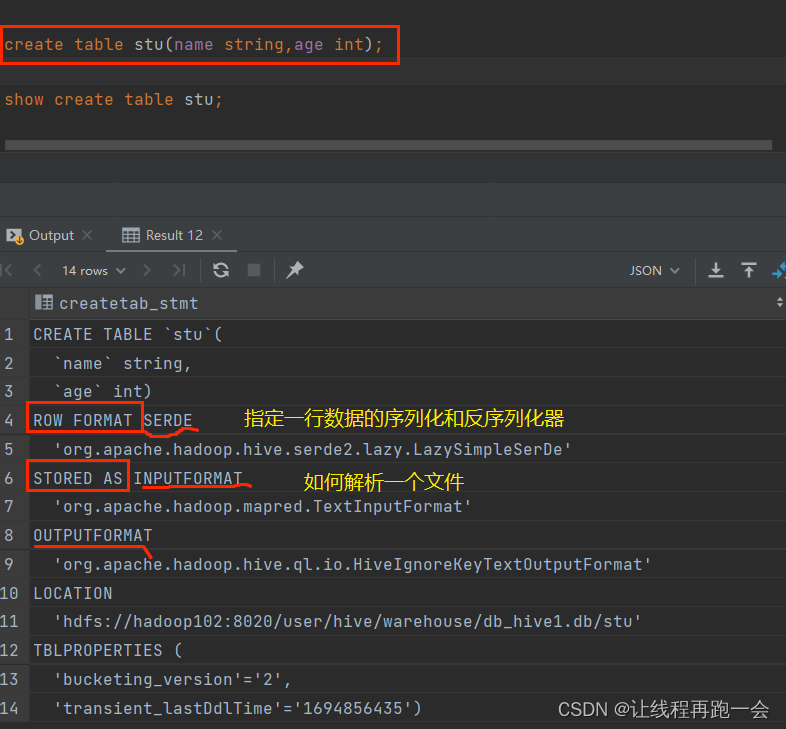
Hive【Hive(一)DDL】
前置准备 需要启动 Hadoop 集群,因为我们 Hive 是在 Hadoop 集群之上运行的。 从DataGrip 或者其他外部终端连接 Hive 需要先打开 Hive 的 metastore 进程和 hiveserver2 进程。
Hive DDL 数据定义语言
1、数据库(database)
创建数据库
c…
(三十)大数据实战——HBase集成部署安装Phoenix
前言
Phoenix 是一个开源的分布式关系型数据库查询引擎,它基于 Apache HBase构建。它提供了在 Hadoop 生态系统中使用 SQL查询和事务处理的能力。本节内容我们主要介绍一下Hbase如何集成部署安装Phoenix服务工具,并集成hive框架,能够快速、灵…
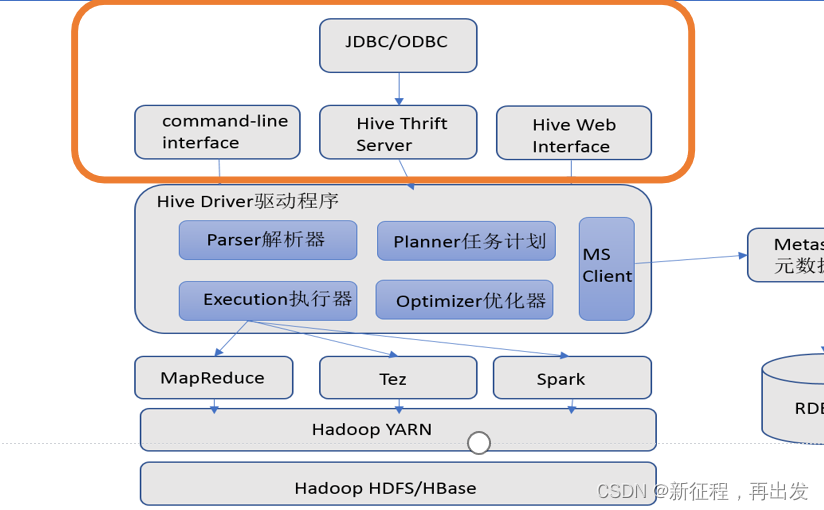
Apache Hive概述,模拟实现Hive功能,Hive基础架构
1、Apache Hive 概述
1.1、分布式SQL计算
对数据进行统计分析,SQL是目前最为方便的编程工具。
大数据体系中充斥着非常多的统计分析场景 所以,使用SQL去处理数据,在大数据中也是有极大的需求的。
MapReduce支持程序开发(Java…
大数据学习(23)-hive on mapreduce对比hive on spark
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博主哦ᾑ…
Hive csv文件导入Hive
一、如何把csv文件导入Hive
(1) 在Hive中建立与csv相对应的表
create table if not exists tmp.tmp_wenxin_20231123
(redeem_code_id string comment
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ,
STORED AS TEXTFILE;创建了一张名为tmp_wenxin_20231123的hive表&am…
HIVE SQL取整函数汇总
目录 int()round(double a)round(double a,int d)floor()ceil() int() 向零取整,即向接近零的方向取整。 int(5.6)输出:5
int(-5.6)输出:-5
round(double a) 四舍五入取整 select round(5.6)输出:6
select round(-5.6)输出&…
sqoop(DataX)-MySQL导入HIVE时间格问题
这里写自定义目录标题 问题1:测试MySQL 数据信息HIVE数据信息hive中用 parquet(orc) 列式文件格式存储 解决方法问题2:解决方法 问题1:
用公司的大数据平台(DataX)导数,已经开发上线…
保姆级连接FusionInsight MRS kerberos Hive
数新网络,让每个人享受数据的价值https://xie.infoq.cn/link?targethttps%3A%2F%2Fwww.datacyber.com%2F
概述 本文将介绍在华为云 FusionInsight MRS(Managed Relational Service)的Kerberos环境中,如何使用Java和DBeaver实现远…
Java面试题106-115
106、说一说Servlet的生命周期?
答:servlet有良好的生存期的定义,包括加载和实例化、初始化、处理请求以及服务结束。这个生存期由javax.servlet.Servlet接口的init,service和destroy方法表达。 Servlet被服务器实例化后,容器运行其init方法ÿ…
hivesql 将json格式字符串转为数组
hivesql 将json格式字符串转为数组 完整过程SQL在文末 json 格式字符串 本案例 json 字符串参考格式,请勿使用本数据 {"data": [{"province": 11,"id_card": "110182198903224674","name": "闾丘饱乾"…
day02 hive 实操练习
一、某高校图书管理系统中有如下三个数据模型:
create table book(
book_id string,
sort string,
book_name string,
writer string,
output string,
price decimal(10,2));INSERT INTO TABLE book VALUES (001,TP391,information_processing,author1,machinery_i…
二百零八、Hive——HiveSQL异常:Select查询数据正常,但SQL语句加上group by查询数据为空
一、目的
在HiveSQL的DWD层中,需要对原始数据进行去重在内的清洗,结果一开始其他数据类型的清洗工作都正常,直到碰到转向比数据。
一般的SQL查询有数据,但是加上group by以后就没数据;
一般的SQL查询有数据…
Hive进阶函数:SPACE() 一行炸裂指定行
数据一行如何转多行
假如有一张表,字段有两个,分别是name 和 number,代表含义为名字 和 名字出现的次数,现在需要把一行数据转为number行
举例: 输入: tom|3jery|4输出:…
Hive环境准备[重点学习]
1.前提启动hadoop集群 hadoop在统一虚拟机中已经配置了环境变量 启动hdfs和yarn集群
命令:start-all.sh
[rootnode1 /]# start-all.sh启动mr历史服务
命令:mapred --daemon start historyserver
[rootnode1 /]# mapred --daemon start historyserver检查服务
命令:jps
[r…
使用Sqoop将Hive数据导出到TiDB
关系型数据库与大数据平台之间的数据传输之前写过一些 使用Sqoop将数据在HDFS与MySQL互导 使用Sqoop将SQL Server视图中数据导入Hive 使用DataX将Hive与MySQL中的表互导 使用Sqoop将Hive数据导出到TiDB虽然没写过,但网上一堆写的,那为什么我要专门写一下…
sql面试题之连续登陆问题以及连续登陆问题的扩展!!!
最大连续登陆天数问题在SQL领域,不管是刚入门的小白还是工作几年的大牛给人的感觉就是比较棘手且细思极恐的问题,今天我们通过两个案例从不同角度去了解连续登陆问题以及连续登陆问题变化的场景。消除恐惧的最好办法就是面对恐惧,加油 !奥利给! 某游戏公司有两张用户登陆表…
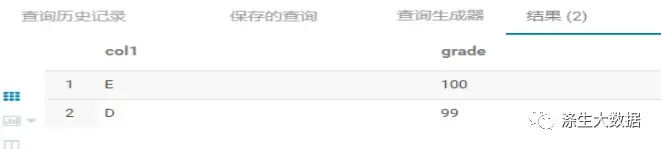
含泪整理的超全窗口函数:数据开发必备
最近在搞一些面试和课程答辩的时候,问什么是窗口函数,知道哪些窗口函数?最多的答案就是row_number、rank、dense_rank,在问一下还有其他的吗?这时同学就蒙了,还有其他的窗口函数?其实上面的回答也只是专用窗口函数&am…
![[yarn]yarn异常](https://img-blog.csdnimg.cn/85e5428f7eff4ff18014e31c02af55a6.png)
[yarn]yarn异常
一、运行一下算圆周率的测试代码,看下报错
cd /home/data_warehouse/module/hadoop-3.1.3/share/hadoop/mapreduce hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 1000 1000
后面2个数字参数的含义: 第1个1000指的是要运行1000次map任务 …

Sqoop的增量数据加载策略与示例
当使用Apache Sqoop进行数据加载时,增量数据加载策略是一个关键的话题。增量加载可以仅导入发生变化的数据,而不必每次都导入整个数据集,这可以显著提高任务的效率。本文将深入探讨Sqoop的增量数据加载策略,提供详细的示例代码&am…

Sqoop与其他数据采集工具的比较分析
比较Sqoop与其他数据采集工具是一个重要的话题,因为不同的工具在不同的情况下可能更适合。在本博客文章中,将深入比较Sqoop与其他数据采集工具,提供详细的示例代码和全面的内容,以帮助大家更好地了解它们之间的差异和优劣势。
Sq…
JavaWeb篇_08——Servlet技术以及第一个Servlet案例
Servlet技术
Web开发历史回顾
CGI
公共网关接口(Common Gateway Interface,CGI)是Web 服务器运行时外部程序的规范。
CGI缺点
以进程方式运行,对每一个客户端的请求都要启动一个进程来运行程序,导致用户数目增加时…
![[Hive] INSERT OVERWRITE DIRECTORY要注意的问题](https://img-blog.csdnimg.cn/4543ec8a5e0d476faf70a9ab57832ba8.jpeg)
[Hive] INSERT OVERWRITE DIRECTORY要注意的问题
在使用Hive的INSERT OVERWRITE语句时,需要注意以下问题:
数据覆盖:INSERT OVERWRITE语句会覆盖目标目录中的数据。因此,在执行该语句之前,请确保目标目录为空或者你希望覆盖的数据已经不再需要。数据格式:…
比较 Apache Hive 和 Spark
Hive 和 Spark 是两种非常流行且成功的用于处理大规模数据集的产品。换句话说,他们进行大数据分析。本文重点描述这两种产品的历史和各种功能。对它们的功能进行比较将说明这两种产品可以解决的各种复杂的数据处理问题。
有关该主题的更多信息:
AWS EK…
sqoop事务如何实现
场景1:如Sqoop在导出hdfs数据到Mysql时,某个字段过长导致任务失败,该错误记录之前的数据正常导入,之后的数据无法导入。如何保证错误发生后数据回滚?
场景2:如Sqoop在导出hdfs数据到Mysql时,某…
Doris Hive外表
Hive External Table of Doris 提供了 Doris 直接访问 Hive 外部表的能力,外部表省去了繁琐的数据导入工作,并借助 Doris 本身的 OLAP 的能力来解决 Hive 表的数据分析问题: 支持 Hive 数据源接入Doris支持 Doris 与 Hive 数据源中的表联合查询,进行更加复杂的分析操作1 基…

使用Sqoop的并行处理:扩展数据传输
使用Sqoop的并行处理是在大数据环境中高效传输数据的关键。它可以显著减少数据传输的时间,并充分利用集群资源。本文将深入探讨Sqoop的并行处理能力,提供详细的示例代码,以帮助大家更全面地了解和应用这一技术。
Sqoop的并行处理
在开始介绍…

毕设:《基于hive的音乐数据分析系统的设计与实现》
文章目录 环境启动一、爬取数据1.1、歌单信息1.2、每首歌前20条评论1.3、排行榜 二、搭建环境1.1、搭建JAVA1.2、配置hadoop1.3、配置Hadoop环境:YARN1.4、MYSQL1.5、HIVE(数据仓库)1.6、Sqoop(关系数据库数据迁移) 三、hadoop配置内存四、导…
业务场景中Hive解析Json常用案例
业务场景中Hive解析Json常用案例
json在线工具
json格式转换在线工具
https://tool.lu/json/format格式互转:
// 格式化可以合并整行显示
{"name":"John Doe","age":35,"email":"johnexample.com"}// 格式化…

【Hive】——安装部署
1 MetaData(元数据) 2 MetaStore (元数据服务) 3 MetaStore配置方式 3.1 内嵌模式 3.2 本地模式 3.3 远程模式 4 安装前准备 <!-- 整合hive --><property><name>hadoop.proxyuser.root.hosts</name><v…
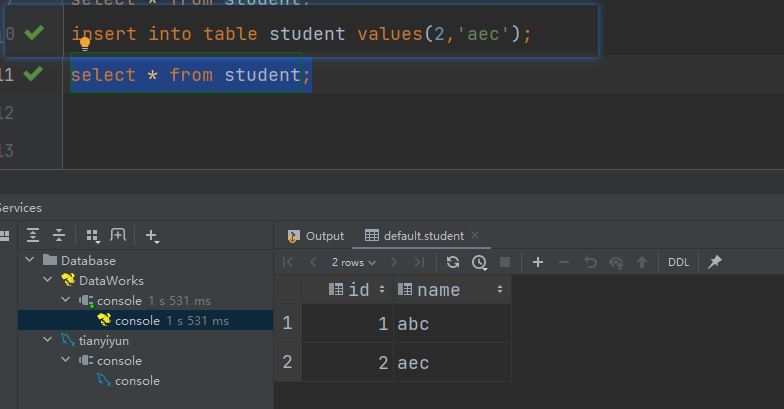
User: zhangflink is not allowed to impersonate zhangflink
使用hive2连接进行添加数据是报错:
[08S01][1] Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. User: zhangflink is not allowed to impersonate zhangflink 有些文章说需要修…
mongodb数据同步到hive
背景
用户需求: 需要将 mongodb 的数据同步到 hive 表,共 2 亿条数据,总数据量约 30G
查阅一些博客后,大致同步方法有以下几种
手动离线
对于比较小的数据,可以先通过 mongoexport 将数据导出到本地 json 文件,再将…

大数据毕业设计选题推荐-智慧消防大数据平台-Hadoop-Spark-Hive
✨作者主页:IT毕设梦工厂✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Py…
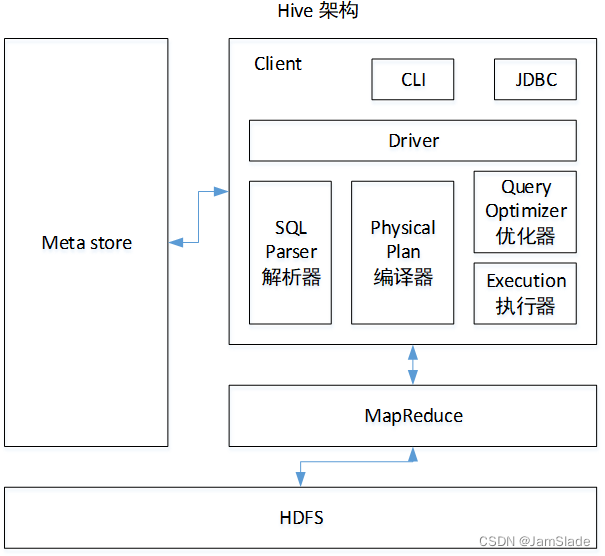
Hive 知识点八股文记录 ——(一)特性
Hive通俗的特性
结构化数据文件变为数据库表sql查询功能sql语句转化为MR运行建立在hadoop的数据仓库基础架构使用hadoop的HDFS存储文件实时性较差(应用于海量数据)存储、计算能力容易拓展(源于Hadoop)
支持这些特性的架构
CLI&…
hive/spark用法记录
1. cast()更改数据类型
cast(column_name as type)
2. get_dt_date()自定义日期操作函数(返回不带横线的日期)
select get_dt_date();–获取当前日期,返回 20170209 select get_dt_date(get_date(-2));–获取当前日期偏移,转为…
hive 语句关键词 执行的优先级
在 Hive 中编写 SQL 语句时,各个关键词(比如 SELECT、FROM、WHERE、GROUP BY、ORDER BY 等)的执行顺序对于理解和优化查询非常重要。 FROM: 首先执行。确定要查询的表或视图。 JOIN: 如果有 JOIN 操作,它紧…
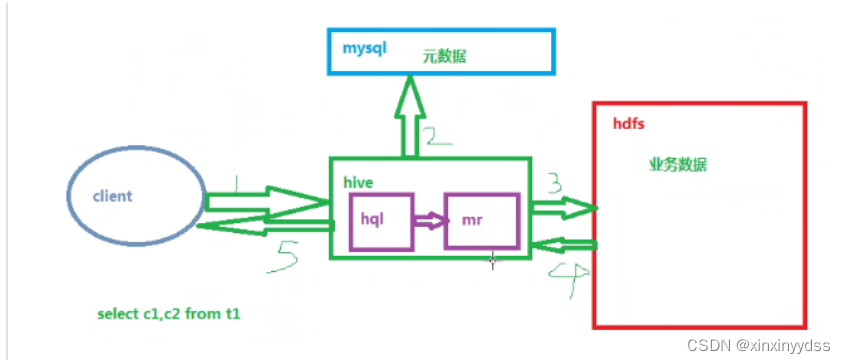
hive数据仓库工具
1、hive是一套操作数据仓库的应用工具,通过这个工具可实现mapreduce的功能 2、hive的语言是hql[hive query language] 3、官网hive.apache.org 下载hive软件包地址 Welcome! - The Apache Software Foundationhttps://archive.apache.org/ 4、hive在管理数据时分为元…
Spark读写Hive
Spark读写Hive 文章目录 Spark读写Hive(一)配置本地域名映射(二)创建Hive表(三)IDEA中编写Spark代码读取Hive数据(四)IDEA中编写Spark代码写入数据到Hive (一)…
hive聚合函数之JOIN原理及案例
1.数据准备
原始数据 创建dept.txt文件,并赋值如下内容,上传HDFS。
部门编号 部门名称 部门位置id
10 行政部 1700
20 财务部 1800
30 教学部 1900
40 销售部 1700创建emp.txt文件,并赋值如下内容,上传HDFS。
员工编号 姓名 岗…

hive客户机执行sql脚本无法显示表头
hive客户机执行sql脚本无法显示表头
临时跑数
在sql脚本前加以下语句 set hive.cli.print.headertrue;
日常跑数不想每次跑数前都执行以下
1、在home路径下创建 .hiverc 文件
vim .hiverc 2、在文件中copy下面这句话 set hive.cli.print.headertrue; 3、保存文件并退出
这…
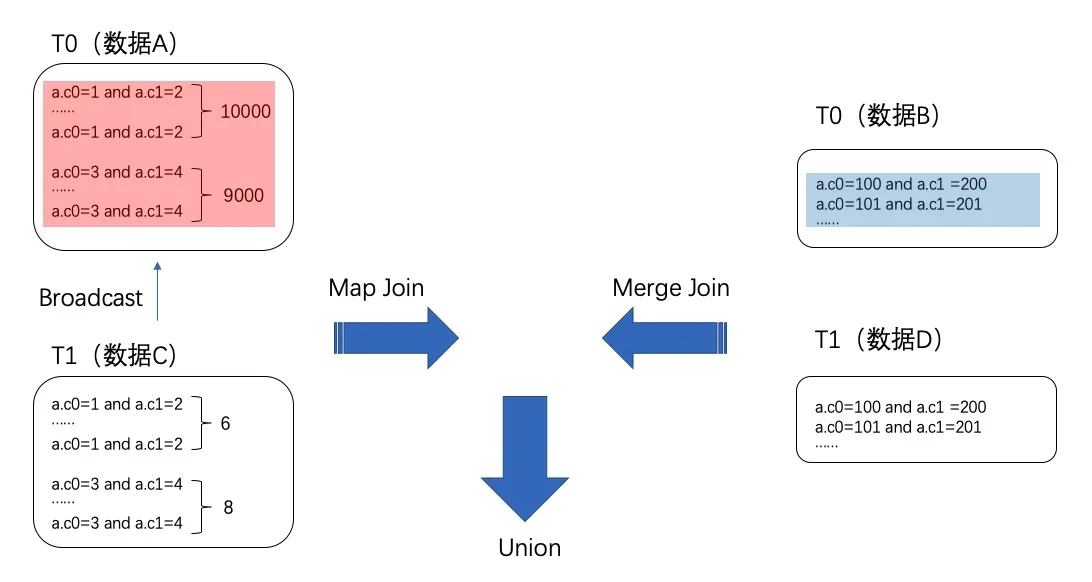
Hive 的三种join
Hive 的三种join
Merge join
reduce阶段完成join。整个过程包括Map、Shuffle和Reduce三个阶段。
Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key; Map输出的value为joi…

【Hive】——DDL(DATABASE)
1 概述 2 创建数据库 create database if not exists test_database
comment "this is my first db"
with dbproperties (createdByAllen);3 描述数据库信息
describe 可以简写为desc extended 可以展示更多信息
describe database test_database;
describe databa…
全国职业院校技能大赛“大数据应用开发”赛项说明
1、赛项介绍
(1)赛项名称 全 国 职 业 院 校 技 能 大 赛 “大数据应用开发” 赛 项 职业院校技能大赛官网 (vcsc.org.cn)https://www.vcsc.org.cn/ 大赛组织机构介绍 全国职业院校技能大赛(以下简称大…
【已解决】Atlas 导入 Hive 元数据,执行 import-hive.sh 报错
部署完 Atlas 之后,尝试导入 Hive 元数据,遇到了一些错误,特此记录一下,方便你我他。 执行 import-hive.sh 报错
[omchadoop102 apache-atlas-2.2.0]$ hook-bin/import-hive.sh
Using Hive configuration directory [/opt/module…

Hive学习新天地一站式掌握Hive技能,让你成为大数据领域的佼佼者!
介绍:Hive是一个构建在Hadoop顶层的数据仓库工具,起源于Facebook为了解决海量数据的统计分析需求。它能够将结构化的数据文件映射为一张数据库表,并提供类似于SQL的查询功能,可以将SQL语句转换为MapReduce任务进行运行。 Hive的出…
Hive Serde
Hive Serde
目的:
Hive Serde用来做序列化和反序列化,构建在数据存储和执行引擎之间,对两者实现解耦。
应用场景:
1、hive主要用来存储结构化数据,如果结构化数据存储的格式嵌套比较复杂的时候,可…
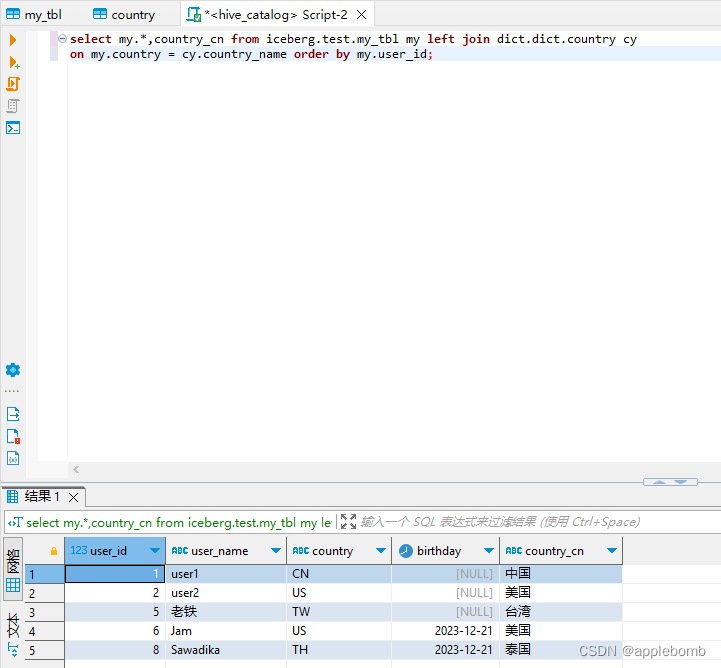
【湖仓一体尝试】MYSQL和HIVE数据联合查询
爬了两天大大小小的一堆坑,今天把一个简单的单机环境的流程走通了,记录一笔。
先来个完工环境照: mysqlhadoophiveflinkicebergtrino
得益于IBM OPENJ9的优化,完全启动后的内存占用:
1)执行联合查询后的…
【hive】Hive中的大宽表及其底层详细技术点
简介: 在大数据环境中,处理大规模数据集是常见的需求。为了满足这种需求,Hive引入了大宽表(Large Wide Table)的概念,它是一种在Hive中管理和处理大量列的数据表格。本文将详细介绍Hive中的大宽表概念以及其底层的详细…
hive中array相关函数总结
目录 hive官方函数解释示例实战 hive官方函数解释
hive官网函数大全地址: hive官网函数大全地址
Return TypeNameDescriptionarrayarray(value1, value2, …)Creates an array with the given elements.booleanarray_contains(Array, value)Returns TRUE if the a…
Hive-DML详解(超详细)
文章目录 前言HiveQL的数据操作语言(DML)1. 插入数据1.1 直接插入固定值1.2 插入查询结果 2. 更新数据3. 删除数据3.1 删除整个分区 4. 查询数据4.1 基本查询4.2 条件筛选4.3 聚合函数 总结 前言
本文将介绍HiveQL的数据操作语言(DML&#x…
Hive-DDL详解(超详细)
文章目录 前言HiveQL的数据定义语言(DDL)1. 创建数据库2. 切换到指定数据库3. 创建表格(1) 基本形式:(2) 示例: 4. 查看表格结构5. 删除数据库和表格(1) 删除数据库:(2) 删除数据表: 总结 前言
本教程将介绍HiveQL的数据定义语言(DDL&#x…
Hadoop入门学习笔记——七、Hive语法
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8
Hadoop入门学习笔记(汇总) 目录 七、Hive语法7.1. 数据库相关操作7.1.1. 创建数据库7.1.2…
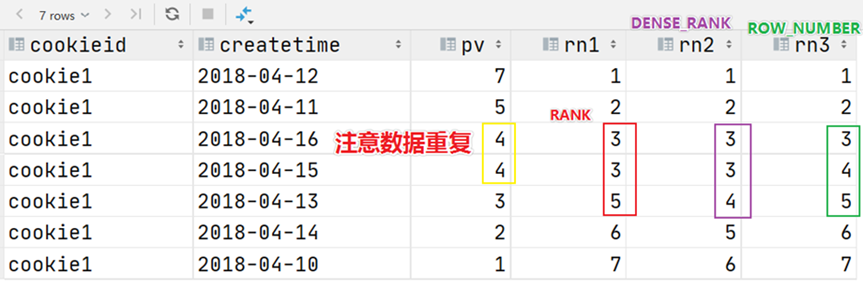
【Hive】——函数
1 概述 2 内置函数
内置函数(build-in)指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。官方文档地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManualUDF describe function extended get_json_obj…
Hive与Presto中的列转行区别
Hive与Presto列转行的区别 1、背景描述2、Hive/Spark列转行3、Presto列转行 1、背景描述 在处理数据时,我们经常会遇到一个字段存储多个值,这时需要把一行数据转换为多行数据,形成标准的结构化数据
例如,将下面的两列数据并列转换…

【kettle】pdi/data-integration 集成kerberos认证连接hive或spark thriftserver
一、背景
kerberos认证是比较底层的认证,掌握好了用起来比较简单。 kettle当前任务的jvm任务完成kerberos认证后会存储认证信息,之后直接连接hive就可以了无需提供额外的用户信息。
spark thriftserver本质就是通过hive jdbc协议连接并运行spark sql任…
Atlas Hook 导入 Hive 元数据
Atlas 部署之后就可以导入 Hive 元数据,这部分工作由 Atlas 组件 Hook 来完成。初次导入 Hive 元数据需要通过执行 shell 脚本来完成,然后,Atlas 就可以自动同步增量元数据信息了。下面我介绍一下如何完成这些工作。
初次导入 Hive 元数据
…
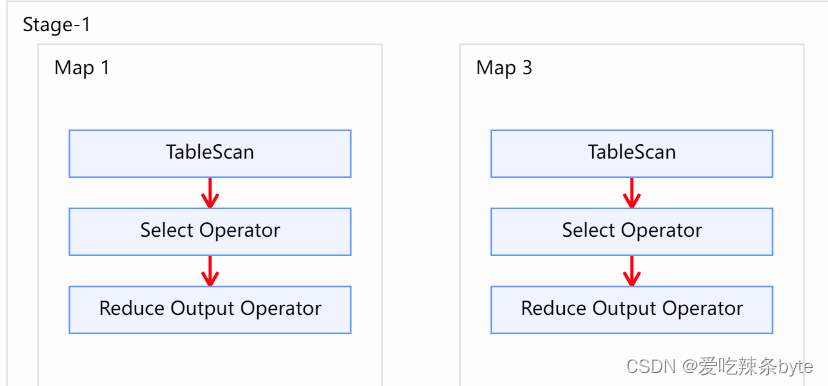
Hive的Join连接
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…
Hive的CTE 公共表达式
目录
1.语法 2. 使用场景
select语句
chaining CTEs 链式
union语句
insert into 语句
create table as 语句
前言 Common Table Expressions(CTE):公共表达式是一个临时的结果集,该结果集是从with子句中指定的查询派生而来…
Hive的Join连接、谓词下推
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…
Hive3.1.2——企业级调优
前言 本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~
一、性能评估和优化
1.1 Explain查询计划 使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。 explain执行计划…
Hive的相关概念——分区表、分桶表
目录
一、Hive分区表
1.1 分区表的概念
1.2 分区表的创建
1.3 分区表数据加载及查询
1.3.1 静态分区
1.3.2 动态分区
1.4 分区表的本质及使用
1.5 分区表的注意事项
1.6 多重分区表
二、Hive分桶表
2.1 分桶表的概念
2.2 分桶表的创建
2.3 分桶表的数据加载
2.4 …
Hive——动态分区导致的小文件问题
目录
0 问题现象
1 问题解决
解决方案一:调整动态分区数
方案一弊端:小文件剧增
解决方案二:distribute by
方案二弊端:数据倾斜
解决方案三:distribute by命令
2 思考
3 小结
0 问题现象
现象:…
(04)Hive的相关概念——order by 、sort by、distribute by 、cluster by
Hive中的排序通常涉及到order by 、sort by、distribute by 、cluster by
一、语法 selectcolumn1,column2, ...
from table
[where 条件]
[group by column]
[order by column]
[cluster by column| [distribute by column] [sort by column]
[limit [offset,] rows];
…
(15)Hive调优——数据倾斜的解决指南
目录
前言
一、什么是数据倾斜
二、发生数据倾斜的表现
2.1 MapReduce任务
2.2 Spark任务
三、如何定位发生数据倾斜的代码
四、发生数据倾斜的原因
3.1 key分布不均匀
3.1.1 某些key存在大量相同值
3.1.2 存在大量异常值或空值
3.2 业务数据本身的特性
3.3 SQL语句…
SparkUI任务启动参数介绍(148个参数)
SparkUI任务启动参数介绍(148个参数)
1 spark.app.id: Spark 应用程序的唯一标识符。 2 spark.app.initial.jar.urls: Spark 应用程序的初始 Jar 包的 URL。 3 spark.app.name: Spark 应用程序的名称。 4 spark.app.startTime: Spark 应用程序的启动时间…
(08)Hive——Join连接、谓词下推
前言 Hive-3.1.2版本支持6种join语法。分别是:inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左…

Shiro-11-web 介绍
配置
将Shiro集成到任何web应用程序的最简单方法是在web.xml中配置一个Servlet ContextListener和过滤器,该Servlet了解如何读取Shiro的INI配置。
INI配置格式本身的大部分是在配置页面的INI部分中定义的,但是我们将在这里介绍一些额外的特定于web的部…

Sqoop 入门基础
简介 Sqoop(SQL to Hadoop)是一个开源工具,用于在关系型数据库和Hadoop之间传输数据。它提供了一种快速高效的方式,将数据从关系型数据库导入到Hadoop集群进行分析,并支持将Hadoop集群中的数据导出到关系型数据库中。本…

从零开始了解大数据(七):总结
系列文章目录 从零开始了解大数据(一):数据分析入门篇-CSDN博客 从零开始了解大数据(二):Hadoop篇-CSDN博客 从零开始了解大数据(三):HDFS分布式文件系统篇-CSDN博客 从零开始了解大数据(四):MapReduce篇-CSDN博客 从零开始了解大…

Hive - Select 使用 in 限制范围
目录
一.引言
二.Select Uid Info
1.少量 Uid
2.大量 Uid
◆ 建表
◆ 本地 Load
◆ HDFS Load
◆ Select In
三.总结 一.引言
工业场景下 Hive 表通常使用 uid 作为用户维度构建和更新 Hive 表,当我们需要查询指定批次用户信息时,可以使用 in …

Hive11_Rank函数
Rank
1)函数说明
RANK() 排序相同时会重复,总数不会变 DENSE_RANK() 排序相同时会重复,总数会减少 ROW_NUMBER() 会根据顺序计算
2)数据准备 3)需求
计算每门学科成绩排名。
4)创建本地 score.txt&…
Mysql数据库中表名和数据导入hive数据库中
使用的是shell脚本
#!/bin/bash
#mysql地址
mysql_host"ip地址"
#mysql端口
mysql_port"3306"
#mysql用户名
mysql_user"root"
#mysql密码
mysql_password"root"
#mysql数据库
mysql_database"testdb"
#连接mysql执行sql语…
Hive之set参数大全-4
F
指定在使用 FETCH 命令提取查询结果时的序列化/反序列化器
hive.fetch.output.serde 是 Hive 的一个配置参数,用于指定在使用 FETCH 命令提取查询结果时的序列化/反序列化器。
以下是一个示例:
-- 设置 hive.fetch.output.serde 为 org.apache.had…

大数据本地环境搭建-Zookeeper/Hadoop/Hive搭建
1. Zookeeper环境安装
链接:https://pan.baidu.com/s/1wzbCiDxP7H5G_llwjSS3Rw?pwdwgal 提取码:wgal
1.1 上传tar包
zookeeper-3.4.6.tar 注意:上传文件位置为 /export/server目录 1.2 解压缩
cd /export/server
tar xvf /export/server…
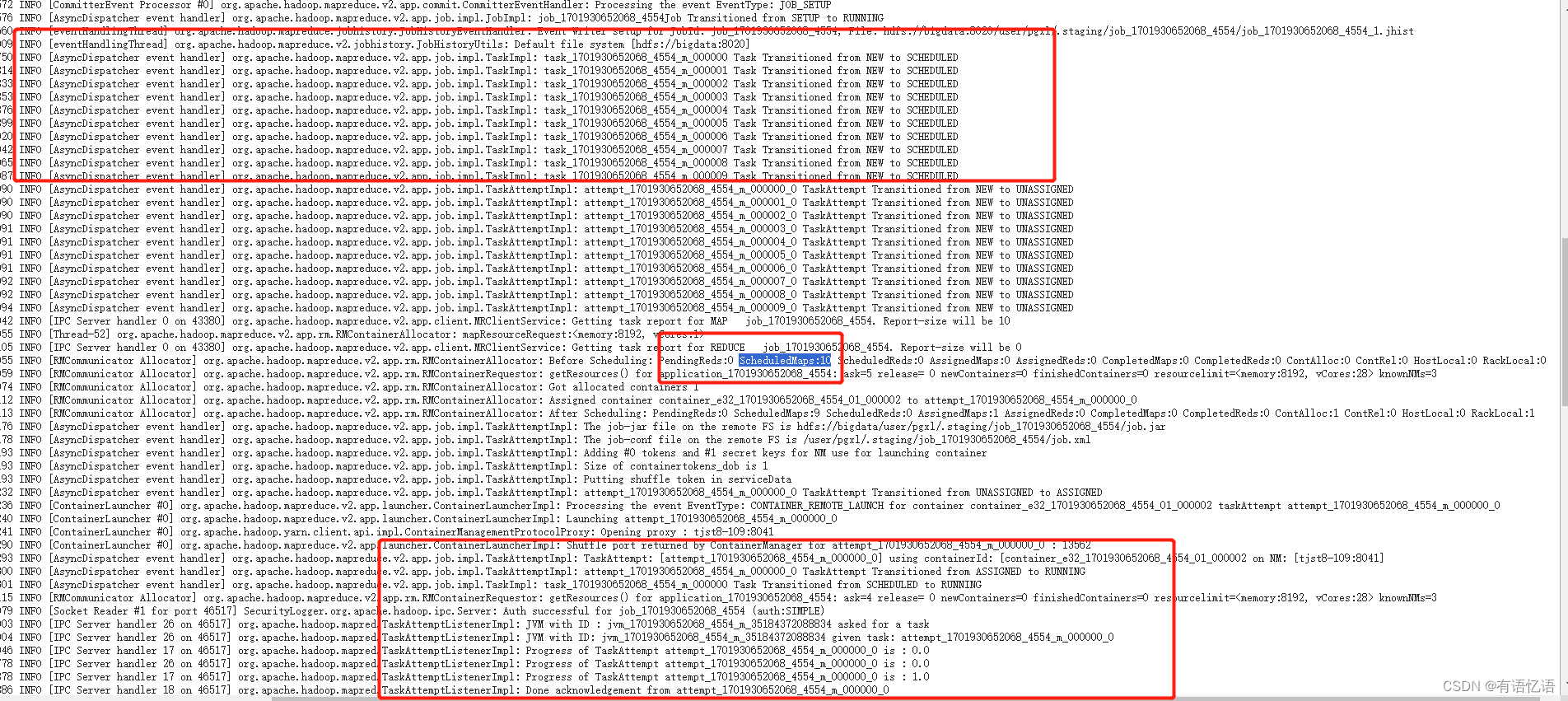
hive映射es表任务失败,无错误日志一直报Task Transitioned from NEW to SCHEDULED
一、背景
要利用gpt产生的存放在es种的日志表做统计分析,通过hive建es的映射表,将es的数据拉到hive里面。 在最初的时候同事写的是全量拉取,某一天突然任务报错,但是没有错误日志一直报:Task Transitioned from NEW t…
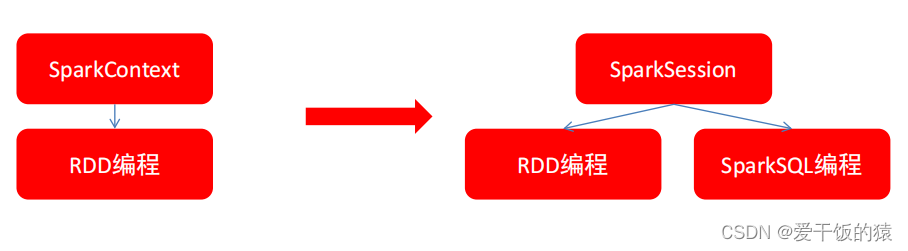
【SparkSQL】基础入门(重点:SparkSQL和Hive的异同、SparkSQL数据抽象)
【大家好,我是爱干饭的猿,本文重点介绍Spark SQL的定义、特点、发展历史、与hive的区别、数据抽象、SparkSession对象。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一…

Kettle 安装配置
文章目录 Kettle 安装配置Kettle 安装Kettle 配置连接 Hive Kettle 安装配置
Kettle 安装
在安装Kettle之前,需要确定已经安装Java运行环境。Kettle需要Java的支持才能运行,JDK的版本最好是8.x的太新的也会出现bug。Kettle的7.1版本的太旧了࿰…
大华的Hive技术文档
。。。。。
如何在Linux上安装并配置Hive
##############
# HIVE 3.1.2 #
############### 1、解压并重命名cd /opt/downloadtar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/software/mv /opt/software/apache-hive-3.1.2-bin/ /opt/software/hive312cd /opt/software/hive…
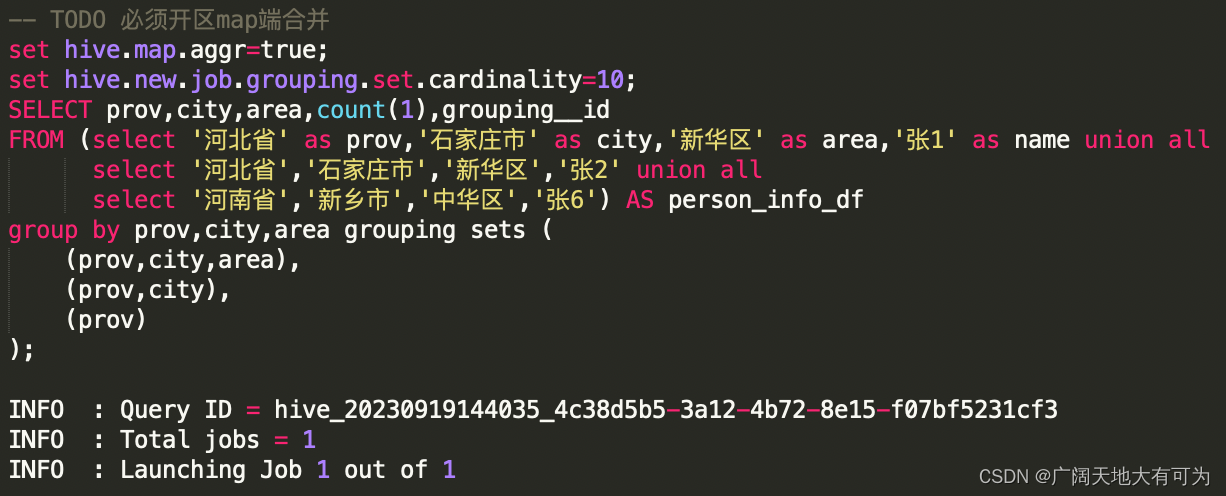
hive、spark、presto 中的增强聚合-grouping sets、rollup、cube
目录
1、什么是增强聚合和多维分析函数?
2、grouping sets - 指定维度组合
3、with rollup - 上卷维度组合
4、with cube - 全维度组合
5、Grouping__ID、grouping() 的使用场景
6、使用 增强聚合 会不会对查询性能有提升呢?
7、对grouping sets、…
hive表字段跟字段对应的值转为json数组
第一种方式 直接用hive 函数实现
select collect_list(named_struct(id,id,name,name)) from table 此方式不适用于字段数量过多的情况(比较麻烦)
第二种方式 写udf 函数
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.had…
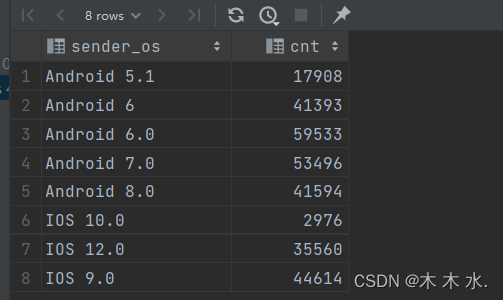
大数据从入门到精通(超详细版)之Hive案例,指标统计, Sql语句的编写
前言
嗨,各位小伙伴,恭喜大家学习到这里,不知道关于大数据前面的知识遗忘程度怎么样了,又或者是对大数据后面的知识是否感兴趣,本文是《大数据从入门到精通(超详细版)》的一部分,小…
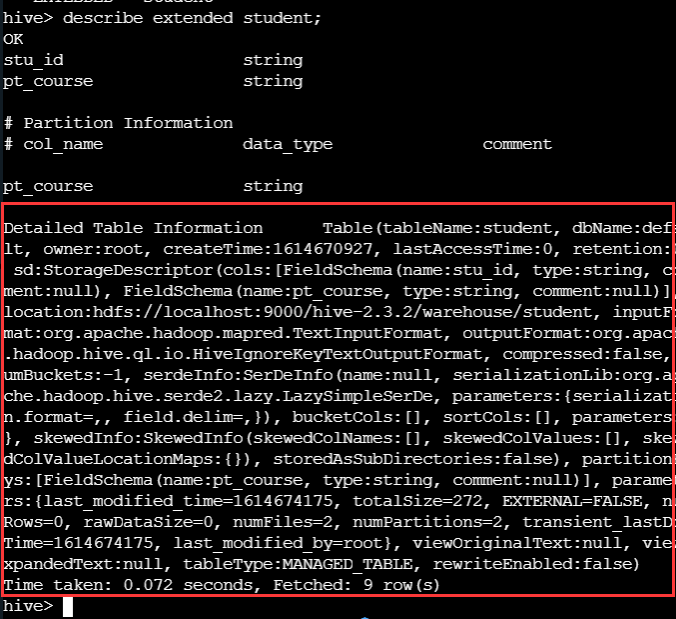
第1关:Hive 的 Alter Table 操作
相关知识
为了完成本关任务,你需要掌握: 1.Alter Table 命令
Alter Table 命令
Alter Table 命令 可以在 Hive 中修改表名,列名,列注释,表注释,增加列,调整列顺序,属性名等操作。…

一百八十四、大数据离线数仓完整流程——步骤三、在Hive中建基础库维度表并加载MySQL中的维度表数据
一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(三)步骤三、在Hive中…
Hive SQL初级练习(30题)
前言
Hive 的重要性不必多说,离线批处理的王者,Hive 用来做数据分析,SQL 基础必须十分牢固。
环境准备
建表语句
这里建4张表,下面的练习题都用这些数据。
-- 创建学生表
create table if not exists student_info(stu_id st…
数据库:Hive转Presto(三)
继续上节代码。
import re
import os
import tkinter.filedialog
from tkinter import *class Hive2Presto:def __int__(self):self.t_funcs [substr, nvl, substring, unix_timestamp] \[to_date, concat, sum, avg, abs, year, month, ceiling, floor]self.time_funcs [d…
电影票房之数据分析(Hive)--第3关
第3关:统计2020年中当日综合总票房最多的10天
本关任务
基于EduCoder平台提供的初始数据集,统计 2020 年中当日综合总票房最多的 10 天及其当日综合总票房。
编程要求
本实验环境已开启Hadoop服务
在 hive 中创建数据库 mydb;
注意&…
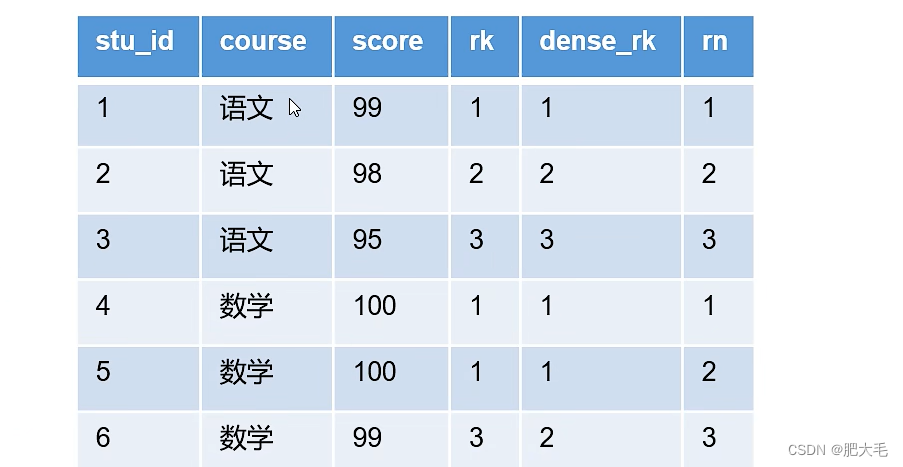
Hive窗口函数回顾
1.语法 1.1 基于行的窗口函数
Hive的窗口函数分为两种类型,一种是基于行的窗口函数,即将某个字段的多行限定为一个范围,对范围内的字段值进行计算,最后将形成的字段拼接在该表上。 注意:在进行窗口函数计算之前&#…
Hive的几种排序方式、区别,使用场景
一、几种排序和区别
Hive 支持两种主要的排序方式:ORDER BY 和 SORT BY。除此之外,还有 DISTRIBUTE BY 和 CLUSTER BY 语句,它们也在排序和数据分布方面发挥作用。
1. ORDER BY
ORDER BY 在 Hive 中用于对查询结果进行全局排序࿰…
如何截取Hive数组中的前N个元素?
文章目录 1、需求描述2、使用索引3、使用posexplode()4、转换为字符串操作 1、需求描述 需求:截取任意给定数组中的前N个元素,返回截取后的子数组
假设我们有如下三种类型的Hive数组:
select array(1,2,3,4) -- [1,2,3,4]
selec…
大数据Hive--分区表和分桶表
文章目录 一、分区表1.1 分区表1.1.1 分区表基本语法1.1.1.1 创建分区表1.1.1.2 分区表读写数据1.1.1.3 分区表基本操作 1.2 二级分区表1.3 动态分区 二、分桶表2.1 分桶表基本语法2.2 分桶排序表 一、分区表
1.1 分区表
Hive中的分区就是把一张大表的数据按照业务需要分散的…
java大数据hadoop2.9.2 hive操作
1、创建常规数据库表
(1)创建表
create table t_stu2(id int,name string,hobby map<string,string>
) row format delimited
fields terminated by ,
collection items terminated by -
map keys terminated by :;
(2)创…

数据湖技术之发展现状篇
一. 大数据处理架构: 大数据处理架构的发展过程具体可以分为三个主要阶段:批处理架构、混合处理架构(Lambda、Kappa架构)、湖仓一体。首先是随着Hadoop生态相关技术的大量应用,批处理架构应运而生,借助离线…
Hive之set参数大全-17
配置是否启用 HiveServer2 的 Web 用户界面(WebUI)中的跨源资源共享(CORS)
在 Hive 中,hive.server2.webui.enable.cors 是一个参数,用于配置是否启用 HiveServer2 的 Web 用户界面(WebUI&…
Hive之set参数大全-14
指定在复制过程中的最大负载任务数的近似值
在 Hive 中,hive.repl.approx.max.load.tasks 是一个配置参数,用于指定在复制过程中的最大负载任务数的近似值。这个参数用于限制 Hive 复制过程中的任务数量,以防止对源系统造成过大的负载。
以…
HiveSQL题——聚合函数(sum/count/max/min/avg)
目录
一、窗口函数的知识点
1.1 窗户函数的定义
1.2 窗户函数的语法
1.3 窗口函数分类
聚合函数
排序函数
前后函数
头尾函数
1.4 聚合函数
二、实际案例
2.1 每个用户累积访问次数
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 各直播间最大的同时在线人数 …
Java抽取Hive、HDFS元数据信息
文章目录 一、技术二、构建SpringBoot工程2.1 创建maven工程并配置 pom.xml文件2.2 编写配置文件 application.yml2.3 编写配置文件 application.propertites2.4 开发主启动类2.5 开发配置类 三、测试抽取Hive、HDFS元数据四、将抽取的元数据存储到MySQL4.1 引入依赖4.2 配置ap…

Servlet过滤器个监听器
过滤器和监听器
过滤器
什么是过滤器
当浏览器向服务器发送请求的时候,过滤器可以将请求拦截下来,完成一些特殊的功能,比如:编码设置、权限校验、日志记录等。
过滤器执行流程 Filter实例
package com.by.servlet;import jav…
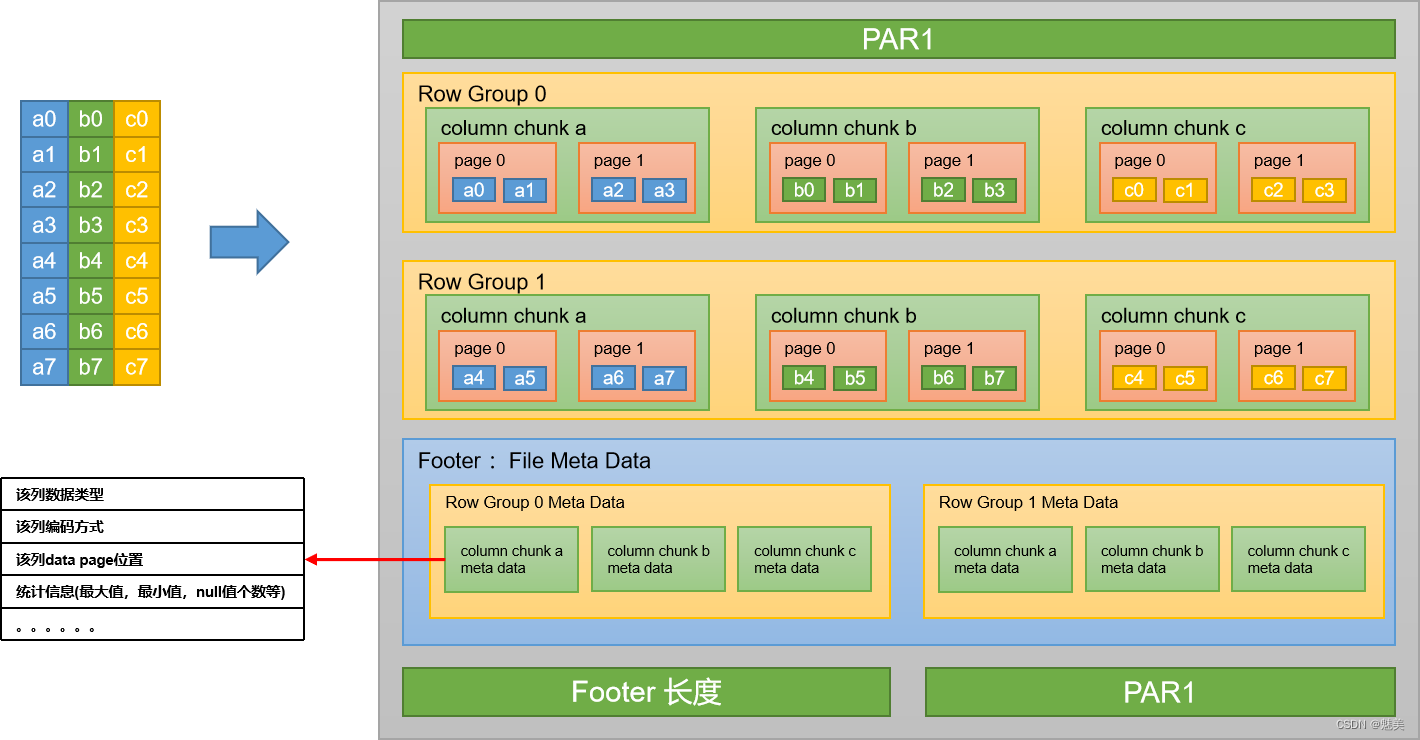
Hive3.1.3基础(续)
参考B站尚硅谷 目录 分区表和分桶表分区表分区表基本语法二级分区表动态分区 分桶表分桶表基本语法分桶排序表 文件格式和压缩Hadoop压缩概述Hive文件格式Text FileORCParquet 压缩Hive表数据进行压缩计算过程中使用压缩 分区表和分桶表
分区表
Hive中的分区就是把一张大表的…

Hive SQL 开发指南(二)使用(DDL、DML,DQL)
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指…
Hive之set参数大全-22(完)
指定是否启用矢量化处理复杂数据类型
在 Hive 中,hive.vectorized.complex.types.enabled 是一个配置参数,用于指定是否启用矢量化处理复杂数据类型。以下是有关该参数的一些解释: 用途: 该参数用于控制是否启用 Hive 的矢量化执…
大数据学习(3)-hive分区表与分桶表
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
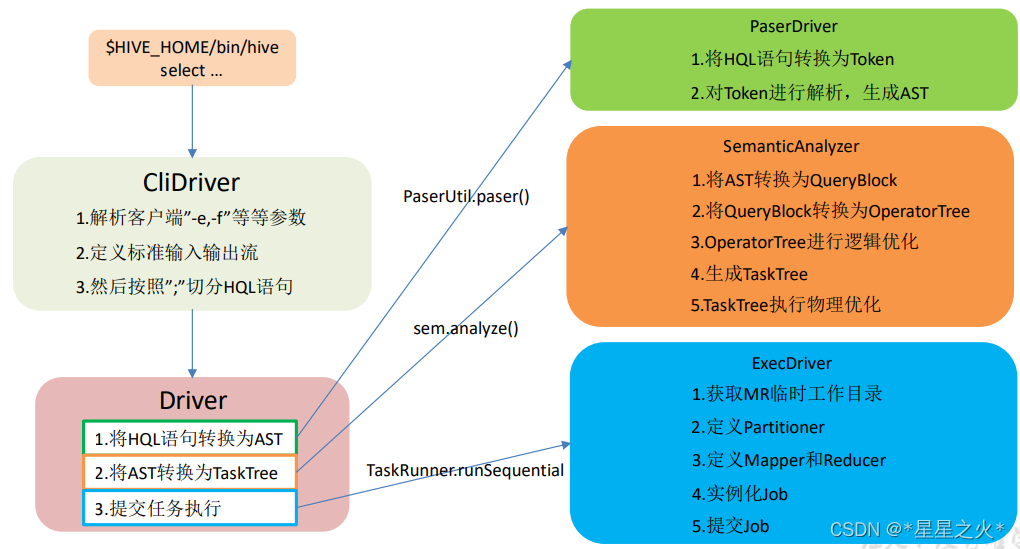
hive3.1核心源码思路
系列文章目录
大数据主要组件核心源码解析 文章目录 系列文章目录大数据主要组件核心源码解析 前言一、HQL转化为MR 核心思路二、核心代码1. 入口类,生命线2. 编译代码3. 执行代码 总结 前言
提示:这里可以添加本文要记录的大概内容:
对大…
【Spark实战系列】sparkstreaming 实时写入 hive 后合并小文件问题
今天主要来说一下sparksql写入hive后小文件太多,影响查询性能的问题.在另外一篇博客里面也稍微提到了一下,但还是感觉要单独说一下,首先我们要知道hive里面文件的数量=executor-cores*num-executors*job数,所以如果我们batchDuration的设置的比较小的话,每天在一个分区里面就会…
数据库:Hive转Presto(四)
这次补充了好几个函数,并且新加了date_sub函数,代码写的比较随意,有的地方比较繁琐,还待改进,而且这种文本处理的东西,经常需要补充先前没考虑到的情况,要经常修改。估计下一篇就可以补充完所有…
hive进行base64 加密解密函数
加密
select base64(cast(abcd as binary))YWJjZA
解密
-- 直接解密(结果字段格式为比binary格式)
select unbase64(YWJjZA)
-- 格式转换
select cast(unbase64(YWJjZA) as string) abcd
大数据学习(15)-数据倾斜
&&大数据学习&&
🔥系列专栏: 👑哲学语录: 承认自己的无知,乃是开启智慧的大门 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言📝支持一下博>主哦&#x…
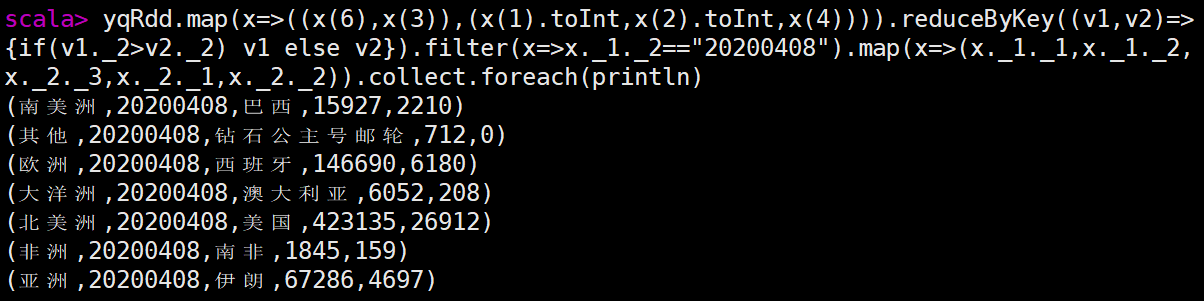
Hadoop+Hive+Spark+Hbase开发环境练习
1.练习一 1.数据准备 在hdfs上创建文件夹,上传csv文件 [rootkb129 ~]# hdfs dfs -mkdir -p /app/data/exam 查看csv文件行数 [rootkb129 ~]# hdfs dfs -cat /app/data/exam/meituan_waimai_meishi.csv | wc -l 2.分别使用 RDD和 Spark SQL 完成以下分析…

Hadoop3.0大数据处理学习1(Haddop介绍、部署、Hive部署)
Hadoop3.0快速入门
学习步骤:
三大组件的基本理论和实际操作Hadoop3的使用,实际开发流程结合具体问题,提供排查思路
开发技术栈:
Linux基础操作、Sehll脚本基础JavaSE、Idea操作MySQL
Hadoop简介
Hadoop是一个适合海量数据存…
【Java 进阶篇】Java HTTP响应消息详解
在Web开发中,HTTP(Hypertext Transfer Protocol)是一种用于传输数据的协议,它用于浏览器和Web服务器之间的通信。当你在浏览器中访问一个网页时,浏览器向Web服务器发送HTTP请求,然后Web服务器返回HTTP响应。…
(14)Hive调优——合并小文件
目录 一、小文件产生的原因
二、小文件的危害
三、小文件的解决方案
3.1 小文件的预防
3.1.1 减少Map数量 3.1.2 减少Reduce的数量
3.2 已存在的小文件合并
3.2.1 方式一:insert overwrite (推荐) 3.2.2 方式二:concatenate 3.2.3 方式三ÿ…

(17)Hive ——MR任务的map与reduce个数由什么决定?
一、MapTask的数量由什么决定? MapTask的数量由以下参数决定
文件个数文件大小blocksize 一般而言,对于每一个输入的文件会有一个map split,每一个分片会开启一个map任务,很容易导致小文件问题(如果不进行小文件合并&…
(16)Hive——企业调优经验
前言 本篇文章主要整理hive-3.1.2版本的企业调优经验,有误请指出~
一、性能评估和优化
1.1 Explain查询计划 使用explain命令可以分析查询计划,查看计划中的资源消耗情况,定位潜在的性能问题,并进行相应的优化。 explain执行计划…
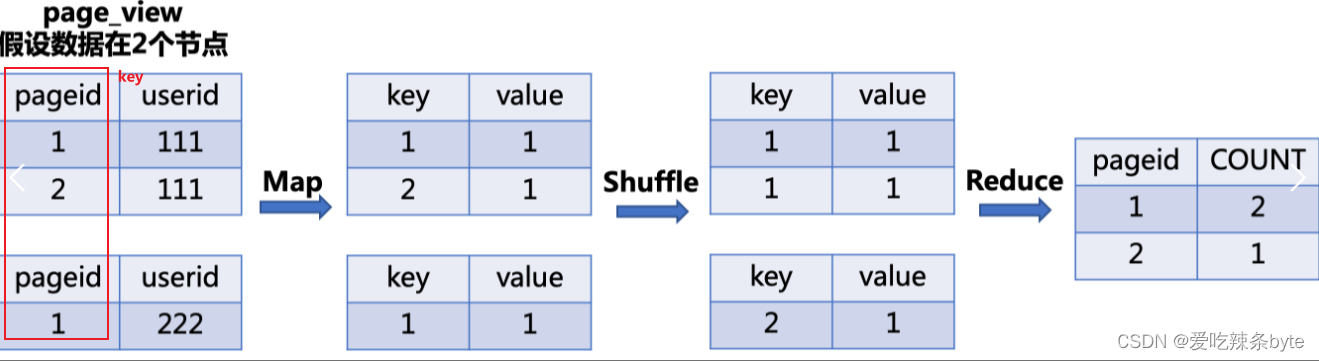
(02)Hive SQL编译成MapReduce任务的过程
目录 一、架构及组件介绍
1.1 Hive底层架构
1.2 Hive组件
1.3 Hive与Hadoop交互过程
二、Hive SQL 编译成MR任务的流程
2.1 HQL转换为MR源码整体流程介绍
2.2 程序入口—CliDriver
2.3 HQL编译成MR任务的详细过程—Driver
2.3.1 将HQL语句转换成AST抽象语法树
词法、语…
HiveSQL题——炸裂函数(explode/posexplode)
目录
一、炸裂函数的知识点
1.1 炸裂函数 explode
posexplode
1.2 lateral view 侧写视图
二、实际案例
2.1 每个学生及其成绩
0 问题描述
1 数据准备
2 数据分析
3 小结
2.2 日期交叉问题
0 问题描述
1 数据准备
2 数据分析
3 小结
2.3 用户消费金额
0 问题…
Hive之set参数大全-20
指定在执行大表半连接操作时的最小表大小,以决定是否启用半连接操作的优化
在 Hive 中,hive.tez.bigtable.minsize.semijoin.reduction 是一个配置参数,用于指定在执行大表半连接操作时的最小表大小,以决定是否启用半连接操作的优…
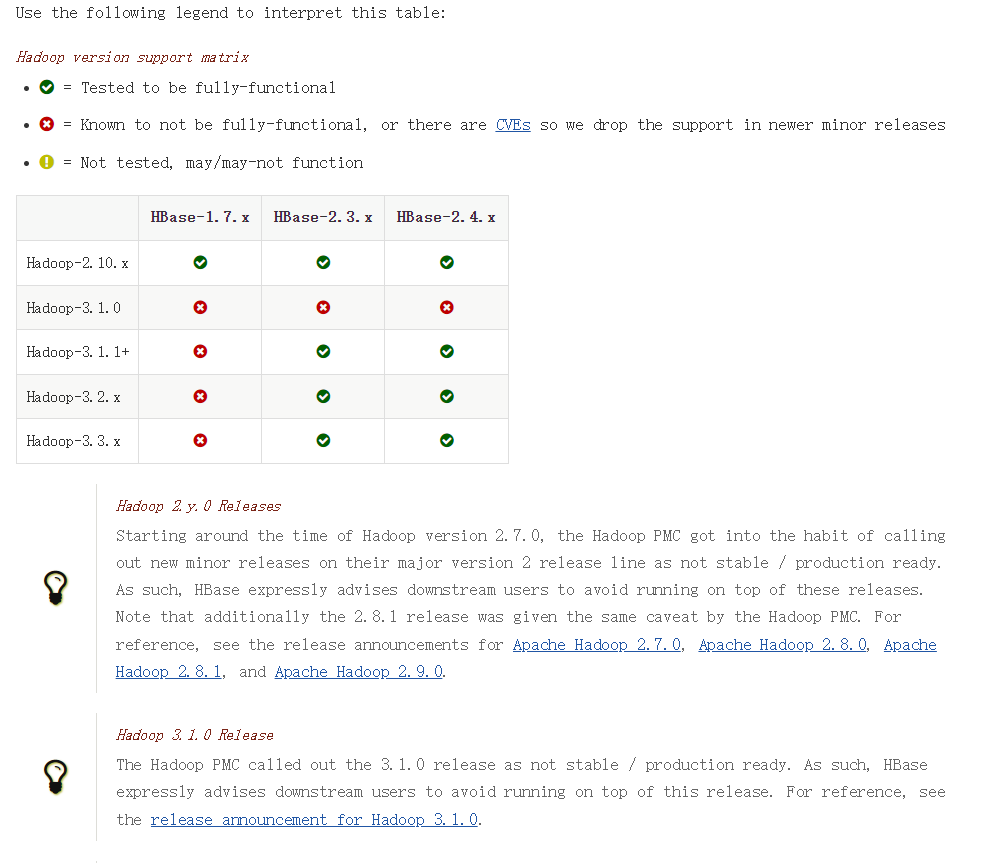
Java技术栈 —— Hive与HBase
Java技术栈 —— Hive与HBase 一、 什么是Hive与HBase二、如何使用Hive与HBase?2.1 Hive2.1.1 安装2.1.2 使用2.1.2.1 使用前准备2.1.2.2 开始使用hive 2.2 HBase2.2.1 安装2.2.2 使用 三、Apache基金会 一、 什么是Hive与HBase
见参考文章。
一、参考文章或视频链…
hivesql的基础知识点
目录
一、各数据类型的基础知识点
1.1 数值类型
整数
小数
float
double(常用)
decimal(针对高精度)
1.2 日期类型
date
datetime
timestamp
time
year 1.3 字符串类型
char
varchar / varchar2
blob /text tinyblob / tinytext
mediumblob / mediumtext
lon…

JDK8 和 JDK17 下基于JDBC连接Kerberos认证的Hive(代码已测试通过正常)
0.背景
之前自研平台是基于jdk8开发的,连接带Kerberos的hive也是jdk8,现在想升级jdk到17,发现过Kerberos的hive有点不一样,特地记录 连接Kerberos,krb5.conf 和对应服务的keytab文件以及principal肯定是需要提前准备的,
一般从服务器或者运维那里获取krb5.conf 与 Hive对应的…
Hive collect_set()、collect_list()列转行,并对转换后的行值排序
Hive collect_set()、collect_list()列转行,和concat_ws()使用,并对转换后的行值排序 1、需求描述
对列值分组,并按一定顺序排序,最后多行合并一行,合并值左到右逆序排列。
2、考点:
sort_array(e: colu…
SpringBoot源码解读与原理分析(六)WebMvc场景的自动装配
文章目录 2.6 WebMvc场景下的自动装配原理2.6.1 WebMvcAutoConfiguration2.6.2 Servlet容器的装配2.6.2.1 EmbeddedTomcat、EmbeddedJetty、EmbeddedUndertow2.6.2.2 BeanPostProcessorsRegistrar(后置处理器的注册器)2.6.2.3 两个定制器的注册 2.6.3 DispatcherServlet的装配2…
sqoop-import 详解
文章目录 前言一、介绍1. sqoop简介2. sqoop import的作用3. 语法3.1 sqoop import 语法3.2 导入配置属性 二、导入参数1. 常见参数2. 验证参数3. 导入控制参数4. 用于覆盖映射的参数5. 增量导入参数6. 输出行格式参数7. 输入解析参数8. Hive 参数9. HBase 参数10. Accumulo 参…
java : 通过jdbc读取hive(2.3)中的数据
一、准备好hive的环境,创建表(例如userinfo),添加数据。
create table userinfo(x string, y string);
insert into userinfo values(tju,beiyang);二、启动hive服务 hive --service hiveserver2 三、项目中添加依赖 <dependency><groupId>org.apache.…
Hive基础知识(十一):Hive的数据导出方法示例
1. Insert 导出 1)将查询的结果导出到本地 hive (default)> insert overwrite local directory /opt/module/hive/data/export/student select * from student5;
Automatically selecting local only mode for query
Query ID atguigu_20211217153118_31119102-…

Hive命令行运行SQL将数据保存到本地如何去除日志信息
1.场景分析
先有需求需要查询hive数仓数据并将结果保存到本地,但是在操作过程中总会有日志信息和表头信息一起保存到本地,不符合业务需要,那如何才能解决该问题呢? 废话不多少,直接上代码介绍:
2.问题解决…
大数据开发之Hive(企业级调优)
第 10 章:企业级调优
创建测试用例 1、建大表、小表和JOIN后表的语句
// 创建大表
create table bigtable(id bigint, t bigint, uid string, keyword string, url_rank int, click_num int, click_url string) row format delimited fields terminated by \t;
//…

Hive导入数据的五种方法
在Hive中建表成功之后,就会在HDFS上创建一个与之对应的文件夹,且文件夹名字就是表名; 文件夹父路径是由参数hive.metastore.warehouse.dir控制,默认值是/user/hive/warehouse; 也可以在建表的时候使用location语句指定…
CDH6.3.2,不互通的cdh平台互导hive数据
1、先导出所有建表语句,在源CDH服务器命令行输入下面命令,该库下所有建表语句保存至hive目录中的tables.sql文件中,不知道具体路径可以全局搜索一下,拿到源库hive的建表语句后,稍微处理一下,去目标库把表建…
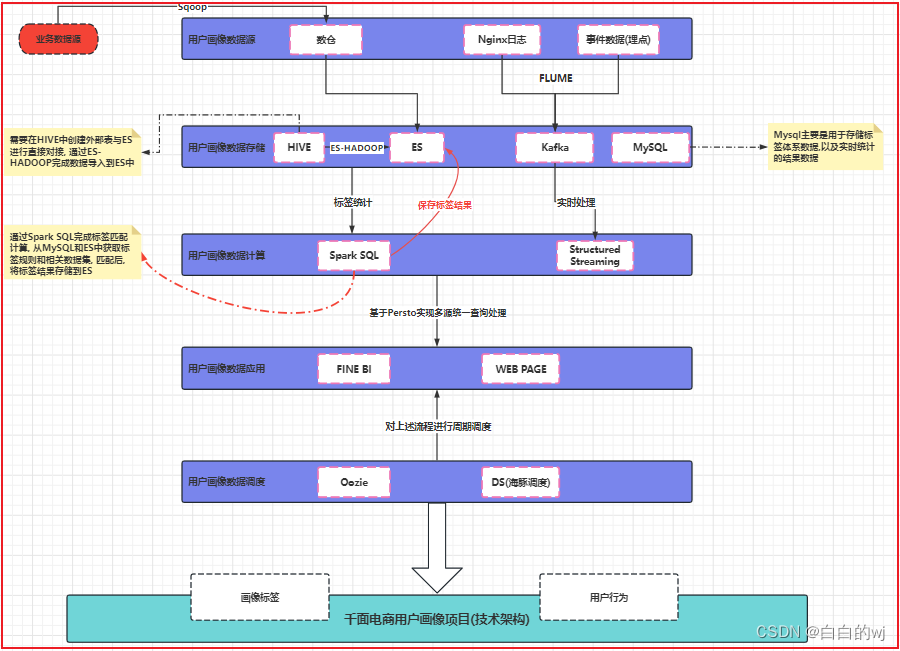
2024.1.16 用户画像day01 - 项目介绍
目录 一. 项目介绍
整体流程:
项目建设目的:
学习安排:
技术选型:
技术架构:
项目架构:
二 . 名词解释 一. 项目介绍
整体流程: 项目介绍-elasticSearch-业务数据源导入-离线指标开发-Flume实时采集-Nginx日志埋点数据- 结构化流实时指标 - 制作报表 数仓开发用户画像…
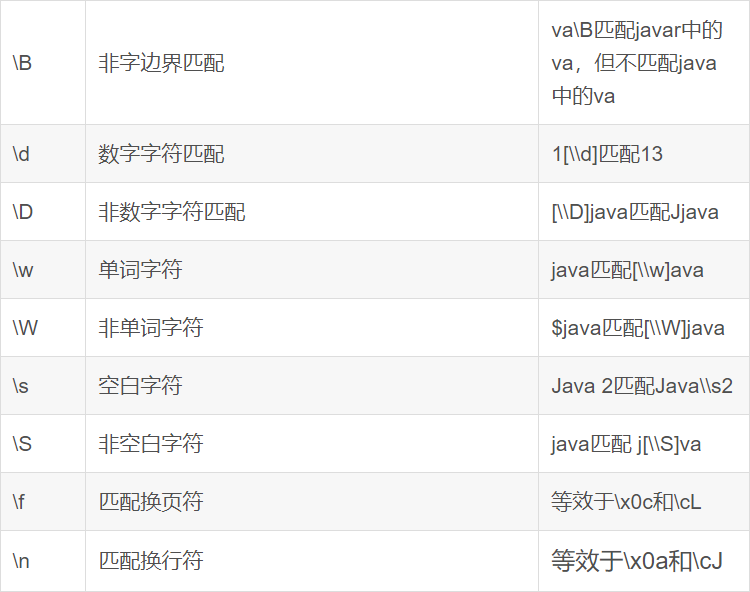
Hive-SQL语法大全
Hive SQL 语法大全
基于语法描述说明
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION] path;
SELECT expr, ... FROM tbl ORDER BY col_name [ASC | DESC]
(A | B | C)如上语法,在语法描述中出现: [],表示可选,如上[LOCATI…
Spark On Hive配置测试及分布式SQL ThriftServer配置
文章目录 Spark On Hive的原理及配置配置步骤在代码中集成Spark On Hive Spark分布式SQL执行原理及配置配置步骤在代码中集成Spark JDBC ThriftServer 总结 Spark On Hive的原理及配置
Spark本身是一个执行引擎,而没有管理metadate的能力,当我们在执行S…
通过sqoop把hive数据到mysql,脚本提示成功,mysql对应的表中没有数
1、脚本执行日志显示脚本执行成功,读写数量不为0
2、手动往Mysql对应表中写入数据十几秒后被自动删除了 问题原因:
建表时引擎用错了,如下图所示 正常情况下应该用InnoDB

基于华为MRS3.2.0实时Flink消费Kafka落盘至HDFS的Hive外部表的调度方案
文章目录 1 Kafka1.1 Kerberos安全模式的认证与环境准备1.2 创建一个测试主题1.3 消费主题的接收测试 2 Flink1.1 Kerberos安全模式的认证与环境准备1.2 Flink任务的开发 3 HDFS与Hive3.1 Shell脚本的编写思路3.2 脚本测试方法 4 DolphinScheduler 该需求为实时接收对手Topic&a…
Hive之set参数大全-9
指定LLAP(Low Latency Analytical Processing)引擎中的IO(输入/输出)线程池的大小
hive.llap.io.threadpool.size 是Apache Hive中的一个配置属性,用于指定LLAP(Low Latency Analytical Processing&#x…
大数据开发之电商数仓(hadoop、flume、hive、hdfs、zookeeper、kafka)
第 1 章:数据仓库
1.1 数据仓库概述
1.1.1 数据仓库概念
1、数据仓库概念: 为企业制定决策,提供数据支持的集合。通过对数据仓库中数据的分析,可以帮助企业,改进业务流程、控制成本,提高产品质量。 数据…
Hive 拉链表详解及实例
拉链表 版本迭代:hive 0.14 slowly changing dimension > hive 2.6.0 merge 事务管理 原来采用分区表,用户分区存储历史增量数据,缺点是重复数据太多 定义:数仓用于解决持续增长且存在一定时间时间范围内重复的数据 存储&…
docker本地搭建spark yarn hive环境
docker本地搭建spark yarn hive环境 前言软件版本准备工作使用说明构建基础镜像spark on yarn模式构建on-yarn镜像启动on-yarn集群手动方式自动方式 spark on yarn with hive(derby server)模式构建on-yarn-hive镜像启动on-yarn-hive集群手动方式自动方式 常用示例spark执行sh脚…

云服务器安装Hive
文章目录 1. 安装Hive(最小化部署)2. MySQL安装3. Hive元数据配置到MySQL4. HiveServer2服务5. Metastore服务运行模式6. 编写脚本来管理hive的metastore/hiveserver2服务的启动和停止1.7 Hive常用命令 7. Hive参数配置方式7.1 Hive常见的几个属性配置 安装Hive的前提是先安装H…

【漏洞复现】CNVD-2023-08743
【漏洞复现】
CNVD-2023-08743
【漏洞介绍】
Hongjing Human Resource Management System - SQL Injection
【指纹】
title”人力资源信息管理系统”
【系统UI】 【payload】
/servlet/codesettree?flagc&status1&codesetid1&parentid-1&categories~31…
【Java 进阶篇】Java ServletContext详解:在Web应用中获取全局信息
在Java Web开发中,ServletContext是一个重要的概念,它允许我们在整个Web应用程序中共享信息和资源。本篇博客将深入探讨ServletContext的作用、如何获取它,以及如何在Web应用中使用它。无论您是刚刚入门的小白还是有一定经验的开发者…
【数据开发】大数据平台架构,Hive / THive介绍
1、大数据引擎
大数据引擎是用于处理大规模数据的软件系统, 常用的大数据引擎包括Hadoop、Spark、Hive、Pig、Flink、Storm等。 其中,Hive是一种基于Hadoop的数据仓库工具,可以将结构化的数据映射到Hadoop的分布式文件系统上,并提…

Hive 分区表 Select 优化
Hive 分区表 Select 优化 对hive分区表执行select操作时,经常执行很慢,原因竟是因为一个点! 优化适配情况:
分区表执行select操作where选择某一分区或多个分区查询
操作:
where条件内分区选择时 在分区字段上加单引…
Hive 分区表创建,增加,删除
Hive分区表 1.从HDFS加载数据
A.建表时加载
hive -e "create table if not exists tableName
str1 string,
str2 string,
str3 string
)
partitioned by (dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY \t
STORED AS TEXTFILE"
LOCATION /user/xxx/xxx/xx…
MongoDB数据接入实践
把数据导入数据平台是挖掘数据价值的第一步,如果做不好,数据分析将收到很大影响。所以,快速、高质量、稳定的将数据从业务系统接入到数据平台是至关重要的一环。
数据平台最常见的一个数据源是关系型的数据库,然而随着软件技术的…
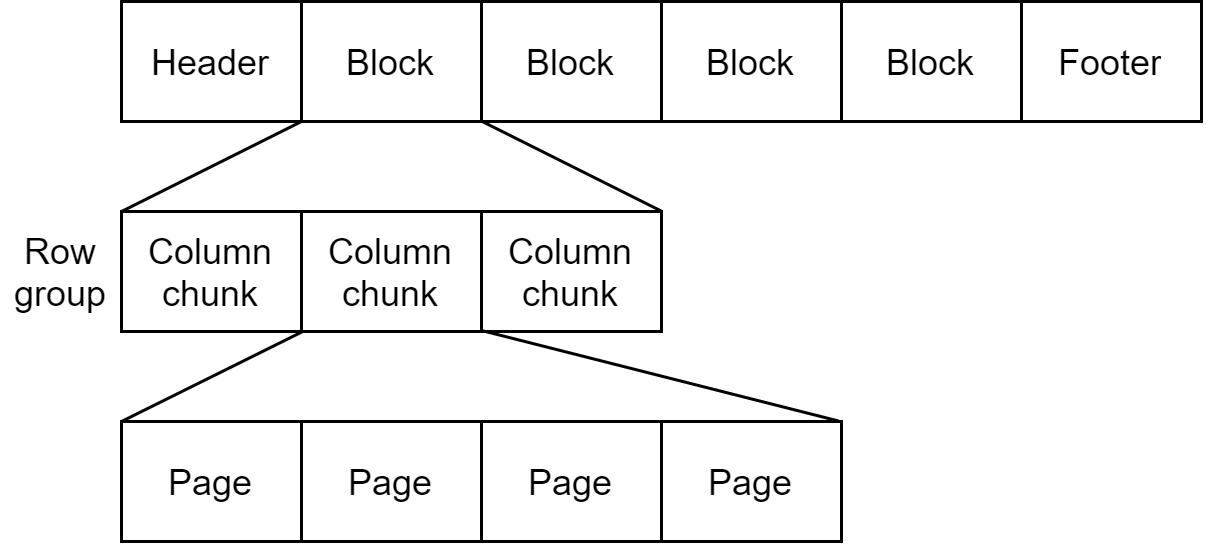
Parquet存储的数据模型以及文件格式
文章目录 数据模型Parquet 的原子类型Parquet 的逻辑类型嵌套编码 Parquet文件格式 本文主要参考文献:Tom White. Hadoop权威指南. 第4版. 清华大学出版社, 2017.pages 363. Aapche Parquet是一种能有效存储嵌套数据的列式存储格式,在Spark中应用较多。 …
Hive on Spark (1)
spark中executor和driver分别有什么作用?
Spark中Executor
在 Apache Spark 中,Executor 是分布式计算框架中的一个关键组件,用于在集群中执行具体的计算任务。每个 Executor 都在独立的 JVM 进程中运行,可以在集群的多台机器上…
Spark SQL或Hive开发调试小技巧
在本地开发机装本地模拟环境,或者能远程调试,可以参考Spark如何在生产环境调试输出dataframe日志,最好有一个开关来控制,正式上线时,把开关关了来提升速度
if (isDebug) {dataframeDF.show(10)
}dataframe的输出&…

Hive On Tez小文件合并的技术调研
Hive On Tez小文件合并的技术调研
背景
在升级到CDP7.1.5之后,默认的运算引擎变成了Tez,之前这篇有讲过:
https://lizhiyong.blog.csdn.net/article/details/126688391
具体参考Cloudera的官方文档:https://docs.cloudera.com…
SQL优化之诊断篇:快速定位生产性能问题实践
1.优化背景
用户提交一个 SQL 作业后,一方面是希望作业能够成功运行,另一方面,对于成功完成的作业,需要进一步分析作业瓶颈,进行性能调优。针对这两个方面的需求,本文将介绍如何解决作业运行时的常见问题、…
hive分区表 静态分区和动态分区
一、静态分区 现有数据文件 data_file 如下: 2023-08-01,Product A,100.0 2023-08-05,Product B,150.0 2023-08-10,Product A,200.0 1、创建分区表
CREATE TABLE sales (sale_date STRING,product STRING,amount DOUBLE
)
PARTITIONED BY (sale_year INT, sale_mon…
Hive查询转换与Hadoop生态系统引擎与优势
目录 摘要一、Hive是什么二、HDFS是什么三、Hive与HDFS的关系四、什么是HiveQL五、什么是mapreduce六、Hive如何将查询转为mapreduce任务七、Hadoop生态系统中的高性能引擎八、使用Hadoop的优点 摘要
Hadoop生态系统中包含了多个关键组件,如Hive、HDFS、MapReduce等…

ubuntu-server部署hive-part4-部署hive
参照
https://blog.csdn.net/qq_41946216/article/details/134345137 操作系统版本:ubuntu-server-22.04.3
虚拟机:virtualbox7.0
部署hive 下载上传
下载地址
http://archive.apache.org/dist/hive/ apache-hive-3.1.3-bin.tar.gz 以root用户上传至…

有关数据开发项目中使用HIVE由于无法update和delete的场景下,如何解决数据增量的思路
解决数据增量问题的思路在Hive中
在数据开发项目中,使用Hive进行数据处理时,由于Hive不支持update和delete语句,处理数据增量可能会变得有些棘手。然而,有几种策略和技术可以帮助我们解决这个问题,并确保数据增量的高…
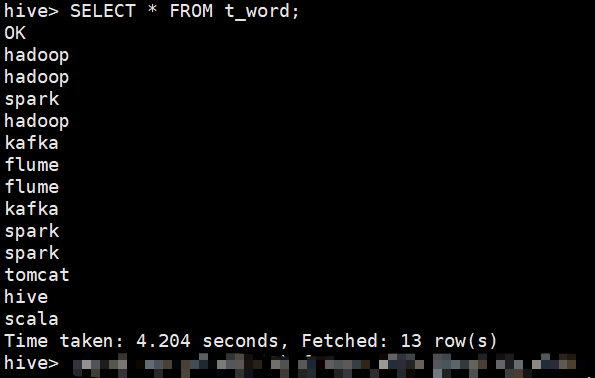
hive词频统计---文件始终上传不来
目录
准备工作:
文件内容:
创建数据库及表
将文件上传到:上传到/user/hive/warehouse/db1.db/t_word目录下
hive里面查询,始终报错:(直接查询也是不行)
解决方案: 准备工作&am…
hive 慢sql 查询
hive 慢sql 查询 查找 hive 执行日志存储路径(一般是 hive-audit.log ) 比如:/var/log/Bigdata/audit/hive/hiveserver/hive-audit.log 解析日志 获取 执行时间 执行 OperationId 执行人 UserNameroot 执行sql 数据分隔符为 \001 并写入 hiv…
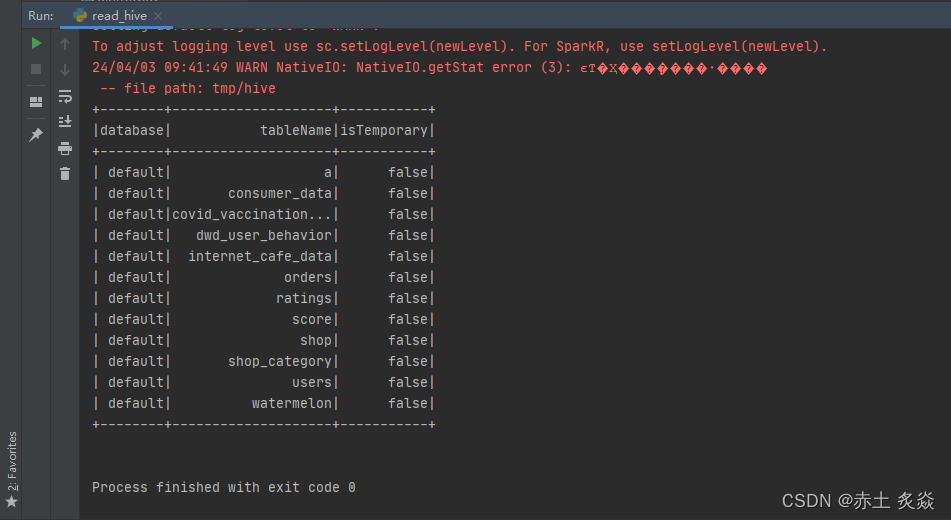
pycharm pyspark连接虚拟机的hive表 读取数据
方法:
hive配置hiveserver2和metastore url
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop111</value>
</property><!-- 指定hiveserver2连接的端口号 -…
Day2-Hive的多字段分区,分桶和数据类型
Hive
表结构
分区表 多字段分区:需要使用多个字段来进行分区,那么此时字段之间会构成多层目录,前一个字段形成的目录会包含后一个字段形成的目录,从而形成多级分类的效果。例如商品的大类-小类-子类, 省市县、年级班…
Hive 和 HDFS、MySQL 之间的关系
文章目录 HiveHDFSMySQL三者的关系 Hive、MySQL 和 HDFS 是三个不同的数据存储和处理系统,它们在大数据生态系统中扮演不同的角色,但可以协同工作以支持数据管理和分析任务。
Hive Hive 是一个基于 Hadoop 生态系统的数据仓库工具,用于管理和…

Hive 表注释乱码解决
文章目录 出现原因MySQL 字符集修改调整元数据库字符集测试 出现原因
一般 Hive 的元数据信息都存储在 MySQL 中,但 MySQL 数据库中的 character_set_server 和 character_set_database 参数,默认都为 latin1 字符集,这两个参数决定了服务器…
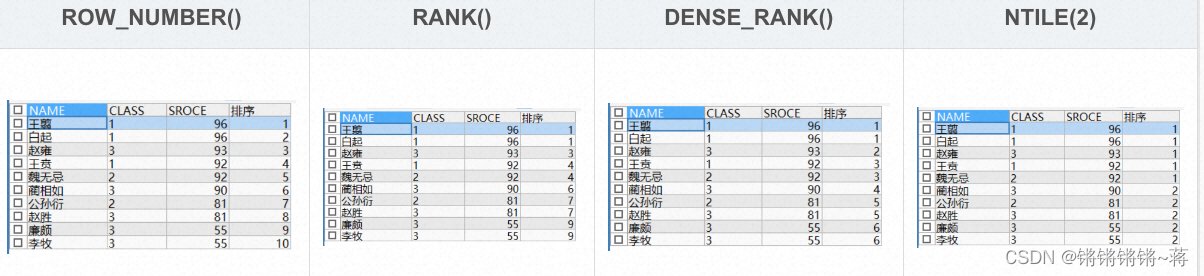
窗口函数-分组排序:row_number()、rank() 、dense_rank()、ntile()
窗口函数语法结构:
分析函数() over(partition by 分组列名 order by 排序列名 rows between 开始位置 and 结束位置)
开窗函数和聚合函数区别: 聚合函数会对一组值进行计算并返回一个值,常见的比如sum(),count(),ma…
Day4-Hive直播行业基础笔试题
Hive笔试题实战
短视频
题目一:计算各个视频的平均完播率
有用户-视频互动表tb_user_video_log: id uid video_id start_time end_time if_follow if_like if_retweet comment_id 1 101 2001 2021-10-01 10:00:00 2021-10-01 10:00:30 …

Hive 之 UDF 运用(包会的)
文章目录 UDF 是什么?reflect静态方法调用实例方法调用 自定义 UDF(GenericUDF)1.创建项目2.创建类继承 UDF3.数据类型判断4.编写业务逻辑5.定义函数描述信息6.打包与上传7.注册 UDF 函数并测试返回复杂的数据类型 UDF 是什么?
H…

【大数据】安装hive-3.1.2
1、上传HIVE包到/opt/software目录并解压到/opt/modules/ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/modules/ 2、修改路径 mv /opt/modules/apache-hive-3.1.2-bin/ /opt/modules/hive 3、将hIVE下的bin目录加入到/etc/profile中 export HIVE_HOME/opt/module…

HiveSQL如何生成连续日期剖析
HiveSQL如何生成连续日期剖析
情景假设: 有一结果表,表中有start_dt和end_dt两个字段,,想要根据开始和结束时间生成连续日期的多条数据,应该怎么做?直接上结果sql。(为了便于演示和测试这里通过…
hive metatool 使用说明
metatool 使用说明
usage: metatool-dryRun Perform a dry run ofupdateLocation changes.When runwith the dryRun optionupdateLocation changes aredisplayed but not persisted.dryRun is valid only with theupdateLocation option.-ex…

springboot在使用 Servlet API中提供的javax.servlet.Filter 过滤器 对请求参数 和 响应参数 进行获取并记录日志方案
不多说 直接上代码 第一步
package com.xxx.init.webFilter;import com.alibaba.fastjson.JSONObject;
import com.xxx.api.constant.CommonConstant;
import com.xxx.api.entities.log.OperationLog;
import com.xxx.init.utils.JwtHelper;
import com.xxx.init.utils.Reques…
hive窗口函数数据范围
window的内包括:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN…
【小贪】数据库常用操作:MySQL, HQL, Spark SQL
近期致力于总结科研或者工作中用到的主要技术栈,从技术原理到常用语法,这次查缺补漏当作我的小百科。主要技术包括: 数据库常用:MySQL, Hive SQL, Spark SQL 大数据处理常用:Pyspark, Pandas 图像处理常用:…
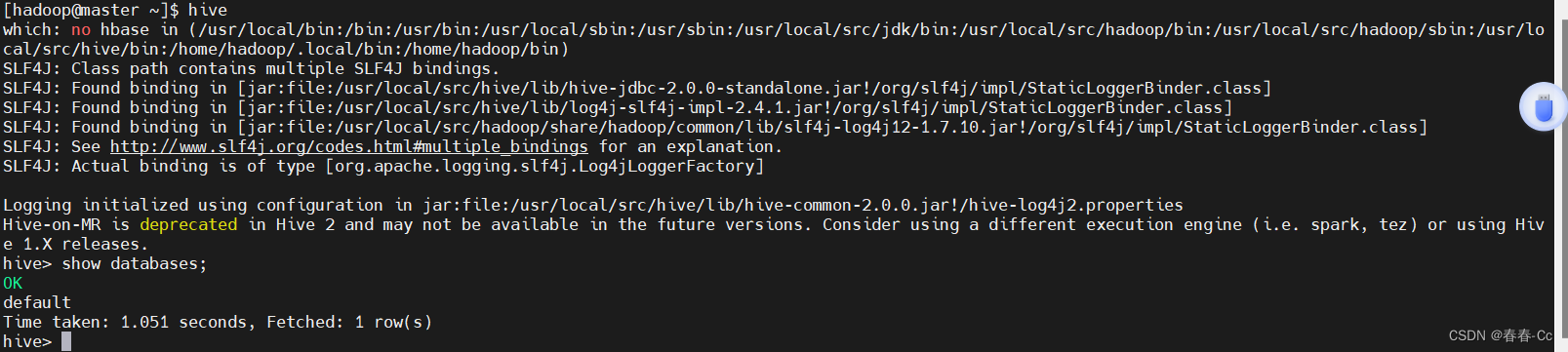
大数据之搭建Hive组件
声明:所有软件自行下载,并存放到统一目录中 1.Hive组件的安装配置
1.1实验环境
服务器集群3 个以上节点,节点间网络互通,各节点最低配置:双核 CPU、8GB 内存、100G 硬盘运行环境CentOS 7.4服务和组件完成前面章节实验…

Hive的简单学习一
一 Hive的搭建
1.1 准备好文件
1. apache-hive-3.1.2-bin.tar.gz
2.mysql-connector-java-8.0.29.jar
3.上传到linux中
1.2 安装
1.解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/soft/
2.重命名
mv apache-hive-3.1.2-bin hive-3.1.2
3.配置环境变量 …
数据操作——缺失值处理
缺失值处理
缺失值的处理思路
如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值 什么是缺失值 一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如…

cdh6.3.2的hive配udf
背景
大数据平台的租户要使用udf,他们用beeline连接, 意味着要通过hs2,但如果有多个hs2,各个hs2之间不能共享,需要先把文件传到hdfs,然后手动在各hs2上create function。之后就可以永久使用了,…
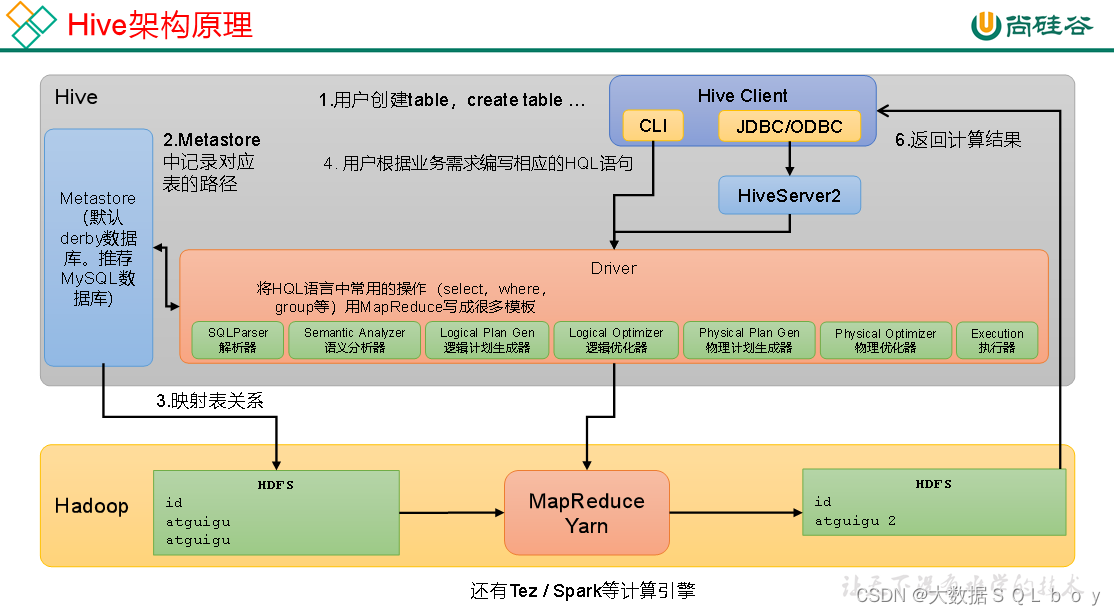
关于Hive架构原理,尚硅谷
最近学习hive 时候,在做一个实操案例,具体大概是这样子的: 我在dataGip里建了一个表,然后在hadoop集群创建一个文本文件里面存储了数据库表的数据信息,然后把他上传到hdfs后,dataGrip那个表也同步了我上传到…
Hive之set参数大全-12
指定是否尝试在 Hive Metastore 中使用直接 SQL 查询执行 DDL(数据定义语言)操作
hive.metastore.try.direct.sql.ddl 是 Hive 的配置参数之一,用于指定是否尝试在 Hive Metastore 中使用直接 SQL 查询执行 DDL(数据定义语言&…
HiveSQL题——array_contains函数
目录
一、原创文章被引用次数
0 问题描述
1 数据准备
2 数据分析
编辑
3 小结
二、学生退费人数
0 问题描述
1 数据准备
2 数据分析
3 小结 一、原创文章被引用次数
0 问题描述 求原创文章被引用的次数,注意本题不能用关联的形式求解。
1 数据准备 i…
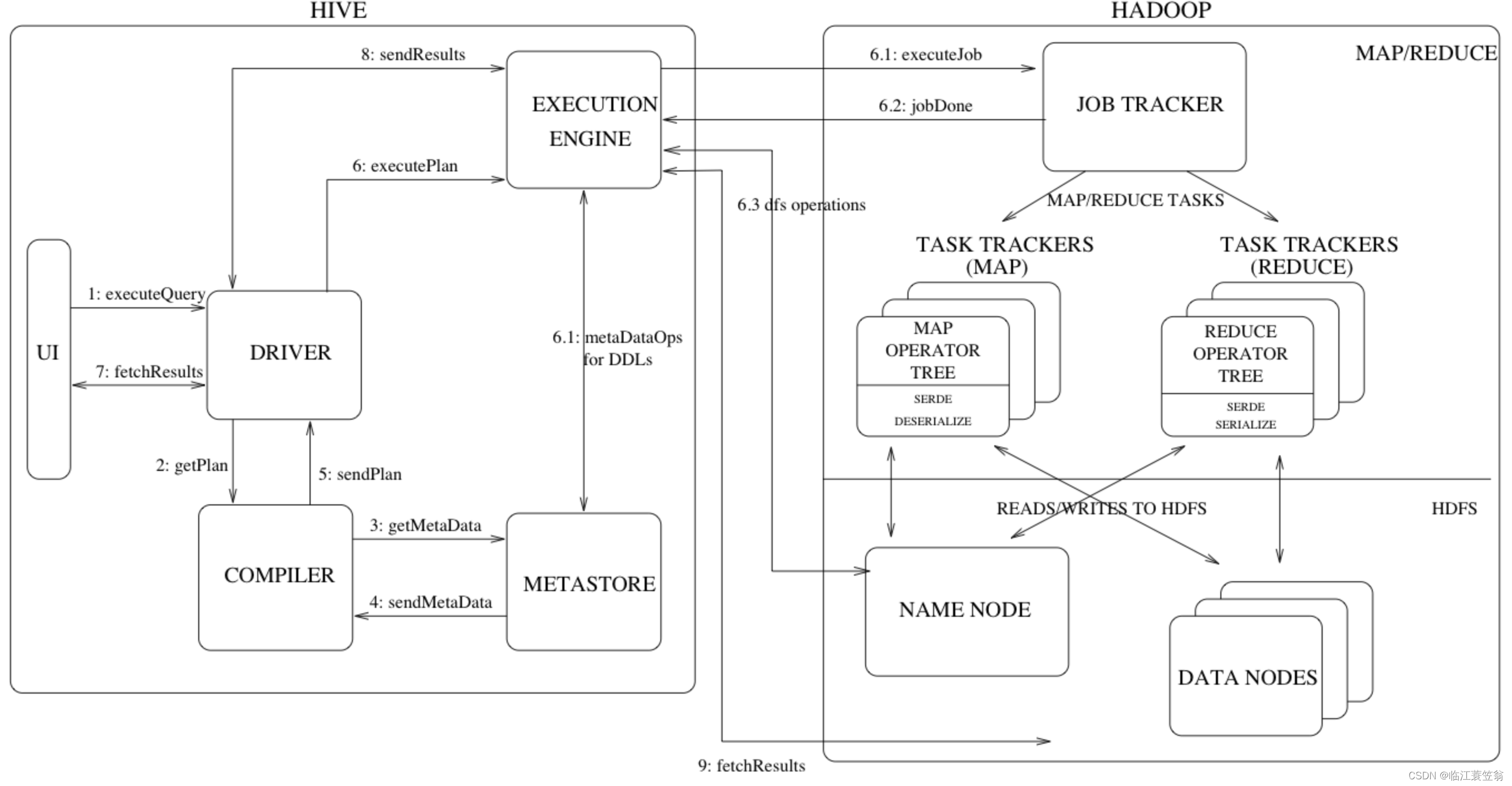
Hive-架构与设计
架构与设计 一、背景和起源二、框架概述1.设计特点 三、架构图1.UI交互层2.Driver驱动层3.Compiler4.Metastore5.Execution Engine 四、执行流程1.发起请求2.获取执行计划3.获取元数据4.返回元数据5.返回执行计划6.运行执行计划7.运行结果获取 五、数据模型1.DataBase数据库2.T…
Hive切换引擎(MR、Tez、Spark)
Hive切换引擎(MR、Tez、Spark)
1. MapReduce计算引擎(默认)
set hive.execution.enginemr;2. Tez引擎
set hive.execution.enginetez;1. Spark计算引擎
set hive.execution.enginespark;
拉链表的概念设计与实现
拉链表
一、概念
拉链表是针对数据仓库设计中表存储数据的方式而定义的,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。
用处: 解决持续增长且存在一定时间时间范围内重复的数据 场景࿱…
Hive超市零售案例
超市零售案例
一、部分数据展示
Fiskars 剪刀| 蓝色,61,中国,华东,杭州,用品,曾惠,2,浙江,办公用品,US-2019-1357144,130
GlobeWeis 搭扣信封| 红色,43,中国,西南,内江,信封,许安,2,四川,办公用品,CN-2019-1973789,125
Cardinal 孔加固材料| 回收,4,中国,西南,内江,装订机,许…

CentOS7 Hive2.3.8安装
CentOS7 Hive2.3.8 安装
建议从头用我的博客,如果用外教的文件到 一、9)步骤了,就用他的弄完,数据库不一样,在9步骤前还能继续看我的
一、 安装MySQL
0.0)查询mariadb,有就去0.1),没有就不管…
什么是大数据技术栈中的Hive和HBase等工具如何使用它们进行数据处理和分析呢。
什么是大数据技术栈中的Hive和HBase等工具如何使用它们进行数据处理和分析呢。
Hive和HBase是大数据技术栈中的两种重要工具,它们在数据处理和分析方面具有各自的特点和用途。
Hive:
Hive是一个数据仓库工具,用于进行大规模数据的汇总、查…
【错误处理】【Hive】【Spark】ERROR FileFormatwriter: Aborting job null.
问题背景
近日,使用 Spark 在读写 Hive 表时发生了报错:Aborting job null,如果怎么都使用不了那张表的话,大概率是那张表有脏数据,导致整张表无法正常使用。
ERROR FileFormatwriter: Aborting job null.解决方法
…
【hive】单节点搭建hadoop和hive
一、背景
需要使用hive远程debug,尝试使用无hadoop部署hive方式一直失败,无果,还是使用有hadoop方式。最终查看linux内存占用6GB,还在后台运行docker的mysql(bitnami/mysql:8.0),基本满意。
版本选择: &a…
Hive-生产常用操作-表操作和数据处理技巧-202404
hive语句操作 我这个只涉及到hive的对表的操作,包括建表,建分区表,加载数据,导出数据,查询数据,删除数据,插入数据,以及对hive分区表的操作,包括查看分区,添加…
hive-分桶-索引(初篇)
hvie - 分桶 创建分桶表之前要先设置hive允许进行强制分桶配置
set hive.enforce.bucketingtrue 创建分桶表
create table tmp_bucket(id int,name String) clustered by (id) into 4 buckets 建表 其中x表示分几个桶进行抽样,y表示间隔几个桶进行一次分桶…

hive-3.1.2分布式搭建与hive的三种交互方式
hive-3.1.2分布式搭建:
一、上传解压配置环境变量
在官网或者镜像站下载驱动包
华为云镜像站地址:
hive:Index of apache-local/hive/hive-3.1.2
mysql驱动包:Index of mysql-local/Downloads/Connector-J # 1、解压 tar -zx…

hive管理之ctl方式
hive管理之ctl方式 hivehive --service clictl命令行的命令 #清屏
Ctrl L
#或者
! clear
#查看数据仓库中的表
show tabls;
#查看数据仓库中的内置函数
show functions;#查看表的结构
desc表名
#查看hdfs上的文件
dfs -ls 目录
#执行操作系统的命令
!命令…
Hadoop、HDFS、Hive、Hbase区别及联系
Hadoop、HDFS、Hive和HBase是大数据生态系统中的关键组件,它们都是由Apache软件基金会管理的开源项目。下面将深入解析它们之间的区别和联系。
Hadoop
Hadoop是一个开源的分布式计算框架,它允许用户在普通硬件上构建可靠、可伸缩的分布式系统。Hadoop通常指的是整个生态系统…
大数据之 Hive 快速搭建的详细步骤
Hive hive 搭建三种模式: 内嵌模式本地模式远程模式内嵌模式
Hadoop 和 Hive 整合
修改 hadoop/etc/下的 core-site.xml:
<property><name>hadoop.proxyuser.root.hosts</name><value>*</value>
</property>
<property><nam…

一百七十七、Hive——海豚调度执行Hive的.sql文件
一、目的
对于Hive数仓,每一层的建库建表SQL语句都各自放在一个.sql文件里,然后用海豚调度执行一下Hive的.sql文件
二、实施步骤
(一)第一步,上传.sql文件到海豚调度器上 (二)第二步…
黑马在线教育数仓实战7
1. hive的相关的优化
1.1 hive的相关的函数(补充说明) if函数: 作用: 用于进行逻辑判断操作语法:
if(条件, true返回信息,false返回信息) 注意: if函数支持嵌套使用 nvl函数: 作用: null值替换函数格式:
nvl(T value, T default_value) COALESCE函数 作用: 非空查找函数:格式…
【大数据】Docker部署HMS(Hive Metastore Service)并使用Trino访问Minio
本文参考链接置顶: Presto使用Docker独立运行Hive Standalone Metastore管理MinIO(S3)_hive minio_BigDataToAI的博客-CSDN博客
一. 背景
团队要升级大数据架构,需要摒弃hadoop,底层使用Minio做存储,应用…
jsp生成验证码的代码
效果图: loginProcess.jsp <% page language"java" contentType"text/html; charsetUTF-8"pageEncoding"UTF-8"%><% String captcharequest.getParameter("captcha");%><% String captcha_session(String)s…
hive 命令记录(随时更新)
1.进入 hive 数据库: hive 2.查看hive中的所有数据库: show databases; 3.用 default 数据库 use default; 4.查看所有的表 show tables; 5.查询 book 表结构: desc book ; 6.查询 book 表数据 select * from book; 7.创建 shop 数据库 creat…
hive中常见参数优化总结
1.with as 的cte优化,一般开发中习惯使用with as方便阅读,但如果子查询结果在下游被多次引用,可以使用一定的参数优化手段减少表扫描次数 默认set hive.optimize.cte.materialize.threshold-1;不自动物化到内存,一般可以设置为 se…

hive报错:FAILED: NullPointerException null
发现问题
起因是我虚拟机的hive不管执行什么命令都报空指针异常的错误 我也在网上找了很多相关问题的资料,发现都不是我这个问题的解决方法,后来在hive官网上与hive 3.1.3版本相匹配的hadoop版本是3.x的版本,而我的hadoop版本还是2.7.2的版本…
Hive SQL 开发指南(一)数据类型及函数
在大数据领域,Hive SQL 是一种常用的查询语言,用于在 Hadoop上进行数据分析和处理。为了确保代码的可读性、维护性和性能,制定一套规范化的 Hive SQL 开发规范至关重要。本文将介绍 Hive SQL 的基础知识,并提供一些规范化的开发指…
Apache Paimon Hive引擎解析
HIve 引擎
Paimon 当前支持 Hive 的 3.1, 2.3, 2.2, 2.1 和 2.1-cdh-6.3 版本。
1.执行引擎
当使用Hive Read数据时,Paimon 支持 MR 和 Tez 引擎, 当使用Hive Write数据时,Paimon支持MR引擎,如果使用 beeline,需要重启hive clu…
JavaWeb Servlet详解
Servlet(Server Applet)服务器小程序,主要功能用于生成动态Web内容,Servlet就是一个接口,定义了Java类被浏览器访问到(Tomcat识别)的规则。 快速入门
创建Web项目,导入Servlet依赖坐标。
<dependency&…
Hive之set参数大全-18
指定在执行 Spark 上的动态分区裁剪时,用于评估分区数据大小的最大限制
在 Hive 中,hive.spark.dynamic.partition.pruning.max.data.size 是一个配置参数,用于指定在执行 Spark 上的动态分区裁剪时,用于评估分区数据大小的最大限…
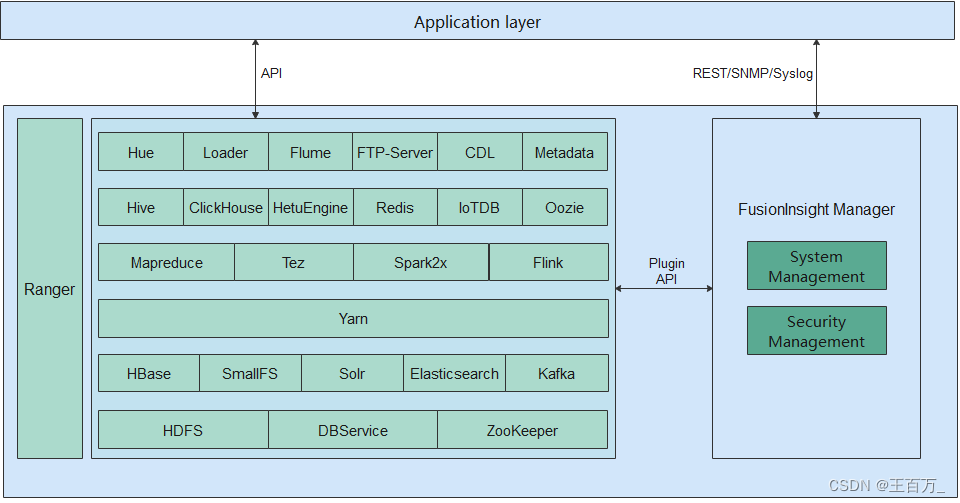
华为大数据平台-FusionInsight MRS
1、产品定位
(1) 关于华为的大数据平台,本人之前用过FusionInsight HD版本,近期也在用MRS结合MPP和治理平台做湖仓一体的开发,其实MRS是在HD基础上进行的升级、改版,MRS是集成一些开源的大数据组件,有自己的运维和安全…
flink - sink - hive
依赖
以下依赖均可以放到flink lib中,然后在pom中声明为provided
flink-connector-hive
flink对hive的核心依赖 <dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_${scala.version}</artifactId>…
【Hadoop】使用Metorikku框架读取hive数据统计分析写入mysql
一、定义作业文件 作业文件 该文件将包括输入源、输出目标和要执行的配置文件的位置,具体内容如下 metrics:- /user/xrx/qdb.yaml # 此位置为hdfs文件系统目录
inputs:
output:jdbc:connectionUrl: "jdbc:mysql://233.233.233.233:3306/sjjc"user: &quo…
Apache Hive(三)
一、Apache Hive
1、ETL数据清洗
数据问题 问题1:当前数据中,有一些数据的字段为空,不是合法数据
解决:where 过滤 问题2:需求中,需要统计每天、每个小时的消息量,但是数据中没有天和小时字段…

【hive Hadoop】踩坑 记录
【hive & Hadoop】踩坑 记录
平台部署知识 本文记录的配置 hive Hadoop 时可能会出现的问题以及解决方案。
目录 文章目录 【hive & Hadoop】踩坑 记录目录Hive记录hive 启动报错 Permission denied Unable to determine Hadoop version information.原因解释本次的解…
大数据开发(Hive面试真题-卷一)
大数据开发(Hive面试真题) 1、简要描述一下Hive表与数据库表之间有哪些区别?2、请解释一下Hive的优点和缺点。3、如何调优Hive查询性能?4、如何避免Hive中Join操作引起全表扫描?5、如何在Hive里删除一条记录࿱…
【大数据面试题】011 Hive的内部外部表
一步一个脚印,一天一道面试题
hive内部表和外部表的区别
空白内部表外部表定义表结构和数据有Hive管理表结构由Hive管理,数据可由其他导入删除表时表结构被删除,数据也被清除表结构被删除,但数据不变导入数据使用Hive SQL 导入将…
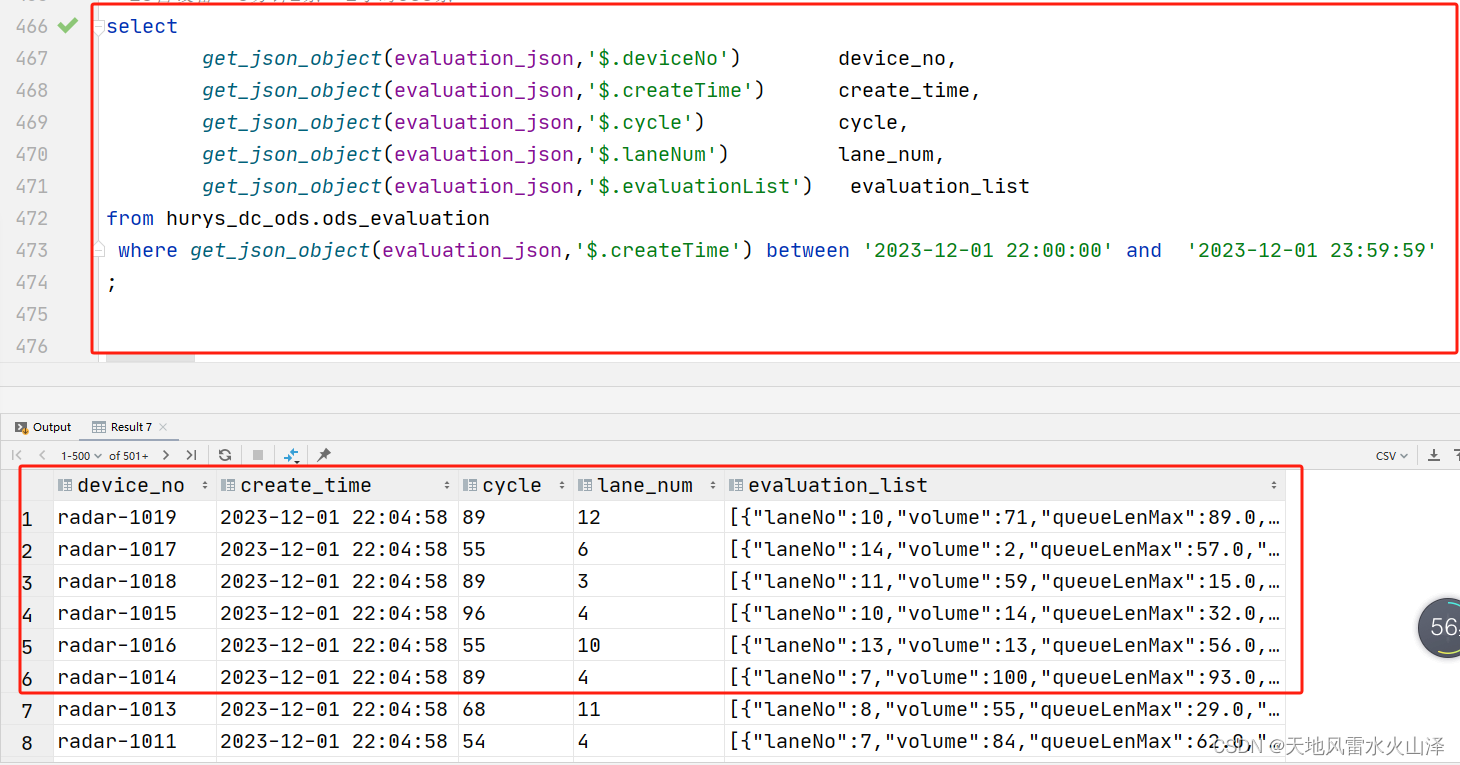
二百一十、Hive——Flume采集的JSON数据文件写入Hive的ODS层表后字段的数据残缺
一、目的
在用Flume把Kafka的数据采集写入Hive的ODS层表的HDFS文件路径后,发现HDFS文件中没问题,但是ODS层表中字段的数据却有问题,字段中的JSON数据不全
二、Hive处理JSON数据方式
(一)将Flume采集Kafka的JSON数据…
Hive增强的聚合、多维数据集、分组和汇总
Hive多维分析 1、多维分析概述2、GROUPING SETS多维分组3、GROUPING__ID函数4、ROLLUP与CUBE语法糖5、多维分析常见问题与解决春雨惊春清谷天,夏满芒夏暑相连;秋处露秋寒霜降,冬雪雪冬小大寒。今天是2023年的最后一个节气:大雪。大雪节气之后,全国气温显著下降,北方冷空气…
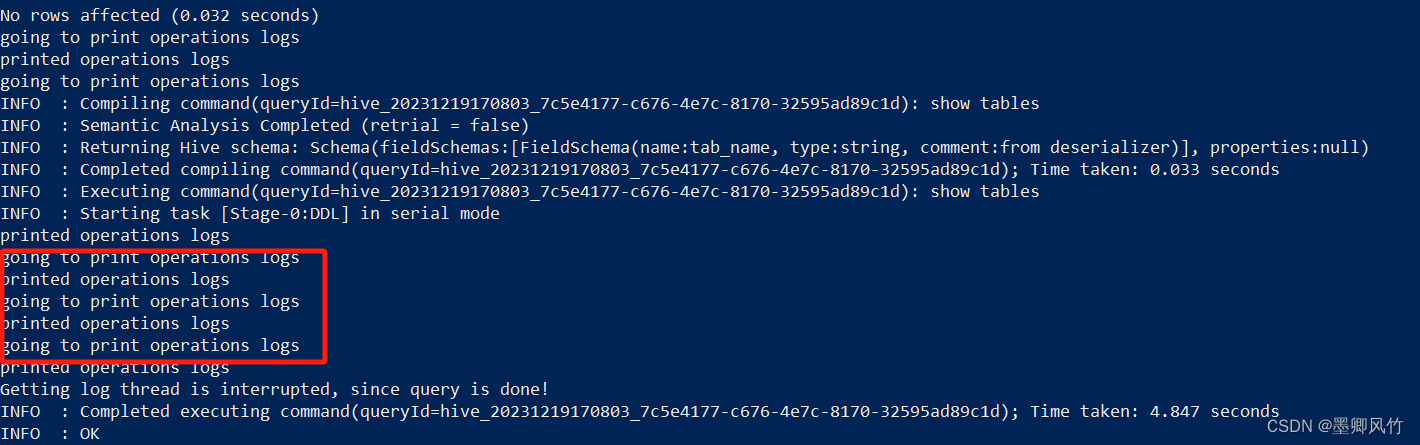
运行hive的beelin2时候going to print operations logs printed operations logs
运行hive的beelin2时候going to print operations logs printed operations logs 检查HiveServer2的配置文件hive-site.xml,确保以下属性被正确设置:
<property><name>hive.async.log.enabled</name><value>false</value>…

hive企业级调优策略之数据倾斜
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511 本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
数据倾斜概述
数据倾斜问题,通常是指参与计算的数据分布不均࿰…
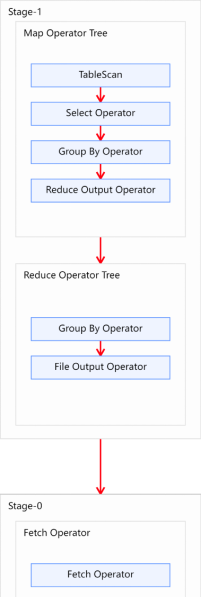
hive企业级调优策略之分组聚合优化
测试用表准备
hive企业级调优策略测试数据 (阿里网盘下载链接):https://www.alipan.com/s/xsqK6971Mrs
订单表(2000w条数据)
表结构 建表语句
drop table if exists order_detail;
create table order_detail(id string comment 订单id,user_id …
【Flink-Kafka-To-Hive】使用 Flink 实现 Kafka 数据写入 Hive
【Flink-Kafka-To-Hive】使用 Flink 实现 Kafka 数据写入 Hive 1)导入相关依赖2)代码实现2.1.resources2.1.1.appconfig.yml2.1.2.log4j.properties2.1.3.log4j2.xml2.1.4.flink_backup_local.yml 2.2.utils2.2.1.DBConn2.2.2.CommonUtils 2.3.conf2.3.1…
【pentaho】kettle读取Hive表不支持bigint和timstamp类型解决。
一、bigint类型
报错:
Unable to get value BigNumber(16) from database resultset显示kettle认为此应该是decimal类型(kettle中是TYPE_BIGNUMBER或称BigNumber),但实际hive数据库中是big类型。 修改kettle源码解决:
kettle中java.sql.Types到kettle…
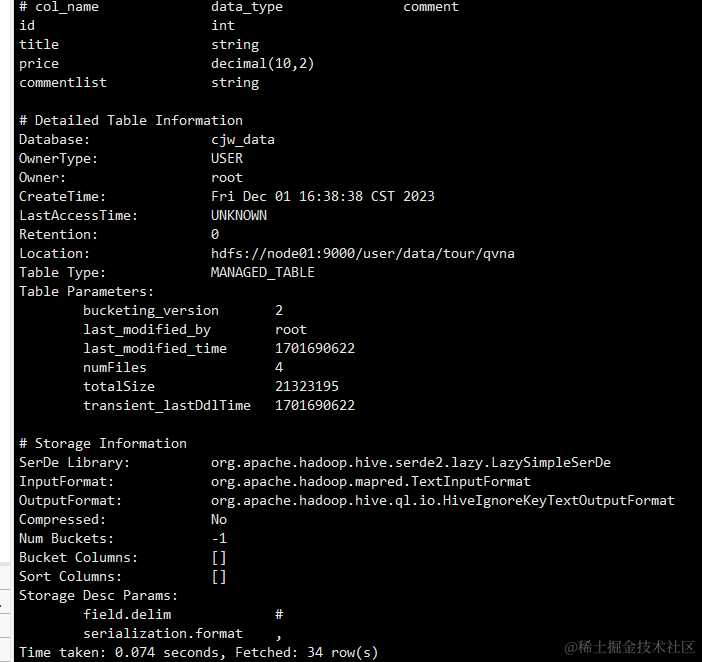
解决 Hive 外部表分隔符问题的实用指南
简介:
在使用 Hive 外部表时,分隔符设置不当可能导致数据导入和查询过程中的问题。本文将详细介绍如何解决在 Hive 外部表中正确设置分隔符的步骤。
问题描述:
在使用Hive外部表时,可能会遇到分隔符问题。这主要是因为Hive在读…

Hive文件存储与压缩
压缩和存储
1、 Hadoop压缩配置
1) MR支持的压缩编码
压缩格式工具算法文件扩展名是否可切分DEFAULT无DEFAULT.deflate否GzipgzipDEFAULT.gz否bzip2bzip2bzip2.bz2是LZOlzopLZO.lzo否LZ4无LZ4.lz4否Snappy无Snappy.snappy否
为了支持多种压缩/解压缩算法,Hadoop…
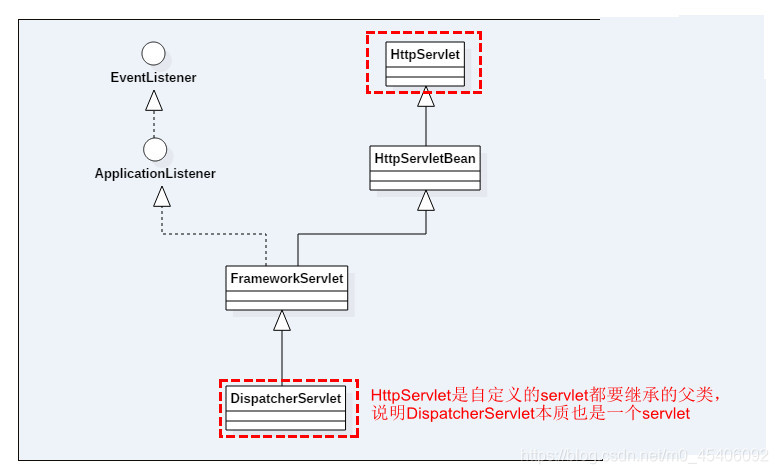
SpringMVC源码解析——DispatcherServlet初始化
在Spring中,ContextLoaderListener只是辅助功能,用于创建WebApplicationContext类型的实例,而真正的逻辑实现其实是在DispatcherServlet中进行的,DispatcherServlet是实现Servlet接口的实现类。Servlet是一个JAVA编写的程序&#…

Hive10_窗口函数
窗口函数(开窗函数)
1 相关函数说明
普通的聚合函数聚合的行集是组,开窗函数聚合的行集是窗口。因此,普通的聚合函数每组(Group by)只返回一个值,而开窗函数则可为窗口中的每行都返回一个值。简单理解,就是对查询的结果多出一列…

个人笔记:分布式大数据技术原理(二)构建在 Hadoop 框架之上的 Hive 与 Impala
有了 MapReduce,Tez 和 Spark 之后,程序员发现,MapReduce 的程序写起来真麻烦。他们希望简化这个过程。这就好比你有了汇编语言,虽然你几乎什么都能干了,但是你还是觉得繁琐。你希望有个更高层更抽象的语言层来描述算法…
Hive 的 安装与部署
目录 1 安装 MySql2 安装 Hive3 Hive 元数据配置到 MySql4 启动 Hive Hive 官网 1 安装 MySql 为什么需要安装 MySql? 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户端共享数据,如果想多窗口操作…
超市账单管理系统产品数据新增Servlet实现
超市账单管理系统产品数据新增Servlet实现
package com.test.controller;
import java.io.IOException; import java.util.List;
import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import ja…
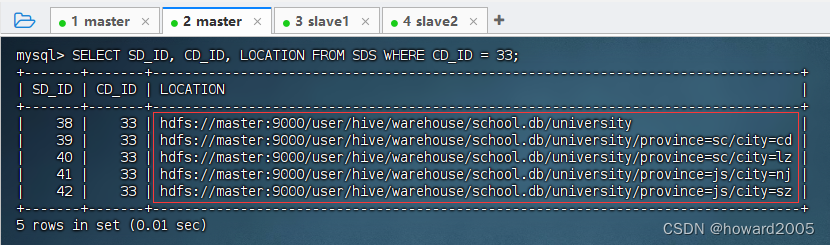
Hive分区表实战 - 多分区字段
文章目录 一、实战概述二、实战步骤(一)创建学校数据库(二)创建省市分区的大学表(三)在本地创建数据文件1、创建四川成都学校数据文件2、创建四川泸州学校数据文件3、创建江苏南京学校数据文件4、创建江苏苏…
Hive数学函数讲解
Hive 是一个基于 Hadoop 的数据仓库工具,它支持类似于 SQL 的查询语言 HiveQL,并且提供了许多内建的数学函数来处理数值数据。下面我将逐一讲解您提到的这些数学函数,并提供一些使用案例和注意事项。 ROUND() 功能:四舍五入到指定…
Hive分组取满足某字段的记录
在SQL分组后取第一条记录中介绍了分组取满足条件的第一条记录的方法,现在业务上面临如此需求:在做公司流程监控时,要求监控每个流程每个节点的用时情况。其中有个字段isend可以判断流程是否结束,但是流程结束后可能还会有操作&…
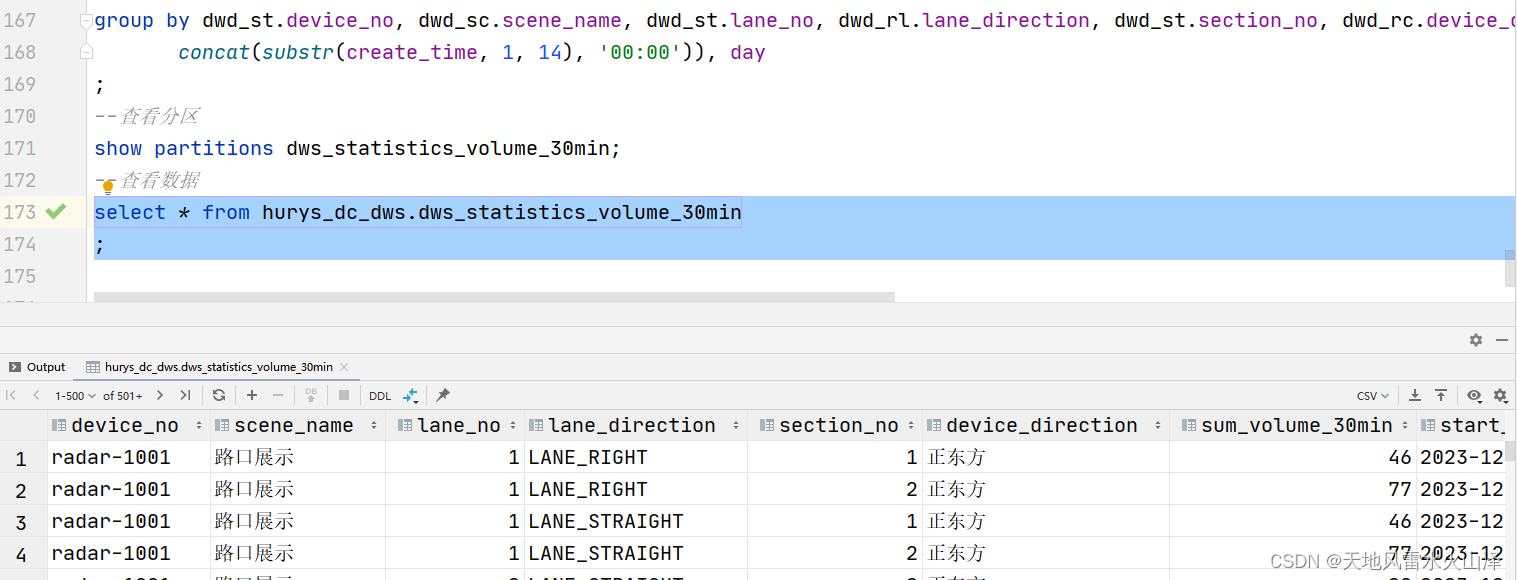
二百二十一、HiveSQL报错:return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
一、目的
在运行HiveSQL时,执行报错
tatement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask 二、在yarn上查看任务报错
The required MAP capability is more than the supported max container capability in t…
Hive优化的21种方案
1、Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:SELECT * FROM employees;在这种情况下,Hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。
在hive-default.x…

paimon取消hive转filesystem
目录 概述实践关键配置spark sql 结束 概述
公司上一版本保留了 hive ,此版优化升级后,取消 hive。
实践
关键配置 同步数据时,配置如下,将形成两个库 # ods库
CREATE CATALOG paimon WITH (type paimon,warehouse hdfs:///d…
详解数据库、Hive以及Hadoop之间的关系
1.数据库:
数据库是一个用于存储和管理数据的系统。数据库管理系统(DBMS)是用于管理数据库的软件。数据库使用表和字段的结构来组织和存储数据。关系型数据库是最常见的数据库类型,使用SQL(Structured Query Language…

Hive SQL必刷练习题:连续问题 间断连续(*****)
问题描述:
1) 连续问题:找出连续三天(或者连续几天的啥啥啥)。
2) 间断连续:统计各用户连续登录最长天数,间断一天也算连续,比如1、3、4、6也算登陆了6天
问题分析&am…
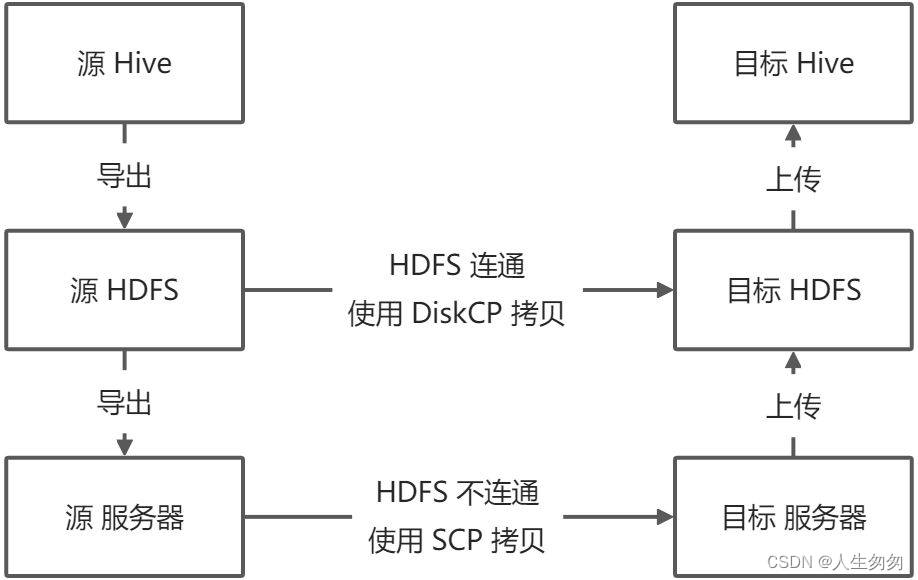
Hive 数据迁移与备份
迁移类型
同时迁移表及其数据(使用import和export)
迁移步骤
将表和数据从 Hive 导出到 HDFS将表和数据从 HDFS 导出到本地服务器将表和数据从本地服务器复制到目标服务器将表和数据从目标服务器上传到目标 HDFS将表和数据从目标 HDFS 上传到目标 Hiv…

大数据毕业设计选题推荐-智慧小区大数据平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨ 个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。 ☑文末获取源码☑ 精彩专栏推荐⬇⬇⬇ Java项目 Python…
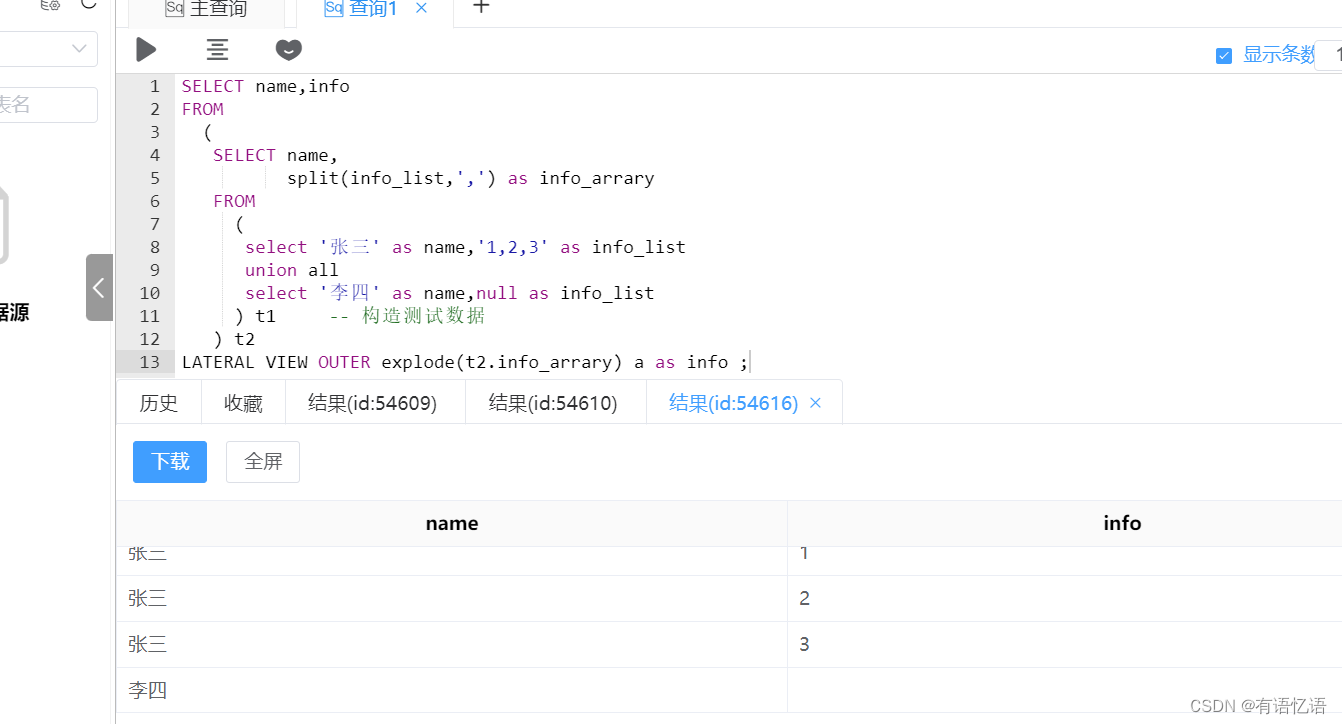
Hive Lateral View explode列为空时导致数据异常丢失
一、问题描述
日常工作中我们经常会遇到一些非结构化数据,因此常常会将Lateral View 结合explode使用,达到将非结构化数据转化成结构化数据的目的,但是该方法对应explode的内容是有非null限制的,否则就有可能造成数据缺失。
SE…
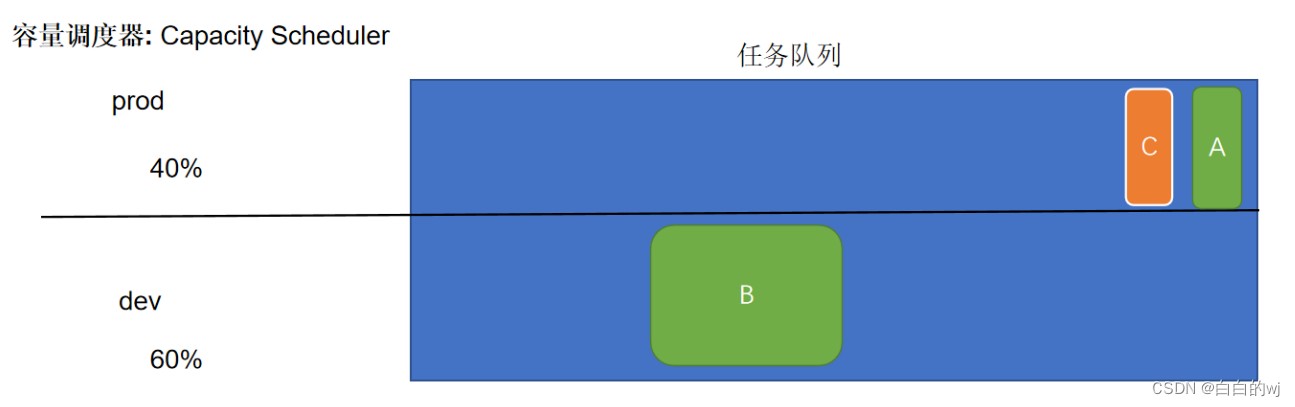
2023.11.18 Hadoop之 YARN
1.简介
Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度。支持多个数据处理框架&…
第二章Iceberg简介
Iceberg数据类型
Iceberg数据类型是在Apache Iceberg这一开源大数据表格管理库中定义的一系列数据格式,它们用于描述和存储表格中的数据。Iceberg旨在提供可扩展且可靠的方式来管理海量数据表格,因此其数据类型设计也充分考虑了大数据处理的需求。
以下…
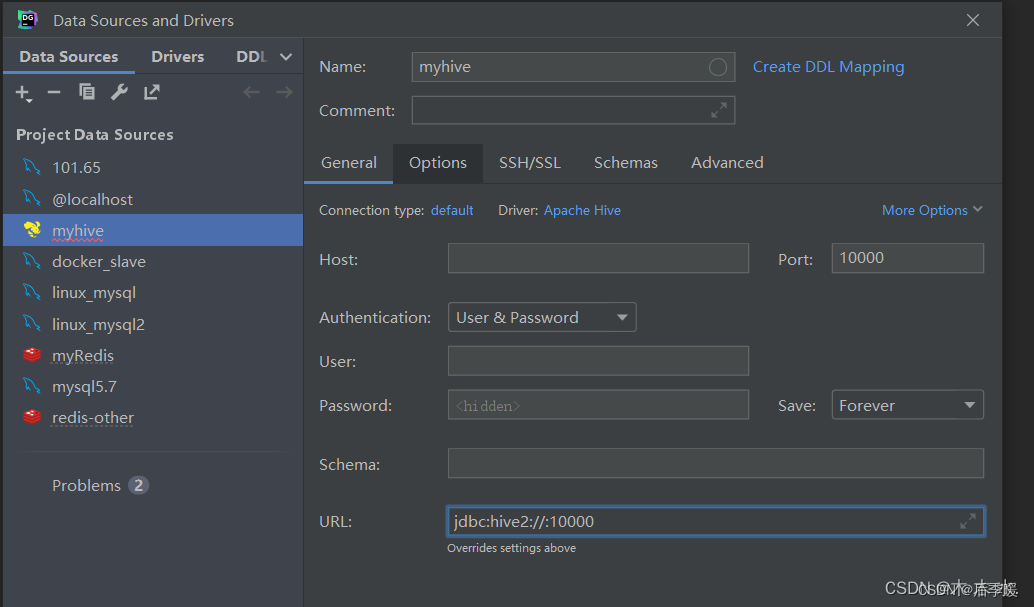
Flink GateWay、HiveServer2 和 hive on spark
Flink SQL Gateway简介
从官网的资料可以知道Flink SQL Gateway是一个服务,这个服务支持多个客户端并发的从远程提交任务。Flink SQL Gateway使任务的提交、元数据的查询、在线数据分析变得更简单。
Flink SQL Gateway的架构如下图,它由插件化的Endpoi…

JavaWeb里的控制器Servlet,过滤器Filter,监听器Listener
文章目录 简介控制器servlet控制器(Controller)概述控制器的工作原理控制器的生命周期控制器的种类控制器的应用场景示例代码Servlet控制器示例Spring MVC控制器示例 总结 过滤器filter过滤器(Filter)概述过滤器的工作原理过滤器的生命周期过滤器的链式调用过滤器的应用场景示例…

Hive SQL必刷练习题:排列组合问题【通过join不等式】
排列组合问题【通过join不等式】 这种问题,就是数学的排列不等式,一个队伍只能和其余队伍比一次,不能重复
方法1:可以直接通过join,最后on是一个不等式【排列组合问题的解决方式】
方法2:也可以是提前多加…
【大数据技术】Hive基本原理以及使用教程
Hive 的基本原理: 元数据存储:Hive 使用元数据来描述数据存储在Hadoop分布式存储系统中的方式。元数据包含表的schema(列名、数据类型等)、表的分区、表的位置等信息,这些元数据通常存储在关系型数据库中,如…
hive sql多表练习
hive sql多表练习
准备原始数据集 学生表 student.csv 讲师表 teacher.csv 课程表 course.csv 分数表 score.csv 学生表 student.csv
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,1995-04-30,男
004,刘德华,1998-08-28,男
005,唐国强,1993-09-10,男
006,陈道…

hive sql 行列转换 开窗函数 炸裂函数
hive sql 行列转换 开窗函数 炸裂函数
准备原始数据集 学生表 student.csv 讲师表 teacher.csv 课程表 course.csv 分数表 score.csv 员工表 emp.csv 雇员表 employee.csv 电影表 movie.txt 学生表 student.csv
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,…

Java Day16 Servlet(二)
Servlet 1、继承结构2、ServletConfig对象3 、ServletContext3.1 获得路径3.2 域对象相关API 4、HttpServletRequest4.1 获得请求行和请求头相关api4.2 请求中键值对相关api 1、继承结构
顶级Servlet接口
//初始化void init(ServletConfig var1) throws ServletException;
//…
Hive在虚拟机中的部署
安装Mysql数据库
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yum安装Mysql
yum -y install mysql-community-server
# 启动Mysql设置开机启动…
ubuntu-server部署hive-part2-安装hadoop
参照
https://blog.csdn.net/qq_41946216/article/details/134345137 操作系统版本:ubuntu-server-22.04.3
虚拟机:virtualbox7.0
安装hadoop 下载上传
下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/ 以root用…

入门用Hive构建数据仓库
在当今数据爆炸的时代,构建高效的数据仓库是企业实现数据驱动决策的关键。Apache Hive 是一个基于 Hadoop 的数据仓库工具,可以轻松地进行数据存储、查询和分析。本文将介绍什么是 Hive、为什么选择 Hive 构建数据仓库、如何搭建 Hive 环境以及如何在 Hi…

Day5-Hive的结构和优化、数据文件存储格式
Hive
窗口函数
案例 需求:连续三天登陆的用户数据 步骤: -- 建表
create table logins (username string,log_date string
) row format delimited fields terminated by ;
-- 加载数据
load data local inpath /opt/hive_data/login into table log…
spark-hive连接操作流程、踩坑及解决方法
文章目录 1 简介2 版本匹配3 spark hive支持版本源码编译3.1 spark-src下载3.2 maven换源3.3 spark编译 4 hive 安装与mysql-metastore配置4.1 mysql下载安装4.1.1 为mysql设置系统环境变量4.1.2 初次登陆更改root身份密码4.1.3 安装后直接更改密码 4.2 hive初始化4.2.1 编写hi…
day30_servlet
今日内容 零、复习昨日 一、接收请求 二、处理响应 三、综合案例 零、复习昨日 画图, 请求处理的完整流程(javaweb开发流程) 零、注解改造 WebServlet注解,相当于是在web.xml中配置的servlet映射 Servlet类
package com.qf.servlet;import javax.servlet.ServletException;
im…
iceberg学习笔记(2)—— 与Hive集成
前置知识: 1.了解hadoop基础知识,并能够搭建hadoop集群 2.了解hive基础知识 3.Iceberg学习笔记(1)—— 基础知识-CSDN博客 可以参考: Hadoop基础入门(1):框架概述及集群环境搭建_TH…
【Hive】with 语法 vs cache table 语法
语法分别如下: cache table table_name as (select ... from ...
)with table_name as (select ... from ...
)需要注意,with语法只相当于一个视图,并不会将数据缓存;如果要将数据缓存,需要使用cache table语法。 参考…
如何构建Hive数据仓库Hive 、数据仓库的存储方式 以及hive数据的导入导出
什么是Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化数据映射为一张表。 hive支持使用sql语法对存储的表进行查询 (本质上是把sql转成mapreduce的任务执行)
Hive有三个特点:
hive所存储的数据是放在HDFS文件系统中的h…
性能比较:in和exists
当在Hive SQL中使用NOT IN和NOT EXISTS时,性能差异主要取决于底层数据的组织方式、数据量大小、索引的使用情况以及具体查询的复杂程度。下面是对这两种方法的性能分析:
1. NOT IN:- 工作原理:NOT IN子查询会逐个比较主查询中的值…

hive sql无法停止
排查流程
hive任务停止是调用org.apache.hive.jdbc.HiveStatement的close()方法实现的
其底层是委托给org.apache.hive.service.cli.thrift.TCLIService.Iface客户端实例来实现。
同时,通过JDK动态代理为其织入了synchronized同步机制:其底层是委托给…
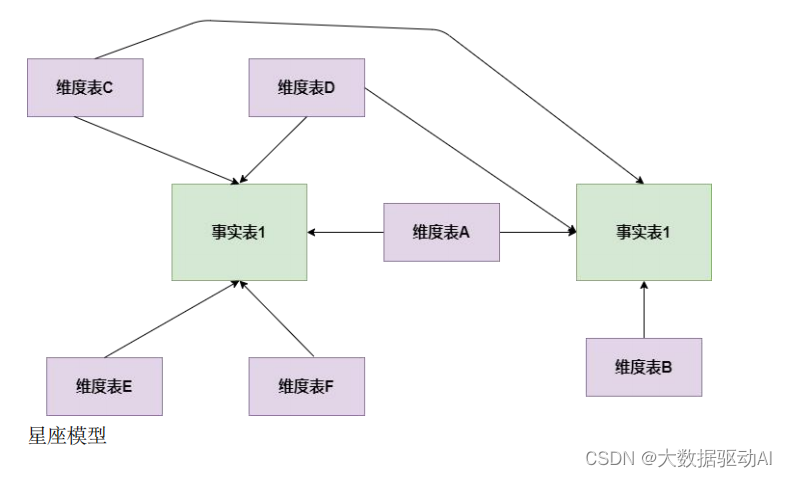
Hive函数 EXPLODE 和 POSEXPLODE 使用示例
Hive函数 EXPLODE 和 POSEXPLODE 使用示例
在Hive中, explode 和 posexplode 是两个常用的函数,用于处理复杂数据类型,如数组和map。以下是它们的具体应用示例和介绍:
1. 创建了一个名为 students 的表,包括 group_n…
![[Spark SQL]Spark SQL读取Kudu,写入Hive](https://img-blog.csdnimg.cn/06e551a7a0d54922bff511126b300587.png)
[Spark SQL]Spark SQL读取Kudu,写入Hive
SparkUnit
Function:用于获取Spark Session
package com.example.unitlimport org.apache.spark.sql.SparkSessionobject SparkUnit {def getLocal(appName: String): SparkSession {SparkSession.builder().appName(appName).master("local[*]").getO…
Hive数据仓库行转列
查了很多资料发现网上很多文章都是转发和抄袭,有些问题。这里分享一个自己项目中使用的行转列例子,供大家参考。代码如下:
SELECTmy_id,nm_cd_map[A] AS my_cd_a,nm_cd_map[B] AS my_cd_b,nm_cd_map[C] AS my_cd_c,nm_num_map[A] AS my_num_…

java 通过 IMetaStoreClient 取 hive 元数据信息
1 pom.xml配置,要与服务器上的版本要一致,并将hive-site.xml 文件放入resources文件夹中
<dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency>&l…

二百二十三、Kettle——从Hive增量导入到ClickHouse(根据day字段判断)
一、目的
需要用Kettle从Hive的DWS层库表数据增量同步到ClickHouse的ADS层库表中,不过这次的增量判断字段是day字段,不像之前的create_time字段
因为day字段需要转换类型,而 create_time字段字段不需要转换类型,因此两者的Kettl…

Hive【内部表、外部表、临时表、分区表、分桶表】【总结】
目录 Hive的物种表结构特性 一、内部表
建表
使用场景 二、外部表
建表:关键词【EXTERNAL】
场景:
外部表与内部表可互相转换 三、临时表
建表 临时表横向对比编辑
四、分区表
建表:关键字【PARTITIONED BY】
场景:
五、分桶表
…
hive中如何取交集并集和差集
交集 要获取两个表的交集,你可以使用INNER JOIN或者JOIN:
SELECT *
FROM table1
JOIN table2 ON table1.column_name table2.column_name;也可以使用 INTERSECT 关键字
SELECT * FROM table1
INTERSECT
SELECT * FROM table2;并集 要获取两个表的并集…
Apache Paimon 使用之Creating Catalogs
Paimon Catalog 目前支持两种类型的metastores:
filesystem metastore (default),在文件系统中存储元数据和表文件。 hive metastore,将metadata存储在Hive metastore中。用户可以直接从Hive访问表。
1.使用 Filesystem Metastore 创建 Cat…
Hive表使用ORC格式和SNAPPY压缩建表语句示例
Hive表使用ORC格式和SNAPPY压缩建表语句示例
下面是一个sql示例:
-- 创建数据库
CREATE DATABASE IF NOT EXISTS mydatabase;-- 使用数据库
USE mydatabase;-- 创建分区表,使用ORC文件格式,采用Snappy压缩算法
CREATE TABLE IF NOT EXISTS …

Hive Thrift Server
hive-site.xml配置文件
<property><name>hive.server2.thrift.bind.host</name><value>node1</value>
</property>hive.server2.thrift.bind.host: This property determines the host address to which the HiveServer2 Thrift service …
hive 数据库用户权限授权
CREATE ROLE cz20240304;
GRANT cz20240304_role TO USER cz20240304;
grant select on table secured_t to role cz20240304_role;hive用户角色授权官网超链接
Hive招聘数据分析
招聘数据分析
一、部分数据展示
鞍山易升科技有限公司,大专,1年工作经验,数据分析师,1,6000,少于50人,计算机软件,鞍山,辽宁
河北展源新能源科技有限公司,大专,3-4年工作经验,数据分析师,2,7000,150-500人,新能源,保定,河北
河北奥润顺达窗业有限公司,本科,1年工作经验,数据分…
Hive中增量插入的处理
增量数据采集,目前实现的方式是hive中按某个字段创建分区表, insert override的时候where语句带上对应的增量过滤条件。 我一般选取日期字段ETL_DATE。
hive建立分区表,hql如下:
CREATE TABLE IF NOT EXISTS product_sell( cate…
【Sqoop教程】Sqoop学习教程以相关资料
当使用Sqoop进行数据传输时,以下是更详细的步骤和示例:
步骤1:安装和配置Sqoop
下载Sqoop并解压缩到指定目录。配置sqoop-env-template.sh文件,设置JAVA_HOME、HADOOP_COMMON_HOME等环境变量,并另存为sqoop-env.sh。…
superset连接Apache Spark SQL(hive)过程中的各种报错解决
superset连接数据库官方文档:Installing Database Drivers | Superset
我们用的是Apache Spark SQL,所以首先需要安装下pyhive #命令既下载了pyhive也下载了它所依赖的其他安装包
pip install pyhive#多个命令也可下载
pip install sasl
pip install th…
Hive中UNION ALL和UNION的区别
1.概述 Hive官方提供了一种联合查询的语法,原名为Union Syntax,用于联合两个表的记录进行查询,此处的联合和join是不同的,join是将两个表的字段拼接到一起,而union是将两个表的记录拼接在一起。 换言之, jo…
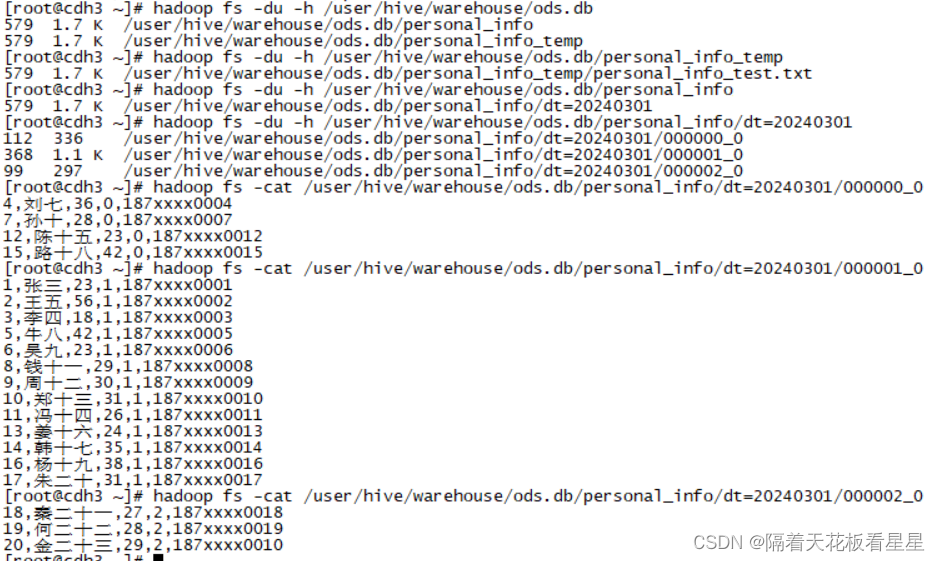
substr函数踩坑
##hive和impala的substr函数比对
###在hive中substr函数使用 select substr(name,0,5) from bd_test; 结果:12345 select substr(name,1,5) from bd_test; 结果:12345
###impala中substr函数使用 select substr(name,0,5) from bd_test; 结果ÿ…

大数据平台 hive 部署
大数据平台 hive 部署
平台部署知识 文章讲解了 hive 的安装与部署 需要 Hadoop 以及 MySQL。
目录 文章目录 大数据平台 hive 部署目录前期准备解压 hive 包配置 hive 的环境变量解决 jar 冲突 内嵌模式部署修改 hive-env.sh 文件初始化元数据库 使用 derby启动 HDFS 和 hiv…
HIVE 大数据学习
介绍 Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模式,称为Hive查询语言(HQL),用于访问…
數據集成平台:datax將MySQL數據同步到hive(全部列和指定列)
1.數據集成平台:將MySQL數據同步到hive(全部和指定列)
python環境:2.7版本py腳本 傳參: source_database:數據庫 source_table:表 source_columns:列 source_splitPk:sp…
基于docker 配置hadoop-hive-spark-zeppelin环境进行大数据项目的开发
转载于: 基于docker的spark-hadoop分布式集群之一: 环境搭建 - Fordestiny - 博客园 (cnblogs.com) ----------------------------------------------------------
如有侵权请私信,看到私信后会立即删除...
------------------------------…
hive表中的数据导出 多种方法详细说明
文章中对hive表中的数据导出 多种方法目录 方式一:insert导出 方式二:hive shell 命令导出
方式三:export导出到HDFS上 目标:
将hive表中的数据导出到其他任意目录,例如linux本地磁盘,例如hd…

深入理解Hive:探索不同的表类型及其应用场景
文章目录 1. 引言2. Hive表类型概览2.1 按照数据存储位置2.2 按照数据管理方式2.3 按照查询优化2.4 按照数据的临时性和持久性 3. 写在最后 1. 引言
在大数据时代,Hive作为一种数据仓库工具,为我们提供了强大的数据存储和查询能力。了解Hive的不同表类型…
hive内置函数--floor,ceil,rand三种取整函数
文中三种取整函数操作目录:
一、向下取整函数: floor
二、向上取整函数: ceil
三、取随机数函数: rand 一、向下取整函数: floor
语法: floor(double a)
返回值: BIGINT
说明:返回等于或者小于该doubl…
Hive集合函数 collect_set 和 collect_list 使用示例
Hive集合函数 collect_set 和 collect_list 使用示例 在Hive中, collect_set 和 collect_list 是用于收集数据并将其存储为集合的聚合 函数。以下是它们的语法:
1. collect_set(expression)- expression : 要收集的数据表达式。collect_set 函数用于将…
Hive连接函数 concat 和 concat_ws 使用示例
Hive连接函数 concat 和 concat_ws 使用示例 concat 函数的语法: concat(str1, str2, …) :将多个字符串连接成一个字符串,中间使用空格进行分隔。 concat_ws 函数的语法: concat_ws(sep, str1, str2, …) :将多个字符…
Hive中的CONCAT、CONCAT_WS与COLLECT_SET函数
1.CONCAT与CONCAT_WS函数
1.1 CONCAT函数
-- concat(str1, str2, ... strN) - returns the concatenation of str1, str2, ... strN or concat(bin1, bin2, ... binN) - returns the concatenation of bytes in binary data bin1, bin2, ... binN
Returns NULL if any argum…

Apache Hive的基本使用语法(二)
Hive SQL操作
7、修改表
表重命名
alter table score4 rename to score5;修改表属性值
# 修改内外表属性
ALTER TABLE table_name SET TBLPROPERTIES("EXTERNAL""TRUE");
# 修改表注释
ALTER TABLE table_name SET TBLPROPERTIES (comment new_commen…
Hive中的explode函数、posexplode函数与later view函数
1.概述 在离线数仓处理通过HQL业务数据时,经常会遇到行转列或者列转行之类的操作,就像concat_ws之类的函数被广泛使用,今天这个也是经常要使用的拓展方法。
2.explode函数
2.1 函数语法
-- explode(a) - separates the elements of array …
hive行转列函数stack(int n, v_1, v_2, ..., v_k)
用stack()函数时,参数中的键值对应按照一对列名和列值进行排使用列
stack(int n, v_1, v_2, ..., v_k)
功能:把k列数据转换成n行,k/n列,其中n必须是正整数,后面的v_1到v_k必须是元素,不能是列名。&#x…
flink重温笔记(十七): flinkSQL 顶层 API ——SQLClient 及流批一体化
Flink学习笔记 前言:今天是学习 flink 的第 17 天啦!学习了 flinkSQL 的客户端工具 flinkSQL-client,主要是解决大数据领域数据计算避免频繁提交jar包,而是简单编写sql即可测试数据,文章中主要结合 hive,即…
使用Hive对HDFS中数据查询的优点
目录 摘要一、Hive是什么二、HDFS是什么三、Hive与HDFS的关系四、什么是HiveQL五、什么是mapreduce六、Hive如何将查询转为mapreduce任务七、Hadoop生态系统中的高性能引擎八、使用Hadoop的优点 摘要
Hadoop生态系统中包含了多个关键组件,如Hive、HDFS、MapReduce等…
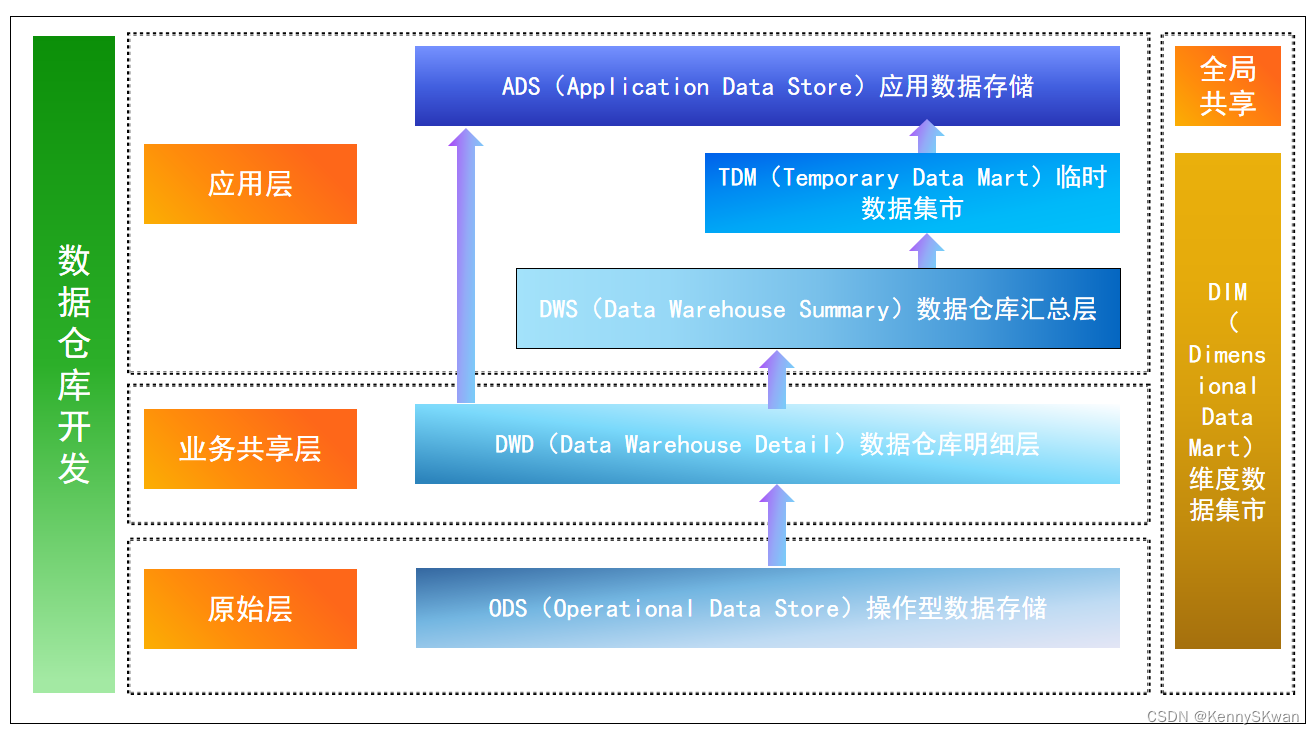
大数据设计为何要分层,行业常规设计会有几层数据
大数据设计通常采用分层结构的原因是为了提高数据管理的效率、降低系统复杂度、增强数据质量和可维护性。这种分层结构能够将数据按照不同的处理和应用需求进行分类和管理,从而更好地满足不同层次的数据处理和分析需求。行业常规设计中,数据通常按照以下…
Hive窗口函数面试题(带答案版本)
Hive笔试题实战
短视频
题目一:计算各个视频的平均完播率
有用户-视频互动表tb_user_video_log: id uid video_id start_time end_time if_follow if_like if_retweet comment_id 1 101 2001 2021-10-01 10:00:00 2021-10-01 10:00:30 …
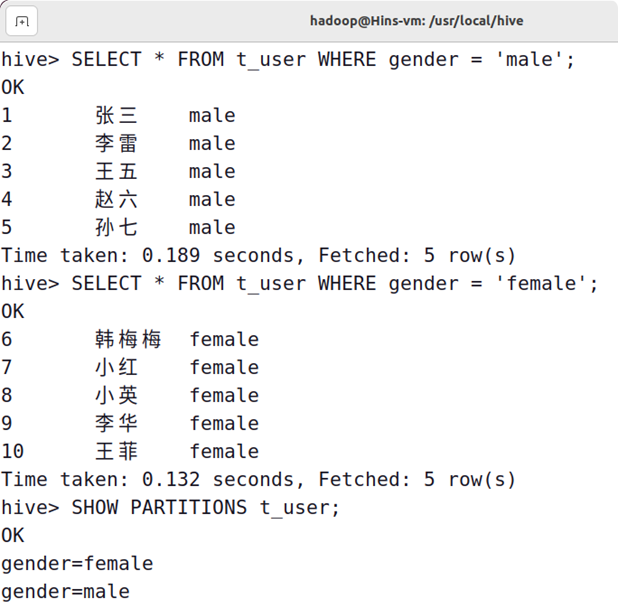
【Hadoop大数据技术】——Hive数据仓库(学习笔记)
📖 前言: Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但…
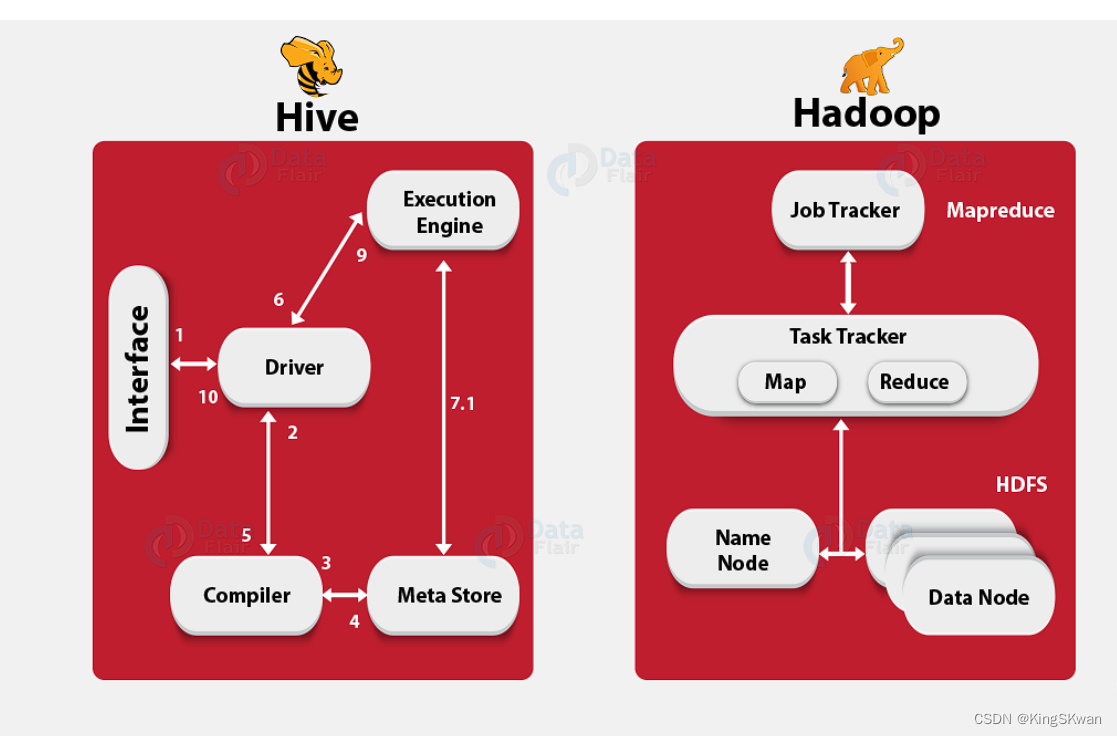
深入理解 Hadoop 上的 Hive 查询执行流程
在 Hadoop 生态系统中,Hive 是一个重要的分支,它构建在 Hadoop 之上,提供了一个开源的数据仓库系统。它的主要功能是查询和分析存储在 Hadoop 文件中的大型数据集,包括结构化和半结构化数据。Hive 在数据查询、分析和汇总方面发挥…
面试题1(京东)之HiveSql --- 难度:入门初级
第1题
有如下的用户访问数据
userIdvisitDatevisitCountu012017/1/215u022017/1/236u032017/1/228u042017/1/203u012017/1/236u012017/2/218u022017/1/236u012017/2/224
要求使用SQL统计出每个用户的累积访问次数,如下表所示:
用户id月份小计累积u01…

Linux(centos7)部署hive
前提环境: 已部署完hadoop(HDFS 、MapReduce 、YARN)
1、安装元数据服务MySQL 切换root用户
# 更新密钥
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysqL-2022
# 安装Mysql yum库
rpm -Uvh http://repo.mysql.com//mysql57-community-release-el7-7.noarch.rpm
# yu…
Hive常用函数_16个时间日期处理
在Hive中,常用的时间处理函数包括但不限于以下几种:
1. current_date(): 返回当前日期,不包含时间部分
SELECT current_date();
-- Output: 2024-09-152. current_timestamp(): 返回当前时间戳,包含日期和时间部分
SELECT curr…
数仓-hive DDL (带你手敲秒懂hive三种常见分区)
hive 数仓DDL 分区
分区是将表的数据以分区字段的值作为目录去存储
---> 减少磁盘IO, 方便数据管理
静态分区 创建外表同时指定静态分区字段 create table if not exists table_name(id int,name string)partitioned by (day string,h string); …
hive逗号分割行列转换
select * from ( select back_receipt_nos,order_no,reject_no from ods_one.ods_us_wms_reject_order_match_all_d where order_no 10150501385980001 ) t1 lateral view explode(split(t1.back_receipt_nos, ,)) t as back_receipt_no where 1 1;
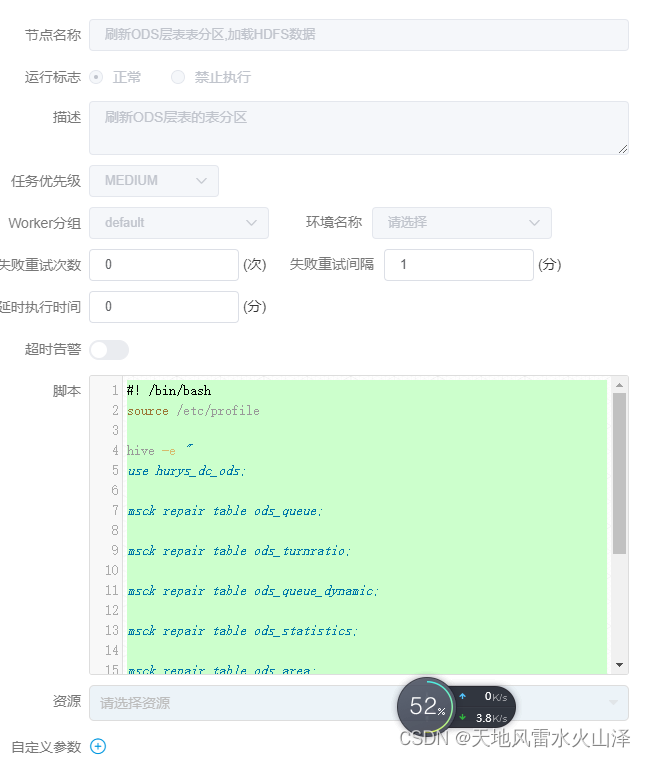
二百二十九、离线数仓——离线数仓Hive从Kafka、MySQL到ClickHouse的完整开发流程
一、目的
为了整理离线数仓开发的全流程,算是温故知新吧
离线数仓的数据源是Kafka和MySQL数据库,Kafka存业务数据,MySQL存维度数据
采集工具是Kettle和Flume,Flume采集Kafka数据,Kettle采集MySQL数据
离线数仓是Hi…
Spark面试整理-什么是Spark SQL?
Spark SQL是Apache Spark的一个模块,用于处理结构化数据。它提供了一个编程抽象,称为DataFrame,并作为分布式SQL查询引擎的作用。DataFrame是组织成命名列的数据集。通过将Spark SQL与Spark集成,用户可以使用SQL或DataFrame API在Spark程序中查询结构化数据。这种集成使得S…
提升物流效率,快递平台实战总结与分享
随着电商行业的蓬勃发展,物流配送服务变得愈发重要。快递平台作为连接电商企业和消费者的桥梁,扮演着至关重要的角色。本篇博客将分享快递平台实战经验,总结关键要点,帮助物流从业者提升物流效率、优化服务质量。
### 快递平台实…
Hive SchemaTool 命令详解
Hive schematool 是 hive 自带的管理 schema 的相关工具。
列出详细说明
schematool -help直接输入 schematool 或者schematool -help 输出结果如下:
usage: schemaTool-alterCatalog <arg> Alter a catalog, requires--catalogLocation an…

深入浅出Hive性能优化策略
我们将从基础的HiveQL优化讲起,涵盖数据存储格式选择、数据模型设计、查询执行计划优化等多个方面。会的直接滑到最后看代码和语法。
目录
引言
Hive架构概览
示例1:创建表并加载数据
示例2:优化查询
Hive查询优化
1. 选择适当的文件格…

数据仓库核心:揭秘事实表与维度表的角色与区别
文章目录 1. 引言2. 基本概念2.1 事实表(Fact Table)2.2 维度表(Dimension Table) 3. 两者关系4. 为什么要有做区分5. 写在最后 1. 引言
前篇我们深入探讨了Hive数据仓库中的表类型,包括内部表、外部表、分区表、桶表…
多进程数据库不适合作为hive的元数据库
简介
“今天发现一个比较奇怪的现象,因为博主不熟悉mysql,所以在安装hive的使用了postgresql作为hive的元数据库,在测试几个连接工具对hive进行链接,后面再测试的时候发现链接不上了,并且报错日志如下:” …

Hive借助java反射解决User-agent编码乱码问题
一、需求背景
在截取到浏览器user-agent,并想保存入数据库中,经查询发现展示的为编码后的结果。
现需要经过url解码过程,将解码后的结果保存进数据库,那么有几种实现方式。
二、问题解决
1、百度:url在线解码工具 …
Hive的相关概念——架构、数据存储、读写文件机制
目录
一、架构及组件介绍
1.1 Hive整体架构
1.2 Hive组件
1.3 Hive数据模型(Data Model)
1.3.1 Databases
1.3.2 Tables
1.3.3 Partitions
1.3.4 Buckets
二、Hive读写文件机制
2.1 SerDe 作用
2.2 Hive读写文件流程
2.2.1 读取文件的过程
…
【Hadoop】解决Hive创建内部表失败:正确配置事务管理器
谁让你我静似月 只能在心里默念 檐下燕替我飞到你身边 谁让你我静似月 各自孤单错弄弦 风吹的帘落见月人不眠 🎵 周笔畅《谁动了我的琴弦》 在使用Apache Hive进行数据处理时,创建内部表是一项常见的操作,它允许用户在H…
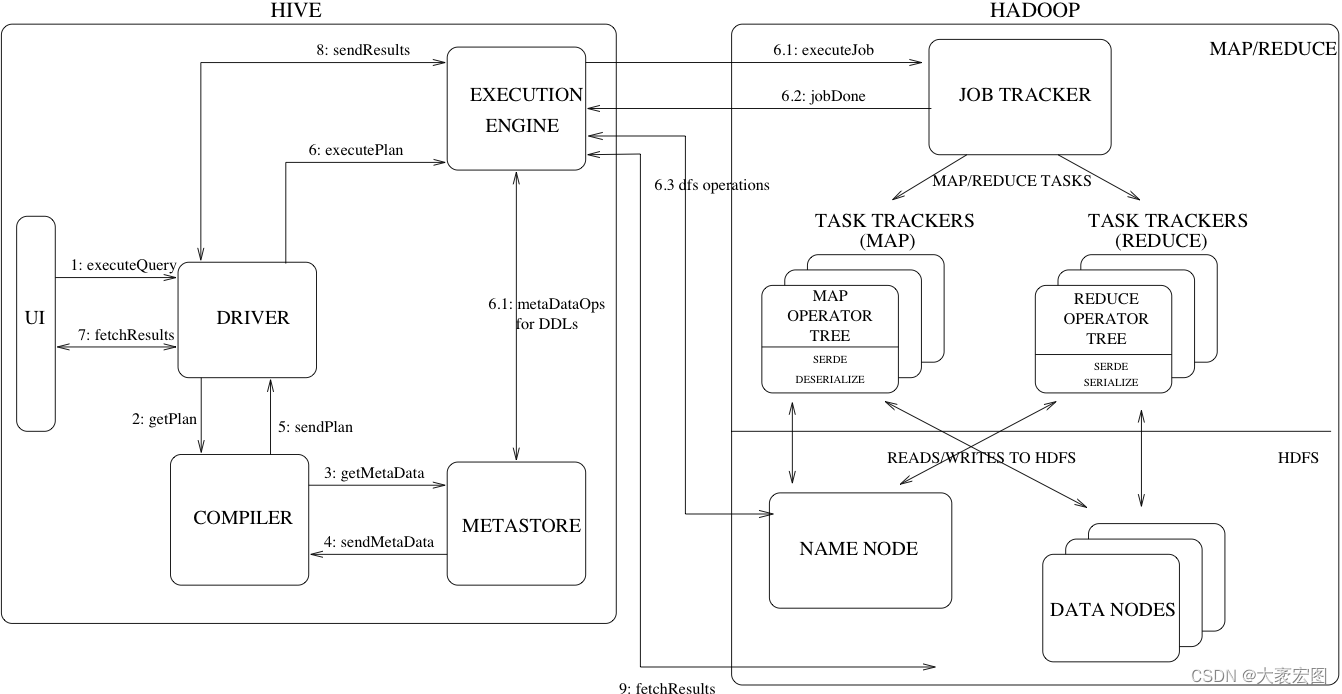
Hive:数据仓库利器
1. 简介
Hive是一个基于Hadoop的开源数据仓库工具,可以用来存储、查询和分析大规模数据。Hive使用SQL-like的HiveQL语言来查询数据,并将其结果存储在Hadoop的文件系统中。
2. 基本概念
介绍 Hive 的核心概念,例如表、分区、桶、HQL 等。
…

Hive案例分析之消费数据
Hive案例分析之消费数据
部分数据展示
1.customer_details
customer_id,first_name,last_name,email,gender,address,country,language,job,credit_type,credit_no
1,Spencer,Raffeorty,sraffeorty0dropbox.com,Male,9274 Lyons Court,China,Khmer Safety,Technician III,jc…

Spark 搭建模式(本地、伪分布、全分布模式)
Spark搭建模式
Standalone模式
环境搭建
1.伪分布式
#1.进入$SPARK_HOME/conf
[rootmaster ~] cd $SPARK_HOME/conf#2.拷贝spark-env.sh.template
[rootmaster conf] cp spark-env.sh.template spark-env.sh
[rootmaster conf] vi spark-env.sh# Options for the daemons u…
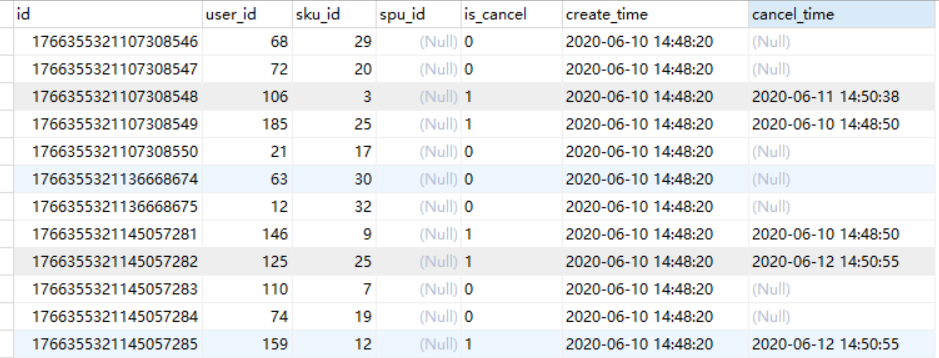
离线数仓(八)【DWD 层开发】
前言 1、DWD 层开发
DWD层设计要点:
(1)DWD层的设计依据是维度建模理论(主体是事务型事实表(选择业务过程 -> 声明粒度 -> 确定维度 -> 确定事实),另外两种周期型快照事实表和累积型…
hive授予指定用户特定权限及beeline使用
背景:因业务需要,需要使用beeline对hive数据进行查询,但是又不希望该用户可以查询所有的数据,希望有一个新用户bb给他指定的库表权限。
解决方案:
1.赋权语句,使用hive管理员用户在终端输入hive进入命令控…

基于Hive大数据分析springboot为后端以及vue为前端的的民宿系
标题基于Hive大数据分析springboot为后端以及vue为前端的的民宿系
本文介绍了如何利用Hive进行大数据分析,并结合Spring Boot和Vue构建了一个民宿管理系统。该民民宿管理系统包含用户和管理员登陆注册的功能,发布下架酒店信息,模糊搜索,酒店详情信息展示,收藏以及对收藏的…

基于Hive的天气情况大数据分析系统(通过hive进行大数据分析将分析的数据通过sqoop导入到mysql,通过Django基于mysql的数据做可视化)
基于Hive的天气情况大数据分析系统(通过hive进行大数据分析将分析的数据通过sqoop导入到mysql,通过Django基于mysql的数据做可视化) Hive介绍: Hive是建立在Hadoop之上的数据仓库基础架构,它提供了类似于SQL的语言&…
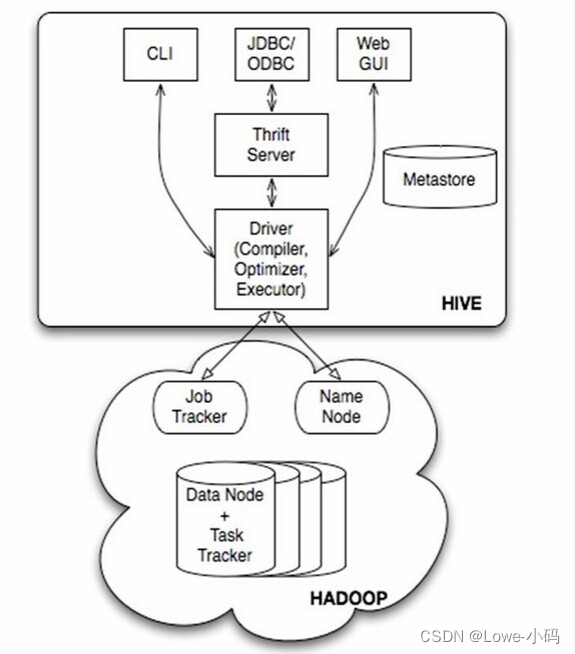
大数据-hive,初步了解
1. Hive是什么
Hive是基于Hadoop的数据仓库解决方案。由于Hadoop本身在数据存储和计算方面有很好的可扩展性和高容错性,因此使用Hive构建的数据仓库也秉承了这些特性。
简单来说,Hive就是在Hadoop上架了一层SQL接口,可以将SQL翻译成MapRedu…
Hive常用函数_20个字符串处理
Hive常用函数_20个字符串处理 以下是Hive中常用的字符串处理函数,可用于执行各种字符串处理转换操作。 1. CONCAT():将多个字符串连接在一起。
SELECT CONCAT(Hello, World);
-- Output: HelloWorld2. SUBSTR():从字符串中提取子字符串&…
Day1 - Hive基础知识
Hive
简介
概述
Hive是由Facobook开发的后来贡献给了Apache的一套用于进行数据仓库管理的工具,使用类SQL语言来对分布式文件系统中的PB级别的数据来进行读写、管理以及分析Hive基于Hadoop来使用的,底层的默认计算引擎使用的是MapReduce。Hive利用类SQ…
【Servlet】Servlet入门
文章目录 一、介绍二、入门案例导入servlet-api的解决办法 一、介绍
概念:server applet,即:运行在服务器端的小程序
Servlet就是一个接口,定义了Java类被浏览器访问到(tomcat识别)的规则。
将来我们定义…
《大数据项目实战》分析及可视化
《大数据项目实战》分析及可视化实训步骤:
一、数据分析
1. 数据分析–需求环境
已安装部署Hadoop伪分布或分布式集群环境Linux系统中已安装部署Mysql数据库已安装部署Hive数据仓库
2. 启动Hadoop和历史服务
主节点上启动Hadoop
[roothadoop01 ~]# start-all.…
【Hadoop】 在Spark-Shell中删除Hive内部表和外部表的数据
你跨越万水千山 只一眼便似万年 梦里繁花也搁浅 相逢不记前缘 再聚凭何怀缅 东风也叹路途远 命运缠丝线 情不愿消散 恩怨皆亏欠 世间踏遍 难抵人生初相见 🎵 刘美麟《初见》 Apache Spark是一个强大的分布式数据处理框架,它提供了对…
大数据开发(Hive面试真题-卷三)
大数据开发(Hive面试真题) 1、Hive的文件存储格式都有哪些?2、Hive的count的用法?3、Hive得union和unionall的区别?4、Hive的join操作原理,left join、right join、inner join、outer join的异同࿱…
Hive实现查询左表有右表没有的记录
工作中遇到这样一个场景,业务逻辑是:如果一个主体发生了某一问题,就不再统计该主体的其他问题。 思路:首先想到的方法就是not in方法,但是Hive并不不支持。那么使用left join对两个表进行连接,右表主键为空…
Hive函数 date_format 使用示例总结
Hive函数 date_format 使用示例总结
Hive函数 date_format 用于将日期或时间戳格式化为指定的输出格式。假设要对时间 2024-03-18 18:18:18.008 进行格式化,以下是一些常见的时间提取格式,这些格式可以在 date_format 函数中使用:
1. yyyy …
Hive 使用 LIMIT 指定偏移量返回数据
Hive 使用 LIMIT 指定偏移量返回数据 LIMIT 子句可用于限制SELECT语句返回的行数。 LIMIT 接受一个或两个数字参数,这两个参数必须都是非负整数常量。第一个参数指定要返回的第一行的偏移量(从Hive 2.0.0开始),第二个参数指定要返…
Hive自定义UpperGenericUDF函数
Hive自定义UpperGenericUDF函数 当创建自定义函数时,推荐使用 GenericUDF 类而不是 UDF 类,因为 GenericUDF 提供了更灵活的功能和更好的性能。以下是使用 GenericUDF 类创建自定义函数的步骤: 编写Java函数逻辑:编写继承自 Gener…
hive 3.1.3 搭建
部署准备
一台机器,一个mysql数据库 可以访问的 web 页面全部绑定了 127.0.0.1。禁止外部访问,需要访问可以使用 nginx 反向代理 增加鉴权之后暴露出去。如果不需要可以替换 IP 。
安装
Hive 安装包准备
hive 下载页面
配置文件修改
配置文件位于 …
hive sql实现查找商品表名称中包含敏感词的商品
背景
用户上传的商品表一般会包含商品名称,由于这些商品名称是用户自己起的,里面可能包含了敏感词,需要通过sql找出来哪些商品的商品名称包含了敏感词汇
hive sql实现查找商品表名称中包含敏感词的商品
实现思路:
1.商品表和敏…
Hive自定义GenericUDTF函数官网示例
Hive自定义GenericUDTF函数官网示例 原文翻译:可以通过扩展 GenericUDTF 抽象类并实现initialize、process以及可能的close方法来创建自定义UDTF。initialize方法由Hive调用,通知UDTF应该期望的参数类型。然后,UDTF必须返回一个对象检查器&am…
hive SQL 移位、运算符、REGEXP正则等常用函数
orderflag & shiftleft(1,14) shiftleft(1,14) SQL中使用的运算符号详解_sql中各种符号-CSDN博客 Hive函数_hive shift-CSDN博客
(内建函数(类型排序)_云原生大数据计算服务 MaxCompute(MaxCompute)-阿里云帮助中心)
hive语法树分析,判断 sql语句中有没有select *
pom依赖参考以下博文java 通过 IMetaStoreClient 取 hive 元数据信息-CSDN博客1 节点处理器类
import lombok.Getter;
import org.apache.hadoop.hive.ql.lib.Dispatcher;
import org.apache.hadoop.hive.ql.lib.Node;
import org.apache.hadoop.hive.ql.parse.ASTNode;
impor…
大数据开发-订单表数据清洗案例
回顾上节简单介绍了什么是数据仓库以及数仓数据同步工具,下面简单弄个demo 文章目录 数据开发ODS层DWD层DWSapp层拉链表数据开发
ODS层
## 建表
create database if not exists ods_mall;
create external table if not exists ods_mall.ods_user_order(
order_id bigint,
…
伪分布式部署Hive
文章目录 1 Hadoop 伪分布式安装1 Hive下载2 Hive配置3 安装MySQL JDBC连接器4 连接Hive CLI4.1 初始化数据库4.2 连接Hive 1 Hadoop 伪分布式安装
假设我们已经安装好hadoop伪分布式
1 Hive下载
Hive下载地址
2 Hive配置
Hive伪分布式需要在conf文件夹下修改两个文件&…
Hive常用函数 之 数值处理
Hive常用函数 之 数值处理 以下是Hive中常用的数值处理函数,可用于执行各种数学运算和数值转换操作。 1. ABS():返回一个数的绝对值。
SELECT ABS(-10);
-- 输出: 102. ROUND():对一个数进行四舍五入。
SELECT ROUND(10.56);
-- 输出: 113.…
Hive正则表达式使用
当在Hive中使用正则表达式时,可以使用三个函数来执行不同的操作:
1. regexp
regexp函数用于测试一个字符串是否匹配给定的正则表达式。它的语法如下:
regexp(string source, string pattern)source: 要测试的源字符串。pattern: 要匹配的正则表达式模式。如果源字符串与指…
Hive自定义GenericUDF函数
Hive自定义GenericUDF函数 当创建自定义函数时,推荐使用 GenericUDF 类而不是 UDF 类,因为 GenericUDF 提供了更灵活的功能和更好的性能。以下是使用 GenericUDF 类创建自定义函数的步骤: 编写Java函数逻辑:编写继承自 GenericUDF…

【Hive】HIVE运行卡死没反应
Hive运行卡死 再次强调 hive:小兄弟,没想到吧,咱可不是随便的人。😄 那么,这次又遇见了hadoop问题,问题描述是这样的。
hive> insert into test values(1, nucty, 男);
Query ID atguigu_202403241754…

基于nodejs+vue基于hive旅游数据的分析与应用python-flask-django-php
系统阐述的是使用基于hive旅游数据的分析与应用系统,对于nodejs结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了express框架和MySql数据库技术搭建系统的整体架构。利用…
使用Apache Hive进行大数据分析的关键配置详解
Apache Hive是一个在Hadoop上构建的数据仓库工具,它允许用户通过类似SQL的语言(HiveQL)进行数据查询和分析。在使用Hive进行大数据分析之前,需要配置一些重要的参数以确保系统正常运行并满足特定需求。本文将重点介绍Apache Hive的…
用DataGrip连接hive时报错:User: root is not allowed to impersonate plck5,解决方法
你可以尝试关闭主机校验 修改hive安装目录下conf/hive-site.xml,将hive.server2.enable.doAs设置成false
<property><name>hive.server2.enable.doAs</name><value>false</value><description>Setting this property to true will have H…
总结:HDFS+YARN+HIVE
总结:HDFSYARNHIVE 第一章 Hello大数据&分布式Part1 数据导论一. 数据二. 数据的价值 Part2 大数据诞生Part3 大数据概述一. 什么是大数据二.大数据特征三.大数据的核心工作 Part4 大数据软件生态一. 大数据软件生态 Part5 Apache Hadoop 概述一. Hadoop概念 第二章 分布式…

Hive详解(一篇文章让你彻底学会Hive)
简介
概述
Hive是由Facebook(脸书)开发的后来贡献给了Apache的一套数据仓库管理工具,针对海量的结构化数据提供了读、写和管理的功能。 图-1 Hive图标
Hive本身是基于Hadoop,提供了类SQL(Hive Query Language,简称为HQL)语言来操作HDFS上的…
Spark重温笔记(五):SparkSQL进阶操作——迭代计算,开窗函数,结合多种数据源,UDF自定义函数
Spark学习笔记 前言:今天是温习 Spark 的第 5 天啦!主要梳理了 SparkSQL 的进阶操作,包括spark结合hive做离线数仓,以及结合mysql,dataframe,以及最为核心的迭代计算逻辑-udf函数等,以及演示了几…
Hive-技术补充-ANTLR语法编写
一、导读
我们学习一门语言,或外语或编程语言,是不是都是要先学语法,想想这些语言有哪些相同点 1、中文、英语、日语......是不是都有 主谓宾 的规则 2、c、java、python、js......是不是都有 数据类型 、循环 等语法或数据结构
虽然人们在…

开源大数据集群部署(十八)Hive 安装部署
作者:櫰木
1 创建hive Kerberos主体
bash /root/bigdata/getkeytabs.sh /etc/security/keytab/hive.keytab hive2 安装
在hd1.dtstack.com主机root权限下操作:
解压包
[roothd3.dtstack.com software]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C …
Hive学习---3、DML(Data Manipulation Language)数据操作、查询
1、DML(Data Manipulation Language)数据操作
1.1 Load
load语句可将文件导入到Hive表中 1、语法
load data [local] inpath filepath [overwrite] into table tablename [partition(partcol1val1,partcol2val2...)]2、关键字说明 (1&…

Spark 6:Spark SQL DataFrame
SparkSQL 是Spark的一个模块, 用于处理海量结构化数据。 SparkSQL是用于处理大规模结构化数据的计算引擎 SparkSQL在企业中广泛使用,并性能极好 SparkSQL:使用简单、API统一、兼容HIVE、支持标准化JDBC和ODBC连接 SparkSQL 2014年正式发布,当…
【Hive SQL 每日一题】环比增长率、环比增长率、复合增长率
文章目录 环比增长率同比增长率复合增长率测试数据需求说明需求实现 环比增长率
环比增长率是指两个相邻时段之间某种指标的增长率。通常来说,环比增长率是比较两个连续时间段内某项数据的增长量大小的百分比。
环比增长率反映了两个相邻时间段内某种经济指标的变…
[AIGC 大数据基础]hive浅谈
在当今大数据时代,随着数据量的不断增大,如何高效地处理和分析海量数据已经成为一个重要的挑战。为了满足这一需求,Hive应运而生。 Hive作为一个基于Hadoop的数据仓库基础设施,为用户提供了类SQL的查询语言和丰富的功能࿰…

Hive3.1.3基础学习
文章目录 一、Hive入门与安装1、Hive入门1.1 简介1.2 Hive架构原理 2、Hive安装2.1 安装地址2.2 Hive最小化安装(测试用)2.3 MySQL安装2.4 配置Hive元数据存储到MySQL2.5 Hive服务部署2.6 Hive服务启动脚本(了解) 3、Hive使用技巧3.1 Hive常用交互命令3.2 Hive参数配置方式3.3 …